
个性化旅游景点推荐中考虑约束的关联规则挖掘算法
2019-07-09 01:13林甲祥高敏节陈崇成巫建伟王雪平张泽均
福州大学学报(自然科学版) 2019年3期
林甲祥,高敏节,陈崇成,巫建伟,王雪平,张泽均
(1.福建农林大学计算机与信息学院,福建福州 350002;2.福州大学福建省空间信息工程研究中心,空间数据挖掘与信息共享教育部重点实验室,福建福州 350108;
3.自然资源部第三海洋研究所海洋环境管理与发展战略研究中心,福建厦门 361001)
0 引言
随着国民经济的增长和人民生活水平的提高,游客的个性化旅游需求越来越强烈.然而由于游客群体的多样化,在经费和时间的限制下,如何较好地选择游客感兴趣的景点、合理地规划旅游路线,往往是游客或旅游营销部门既注重又亟待解决的问题[1].利用关联规则对旅游数据进行挖掘,能够为游客规划旅游线路提供参考,已有学者开展了基于关联规则的智慧旅游相关理论和应用研究.在算法的分布式并行化方面,典型工作如文献[2]基于MapReduce框架对大数据环境下的定量关联规则进行了研究.在约束关联规则方面,文献[3-4]对考虑项集约束的关联规则进行研究,并对基于晶格结构的类别关联规则挖掘进行了探索.文献[5]对考虑项集约束的高效关联规则挖掘进行研究,通过剪枝各阶频繁项集生成过程中产生的不感兴趣的项集和用户不感兴趣的规则,提高了算法挖掘的效率.文献[6]对无时间约束的时空关联规则挖掘进行研究,并在全球恐怖主义事件挖掘中进行了示范应用.文献[7]针对事件序列的有序性,提出了有顺序约束的关联规则挖掘方法KAPMiner.文献[8]对综合考虑类别约束和项集约束的关联规则进行研究,提出了单步骤式的类别数据关联规则挖掘方法.国内,文献[9]对顾及背景知识的多事件序列关联规则挖掘算法进行研究,能在一定程度上改善经典的MOWCATL算法存在的挖掘规则冗余或遗漏问题.在基于关联规则的智慧旅游方面,文献[10]通过蓝牙跟踪数据对旅游胜地的参观模式进行挖掘,并在比利时根特地区进行了示范应用.文献[11]将模糊聚类和关联规则挖掘用于旅游景点分析和提高景点的游客吸引力研究中.文献[12]针对多个约束条件的旅游行程规划问题,提出了一个基于时间框架的旅游行程规划算法.文献[13]基于联合国世界旅游组织(UNWTO)统计的旅游文化数据,使用关联规则对游客与住宿服务之间的供需关系进行了分析.
从考虑约束的数据挖掘角度出发,对旅游景点和旅游线路进行规划的相关研究或成果报道还较少.本文以向用户提供个性化、更加满意、更加高效的旅游景点和路线推荐服务为目标,采用半监督的方式,将用户的具体需求以约束的方式融合到关联规则挖掘中,通过与约束密切相关项的提取,为用户制定个性化旅游路线和景点选择提供相关的候选信息,并在实际数据集中开展示范应用研究.
1 ConstrainARM算法
1.1 核心概念
基于项集约束的关联规则挖掘中,规则的前件后件约束C是项集I的一个或者多个子集的集合,用于限制规则的前件或后件必须包含的内容,记为C={cxx =1,2,…,s},其中cxI.相应地,事务集T中包含约束ci的所有事务的集合称为约束ci关联的事务子集,简称ci的约束子集,记为T(ci).
支持度(sup)和置信度(conf)常用于衡量关联规则挖掘中规则的兴趣度.对项集X,XI,X在事务集T中支持度是:T中包含X的事务的比率,称为全集支持度,记为sup(X);而X在约束子集T(ci)中支持度是:T(ci)中包含X的事务的比率,称为子集支持度,记为supT(ci)(X).
对于关联规则AB,A∩B=,其在全集T上的支持度是T中既包含A又包含B的事务的比率,记为sup(AB);而其在约束子集T(ci)上的支持度是T(ci)中既包含A又包含B的事务的比率,记为supT(ci)(AB),如公式(1)所示.规则在全集T上的置信度是T中包含A的事务中也包含B的事务的比率,记为conf(AB);而其在约束子集T(ci)上的置信度是T(ci)中包含A的事务中也包含B的事务的比率,记为confT(ci)(AB),如公式(2)所示.其中, X表示集合X中元素的个数.
