
一种基于支持向量机和主题模型的评论分析方法∗
2019-06-11 07:40黄新越
软件学报 2019年5期
陈 琪,张 莉,,蒋 竞,黄新越
1(北京航空航天大学 软件学院,北京 100191)
2(北京航空航天大学 计算机学院,北京 100191)
随着移动互联网的兴起,产生了大量针对移动应用的在线评论信息.移动应用程序的用户群体广泛,用户的反馈丰富,并且随着版本迭代迅速更新.尤其是用户对移动应用的中评和差评(简称中差评),是收集用户问题的重要数据来源.现有的应用分发平台都支持用户对应用进行评论,比如 360手机助手,它是国内市场份额较大的移动应用平台,提供应用程序卸载、安装、升级和评论等一系列服务.一些实证性研究表明,用户评论中包含很有价值的信息,例如错误报告、功能需求和用户体验等[1].对开发者来说,应用市场中的用户评论能够帮助他们更好地理解用户反馈,提高软件质量[2,3].
随着移动应用的广泛流行,用户评论的数量庞大,并且是无结构的,手动检查耗时且低效.因此,需要信息挖掘对用户的中差评进行处理,使用户抱怨信息的核心内容直观地展现在开发者面前,让开发者更快更有针对性地对软件进行更新.为了分析用户评论,现有研究主要采用分类或主题提取的方法.
· 首先是对用户评论进行分类.Panichella等人[4]通过评估发现,文本分析、自然语言处理和情感分析这3种技术结合,可以得到最好的分类结果;Maalej等人[5]尝试了多种技术对用户评论进行处理与分类,通过实验发现,多个二元分类器优于单一多元分类器;McIlroy等人[6]对几种机器学习分类器进行了比较,通过评估最终采用支持向量机进行分类.
· 其次,一些研究采用主题提取的方法分析评论.Galvis等人[7]将意见挖掘领域的ASUM模型用于软件应用的用户评论中,来自动地提取评论内包含的主题;姜巍[8]提出了针对意见挖掘问题域的关联 LDA模型,并应用于用户在线评论.
上述研究工作单纯考虑分类或者主题提取的方法,没有结合两种方法来分析评论.我们以两条评论为例,说明分类与主题分析的区别:(1) “页面中的按钮没反应”;(2) “应该在页面中添加一个按钮”.这两条评论以分类的方法来处理,将分为两类:(1) 软件错误;(2) 请求增加功能.以主题分析的方法来处理,将提取出“页面”、“按钮”这样的主题.可以发现:分类方法能够了解用户遇到的问题种类,但很难得到评论中针对的软件特征;而主题分析方法能够得到特征信息,但很难区别用户的意图.如果我们将分类与主题分析结合起来,那么就既能通过分类得到评论指出的问题种类,又能通过主题挖掘得到评论里具体针对的软件特征.对于前面提到的两条评论的例子,结合分类与主题分析得到的结果可能如图1所示.

Fig.1 Results based on classification and topic extraction图1 基于分类和主题提取的结果
开发者则能由此了解用户遇到了页面中按钮相关的错误,以及用户希望为页面中增添按钮.相比于单独的分类分析或是主题分析,都能更精确地定位需求.
针对该问题,本文提出了一种基于支持向量机和主题模型的评论分析方法.该方法从分类和主题分析两个方面对用户评论进行研究,并将这两者结合起来,更好地帮助开发者理解用户中差评中包含的需求,最后将所得结果进行对比实验.首先,该方法对用户评论进行特征提取,使用代价敏感学习减轻不平衡数据带来的影响,并将提取到的文本用线性支持向量机进行多标签分类;然后采用主题模型,对每组分类的用户评论提取主题词和主题句,最终得到了基于分类的主题分析结果.为了证明我们方法的有效性,我们从 360手机助手随机选取了评分高(今日头条)和评分低(360云盘)的两个应用,分析了两个应用共5 141条用户中差评,实验结果表明,本文提出方法获得的结果优于ASUM方法[7].
本文的主要贡献如下:
· 提出了一种基于支持向量机和主题模型的评论分析方法,更好地帮助开发人员了解用户反馈;
· 与经典方法 ASUM[7]相比,本文提出方法的困惑度更低、可理解性更佳,包含更完整的原始评论信息,冗余信息也更少.
本文第 1节介绍分类方法和主题词提取等相关内容.第 2节概述本文方法框架并详细讲解本文提出的RASL方法.第3节通过定性和定量实验评估验证方法效果.第4节进行有效性分析.第5节给出结论及未来工作展望.
1 相关工作
近年来,一些研究人员对用户评论进行主题挖掘,提取出评论中的主题并给出主题下的代表性句子能使开发者快速、直观地理解用户反馈.Blei等人[9]在2003年就提出了主题挖掘模型LDA模型,这是主题挖掘方面的经典模型.姜巍等人[8]提出了针对意见挖掘问题域的关联LDA模型,并应用于用户在线评论.Galvis等人[7]将主题挖掘领域的ASUM模型用于软件应用的用户评论中,来自动地提取评论内包含的主题.在结果的呈现上,为每个主题给出了代表性的句子,需求工程师可以查看这些具有代表性的用户评论,来决定主题是否是需求更改的候选项,比单纯的主题词集合更容易理解,是一种较好的主题表现形式.
