
ASJP模式的汉语方言计算分析
2019-08-09 08:30索伦·维希曼冉启斌
现代语文 2019年5期
索伦·维希曼 冉启斌

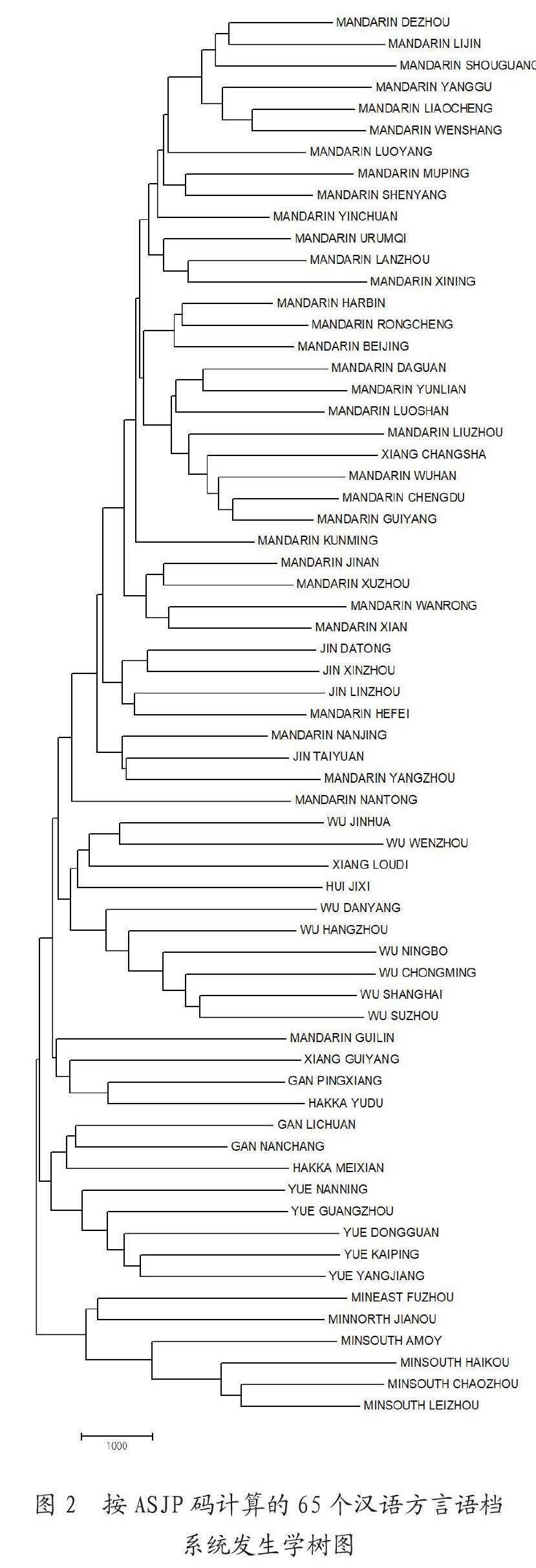

摘 要:通过对直接以IPA转写进行距离计算、转写为ASJP码后进行计算、转写为修订版ASJP码进行计算的比较,发现采用修订版ASJP码后的计算效果最符合汉语方言的实际表现。同时,还分析了65个汉语方言语档的系统发育树和系统发育网络,结果显示:东北官话与闽方言之间的亲缘关系最远,处于其间的依次是西北官话、西南官话、北方官话/中原官话、晋方言、客赣徽湘等方言、吴方言、粤方言;客赣徽湘等方言过渡性特征明显;汉语方言中接触表现突出,闽方言和吴方言内部接触相对少一些,北方方言和过渡性方言的内部接触非常多。
关键词:汉语方言;词汇距离;计算分析;系统发育树;系统发育网络
一、引言
ASJP(相似性自动判断程序,Automated Simil-arity Judgement Program)数据库是马普研究院建立的大型跨语言关联数据(Cross-Linguistic Linked Data)资源库之一。ASJP数据库收录每种语言至少40个核心词的语音形式,用以进行词汇语音形式相似度的计算判断。最新版数据库(第18版)收集有世界范围7655个语档(doculect)的材料,按ISO639-3编码,这7655个语档涉及全球5067种语言(https://asjp.clld.org/)。
通过列文斯坦编辑距离(Levenshtein Distance)可以计算任意两个字符串之间的距离,从而也就可以计算语档词汇的语音形式之间的距离(简称“词汇距离”)。ASJP网站提供有各类计算工具和程序。Müller(2009a,2009b,2010,2013)先后计算绘制了多个版本的世界语言语档系统发育树图,为研究语言的分化与分类提供了新的视角。
第18版ASJP数据库中收集了包括上古汉语、中古汉语、东干语在内的19个与汉语有关的语档材料。相对于丰富的汉语方言资源,19个语档的数量并不大。同时,使用ASJP计算方法对汉语方言进行研究其有效性如何,在计算的一些具体细节上是否有进行调整的空间等,都是值得研究的问题。本文采用ASJP的计算模式和方法,对初步收集到的65个汉语方言语档材料进行计算分析。
二、研究材料与方法
(一)研究材料
在以往研究中,研究者采用编辑距离对不同的材料进行距离测算的有王璐(2014),江荻(2017),赵志靖、江荻(2018)等。王璐(2014)以30个三音节词、20个句子的语音转写,测量吴方言5个方言点之间的距离。江荻(2017)通过计算核心词编辑距离及词汇相似度,对195种藏缅语族语言进行自动分类。赵志靖、江荻(2018)则对侗台语族语言进行计算分类以及亲缘关系程度的描述。