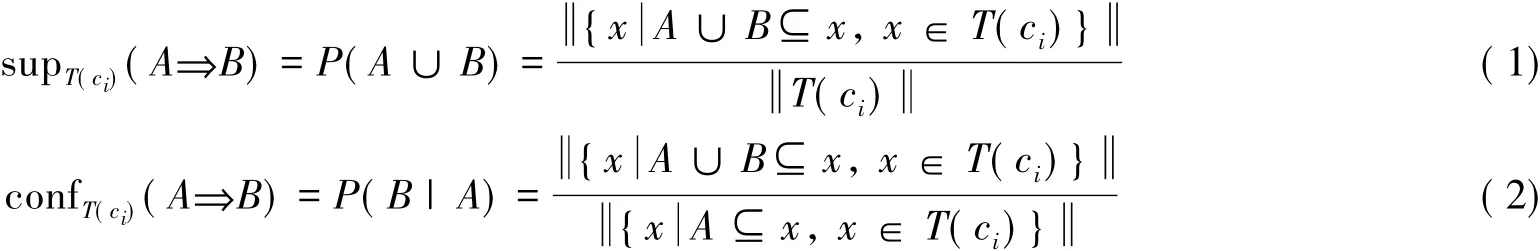
1.2 算法思想
约束关联规则挖掘算法(constrained association rule mining,ConstrainARM)采用三阶段的策略,首先寻找约束条件对应的约束子集,然后在约束子集中寻找频繁项集,最后在频繁项集的基础上产生满足约束条件的关联规则.算法引入约束子集的概念,以满足约束条件的关联规则挖掘为目标导向,同时使用约束条件对待搜索的事务数据集、以及生成的关联规则进行有效剪枝,从而能够降低数据集搜索的时间.
1.3 流程与实现
给定待挖掘的事务数据集T、前因后果约束集C、拟获得的频率最高的项或置信度最大的规则的数目topn,ConstrainARM算法进行约束关联规则挖掘的具体流程如图1所示.
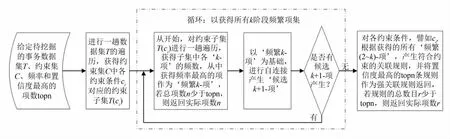
图1 约束关联规则挖掘算法的流程Fig.1 The flow of ConstrainARM algorithm
步骤1遍历事务数据集T一趟,获得约束集中每个约束ci对应的约束子集T(ci).
步骤2对每个约束条件ci关联的约束子集T(ci),进行一趟遍历,获取每个‘项’出现的频数,并获得出现频数最高的topn(用户给定的参数)个项作为频繁1项集L1.若总项数小于topn,则返回实际项数.
步骤3从频繁k项集Lk(k=1)开始,进行k项集的自连接,产生获得候选k+1项集Ck+1;并遍历约束子集T(ci),对Ck+1中的每个元素的出现频次进行计数,从而确定频繁k+1项集;若总项数小于topn,则返回实际项数.递归此过程,直到获得约束子集T(ci)的所有频繁项集.
首先,建立“3T”原则导向下的信息发布制度。 设计科学全面的信息发布制度,是应对网络事件舆情危机的重要举措之一。 传统的由单一部门独立进行信息发布的方法存在着诸多问题,如遇到涉及多主体的事务时会造成部门扯皮、沟通不畅、互相推卸发布职责。 而“3T”原则下信息发布机制的建立,首先建立信息发布常设机构,用以协调各部门联动,对政府发布舆情进行统筹安排。 机构内部依据发布流程设立分部以维持机构运行。 其次,建立与舆情发布相关的专家联系咨询制度,建构发布机构与民众的沟通互动机制,在常设机构下组建一支高素质的舆情发布队伍。
步骤4根据获得的约束子集T(ci)中的所有频繁项集,产生符合ci约束的关联规则,并将置信度最高的topn条规则作为强关联规则返回,若规则的总数目小于topn,则返回实际规则数目.
步骤5循环执行步骤2~4,获得所有约束条件对应的强关联规则.
