
大数据文件存储策略探索
2019-07-15 01:02屈美娟付良廷
科技创新与应用 2019年12期
屈美娟 付良廷

摘要:大数据给各行业带来新的发展机遇,面对各种复杂数据处理需求,高效的数据存储是影响大数据应用的重要因素,不仅决定了数据写入效率,还会影响数据读取。文章提出一种基于HDFS的写预处理存储系统,针对大数据应用中复杂数据写请求,使用聚类策略和文件拆分算法,对文件进行预处理,同时提高数据读取效率。通过仿真实验表明,能有效提高文件存储的写吞吐。
关键词:存储;大数据;写缓存
中图分类号:TP311.13 文献标志码:A 文章编号:2095-2945(2019)12-0140-03
1概述
以互聯网发展为依托的人工智能和物联网技术,在改变生活方式的同时,也带来了数据规模的持续攀升,加速了数据集的增长态势。据统计,Baidu搜索引擎需要每天处理数据集达100PB,Facebook每天新增600TB数据。如何对这种超大规模数据进行有效存储和高效查询,已经成为人工智能和物联网应用的各行业普遍面临的突出问题。如何构建一套应用于大数据存储系统,能够在存储性能、功能、稳定性、易用性等方面均有良好表现,是大数据存储与管理面临的重要问题。
本文在借鉴现有研究的基础上,提出一种基于HDFS的写缓存存储系统,该系统在HDFS存储上层构建写缓存层,在该层中对客户端发出的写请求文件进行预处理工作,以形成固定大小文件,来简化存储过程,提高存储效率。在预处理阶段,依据数据访问关联度和关键字分组策略构建预处理算法,按照存储标准文件大小,对文件进行预处理,以形成固定文件大小,一方面提高存储效率,另一方面,便于还原原始文件,减少后期文件查询的时间和系统开销。
2设计思想
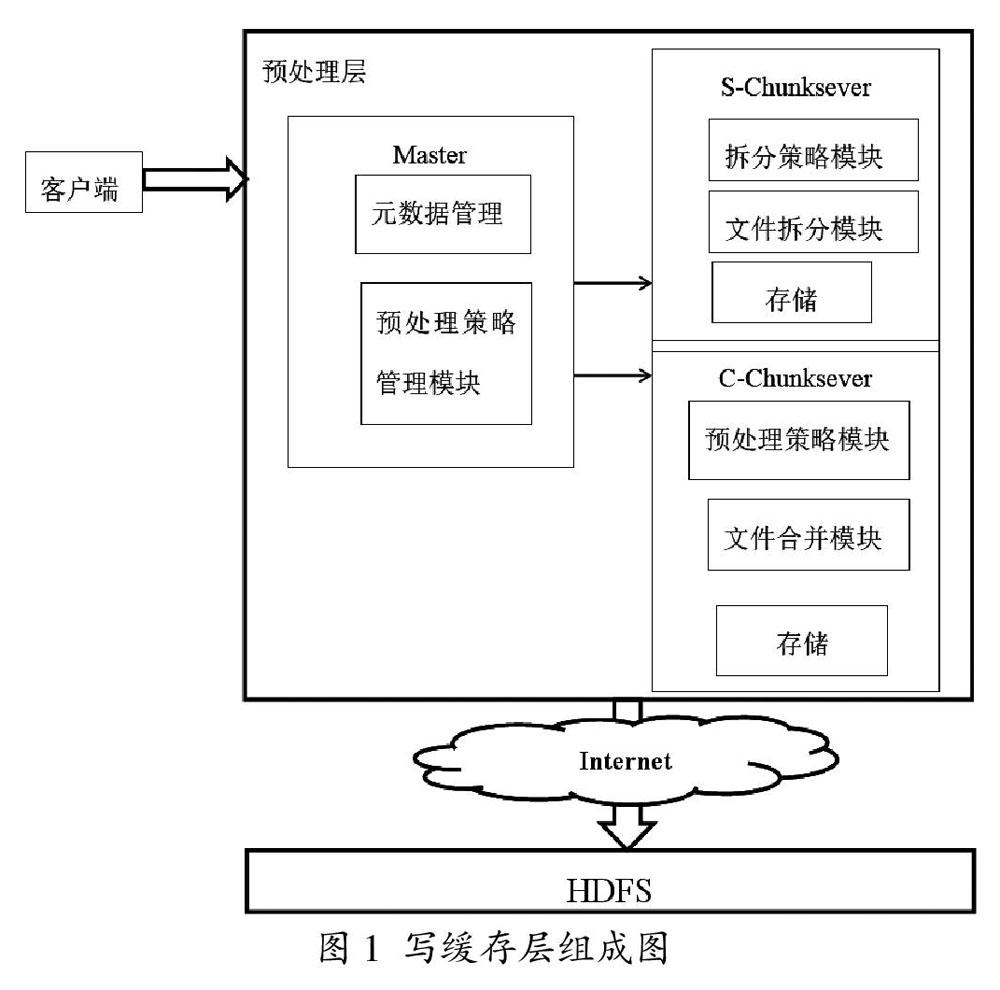
在大数据存储系统中,面对不同大小文件复杂存储请求,系统应能够灵活针对各自特点选择合适的存储策略,一方面提高存储性能,另一方面优化文件存储管理和访问。在大数据应用中,文件类型和文件大小丰富多样,但归根结底都是以文件形式存储的。本文将针对文件存储系统设计基于HDFS写缓存预处理的大数据存储系统,在数据写入HDFS前,先经过预处理层,以合理组织元数据,提高数据写入效率和访问性能。写缓存层具体设计组成如图1所示。
写缓存层包括一个主节点(Master)、文件合并模块(C-Chunkserver)、文件拆分模块(S-Chunkserver)。主节点硬件设置为高性能读写服务器,负责监听客户写文件请求、分配缓存节点、管理元数据,根据负载情况分配预处理节点,同时记录元数据。分配缓存节点包括两部分:主节点和备份节点,主节点对数据进行预处理,副节点完成数据异步备份。客户发出数据写入请求后,Master根据文件大小依据预处理策略,选择文件拆分或合并模块分配预处理节点,预处理完成后存入缓存模块中,再采用多线程写入HDFS中。
