
基于文本与视觉信息的细粒度图像分类
2019-08-08 07:40袁建平陈晓龙陈显龙何恩杰张加其高宇豆
图学学报 2019年3期
袁建平,陈晓龙,陈显龙,何恩杰,张加其,高宇豆
基于文本与视觉信息的细粒度图像分类
袁建平1,陈晓龙1,陈显龙1,何恩杰1,张加其2,高宇豆2
(1. 北京恒华伟业科技股份有限公司,北京 100011;2. 华北电力大学控制与计算机工程学院,北京 102206)
一般细粒度图像分类只关注图像局部视觉信息,但在一些问题中图像局部的文本信息对图像分类结果有直接帮助,通过提取图像文本语义信息可以进一步提升图像细分类效果。我们综合考虑了图像视觉信息与图像局部文本信息,提出一个端到端的分类模型来解决细粒度图像分类问题。一方面使用深度卷积神经网络获取图像视觉特征,另一方面依据提出的端到端文本识别网络,提取图像的文本信息,再通过相关性计算模块合并视觉特征与文本特征,送入分类网络。最终在公共数据集Con-Text上测试该方法在图像细分类中的结果,同时也在SVT数据集上验证端到端文本识别网络的能力,均较之前方法获得更好的效果。
计算机视觉;细粒度图像分类;场景文本识别;卷积神经网络;注意力机制
图像分类是计算机视觉领域的一个经典研究课题,其中细粒度图像分类是一项极具挑战的研究任务。不同于一般粗粒度图像分类任务,细粒度图像的类别精度更加细致,类间差异更加细微,往往只能借助于微小的局部差异才能区分出不同的类别。与人脸识别等对象级分类任务相比,细粒度图像的类内差异更加巨大,存在着姿态、光照、遮挡、背景干扰等诸多不确定因素,分类任务难度较大。而细粒度图像分类无论在学术界还是工业界都有着广泛的研究需求与应用场景[1]。例如在生态保护中,需要有效识别不同种类生物,之前都只能依赖专家知识,研究成本大。如果能实现低成本细粒度图像分类,那么无论对学术界还是工业界都有非常重要的意义。
对于细粒度图像,能够帮助图像分类的信息往往只存在于很细小的局部区域中。因此,如何找到并有效利用有用的局部区域信息,成为了决定细粒度图像分类算法成功与否的关键所在。早期的方法严重依赖人工标注信息,包括标注框(bounding box)和局部区域位置(part locations)等,同时使用了人工提取的图像特征,很大程度上制约了该算法的实用性。近年来,深度学习日益发展,使得之前很多研究问题有了新的解决方法。越来越多的研究不使用标注信息,仅仅使用图像标签来进行图像分类,并且从深度卷积神经网络(deep convolution neural network,DCNN)中提取特征,比人工特征拥有更强大的描述能力[2]。之后DONAHUE等[3]提出DeCAF,将大数据集上训练的深度神经网络迁移到小数据集上再训练,结果在鸟类数据库图像细分类任务中表现不错。在使用深度学习方法基础上,一些图像细分类问题中,局部信息包含大量与图像类别之间有关联关系的文字,因此本文将图像视觉信息与图像中局部文字信息结合,共同参与细粒度图像分类。同时图像文本之间有一定的语义信息,而该信息能够更好地反映图像的类别。