除了主题挖掘,对用户评论进行分类也是用户反馈获取的主流方法.Panichella等人[4]认为,主题分析技术对于发现评论文本中的主题是有用的,但是它们不能揭示包含特定主题评论的用户的意图.文章基于文本分析、自然语言处理和情感分析,设计了 3种不同的技术,从评论中提取出特征,然后使用这些特征来训练机器学习的分类器.通过评估发现,结合 3种技术可以得到最好的结果.Maalej等人[5]尝试了多种技术对用户评论进行处理与分类,如字符串(关键词)匹配、情感分析、二元分类器与多元分类器.最终,通过实验发现,多个二元分类器优于单一多元分类器.McIlroy等人[6]则关注评论的多标签问题,认为一条评论可能包含着多个问题.文章中提出了14种类型的问题,并认为,这些问题是相对于特定应用来说是独立的,并对朴素贝叶斯、J48决策树、支持向量机这几种机器学习分类器进行了比较,通过评估,最终采用支持向量机进行分类.Pagano等人[2]在2013年调查了苹果应用商店(AppStore)上用户评论的具体内容,并将这些内容按照主题进行了分类,该方法是否适合中文应用市场,还需要进一步验证.在本文的前期工作中也对用户评论进行了分类,Zhang等人[10]使用对支持向量机对文本进行分类,评估指标的值优于McIlroy等人提出的Multi-label方法[6].
上述研究采用主题挖掘或者分类方法对用户评论进行分析.在这些工作的基础上,本文先对用户评论进行分类,然后对每个类别的评论进行主题挖掘,产生给出主题的代表词以及代表性句子.这样既能通过分类得到包含用户意图的信息,又能通过主题挖掘得到评论里用户重点关心的问题,使开发者能够快速、方便地理解用户反馈.
2 基于支持向量机和主题模型的评论分析方法RASL
基于以上分析,本文提出一种基于支持向量机和主题模型的评论分析方法 RASL(review analysis method based on SVM and LDA).方法架构如图2所示.
方法分为两个阶段:分类阶段和主题分析阶段.首先,根据第2.1节确定的评论类型,本文通过支持向量机的方法[10]对评论进行分类,可以得到包含用户意图的信息;然后,本文将分类好的评论数据分别进行 LDA主题分析[9],并给出代表句,从而得到评论里用户重点关心的问题.结合现有方法的优势,使得使开发者能够快速、方便地理解用户反馈.可以注意到:每个问题类型的圆圈大小不一,这代表着每个问题类型下的主题个数由该问题类型的评论比例确定.
下面首先讨论用户评论的分类类型,然后对分类方法进行描述,最后将分类的结果作为输入,得到主题词和代表句.
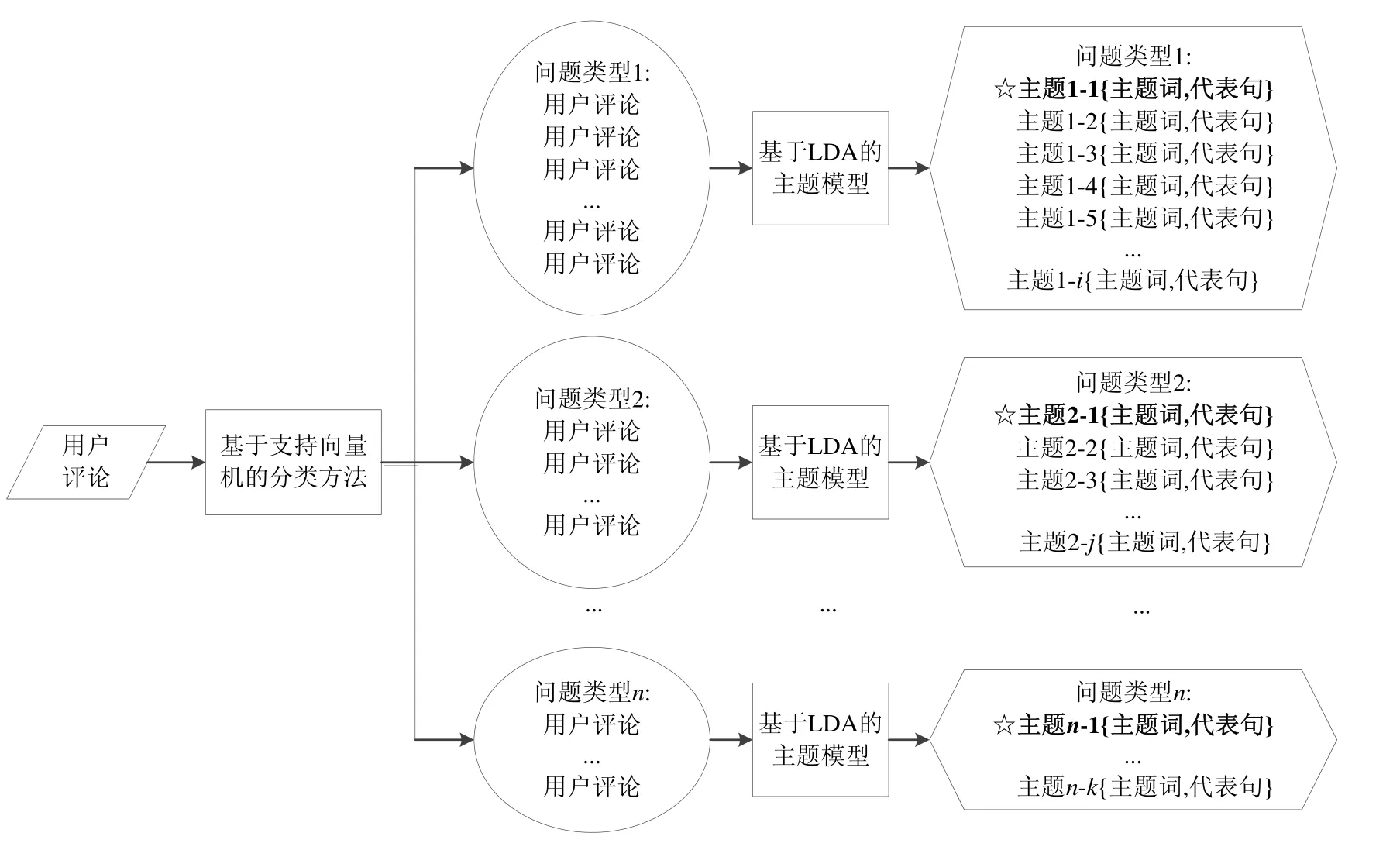
Fig.2 Overall workflow of the RASL method图2 RASL方法的整体工作流程
2.1 用户评论的分类类型
为了对评论进行分类,需要确定用户评论的类型.依照Seaman等人提出的方法[11,12]迭代地对抽取的用户评论进行人工标注,分析评论中包含的问题种类.分析过程如下.
