
大数据知识服务平台架构设计及应用研究
2019-07-11 02:48刘晓丹贾利娟
中国锰业 2019年3期
刘晓丹,贾利娟
(陕西广播电视大学,陕西 西安 710119)
大数据知识资源建设具有数据价值密度低、数据结构复杂、数据规模大等特点。2013年我国产生的数据总量是2012年的2倍,超过了0.8 ZB,相当于2009年全球的数据总量。随着技术的发展我国的数据总量将会持续增加,估计2020年的数据总量将会超过8.5 ZB是2013年的10倍[1],因此,开展大数据知识服务势在必行。在开展大数据知识服务过程中,需要采用信息技术对各种结构化、非结构化、半结构化的数据进行多维的分析和处理,这是一个难题。当前关于大数据知识服务的研究主要体现在大数据知识服务理念和体系、大数据知识服务方法、大数据知识服务应用3个方面。李晨晖等[2]研究了大数据知识服务运行机理、平台构建及其中涉及到的关键技术。ZHANG Junbo等[3]提出了基于并行大规模粗糙集的大数据有效知识挖掘的方法,该方法采用MapReduce编程模型,并对提出的方法有效性进行了验证。CAI Dongfeng等[4]应用大数据处理技术设计了知识服务平台,促进了我国大数据知识服务平台的发展。实际上,大数据知识服务中对数据的处理技术还存在一定的缺陷,但是和国外相比,我国的大数据知识服务应用方面还不成熟,需要继续深入分析和探索。因此,应该加强大数据知识服务平台的建设及创新应用研究。
1 大数据知识服务平台架构设计
1.1 大数据知识服务平台网络架构
大数据知识服务平台主要是为用户提供大数据知识服务,通过信息化服务节点和无线传感器网络对大数据进行采集,通过服务终端自适应接入技术对大数据知识服务网络进行设计,通过互联网终端如手机、IPAD、便携电脑等实现用户的数据管理、数据存储及数据挖掘分析等服务需求,最终帮助用户获得有价值的信息,面向用户的大数据知识服务平台总体网络架构图见图1,主要应用的网络技术包括WIFI、4G/3G/2G、EtherNet、IrDA、BlueTooth、ZigBee技术等。

图1 面向用户的大数据知识服务平台总体网络架构
1.2 平台体系架构
当前海量的知识数据分析需要投入大量的人力和物力,是一项非常复杂的工作,随着技术的发展出现的面向用户的大数据知识服务平台降低了数据分析的人力和物力成本,缓解了数据资源的急剧增长与用户数据需求之间的矛盾。该大数据知识服务平台适用于大数据背景下的信息检索系统,聚合了对结构化数据、非结构化数据、网络资源及本地资源等不同的数据资源,并对数据进行结构归一化处理,用户根据自己的信息需求采用合适的检索方法和聚类算法以实现数据的准确和高效查询。构建的大数据知识服务平台包括服务层、功能层、平台层,整体平台体系见图2。
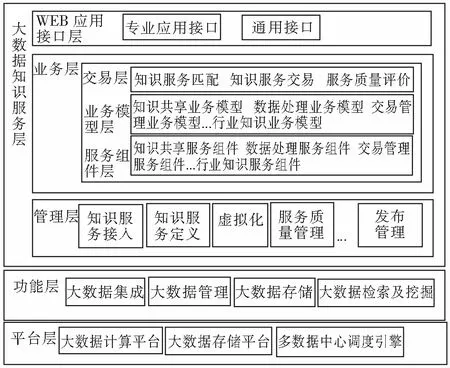
图2 大数据知识服务平台的体系架构
1.3 平台的技术架构
构建的大数据知识服务平台整合了Hadoop分布系统、大数据搜索引擎系统、数据库系统、MapReduce知识检索技术、云计算技术等,技术架构见图3。

图3 大数据知识服务平台技术架构
平台层采用Hadoop大数据处理框架作为技术支持,主要功能为数据的存储和读取,基于Hadoop集群分布进行构建,平台中选择的数据库为MySQL,文件系统包括HDFS及本地Linux文件。本地数据文件上传到HDFS文件系统之后,通过MapReduce的并行相关算法进行数据的分析、处理和挖掘,再将处理结果复制到本地Linux系统文件中,文件解析之后导入MySQL存储。
功能层主要由基于MapReduce的并行相关算法引擎和Tomcat网站服务器组成,Tomcat服务器主要面对Web应用层,Web应用层的请求通过Struts2拦截,拦截之后针对不同的需求实现不同的响应处理。基于MapReduce的相关并行算法,如K-Medoids、K-Means等,主要的实现方式是:针对平台层构建的Hadoop集群,将数据文件的存储目录输入到HDFS文件系统中,调用基于MapReduce的并行算法、MapReduce模型(Hadoop编写)进行HDFS输出目录的计算、分析、整理,挖掘得到强关联规则存储在MySQL数据库中。