ConstrainARM算法的核心在于三个步骤.首先,获取约束集C中的每个约束ci对应的约束子集T(ci);然后,在约束子集中进行频繁项集的检索;最后,在约束对应的频繁项集的基础上,根据设置的算法参数,获得满足约束条件的强关联规则.其中,根据频集产生符合约束条件ci的关联规则且约束ci作为规则前件(事件原因)时,条件概率是规则后件xm发生的可能性的大小;当约束ci作为规则后件(事件结果)时,则后验概率是规则前件xm引发结果ci的可能性的大小.根据条件概率公式和贝叶斯后验概率公式可知,约束条件ci作为规则前件或后件时xm发生的可能性相同.因为子集T(ci)中约束ci发生的概率P(ci)=1,因此ConstrainARM算法的核心任务在于获得约束ci与xm的联合概率P(xm∪ci),具体实现方法是在遍历约束子集T(ci)时对项集xm的出现频次进行计数.
2 实验及分析
以福州林景行信息技术有限公司实际运营的望路者旅游文化业务数据集为对象,本节对约束关联规则挖掘在热点旅游线路推荐中的应用进行示范应用研究.
2.1 数据集概况
望路者旅游文化数据集由三张表格构成.第一张:目的地表,遍布我国各省的13 400余个旅游景点的信息;第二张:总行程表,记录了移动端APP应用程序保存的2016年6月1日至2018年4月16日期间游客出行的2 520余条旅游路线信息;第三张:行程每天安排表,记录了每条旅游路线每天的信息,包含第几天、旅游城市、途经的景点等信息.
2.2 挖掘过程与结果
步骤一数据预处理.将望路者旅游文化数据的总行程表和行程每天安排表进行融合,获得2 520条旅游路线途经的景点信息,如表1所示.
步骤二约束关联规则挖掘.以表1汇总数据中每个游客途经的景点为源数据,以福州市国家5A级旅游景区“三坊七巷”为例,以“三坊七巷”为前件的关联规则表示到三坊七巷的游客有很大可能随后会到这些景点;而以“三坊七巷”为后件的关联规则表示到三坊七巷的游客,有很大可能是从这些景点游玩后来访的,置信度的大小则标示了规则可能性的大小.因而,以约束C={{三坊七巷}}、参数topn=12为例,对ConstrainARM算法进行约束关联规则挖掘的流程进行介绍.