本文研究材料为65个汉语方言点各40个核心词的语音形式。各方言点具体参见附录1“65个汉语方言语档名单”。这些语档涉及官话、晋、吴、赣、湘、徽、粤、闽、客家等方言点。各语档核心词的国际音标(IPA)标写来源于《汉语方言词汇》、刘俐李等《现代汉语方言核心词·特征词集》以及各地方言调查报告、方言志、地方方言研究等。限于篇幅,每个语档的具体来源从略。目前ASJP模式的距离计算主要处理字符串之间的距离,因此各语档的IPA轉写不包括声调。按ASJP数据库的模式,各个语档的信息除40个词的语音形式外,还包括各语档的ISO639-3代码(如该方言有的话)以及该方言点所在地的经纬度等信息。
(二)研究方法
按ASJP模式的做法,通常将40个核心词的IPA形式转换为ASJP码。这样做的目的主要是使软件程序能够对词的语音形式进行计算。IPA与ASJP码的对应情况如附录2所示(前面部分为元音,后面部分为辅音)。出于探索的目的,本文先报道直接依据40个核心词IPA进行计算的结果;再报道转换为ASJP码后的计算结果。
计算与作图的有关情况如下:首先使用ASJP有关软件程序计算各语档之间的词汇距离,可以形成距离矩阵。ASJP模式的距离计算有LDN距离(归一化莱文斯坦距离)、LDND距离(归一化莱文斯坦距离商)的不同(可参看冉启斌、索伦·维希曼,2018:52~53),本文研究均依据LDND距离。在距离矩阵基础上使用分子生物学软件MEGA7与SplitsTree4分别绘制模拟的汉语方言系统发生学树图(phylogenetic tree,或称系统发育树,使用Neighbor-Joining Tree法)和系统发生学网络图(phylogenetic network,或称系统发育网络,使用NeighborNet法),并进行相关分析。
三、汉语方言语档系统发育树分析
(一)依据IPA标写直接进行距离计算
由于收集到的汉语方言记音材料存在不统一之处,后期我们对少部分记音符号进行过局部统一。使用前述语料和方法,依据65个汉语方言语档的IPA直接进行距离计算,形成距离矩阵,并使用MEGA绘制出65个汉语方言语档的系统发生学树图。
在系统发育树上,根节点之下以吴方言、粤方言为主的方言语档首先与其他方言语档分开;然后银川、阳江分布在一个节点之下,与其他方言语档分开;再后官话方言、闽方言、吴方言等分布在一个节点之下,与其他语档分开(进一步的分支节点还有很多,为避免繁复此处从略)。显然这个发生学关系不符合我们关于汉语方言历史的基本认知,且不少距离较远的方言语档在发生学关系上混杂在一起。
同时可以看到,有的方言语档连接在相同的直接节点上,说明它们应该是直接分化形成的;然而事实上它们并不具有很近的分化关系。例如萍乡和北京,很难想象萍乡话和北京话具有最直接的分化来源。类似的还有南通、沈阳,徐州、福州,银川、阳江,扬州、筠连等。它们的关系相对较远,却连接在相同的直接上位节点上。
此外,有的语档处在相同的末端节点,表明它们应该具有很密切的亲缘关系;而汉语方言的事实证明它们的发生学关系并不近。例如绩溪和大同处在同一个末端节点之下,事实是绩溪话和大同话无论在方言归属还是地理上都距离较远。类似的还有温州和长沙,娄底和开平等。