· 首先,选择由McIlroy等人定义的问题类型集[6]作为起始集.对于每一条评论,手工检查并标注评论指出的问题类型.
· 如果评论中的问题不包括在问题类型集中,则设定一个新的问题类型并将其添加到问题类型集中.然后,基于新的问题类型集重新启动标注过程.这个过程是由3人并行完成,在3人均完成此过程后,比较3人标注的结果.
采用组内相关系数(intra-class correlation coefficient,简称ICC)对标注结果的可靠性进行度量.ICC是一个推断统计量,它描述了同一组中元素的相似程度[13],可以用于评估不同观测者进行相同的定量测量时的一致性或可重复性.如果ICC小于0.4,则表示相似性较差;如果ICC在0.40和0.59之间,则表示相似性一般;如果ICC在0.60和0.74之间,则表示相似性较好;如果ICC在0.75和1.00之间,则表示相似性很好.我们对标注结果之间的ICC进行了计算,以衡量人工标注的可靠性.对于每一个问题类型,ICC都是较好或很好,并且发现,独立标注的结果差异没有特别大.然后进行讨论,并消除差异,所有问题类型的ICC均为1,也即没有区别.最终得到了17种问题类型,问题的类型与描述见表1.详细过程见我们的前期工作[10].

Table 1 Classification of comments表1 评论的分类
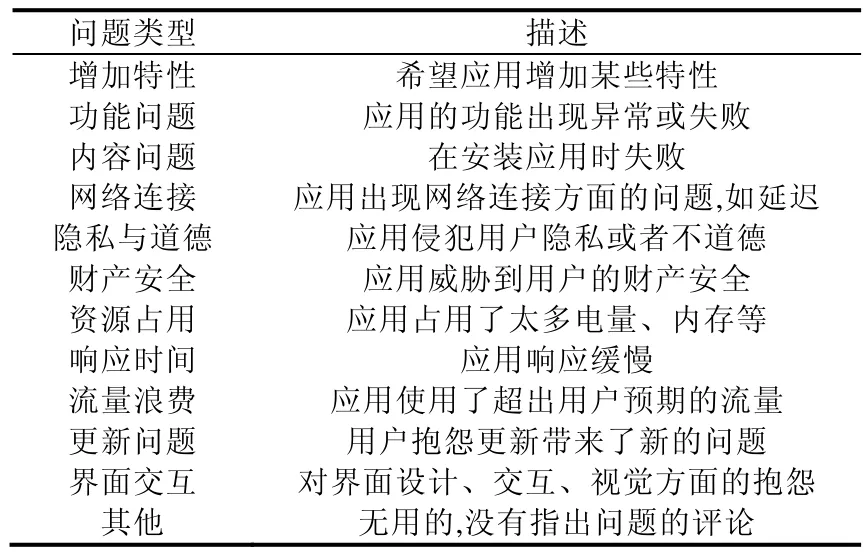
Table 1 Classification of comments (Continued)表1 评论的分类(续)
2.2 用户评论分类方法
为了能自动标记出新的用户评论属于的问题种类,本文采用机器学习的方法来进行用户评论分类.此分类方法包含特征提取部分和模型构建部分:特征提取部分的目标是提取评论文本的特征,使其转换为分类模型可用的形式;然后,采用支持向量机构建用户评论的多标签分类模型.同时,为了减轻不平衡数据的影响,使用了代价敏感学习的方法(如图3所示).
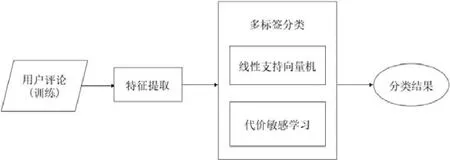
Fig.3 User review classification framework图3 用户评论分类框架
在特征提取阶段,目标是提取评论文本的特征.由于文本是非结构化的数据,因此必须首先将其转换为计算机可解析的形式.向量空间模型(VSM)是一种适用于大规模文献的文本表示模型[14],在该模型中,文本空间被认为是由一组正交特征向量组成的向量空间.矢量的每个维对应于文本中的一个特征,每个维度本身表示文本中对应特征的权重.使用向量空间模型来描述文本数据需要确定文本的特征与权重.对于英文文本来说,一个词就是一个特征.而中文文本首先需要进行分词.Jieba分词是一个 Python分词工具,本文使用它来进行分词,并删除数字和非汉字,但是停止词需要被保留下来,因为其中一些可以帮助确定问题类型,例如“不要”.参考现有工作[6],过滤掉出现不到 3次的词语,去除拼写错误或不重要的词语,降低分类的复杂性.其次,对于特征的权重,tf-idf算法[15]是计算权重的常用方法.它的主要思想是:如果一个单词或短语多次出现在某一文档中,并且在其他文档中很少见,则该词或短语被认为具有很好的分类能力.比如,“安装”一词会在内容问题这个分类下出现,但它很少在资源占用等其他分类下出现,因此我们可以把“安装”一词作为分类依据之一.为了构建特征向量,本文使用String To Word Vector filter,这是WEKA对tf-idf算法的一个实现[16].