3实现算法
3.1小文件聚类策略
对于小文件写入HDFS,要进行聚类合并。本文使用聚类策略为MFCR(Most Frequent Conbin Read)最常读取组合策略,基本思想为,由Master维护一个n*n二维表MFCR表,其中n为最常读取数据的客户机个数,用这个二维表来记录客户机数据组合查询情况。文件合并模块中每个主机设置一个标志信息,标识目前该主机目前已缓存数据客户机编号。二维表中各CR系数(Conbin Read)初始化为0,当查询结果来自客户机s和客户机t时,执行CRst=CRst+1操作。当缓存层Master监听到来自客户主机a发出的写文件请求时,判断文件为小文件需要合并后,同时遍历MCR系数表并询问各chunkserver状态,找到最大CRab,其中b为chunksever中目前待合并数据客户主机编号,将该chunksever编号返回给主机a,建立a主机与该chunksever连接,开始传输合并数据。在系统初始阶段,MFCR表值为空,此时有客户机发出数据存储请求后,根据负载情况分配主机。
3.2大文件拆分算法
对于结构化的大数据,需要将数据拆分为若干个子表,以方便后期管理维护和查询等。当主节点接收到结构化数据的写请求后,由主节点中数据拆分模块完成数据分解,根据负载情况分配存储副本节点,再由副本节点执行递归算法,对文件大小进行二次判断,对超出阈值的文件进行二次分解,直至所有文件大小在写入缓存阈值范围内,最后由各副本节点异步写入缓存。本设计中对于结构化大数据拆分,采用基于列存储的关键字分组策略。设置数据集为D,用于分组的关键字组合为K={K1,K2……Kn},分组时,先依据K1对数据集划分,然后依据K2取值不同在K1分组的基础上继续分组,以此类推,直至分组结束。分组过程如下:
(1)设置分组基数g和分组系数入i,两者乘积得到每个关键字分组数量gi。根据查询频率,为总表中每个关键字制定分组系数,用来确定每个关键字分组个数,应用于查询频率越高,分组系数越高,基于改关键字的分区粒度越细。
(2)获取分组边界值。确定基于第ki关键字分组数目之后,需确定各组之间取值范围,根据ki关键字的不同取值,将数据集划分为gi组数据。
如何确定分组边界值,是决定合理拆分数据的关键因素。为了提高分组效率并减少分组工作系统开销,采用随机采样的方法,来确定分组区间边界值。取样过程类似滑动窗口,过程如下:
(1)根据数据集和写入HDFS标准文件大小,确定抽样记录数量Stotal。
(2)确定抽样点个数Sgroup,即滑动窗口滑动次数。
(3)确定每个抽样点附近抽样记录数量Sno,即滑动窗口宽度,则三个数量之间关系为Sno=Stotal/Sgroup。
(4)在0和数据集记录总数之间获取Sgroup个随机值。