本文设计了一个端到端的训练模型,帮助进一步提升图像细分类的效果。模型首先使用DCNN提取图像的视觉信息,再利用基于注意力机制的文本识别网络从图像局部区域(图像的文字区域)提取文字信息,然后使用双向循环神经网络学习文本之间信息,计算文本行与图像相关性,剔除不相关文本串,最后结合视觉特征信息与文本特征信息获得图像最终的分类结果。
1 相关工作
1.1 图像分类
由于卷积神经网络(convolution neural network,CNN)在图像问题上具有天然优势,加上最近几年DCNN的快速发展,出现了很多优秀的卷积网络模型,使得基于DCNN的图像分类算法效果越来越好。虽然CNN模型对于粗粒度的图像分类可以获得很好的分类效果,但是对于细粒度图像分类目前仍然是一个具有挑战性的任务。目前对于细粒度图像分类问题,主要分为基于强监督信息和弱监督信息2类模型。其中基于强监督信息的细粒度分类模型,如:基于部分的区域卷积神经网络模型(part-based regions with convolution neural network,Part-based R-CNN)4],该模型利用R-CNN算法对细粒度图像进行物体级别(如鸟)与其局部区域(头、身体等部位)的检测,但Part-based R-CNN在训练和测试时都需要借助边界框和标注点,限制了其在实际场景中的应用。基于弱监督信息的细粒度图像分类模型,如:基于整体与部分两层的注意力模型(two level attention model)[5],主要关注物体主体和部分2个不同层次的特征,同时模型并不需要数据集提供标注信息,完全依赖于本身的算法来完成物体和局部区域的检测。最近提出的一种基于弱监督信息分类模型(object-part attention driven discriminative localization for fine-grained image classification,OPADDL)[6]不需要大量边界框与标注点即可检测到目标区域,同时保持了对象主体与部分之间的关联性,防止生成的多个部分包含大量背景区域的同时,又防止区域之间互相严重重叠。这些工作对细粒度对象分类有一定的帮助,但并未考虑将图像中的文本信息用于图像分类。文献[7]虽然将视觉信息与文本信息结合应用到图像细分类问题中,并提出一个端到端的分类网络获得较好的效果,但是只考虑到图像中单词与图像之间的关系。本文在其模型基础上做出改进,将图像中的文字之间的关系考虑进来,进一步提升模型细分类的能力。
1.2 文本检测与识别
文本检测与识别问题在深度学习方法出现之前,手工提取特征为主要解决问题的思路。期间组件级别(如笔画宽度变换,stroke width transform,SWT[8]),最大极致稳定区域(maximally stable extremal regions,MSER[9])、字符级别[10]都是通过手工定义特征,包括基于连通区域的方法,以及基于方向梯度直方图(histogram of oriented gradient, HOG)特征的检测框描述方法。而深度学习方法之后,摆脱了手工定义特征繁琐的工作,使得效率获得很大的提升。目前文本检测模型在深度学习中主要基于建议区间与基于图像分割2种方向。其中前者使用比较广泛。