模型构建阶段的目标是为用户评论构建一个多标签的分类模型,对于输入的评论,模型可以输出评论所属的问题类型.由于一条用户评论可能包含多个问题类型,因此需要解决的问题实际上是一个多标签分类问题.Binary Relevance(BR)是解决多标签分类问题的代表性算法之一,它将多标签分类问题转化为多个二分类问题.模型选择使用 BR,因为它是线性复杂度的,较为简单[17].这意味着需要构建多个二分类器,并且要对分类效果进行整体评估.本文选择支持向量机作为二分类器,支持向量机将数据视为p维向量,如果支持向量机用(p-1)维平面分离这些点,则它被称为是线性的.为了处理有些原始问题在有限维中不能线性分离的情况,支持向量机使用核函数将原始有限维空间映射成高维空间,例如径向基函数核.在样本数量少且特征数量非常大的情况下,非线性分类通常不准确,可能错误地划分特征空间,导致比线性模型更差的结果.因此,本文选择使用线性支持向量机,在具体的算法中采用WEKA的支持向量机实现,即SMO分类器[18,19].将PolyKernel参数设置为1,使其成为线性支持向量机.
但对于一些问题类型,负样本的数量远大于正样本.这些不平衡的数据可能导致分类器更倾向于将新样本预测为负样本.为了减轻不平衡数据的影响,采用代价敏感学习的方法[20]来处理这个问题.代价敏感学习方法的核心是代价矩阵.代价矩阵定义见表2.
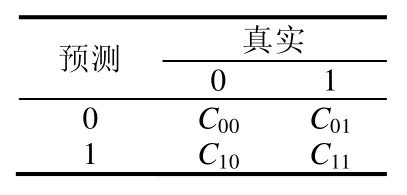
Table 2 Cost matrix表2 代价矩阵
其中,Cij是把j类分类到i类的成本.显然,C00=C11=0;而C01,C10是两种不同的错分代价.由于数据是不平衡的,可以根据不同的错分代价来给数据重新赋予权重.当将正样本预测为负样本的代价较高时,就增加正样本的权重.具体到算法实现中,本文使用一个元分类器来使基类分类器成为代价敏感的,这个元分类器支持通过抽样来增加样本的权重,而基类分类器也即前面提到的支持向量机分类器.元分类器在 WEKA中的实现即CostSensitiveClassifier[18].另外,还需要为每个问题类型指定代价矩阵.为了确定代价矩阵的具体值,对于每个问题类型,通过遍历来得到一个使分类结果最佳的代价矩阵值,然后采用这个值.详细过程见我们的前期工作[10].
2.3 主题词与代表句的生成
本节针对分类结果进行统计抽取主题,通过所得到的主题,进一步生成主题词和代表句.
在使用基于支持向量机的分类模型进行分类,得到分类结果之后,需要确定将提取的主题总数(例如期望每X条评论提取Y个主题,则根据用户评论数量计算提取的主题总数).由于“其他”类型包含的是无用的评论,因此不对该类型进行主题提取.其余问题类型则根据分类的结果中各自所占比例(除去“其他”类型)计算出每个问题类型对应的主题数目,后续再对各问题类型下的评论进行主题分析.在这里,举例说明多分类下主题数的确定,比如主题总数为M,那么每个分类的主题则是分类下的评论数量占总数量的比重.具体来说,如果“内容问题”比重为Ratio,那么分类为内容问题的主题数为M×Ratio.
在机器学习和自然语言处理中,主题模型是用于发现文档集合中抽象“主题”的一种统计模型,是一种经常用于在文本主体中发现隐藏的语义结构的文本挖掘工具.每条评论都是与某些主题相关的,因而特定的词语也会出现在不同主题的评论中.本文采用了 LDA(latent dirichlet allocation)的模型[9]来进行主题词和代表词的生成.这个模型是一种典型的词袋模型,即一个评论是由一组词构成,不去考虑词语的顺序,因而简化了语义关联问题的复杂性.LDA模型包含主题的生成、根据阈值挑选关键词、代表句的生成这3个部分.图4为LDA生成过程[9].LDA方法将评论的主题以概率分布的形式给出,通过分析评论抽取出它们的主题分布,然后再以一定概率迭代的选取主题下的某个单词作为主题词,最后根据概率选择代表句.
在主题生成阶段,本文将通过基于支持向量机的模型得到的 16个(除去“其他”分类)分类评论作为输入,目标输出是指定数目的主题.由于得到了 16个分类的结果.下面我们用“内容问题”这个分类举例说明.基本思想是:LDA中存在主题词库,通过分析“内容问题”这个分类的所有评论,LDA通过词库自动分析得到“内容问题”对应的主题.由于开始的时候我们设定主题数为T,因此LDA方法将选择最相关的前T个主题作为“内容问题”全部评论的主题.对应到图4,“内容问题”所有评论与T个主题的一个多项分布相对应,将该多项分布记为θ;α是主题分布θ的先验分布Dirichlet分布的超参数.在这里,本文选最相关的T个主题作为主题的生成部分的结果.