(5)以每个随机值为起点,读取Sno条记录,读取每个记录的各个关键字取值,取样完成后形成的采样二维表,将具有Stotal条记录,每条记录包含分组关键字{K1,K2……Kn}的n个值。
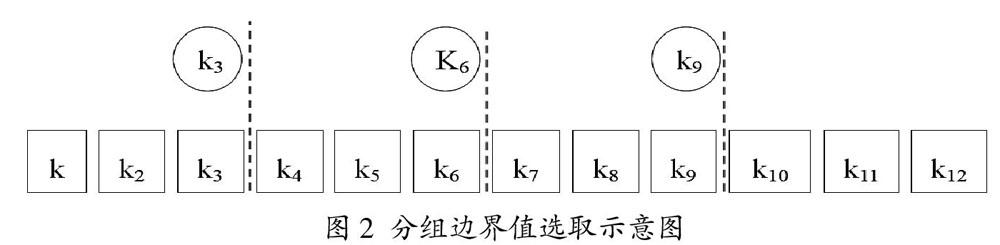
(6)对采样二维表每列数据执行:排序并确定gi-1个分组边界值。举例,假如取样总数Stotal=12,对于K3关键字取值g3=4,则分组边界值选取过程如图2所示。
使用分组边界值,依据数据集中记录ki取值,对数据进行分组。i取值从1至n,完成整个数据集初步分组。
(7)对于完成初步分组的数据子集组合{D1,D2……DT},其中T=∏in=1gi,使用递归算法使所有拆分后文件都满足写入缓存文件大小要求,递归算法执行过程为:若存在Dt文件大于标准文件,则按照标准文件大小截取数据子集前面部分为Dt,剩余部分标记为Dt+1,然后再对Dt+1进行判断,直至所有文件大小符合写要求。
4实验分析
本次仿真实验目的是比较直接写入HDFS和使用写缓存层的HDFS两种方法下,以标准文件大小为准,设定多组不同大小文件大小,比较两种存储系统写吞吐对比。仿真实验环境搭建方式为20台仿真主机作为客户端发送数据,1台仿真服务器作为Master,合并和拆分预处理模块分别使用10仿真主机,20仿真主机作为HDFS存储。
4.1小文件写入测试
实验数据分别由客户端发送大小为10KB-500KB文件写请求,每次发送文件总数目设置为100000个,来进行仿真实验测试。在此情况下,对比本设计和直接写入HDFS写吞吐对比,实验结果数据如图3所示。
通过实验结果可以看到,本系统在处理小文件方面性能较好,但随着文件增大,当文件超过一定阈值(1MB)后,写入速度会出现瓶颈,这是因为在处理非结构化数据的时候,本设计中的写缓存层在花费系统开销再存入HDFS并没有减少写入时间,没有发挥出写缓存的作用。
从图中可以看出,直接使用HDFS存储时,随着文件增大,写入文件耗时也增大,当文件增大到一定程度时,所耗费时间急速增长,对于较大文件写入时间较长。在对文件进行拆分处理后再存储,消耗时间也随着文件增大而延长,但增长速度较缓慢。同时,当文件较小时,由于分组会带来系统开销,因此降低了效率。从图中可看到,30GB文件存储时间大于40GB文件,这是由于本次试验分组参数设置导致。
5结束语
本文提出一种基于HDFS的存储方法,针对大数据应用中不同数据特点,提出针對性存储策略,对于小文件应用基于访问关联度的聚类策略,对大数据提出基于列存储的关键字分组策略,同时采用多线程写入数据,提高了数据整体写入速度。
猜你喜欢
科学与财富(2016年26期)2016-12-01
电脑知识与技术(2016年21期)2016-10-18
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