表1 旅游行程数据汇总表(部分数据)Tab.1 Summary of tourist itinerary of WCTSNOP(Partial data)
首先,对望路者旅游文化汇总数据(表1所示)进行遍历,获得约束c1={三坊七巷}关联的事务子集T(c1),约束子集中事务的数目 T(c1)=176.
然后,在约束子集T(c1)中进行频繁项集搜索.对k-阶项集,至多获取topn=12个项集作为k-阶频繁项集,最终获得的k-阶频繁项集如表2所示.其中仅列出了支持数超过3的2~4阶频繁项12项,5阶频繁项9项,6阶频繁项1项,各频繁项的支持数见第2列.
最终,根据获得的频繁项集,产生符合约束要求的关联规则,并计算规则在约束子集T(c1)中置信度,对每个约束条件获取至多topn=12个置信度最高的规则作为强关联规则.
根据ConstrainARM思想,以约束c1={三坊七巷}为前件或后件的规则置信度如表2第2列所示.
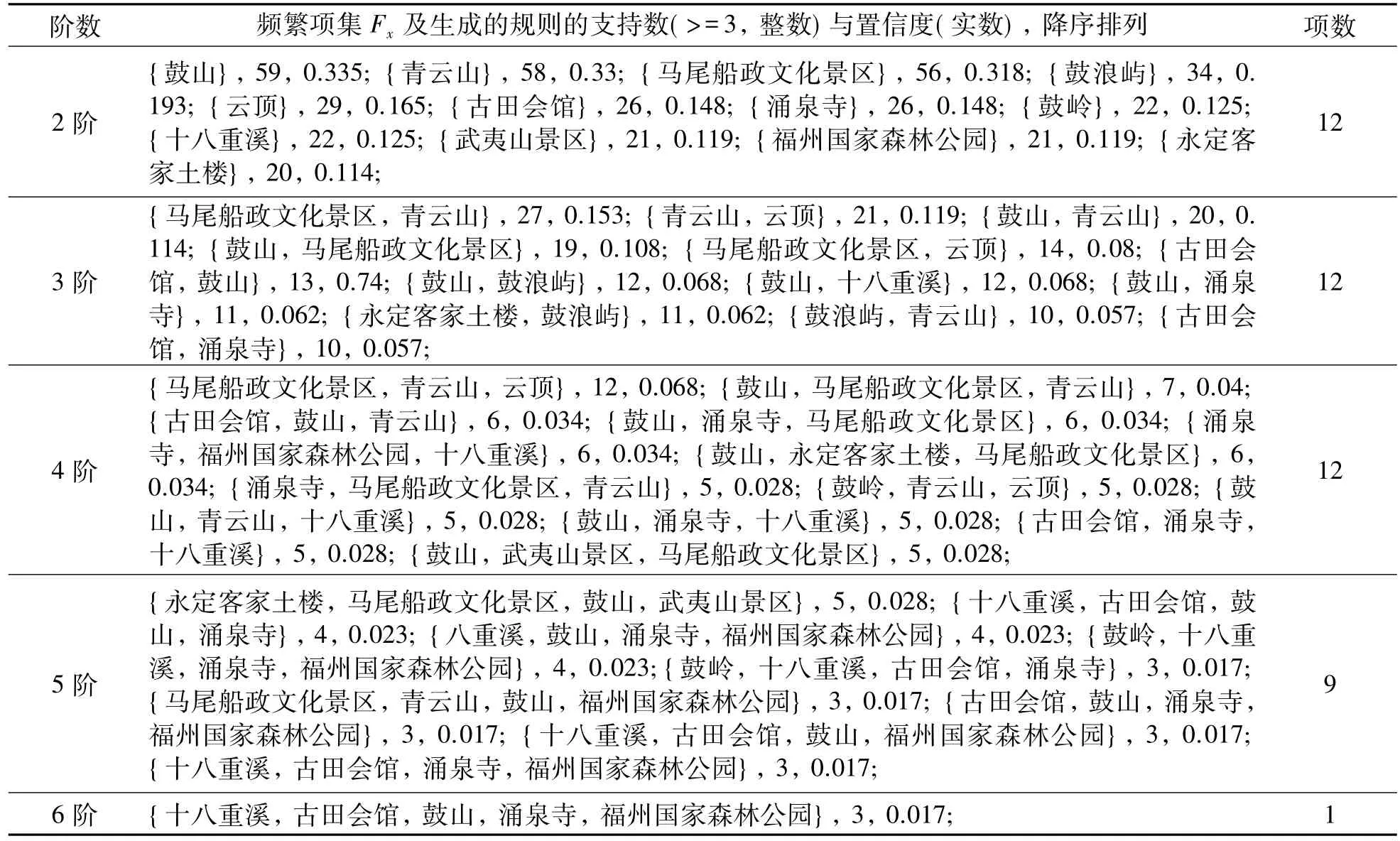
表2 约束子集T(c1)中的频繁项集(约束项c1={三坊七巷}略)Tab.2 Frequent itemsets of T(c1)(c1={三坊七巷}is excluded)
以2阶频繁项为例,参数topn=12条件下获得的关联规则及其支持数和置信度如表3所示.
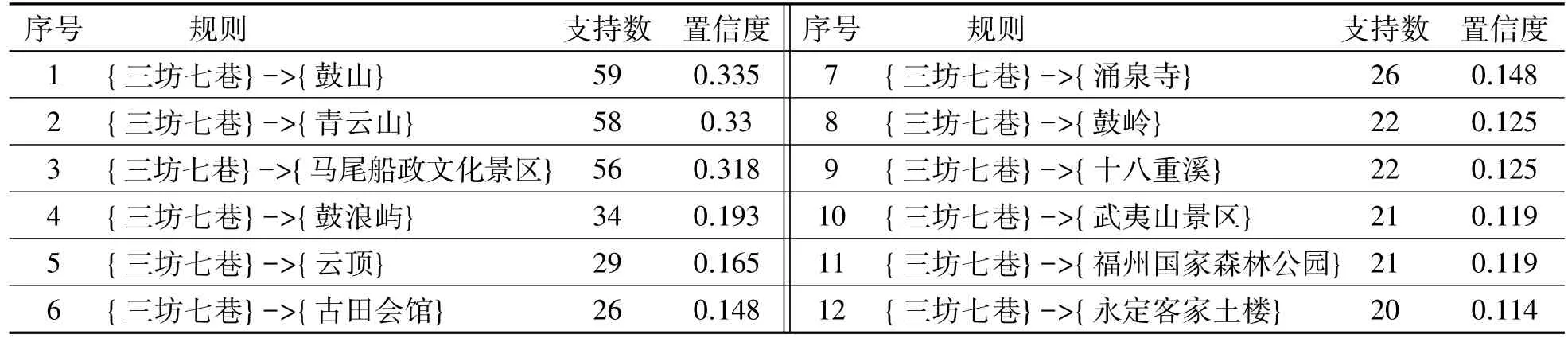
表3 与约束项c1={三坊七巷}最相关的topn=12个景点Tab.3 The topn=12 most closest reated sites for constrained item c1={三坊七巷}
从表3可见,到{三坊七巷}的游客,最有可能去的景点依次是鼓山、青云山、马尾船政文化景区等.因而,对于到访{三坊七巷}的游客,若只想到两个景点游玩,可依次重点推荐这些景点.而从表2可见,若游客计划游览三个景点,那么最优的推荐是{马尾船政文化景区,青云山},其次是{青云山,云顶}.