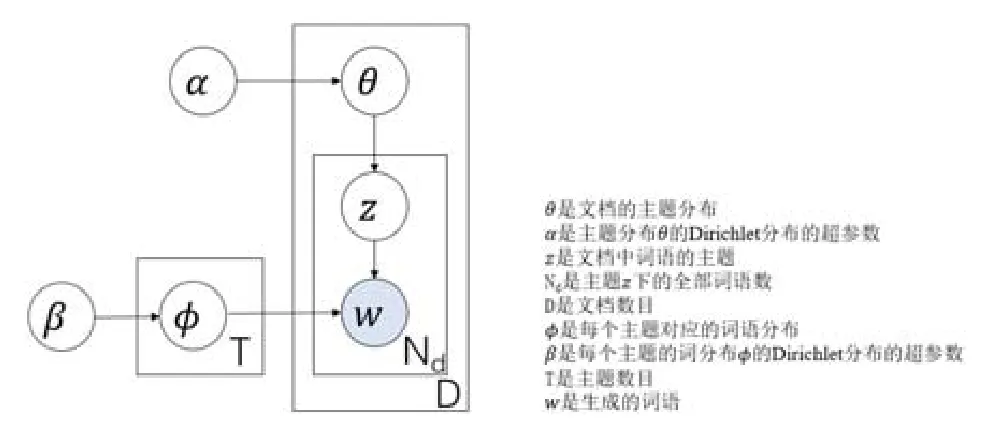
Fig.4 LDA generation process[9]图4 LDA生成过程[9]
在根据阈值挑选关键词阶段,输入是主题生成阶段得到的“内容问题”分类下的T个主题,目标输出是每个主题一下指定数目的主题词.基本思想是:由于一个词汇在“内容问题”的其中一个主题中都存在一个概率值,因此在主题词生成时,去选择对应主题下概率值最高的M个词汇即可,M取值可由需要确定.对应到图4,每个主题与评论中的Nd单词的一个多项分布相对应,将这个多项分布记为φ.β是每个主题的词分布φ的先验分布Dirichlet分布的超参数.依据“内容问题”文档所对应的主题分布θ抽取一个主题z,主题z所对应的多项分布φ中抽取一个单词w,将这个过程重复Nd(主题z下的全部词数)次,就生成了其中主题z下的主题词.LDA通过变分EM算法、Gibbs抽样法等方法,迭代地学习这两个参数,使其最终收敛于某一结果.
在代表句生成阶段,输入是根据阈值挑选关键词阶段得到的主题词,目标输出是每个主题一下的代表句.基本思想是:假设d向量为(d1,d2,...,dn),每个di代表一条用户评论被分配到每个主题的概率,假设主题数为T,则第1条评论的向量d1为(d1-1,d1-2,...,d1-20),第 2条评论的向量d2为(d2-1,d2-2,...,d2-20)等.对于目标主题 1,如果某一评论在di-1位置的概率值为所有评论中的最大值,则选择该评论作为目标主题的代表句.
最终输出结果,本文用分类后得到类别包含评论的数量从多到少进行排序,然后进行主题分类,得到每个主题下评论的数量,将主题按照评论数量从多到少排序,将每个分类下评论数量最多的主题进行标注(用“☆”并且加粗进行标注),从而方便阅读者对提出较多的问题进行重点关注.
3 实验验证
本节对本文提出的基于支持向量机和主题模型的评论分析方法 RASL进行评估验证,本文将从定性分析和定量分析两个方面进行实验,以检验RASL方法的有效性.
3.1 实验对象
本文的RASL方法基于支持向量机分类算法采用LDA主题模型提取主题词和代表句.本文使用Jieba分词工具,把中文分词后输入经典方法ASUM[7].与RASL方法不同,ASUM方法[7]是一种结合情感分析的主题模型.此方法将句子看作文档,句子中每个词都是隐含主题的分布,然后进行主题挖掘.在此基础上,融合主题特征和情感信息来分析用户对这些主题的偏好,并以〈主题词,代表句〉序对作为输出.本节我们将本文所提出的方法RASL与ASUM方法进行对比分析.
360手机助手是国内市场份额较大的应用平台,提供移动应用程序卸载、安装、升级和评价等一系列服务.本文分别从360手机助手中随机抽取一个评分高的应用(评分9以上)和一个评分低的应用(评分6以下),这两个应用分别是今日头条和360云盘,将它们的全部中差评收集起来.360云盘的中差评共计3 950条,今日头条的中差评共计 1 191条.将这 5 141条数据作为原始用户评论信息数据,将通过文本预处理得到的结果分别通过ASUM 方法和 RASL方法处理,得到实验所需数据.根据统计计算,在我们所爬取的 5 141条数据中,只存在0.027%的评论由连续的几个段落组成,而 99.973%的评论是由单独一个段落组成,因此本文没有考虑评论分段问题,将分成多段的评论作为一个单独的评论进行处理.
3.2 研究问题
本文对两个应用的5 141条评论进行了分析,除了本文的方法之外,也采用ASUM方法进行主题提取与代表句提取,和原始评论一起作为比较对象.我们希望通过调查能回答以下研究问题.
· RQ1:ASUM方法和本文方法RASL的困惑度如何?
· RQ2:和原始评论相比,ASUM方法和本文方法RASL是否包含完整的信息?
· RQ3:和原始评论相比,ASUM方法和本文方法RASL是否包含冗余的信息?
· RQ4:ASUM方法和本文方法RASL的阅读理解性如何?
· RQ5:ASUM方法和本文方法RASL的评论阅读时间如何?
3.3 实验方法
3.3.1 困惑度分析
对于主题模型的评估,Blei等人[9]在论文中提出了用困惑度(perplexity值)作为评判标准.困惑度度量概率分布或概率模型的预测结果与样本的契合程度,在这里是指:对于一个文档d,所训练出来的模型对于文档d属于哪个主题的确定程度.困惑度越小,说明模型效果越好.困惑度的计算公式为
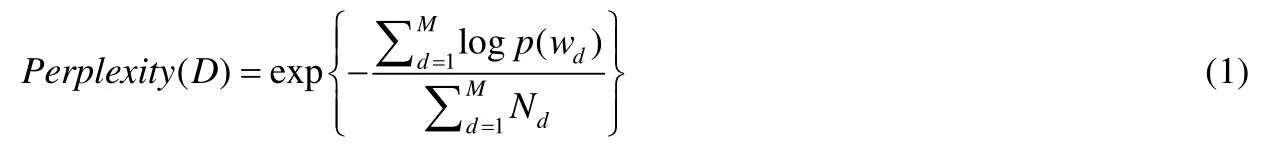
M为文档集合中的文档数目,Nd为第d篇文档中单词的个数,p(wd)为第d篇文档的概率(probability),也即这篇文档中每个单词概率的乘积.而对任意一个单词w,单词概率,z代表主题,p(z|d)为各主题下该词所在文档的概率,p(w|z)为该词在各主题下的概率.