在基于建议区间的方法中,如:基于联结主义的文本区间建议网络(connectionist text proposal network,CTPN)[11]、基于快速区域卷积神经网络(faster regions with convolution neural network,Faster R-CNN)的方法,针对文字形状和一般物体形状的区别,实现了文字水平方向上非常好的识别效果。文献[12]实现了文本端到端的识别,提出了针对文字串的对称性特征,与传统方法不同,不通过检测字符、笔画来确定文字区域,而是直接检测文字串,但该方法速度很慢。而文献[13]将Faster R-CNN中的感兴趣区域池化层(regions of interest,RoI pooling)替换为可快速计算任意方向的模块,对文本进行自动处理,提升了检测速度。另有文献[14]考虑到文本在图像中更多的是不规则多边形轮廓,提出在生成建议框之后回归一个任意多边形而不是去回归一个矩形框,并且在单方向多框架检测(single shot multi box detector,SSD)[15]的框架基础上,将回归边界框和匹配都加入到网络结构中,取得了较好的识别效果并且兼顾了速度。基于图像分割的方法中,同样有很多不错的方法。比如,文献[16]将文本行视为一个需要分割的目标,通过分割得到文字的显著性区域(salience map),获取到文字大概位置、整体方向及排列方式,再结合其他特征进行高效的文字检测。同时CNN可以同时预测字符的位置及字符之间的连接关系,这对定位文字具有很好的帮助。在实现文本端到端的识别问题中,目前文献[17]获得了较先进的结果,其基于Faster R-CNN将文本检测网络与文本识别网络整合到一起,实现端到端的文本识别,同时将注意力机制[18]用于自己的文本识别网络中。本文在文 献[17]提出的识别模型基础上,将文本检测网络CTPN与基于注意力(attention)的序列到序列文本识别网络整合设计,提出一种端到端的文本识别网络,用于提取图像中的文本信息。
1.3 注意力机制
在引入注意力机制之前,图像识别或语言翻译都是直接把完整的图像或语句直接输入,然后给出输出结果。如果图像缩放成固定大小,便会引起信息的丢失,为此引入注意力机制使得模型关注更加感兴趣的地方[19]。注意力机制广泛应用于多个领域,如自然语言处理、语音识别、机器翻译、文本识别等,目前大多数注意力模型都附着在编码-解码(encoder-decoder)框架下,如文献[20]将注意力机制用于文本识别方面,使用的就是这样的架构。在文本处理和语音识别方面,encoder 部分通常采用循环神经网络(recurrent neural network,RNN)模型,图像处理方面一般采用 CNN 模型。同时注意力机制也在计算机视觉领域中引起越来越多的关注。在计算机视觉领域,注意力机制有各种不同形式的实现,可以大致分为软注意力机制(soft attention)和硬注意力机制(hard attention)。Soft attention如文献[18],其是可微的,可以通过反向传播训练。而Hard attention 需要预测关注的区域,通常使用强化学习来训练。在文献[7]中引入注意力机制自动分析文本与图像之间的相关性,有助于选择图像中相关性最大的单词来进行细粒度的分类。本文在文本识别网络与文本相关性计算都应用注意力机制,在文本识别中,主要目的是快速学习文本序列,而文本与图像关系中,主要是学习与图像相关度最大的文本,去除图像本身或文本识别过程中的噪音。