2.3 分析与讨论
ConstrainARM算法使用约束进行数据筛选、生成约束子集需要遍历一趟数据集,时间复杂度近似为O(c·n),其中c和n分别为约束和事务的数目.根据算法的策略,进行密切相关的k阶项集生成所耗费的时间取决于参数topn,近似为topn!,因而总体时间复杂度约为O(c·n+topn!).
从上述挖掘结果可见,ConstrainARM算法能够正确、可靠地获得符合约束条件的关联规则.以约束c1={三坊七巷}为例,获得的topn=12个景点都是福建省闻名的旅游景点,尤其是鼓山、青云山、马尾船政文化景区、鼓浪屿等景区,每年的游客接待量都名列前茅,可见约束挖掘结果与实际情况较为吻合.
算法层面上,ConstrainARM将数据集遍历限定在约束关联的事务子集T(c1)中,约束子集的规模T(c1)=176相对于数据集大小2 520条具有明显的缩减,因而算法效率具有明显的提高.一方面,由于约束子集T(c1)往往比完整数据集小得多,因而算法能够大大降低频繁项集搜索时多次遍历数据集的大量时间开销,从而显著提高算法的效率;另一方面,由约束引导下的规则生成也具有较为明确的用户目标导向性,避免了大量无意义规则的生成,也在一定程度上提高了算法的效率.
与传统基于频集的关联规则挖掘算法相比,ConstrainARM算法不要求提供支持度sup和置信度conf阈值参数,而要求提供拟获得的频率最高的项或置信度最大的规则的数目topn.此外,算法挖掘的目标不同,传统算法的目标是寻找支持度和置信度高于指定阈值的强关联规则,而ConstrainARM算法目标是寻找符合指定约束的最有可能的至多topn个关联项.再者,算法的挖掘策略不同,传统算法采用k项集自连接的方法产生候选k+1项集,并基于频繁项集产生所有规则,而ConstrainARM算法只针对少数最可能最感兴趣的项进行高阶候选项的连接与生成测试,因而候选项集的规模及其由此消耗的CPU处理时间低得多.
由于传统关联规则挖掘算法和ConstrainARM算法的挖掘目标及其采用的策略不同.因此以Apriori算法为例,对传统算法在支持度sup=0.005,0.01和0.02时的候选与频繁项集数(如表4)进行研究,对支持度sup=0.01置信度分为conf=0.5,0.4,0.3和0.2时算法获得的所有规则和强关联规则数目(如表5)进行研究,并对ConstrainARM算法在参数topn为12和15时候选规则和实际获得的规则数目(如图2)进行研究.从而对两种算法的挖掘效果和挖掘效率进行对比分析.