对于ASUM方法,根据每个应用的评论数量计算出提取的主题数量,然后用ASUM方法提取出主题词与代表句,作为这个实验的输入;对于本文所提出的RASL方法,首先将每个应用的评论使用基于支持向量机的分类方法进行分类(问题类型与描述见表1),根据每个应用的评论数量计算出提取的主题总数,再根据分类的结果中各问题类型(除去“其他”类型)所占比例计算出每个问题类型对应的主题数目,然后对各问题类型下的评论按照主题数目进行主题提取与代表句提取,将问题类型和主题词、代表句共同作为这个实验的输入.计算困惑度并进行比较.
3.3.2 问卷调查
为研究RQ2~RQ5,实验选择了今日头条和360云盘作为实验数据.实验邀请了6位北京航空航天大学软件工程专业研究生,都具有至少 4年的编程经验,并且经常使用手机移动应用,有过对手机移动应用软件打分和作评论的经历.由他们完成调查问卷,以便回答 RQ2~RQ5.未来我们尝试联系手机应用的开发人员,请他们评价不同方法的结果.
对于每个应用都提供给受试者3份文件:(1) 原始的中差评集合;(2) ASUM方法提供的分析结果;(3) RASL方法提供的分析结果,结果样例如图5~图7所示.链接(https://github.com/ChenQifromBeihang/Essay.git)展示了一个实际的例子,包括原始评论、ASUM生成的结果和RASL生成的结果.为了对比出结果的“完整性”(完整性指对比原始评论,是否有内容上的缺失)并且不使原始评论影响方法结果的可理解性,本文要求受试者先对ASUM方法和RASL方法进行阅读,最后再阅读原始评论.两种方法可能存在相互影响阅读结果的问题,为了减少这种问题带来的不确定性,本文将受试者随机分为两组:一组先阅读ASUM方法再阅读RASL方法,另一组则先阅读RASL方法再阅读ASUM方法.
表3总结了调查问卷中设计的问题.为了不提供给受试者更多信息,问卷中以方法A指代ASUM方法生成的分析结果,以方法B指代RASL方法生成的分析结果.首先,问卷对两种主题分析方法的结果的表现力进行了比较:为了回答主题分析方法产生的结果是否包含完整的信息,即对比原始评论,是否有内容上的缺失,设计了Q1-1和 Q1-2这两项问题;为了回答主题分析方法产生的结果是否包含冗余的信息,即出现重复性内容,设计了Q2-1和Q2-2这两项问题;为了回答主题分析方法产生的结果是否具有可阅理解性,设计了Q3-1,Q3-2这两项问题.然后,问卷对原始评论和主题分析方法之间进行了比较:为了回答主题分析方法如何影响分析用户评论花费的时间的问题,设计了Q4-1和Q4-2这两项问题.

Fig.5 Original review example图5 原始评论示例

Fig.6 ASUM method results example图6 ASUM方法结果示例

Fig.7 RASL method results example图7 RASL方法结果示例

Table 3 Questionnaire表3 调查问卷
3.4 实验结果
· RQ1:ASUM方法和本文方法RASL的困惑度如何?
用本文所收集的用户评论作为实验数据,运用ASUM方法和RASL模型得到结果,对结果计算困惑度并进行比较,如图8所示,ASUM 的困惑度是 302.1,RASL的困惑度是 100.9.本文所提出的方法得到的困惑度小于ASUM方法所得到的困惑度,本文提出的方法优于ASUM方法.
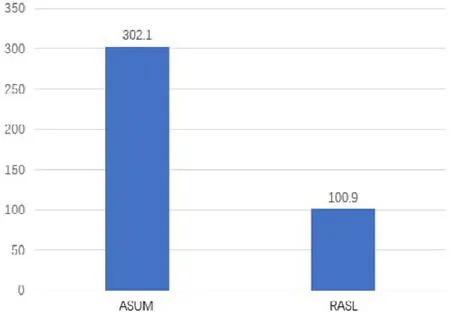
Fig.8 Comparison of ASUM and RASL perplexity图8 ASUM、RASL的困惑度对比
结论:RQ1:本文方法得到的困惑度小于ASUM方法所得到的困惑度
· RQ2:与原始评论相比,ASUM方法和本文方法RASL是否包含完整的信息?
为了回答主题分析方法产生的结果是否具有充分性,将Q3-1,Q3-2的结果汇总于表4,1分为缺失极多信息,10分为没有缺失任何信息.360云盘和今日头条的结果都显示:对于 6位受试者来说,完整性均为 RASL优于ASUM.
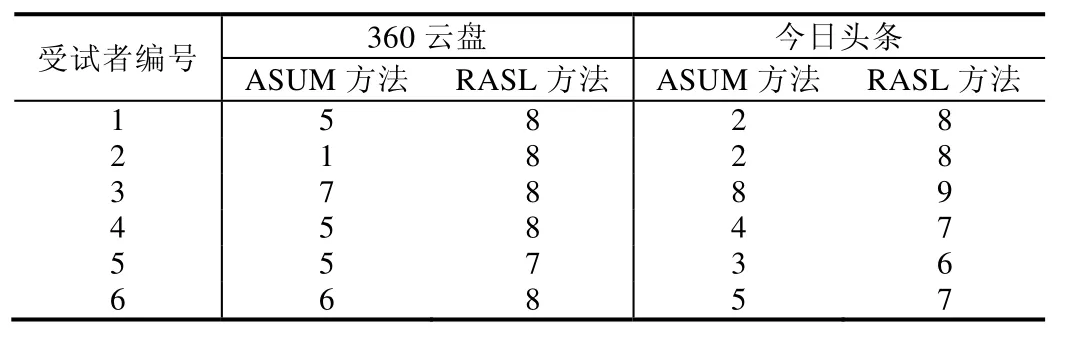
Table 4 Integrity of ASUM and RASL表4 ASUM、RASL的完整性
而后,本文进行Mann-Whitney U检验,检测这种差异的显著性.Mann-Whitney U检验是由Mann和Whitney于 1947年提出的[21],是一种非参数秩和假设检验,这个检验是对独立样本进行的一种不要求正态分布的 t-test检验方法.主要是对来自除了总体均值以外完全相同的两个总体,检验其是否具有显著差异.最终得到的结果显示,RASL的完整性在0.05的显著性水平下明显优于ASUM.