服务层提供应用接口及Web界面操作,接收用户的请求,方便用户获得需要的大数据服务信息,前台页面的编写主要采用JavaScript、JSP、HTML等相关技术,并采用了Web开发框架Struts2,实现Web页面在Tomcat网站服务器上的部署。发送相应的请求被功能层的Struts2拦截器拦截,功能层模块计算分析处理之后与平台层实现数据交换,处理结果在前台页面通过HTML或者JSP展现。
上述的3层结构具有以下优点:
1)层与层之间的耦合性不高,开发者可以不必进行解耦工作;
2)增加了代码的封装性和重用性;平台的逻辑清晰,方便扩展或修改原有的功能;
3)方便平台的后期维护。
2 K-Medoids聚类算法改进
知识捜索主要是实现知识从属关系、层次关系及学科性质等的汇总分类,然后根据设置的关键词、关键字等提取相关信息,提高知识获取的准确度及速度。K-Medoids聚类方法由于K值不好估算造成分类困难,因此,该平台对K-Medoids算法进行改进,构建了基于K-Medoids和KNN算法的聚类算法。
2.1 K-Medoids算法过程
假设符合条件的、输出的聚类结果为K个,一般使用绝对误差标准函数C衡量聚类效果,见公式(1):
(1)
式(1)中,C值的大小受到簇内每个对象到中心点之间的距离的影响,值越大说明簇中的相似类越低,k代表簇的数目,si代表聚类中心的第i个簇,x代表簇si中的任意对象。
K-Medoids算法过程如下:
1)从n个数据集中,选k个对象作为聚类的初始中心点;
2)计算不同点与质心之间的距离;
3)将点划分到与他距离最近的质心的类,形成K个cluster,重新计算每个cluster的质心;
4)反复2)、3)步骤,直到类收敛。
2.2 KNN算法
KNN算法进行特征提取,有如下假设:
1)知识信息都是相对独立的,其位置不影响出现的频率;
2)通过抽取映射分组,将知识信息分成U1,T1;U2,T2;…UN,TN组别;
3)知识分组的训练集为C,C中有M个对象,N个不同的类别V1,V2,V3,…,VN;
4)降维之后表示为Wi={a1,a2,a3,…an}T,其中0 在特征提取阶段,根据特征向量,将没有进行分类的知识信息W表示为:W={a1,a2,a3,…an}T;再次从C训练集中提取出与W具有最高相似度的训练集知识信息。 Wi={a1,a2,a3,…an}T,得到知识信息的局部相似性分类,最后将W归属在分类知识信息中。根据向量夹角余弦公式实现待分类知识信息和训练集的计算,公式表达式为: (2) 根据K临近值,可计算分类信息W与不同类之间的所属关系,公式为: (3) 由公式(3)得到Vm,其中包含了等分类的信息文本W。 K-Medoids聚类算法改进就是在聚类过程中同时采用K-Medoids和KNN算法实现大数据集知识信息的二次聚类处理。 1)随机抽取数据集中的数据,获得样本集W1,W2,W3,…,Wm,以这些样本集作为原始聚类中心点。 2)应用K-Medoids算法公式(1)实现样本集的聚类处理,并将每个聚类标记为C1,C2,C3,…Cm。 3)反复从训练集W中计算样本的相似类,获得最大相似度的文本。 4)得到初始聚类之后,利用KNN算法对类收缩进行计算,将增长缓慢不能形成类的数据剔除,重新对聚类中心进行调整。 5)重复1)~4)步中的相关操作,直到将所有的数据全部归入类中,最终形成M个类。 基于软件环境和硬件环境搭建好大数据知识服务平台的总体框架之后,其关键模块实现如下所述。 研究中首先需要搭建Struts2框架(Java模型—视图—控制器(MVC)框架)的开发环境,具体步骤如下。 