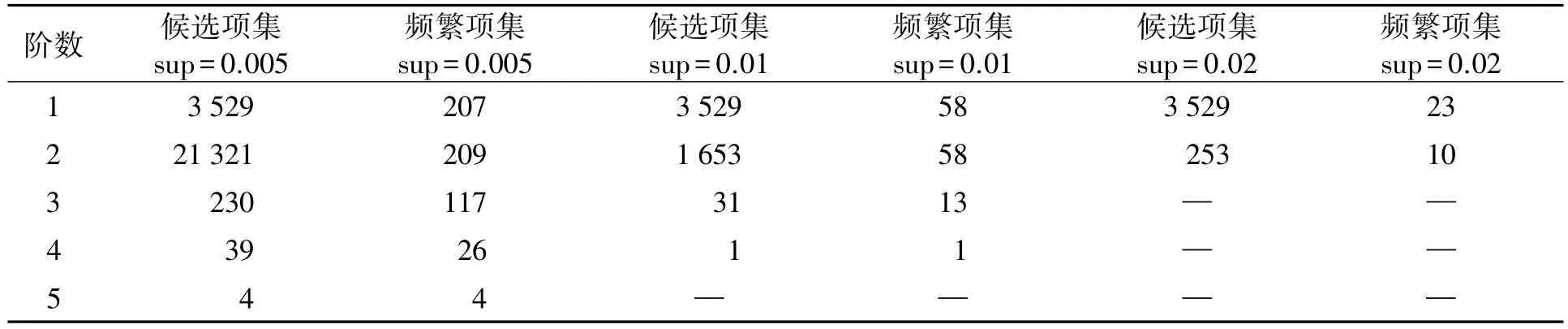
表4 不同支持度时Apriori的候选和频集项集数Tab.4 Ckand Lksizes with different sup for Apriori

表5 sup=0.01和不同置信度时Apriori的规则数Tab.5 Rule numbers with sup=0.01 and different conf for Apriori
从表4可见,传统算法Apriori在频繁项集生成时,将产生大量的候选项集,且随着支持度的降低,候选项集的规模呈指数增长;从表5可见,对支持度sup=0.01时获得的频繁项集,算法Apriori随着置信度阈值的降低,获得的强关联规则数目不断升高.从图2可见,ConstrainARM算法在挖掘topn个置信度最高的规则时,也将产生一定数量的候选规则,但相对于Apriori算法的候选项集,其数目远远来得小.此外,Apriori算法获得的挖掘目标针对性不足,以图2所示的参数sup=0.01和conf=0.4为例,获得的118条强关联规则无一满足约束c1={三坊七巷}的挖掘需求,因其关联的1阶频繁项中,“鼓山”的支持数最高(为59,如表3所示),其在子集T(c1)中的置信度为0.335,并非置信度conf=0.4条件下的强关联规则.换言之,子集上产生的规则,在全局T中的支持度与置信度的值均较低,因而许多与约束c1密切相关的项集往往不是传统算法挖掘的潜在频繁项集,进而无法产生相对应的规则.而为了获得约束相关的规则,往往只能降低支持度和置信度的阈值,那么不可避免地导致大量无效候选项集和规则的生成,从而显著降低算法的挖掘效率.
从上述分析可见,提出的ConstrainARM算法,通过约束条件进行数据剪枝和目标限定,在降低候选项集等算法中间产物规模的同时,提高了挖掘结果的针对性,在个性化旅游路线制定时的景点推荐中具有明显的实际应用价值.
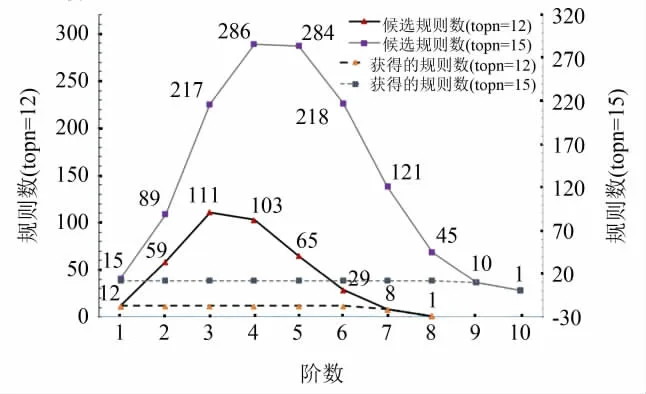
图2 不同topn值时ConstrainARM获得的规则数Fig.2 Rule numbers with differenttopn for ConstrainARM
3 结语
针对个性化旅游景点推荐提出了一个考虑约束的关联规则挖掘ConstrainARM算法,并在福州林景行信息技术有限公司实际运营的望路者旅游文化业务数据集中开展了应用实验研究.结果表明,效率上,算法能够正确获得给定约束条件下的关联规则,且通过提出的约束子集的概念,能够将关联规则挖掘所需的频繁项集搜索限制在规模较小的约束子集中,一定程度上提高了算法的效率;效果上,对于每个景点,即使受游客喜爱的热度不高,但与之最相关的其它景点的获得,能够为到此景点游玩的旅客在制定个性化旅游线路时提供较为科学的决策依据.基于约束多级关联规则的旅游景点联动和旅游路线规划是下一步研究的重点.
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
轴承(2015年2期)2015-07-25
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