结论:RQ2:在0.05的显著性水平下,RASL方法在完整性显著优于ASUM方法.
· RQ3:和原始评论相比,ASUM方法和本文方法RASL是否包含冗余的信息?
为了回答主题分析方法产生的结果是否具有简明性,将Q4-1,Q4-2的结果汇总于表5,1分为有许多冗余的信息,10分为没有冗余的信息.360云盘的结果显示:对于受试者1、受试者2、受试者4和受试者5来说,RASL包含的冗余信息相比ASUM较少;受试者3认为,ASUM和RASL包含多于信息的数量差不多;而受试者6评价ASUM包含的冗余信息相比RASL较少.采访受试者6,其认为RASL存在个别主题与问题类型不匹配的问题,因此评价略低于ASUM.今日头条的结果显示:对于其中5位受试者来说,RASL包含的冗余信息相比ASUM较少;对于受试者3来说,ASUM和RASL得到结果包含冗余信息量相同.
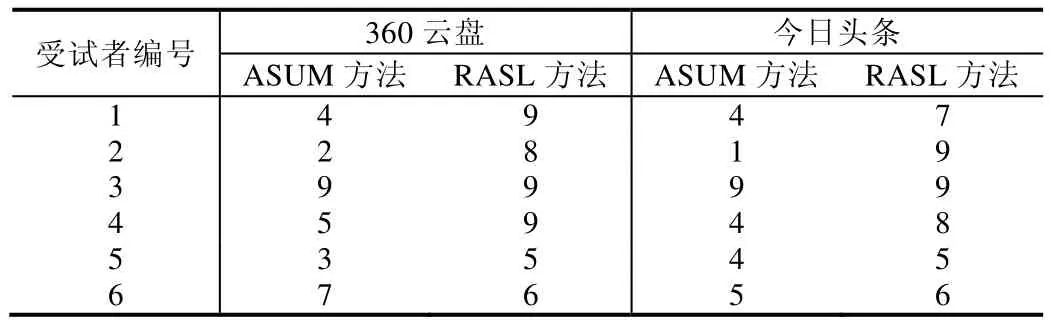
Table 5 Redundancy of ASUM and RASL表5 ASUM表5RASL的冗余性
为了检测这种差异是否具有显著性,本文对两个方法的简明性进行了Mann-Whitney U检验,在0.05的显著性水平下,RASL包含的冗余信息明显少于ASUM.
结论:RQ3:在0.05的显著性水平下,RASL包含的冗余信息显著少于ASUM.
· RQ4:ASUM方法和本文方法RASL的的阅读理解性如何?
为了回答主题分析方法产生的结果是否具有可阅读性,将Q5-1,Q5-2的结果汇总于表6,1分为难以阅读理解,10分为非常易于阅读理解.360云盘和今日头条的结果都显示:对于6位受试者来说,可阅读性均为RASL优于ASUM.
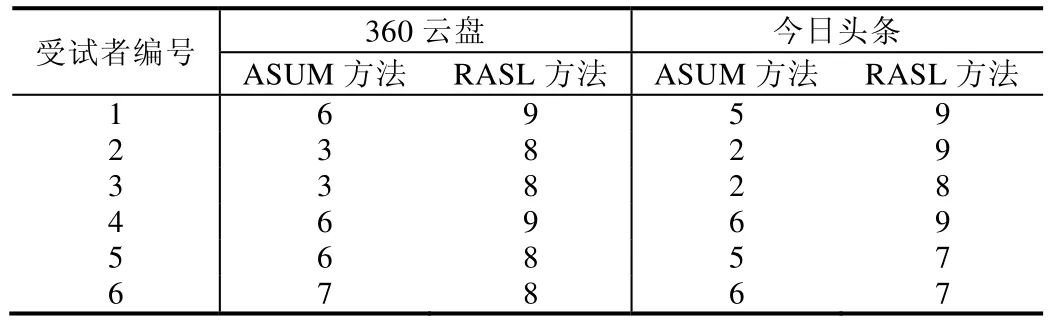
Table 6 Understandability of ASUM and RASL表6 ASUM、RASL的可理解性
而后,本文进行 Mann-Whitney U检验,检测这种差异的显著性,最终得到的结果显示,RASL的可阅读性在0.05的显著性水平下明显优于ASUM.
结论:RQ4:在0.05的显著性水平下,RASL方法在可理解性方面显著优于ASUM方法.
· RQ5:ASUM方法和本文方法RASL的评论阅读时间如何?
为了回答主题分析方法如何影响分析用户评论所花费时间的问题,将Q2-1,Q2-2的结果汇总于表7.360云盘的结果显示:受试者3阅读ASUM和RASL所花费的时间相等;受试者2、受试者5、受试者6阅读RASL所花费的时间略高于ASUM;受试者1和受试者3阅读RASL所花费的时间略低于ASUM.今日头条的结果显示:受试者1、受试者4、受试者5阅读ASUM和RASL所花费的时间相等;受试者2阅读ASUM所花费的时间略高于RASL;受试者3和受试者6阅读RASL所花费的时间略低于ASUM.