2 视觉与文字信息融合分类模型
本文模型主要分为视觉特征提取、端到端文本识别与基于注意力机制的文本相关性计算3个模块。模型主要架构图如图1所示。
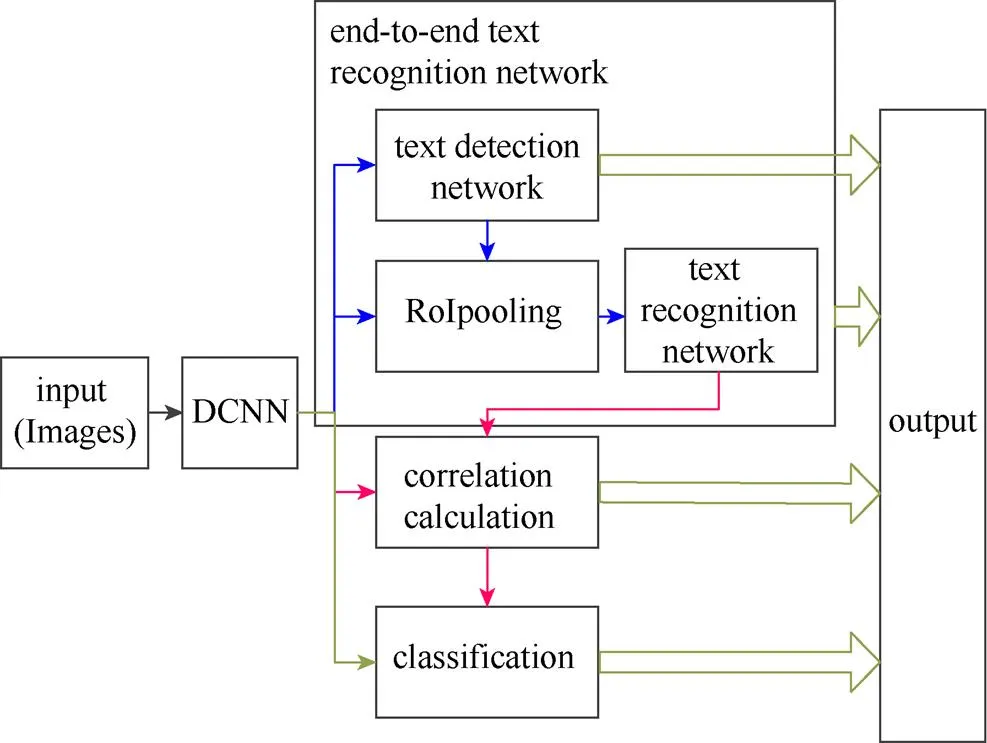
图1 模型主架构图
(1) 使用预训练的DCNN提取图像的视觉特征,同时为了最大程度减少计算量,该视觉特征又共享到文本识别网络与最后的分类网络中。其中在视觉特征提取模块中,本文使用预训练的DCNN模型,但只保留特征提取部分。
(2) 视觉特征传输到端到端的文本识别网络(end-to-end recognition network),不同于一般的文本识别网络将文本检测与文本识别分开,在本文中使用一种端到端的网络结构。该网络以CPTN[11]网络结构为基础,添加基于注意力的文字识别网络,完成对图像文字的端对端识别。文本检测网络(text detection network,TDN)模块主要实现图像的文本检测,RoI pooling主要将检测到的文本区域与视觉特征结合,并送入文本识别网络(text recognition network,TRN)模块进行文本识别。
(3) 将识别到的文本行信息送入相关性计算模块(correlation calculation)中,模块给出文本与图像的相关权重,同时去除识别噪声。
(4) 将图像视觉信息与文本信息共同送入分类网络,获得最终的图像分类结果。
2.1 深度卷积神经网络提取视觉特征
视觉几何组网络(visual geometry group net,VGGNet)是从亚历克斯网络(Alex-net)发展而来,其在基础的DCNN上做了改进,使用更小的滤波器尺寸和间隔,同时在整个图片和多尺度上训练和测试图片。其中使用多个小尺寸滤波器组合相比一个大尺寸滤波器效果要好。主要表想在:
(1) 多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。
(2) 若所有的数据有个通道,那么单独的7×7卷积层将会包含7×7×=49个参数,而3个3×3的卷积层的组合仅有个3×(3×3×)=27个参数。由此可以看出选择小滤波器的卷积组合更能表示特征。
(3) VGGNet中使用了1×1的滤波器,能在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,进而增加网络的非线性表达能力。
正是由于其在少量参数下模型优秀的表征能力,本文使用预训练的VGGNet16网络模型提取图像的表示特征,并同时舍弃VGGNet网络模型中的全连接层,主要由于VGGNet模型中全连接层参数占很大一部分,而去掉全连接层又对模型表征能力没有什么影响。通过DCNN提取的特征在本文模型后续计算中有很大的帮助,一方面图像表示特征被送入文本检测与识别网络,用来确定图像中的文字区域以及识别文本,另一方面特征又被送入相关度度量模块计算图像文本与图像的相关度,最后又送入分类网络进行信息融合分类。
