
基于内存表的人员信息系统综合查询优化
2019-06-20 01:34彭起
科技视界 2019年12期
【摘 要】本文主要面向人员检索系统中数据查询的优化问题。该优化算法将人员检索数据库综合查询速度从分钟级优化至秒级。同时解决查询结果集组合、去重等一系列问题。为提高用户使用体验极大提高。
【关键词】内存表;人员信息系统;综合查询优化
中图分类号: TP311.52 文献标识码: A 文章编号: 2095-2457(2019)12-0236-002
DOI:10.19694/j.cnki.issn2095-2457.2019.12.114
1 问题引出
在实际的人员检索系统中,对于全库检索时间效率的问题,一直是困扰开发者的难题。在我实际做项目过程中,我在做人员信息系统全库检索时,发现由于数据分散组织的原因,导致查询速度异常缓慢。查询速度缓慢给用户带来的体验是极其糟糕的。刘芬[1]、杨莹鹃[2]等做了关于优化查询规则、查询逻辑等方面工作。本文将在借鉴其成果基础上,通过优化数据库中数据组织、存储方式来优化查询。在仔细分析系统架构之后,对系统架构做大调整,同时提出基于内存表的综合查询算法。以此来大幅度提高综合查询速度。本文所有涉及到数据表均是基于MySQL数据库。所有涉及到的算法均采用PHP语言进行设计。
2 相关概念解释辨析及其应用条件
2.1 内存表与临时表
内存表是指存放在内存中的表,所使用的内存大小可以通过相关的配置文件进行配置。与内存表相关的,需要区分一个概念,临时表。临时表也是存放在内存中,临时表的内存也通过相关配置文件进行配置。当数据超出临时表最大值限制时,数据将自动转为磁盘表,而内存表相应的会提示数据溢出错误。
2.2 内存表使用说明
MySQL内存表的容量受两个参数限制,分别是:“max_heap_table_size”和“max_rows”。也可以将“max_rows”类似参数的设定放在数据库的存储引擎之后。同时在使用之前,仍需修改“my.ini”文件中的相关配置项。具体是“max_heap_table_size”和“max_rows”。经过修改之后,创建数据库表时将存储引擎改为“MEMORY”即可。
3 算法设计过程
3.1 创建内存索引表
综合查询时,由于需要多次访问全库索引表,导致频繁“IO”请求,从而大大降低检索速度。同时,数据管理系统的数据类型众多,数据分散组织,碎片化较为严重,特将数据按照数据类型进行分类存储。一个数据类型一张表,每一张表的关键字信息存入内存索引表。为提高检索独特,为内存表建立索引。同时将表名相关信息存入索引表中,方便后期查询时对表进行定位。
3.2 传入参数分析
本系统数据根据不同类型分散组织数据表,设计有近一百多种数据类型,每种数据类型中会涉及到人名、身份证号等信息。根据本信息系统数据表的组织方式,进行综合查询时,需传入以下参数:一级分类ID;二级分类ID;年份;关键字一;关键字二;关键字三等等。
3.3 算法過程详述
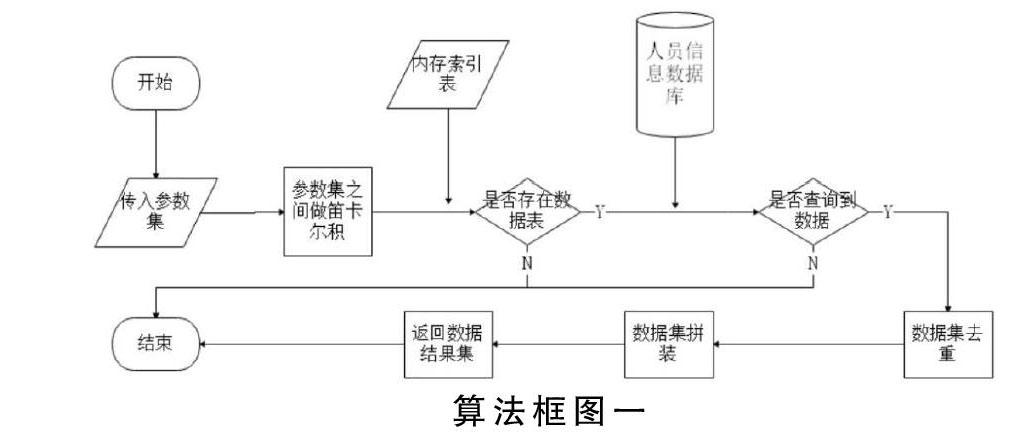
根据调用程序传入的参数(见3.2),将一级分类ID、二级分类ID、年份三个数据集合做笛卡尔积,确定所有可能的“数据类型-年份”组合。遍历做好的笛卡尔积,对于每一个记录,通过一级分类ID、二级分类ID、年份组合查询条件到索引表中查询是否对应有数据库表。当数据表不存在时,随机跳出本次循环,开始下一次循环。如果数据表存在,则可以拿到数据表的表名。得到数据表之后,再次根据关键字一、关键字二其中的一个或两个或其组合作为查询条件模糊查询对应数据库表。通过上述步骤即可确定查询结果集。同时,每一张表查询出的结果集合并,并将数据类别作为返回结果集的一个元素。详细的算法见算法框图一。
算法框图一
3.4 查询结果集去重
去重操作相对简单。PHP自身带有“unique”函数,可作为去重的直接系统方法。但是由于返回结果集的结构相对复杂,所以单单使用“unique”函数是远远不能满足去重需要的。对于一个结果集,如果进行多重“for”循环,对每一种数据类型编写去重算法,则工作量过大,而且容易出错。如果进行的“for”循环层数太少,则无法完成去重操作。经过反复实验,最终确定为,采用二重“for”循环,并结合“unique”函数进行去重。经过反复实验,与优化之前相比,查询时间效率大大提高。目前,综合查询的相应时间在两秒中之内。
3.5 查询结果集返回
在以上所有步骤进行完之后,即可对数据进行返回。在PHP中,数据集通常以“JSON”方式进行返回。用语句“echo json_encode($list,JSON_UNESCAPED_UNICODE)”返回数据集。至此,算法设计过程结束。
4 结束语
本文通过做数据库索引表放入内存存储、数据分类型存储、参数优化、查询过程优化、查询结果组合和去重等方式,大幅度提高综合查询的效率。经过反复测试,查询时间由原先的分钟级别降低至现在的两秒之内。可以看出,将多种类型的数据分类型存储,并建立系统内存索引表。同时优化传入参数等方式,其查询效率将大大提高。在后面做人员信息检索系统时,也可将本文中提到的算法做好的借鉴。在此算法基础上,经过更高层次的优化,其查询效率也将会大幅度提高。
【参考文献】
[1]刘芬.数据库管理系统中查询优化的设计和实现[J].信息安全与技术,2014,5(2):82-84.
[2]杨莹鹃.数据库管理系统中查询优化的设计与实现[J].电脑知识与技术,1009-3044(2018)25-0014-03.
作者简介:彭起(1998.01—),河南开封人,河南大学计算机与信息工程学院,本科在读。