1)选用的Struts版本为2.3.15.1,需要将freemarker-2.3.19.jar、commons-logging-1.1.3.jar、commons-fileupload-1.3.jar、commons-io-2.1.jar、xwork-core-2.3.12.1.jar、ognl-3.0.6.jar、struts2-core-2.3.15.1.jar等运行库文件复制到工程的WEB-INF下的lib文件夹中。 2)在WEB-INF目录下web.xml文件中配置FilterDispatcher。Struts2的核心控制器FilterDispatcher设计成过滤器,设计时采用 3)配置struts.xml。struts.xml文件的主要功能是Struts2应用中各个Action的具体实现逻辑,为Struts2框架的核心配置文件。 用户登录时需要和MySQL数据库进行连接,并且输入用户名和密码之后进行验证,验证时,将用户输入的相关信息传递到后台,然后从数据库中查找匹配的用户名和密码,如果匹配成功则登录成功,否则用户需重新登录或注册。 用户登录部分代码如下: public String login(){ int level =userService.checkLogin(username, password); if(-1==level){ session.put("username",username); return "home";//用户名和密码验证成功 } info="用户名或密码错误!"; return "login";} 大数据知识服务平台采用改进的K-Medoids聚类算法对结构化、非结构化及其他数据进行二次整理,形成可靠的信息数据存储在大数据存储平台,也就是数据库中。用户登录平台之后,对数据进行查询,平台根据用户需求通过大数据技术、知识聚类技术等手段,通过智能搜索引擎实现数据信息深度挖掘,以此满足大数据背景下用户对知识的需要。 在对大数据知识服务平台进行应用分析时,系统环境如下:处理器为Intel(R)Core(TM)i5-5200 U CPU@2.20 GHz,内存容量4.0 GB,windows 7 64位操作系统,采用Tomcat服务器搭建运动环境。选择某所高校的图书馆馆藏编目数据作为实验数据,大约具有30余万条元数据条目,包含了法律、环境科学、经济、生物等22个基本大类的知识数据,其中也包含了数字期刊、电子图书中的文本数据,平台测试之前已经建立数据库系统的索引目录,输入“计算机”一次,采用上文提出的算法进行检索。应用改进的K-Medoids算法,分类效果较精确,检索效率更高,这说明该平台的应用效果较好。 随着信息技术的发展,互联网应用、传感网络及电子商务等应用领域的数据量呈现出飞速增长,大数据已经成为研究和关注的热点,大数据知识服务也越来越重要。国内关于大数据知识服务平台的研究还处于起步阶段,还需要进一步对平台的功能进行研究和探索。本研究提出的大数据知识服务平台还应用过程中可能还会存在一定的问题,今后的研究中需要不断对平台功能进行完善。2.3 K-Medoids聚类算法改进
3 大数据知识服务平台关键模块的实现
3.1 Struts2框架的实现
3.2 用户登录的实现
4 大数据知识服务平台应用分析
4.1 大数据知识服务平台应用处理流程
4.2 应用分析
5 结 语
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
小学生学习指导(低年级)(2021年12期)2021-12-31
中国交通信息化(2020年11期)2021-01-14
湖北农机化(2020年4期)2020-07-24
中国交通信息化(2020年12期)2020-02-06
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
雷达学报(2017年6期)2017-03-26
现代防御技术(2016年1期)2016-06-01
互联网天地(2016年1期)2016-05-04