2.2 构建TDN
TDN以Faster RCNN网络为基础,参考CTPN网络结构。CTPN模型是第一个将RNN引入检测问题,使得对图像的检测结果不是在字符级别,而是在行级别,对于学习图像中的文本语义信息更有帮助。检测网络的主要结构图如图2所示。

图2 文本区域检测模型图
(1) 使用VGGNet16网络获得卷积层输出的特征图(××,对应宽度×高度×通道数)。在输出特征图的每个位置上取3×3×的窗口的特征,用于预测该位置k(本文设置k=10)个anchor(anchor的定义和Faster RCNN类似)对应的类别信息、位置信息。
(2) 将每行的所有窗口对应的3×3×的特征(×3×3×)输入到双向长短期记忆网络(bidirectional long short-term memory,BLSTM)中,得到×256的输出。将BLSTM的×256输入到512维的全连接层。
(3) 全连接层再将特征输入到3个分类层中。2k scores表示的是k个anchor的类别信息(不同于Faster RCNN,本文只有2类,字符与非字符)。2k vertical coordinate和k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示边界框的高度和中心点轴坐标(以此决定上下边界),个side-refinement表示边界框的水平平移量。本文只用了3个参数表示回归的bounding box,因为本文默认了每个anchor的宽度是16,且不再变化。
(4) 将文本/非文本分数大于0.7作为正锚点,得到固定宽度的小规模文本建议框,再利用文本行构造算法[11],将多个相邻的文本建议合并成一个文本行用于后续的文本识别。
2.3 构建TRN
首先RoIpooling模块依据回归之后的文本建议框与卷积层输出的特征图得到要识别文本的特征;之后将高度固定、长度不同的文本特征送入BLSTM中获取到固定长度()的文本特征表示,适应不同长度的文本识别;将统一长度的文本特征送入图3所示的文本识别模型中。
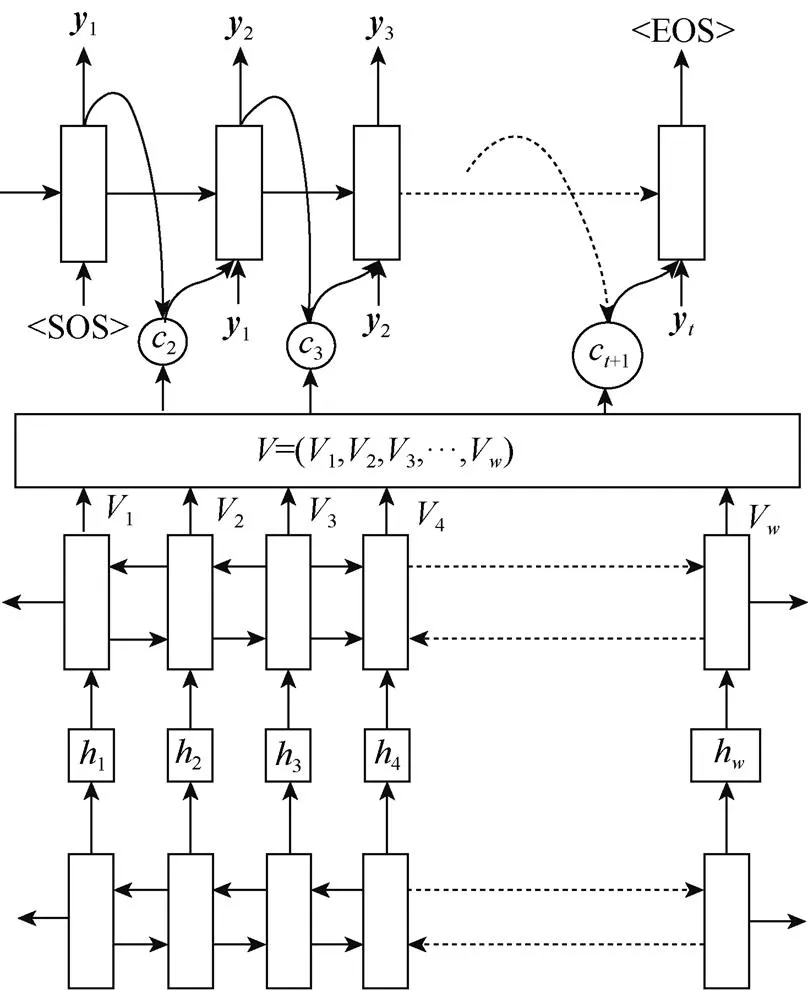
图3 文本识别模型图
文本识别模型主要基于软注意力机制检测窗口中的文本信息,其不用预先对文字进行分割,并且可以通过反向传播的方式优化损失函数。模型具体流程如图3。
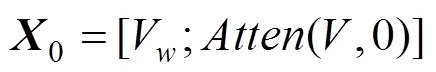
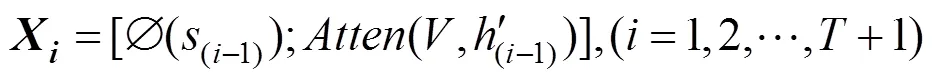
猜你喜欢
红外技术(2022年11期)2022-11-25
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
安阳工学院学报(2020年2期)2020-06-05
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
北京航空航天大学学报(2018年1期)2018-04-20
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