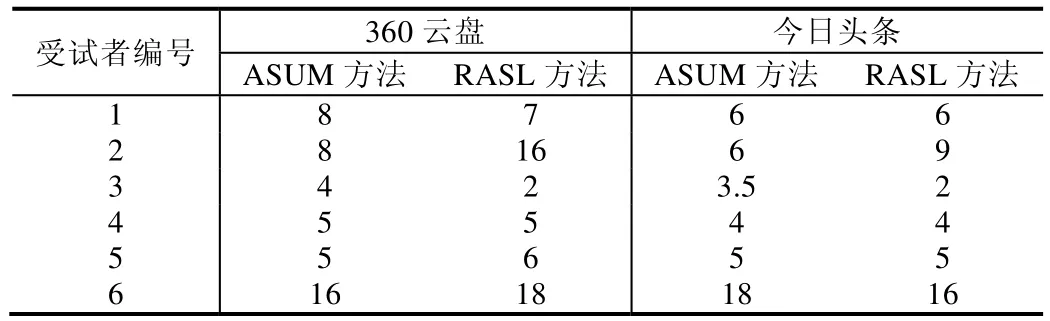
Table 7 Analysis time of ASUM and RASL (min)表7 ASUM、RASL的分析时间 (min)
由于所得ASUM方法和RASL方法所得阅读时间无法直接看出是否具有差异性,本文进行Mann-Whitney U检验,在 0.05的显著性水平下,ASUM 方法和 RASL方法之间的时间差异不具有统计的显著性,总的来说,RASL和ASUM所用阅读时间无差异.
结论:RQ5:RASL方法和ASUM方法所用阅读时间无显著差异.
从实验结果分析中,我们可以得出结论:在困惑度方面,RASL主题分析方法明显优于ASUM方法;RASL主题分析方法和ASUM方法相比,可理解性更佳,包含更完整的原始评论信息,冗余信息也更少.
3.5 定性分析
回收问卷后,采访了受试者对于两种主题分析方法的主观感受.受试者们表示,ASUM的主题阅读起来比较费力,存在较多的无意义主题.本文方法 RASL由于有问题类型作为基础,相当于具有两层结构,有组织性,阅读起来较为清晰明了,一些用户评论可以帮助开发者发现问题.如图9所示,本文方法RASL可以发现“安装”分类下,最常见的问题是更新的版本在部分机器上无法进行安装.

Fig.9 Example图9 示例图
4 有效性威胁
4.1 内部有效性威胁
在对主题分析方法 RASL进行问卷调查时,比较了两种可能的方法:一是分两组,单独评价 ASUM 方法和RASL方法,但是在人员不足够多的情况下,难以消除不同人不同判断标准的问题;因此,本文将受试者随机分为两组,每位受试者对两种方法进行阅读,虽有可以在同一标准下给两种方法打分,但是会带来阅读顺序的问题,因此,本文采用改变顺序减轻了两种方法间的相互影响.另外,ASUM和RASL产生200个主题的结果.主题数量较多,难以请受试者对每个主题进行详细打分.未来我们尝试联系更多的受试者参加问卷调查,减轻阅读顺序、主题差异造成的偏差.最后,本文的研究没有加入好评,这可能会导致一些问题的遗漏,因为在好评中也可能有用户对于应用的一些抱怨意见.不过,即使好评中存在一些抱怨意见,也不会影响本文方法的可用性.今后,我们将进行更多的实验来完善对所有评论的研究.
4.2 外部有效性威胁
评估实验针对两个应用进行,尽管本文选择的两个应用软件分别随机抽取了评分最高的应用软件和评分最低的应用软件,但这两个应用可能仍然不能代表所有应用软件.在未来的工作中,我们计划爬取更多应用软件的评论,并与现有的结果进行比较.而且评估实验中的两个应用都来自于 360手机助手,得到的结果是否可以推广到其他应用商店是未知的.在今后的工作中,我们将选取不同平台的应用进行实验,并将结果与 360手机助手的结果进行比较,以巩固我们的发现.
5 结论与展望
移动应用的用户在线评论数量巨大、信息量丰富,是重要的反馈数据来源,通过收集用户使用软件后产生的反馈信息,挖掘其中的各类需求,对软件开发者而言有重要的价值,使开发者能快速、直观地理解用户反馈.本文提出了一种基于支持向量机和主题模型的评论分析方法RASL.RASL方法首先进行用户的评论分类,然后对每个类别下的评论进行主题挖掘.
本文方法基于支持向量机的分类模型的分类结果为基础,依照分类结果中每个问题类型所占比例确定每个问题类型的主题数目.然后选择了LDA模型进行主题分析,使用LDA模型对各问题类型下的评论进行主题提取与代表句提取.而后,设计实验对比ASUM方法对RASL方法进行评估.首先对两种方法不同主题数目下的困惑度进行计算,结果得到 RASL方法困惑度明显减少.然后用调查问卷进行评估,实验数据是两个应用的全部中差评,邀请软件工程专业的受试者对原始评论、ASUM主题分析方法和RASL主题分析方法的生成结果进行评估.实验结果表明,与ASUM相比,RASL方法的可理解性、完整性更佳,包含的冗余信息也更少.
在未来的工作中,我们将邀请足够多的受试者进行实验,并且邀请一些软件开发人员,将本文的方法应用于更多应用软件,从而判断本文提出方法所得结果是否能真正符合开发商需求.
猜你喜欢
中国心血管杂志(2022年2期)2022-11-25
中国心血管杂志(2022年4期)2022-11-25
世界最新医学信息文摘(2022年43期)2022-11-19
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
科学生活(2020年9期)2020-10-10
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
高中生学习·高三版(2016年9期)2016-05-14
