
面向公共安全监控的多摄像机车辆重识别
2019-08-20 05:53王艳芬朱绪冉孙彦景石韫开王赛楠
西安电子科技大学学报 2019年4期
王艳芬,朱绪冉,云 霄,孙彦景,石韫开,王赛楠
(中国矿业大学 信息与控制工程学院,江苏 徐州 221116)
车辆重识别(Re-IDentification, Re-ID)旨在跨越不同的监控摄像机场景识别出目标车辆,对社会公共安全的维护起到至关重要的作用,如寻找可疑车辆、跨摄像头车辆跟踪以及驾驶轨迹分析等。 由于交通场景复杂、摄像机视点有限、光照变化等约束的影响,车辆重识别仍是个极具挑战的问题。
现有的车辆重识别方法[1-5]仅在已裁剪好的车辆图像之间实现识别,而在真实监控场景中,车辆重识别任务要先从视频中检测并获取车辆边界框。 传统的车辆识别方法主要采用颜色[6]、纹理[7]和灰度梯度直方图[8]等人工特征,但此类特征在环境变化时鲁棒性较差。 随着卷积神经网络(Convolutional Neural Network, CNN)在计算机视觉领域的快速发展,众多基于卷积神经网络的车辆识别方法被提出。 文献[3]中提出一种基于深度学习的渐进式车辆重识别方法,但此方法从图像中获取车牌区域时计算复杂度较高,因此实时性较差。 文献[4-5]在车辆细粒度识别中采用先进的三元损失模型,但该模型收敛缓慢,较softmax分类损失模型更易过拟合。
为解决以上问题,笔者针对公共安全视频监控领域提出一种结合车辆检测与识别的多摄像机无标注车辆重识别方法。 首先,在检测阶段设计出基于二值-单点多盒检测(Binary-Single Shot multibox Detector, B-SSD)的车辆检测网络,先从视频中检测出所有车辆区域并在线生成候选车辆数据库,以解决原始视频中无标注问题;在车辆识别阶段提出一种多任务孪生(Multi-Task Siamese, MT-S)车辆识别网络,该网络结合分类和验证两种模型,充分利用监督信息学习更具判别性的车辆特征,从而提高重识别精度;最后组建“VeRi-1501”数据集,该数据集在现有数据集[1,4]上扩充车辆标识数量,并均衡每个标识在不同摄像机下的图像数量。 在VeRi-1501数据集和实际交通场景中对所提方法进行了验证。
1 面向公共安全监控的多摄像机车辆重识别
1.1 方法概述
笔者提出面向公共安全监控的多摄像机车辆重识别方法,流程图如图1所示。 对于给定的无标注原始视频流,先用二值-单点多盒检测车辆检测网络从视频中获取车辆区域,并在线生成候选车辆数据库;然后利用多任务孪生车辆识别网络提取目标车辆与候选数据库中车辆的特征,并计算相似度;最终匹配到目标车辆。

图1 面向公共安全监控的多摄像机车辆重识别流程图
1.2 二值-单点多盒检测车辆检测网络
单点多盒检测(SSD)[9]较其他检测框架[10-11]具有更快的运行速度和更高的精度。 在车辆重识别问题中,区分车辆和背景是检测阶段的核心任务。 因此,笔者设计了一种二值-单点多盒检测车辆检测网络,将单点多盒检测算法用于二值车辆检测问题。 如图2所示,二值-单点多盒检测的架构主要由两部分组成:一部分是位于前端的深度卷积神经网络,采用的是VGG-16[12]图像分类网络,用于初步提取目标特征;另一部分是位于后端的多尺度特征检测网络,其作用是对前端产生的特征层进行不同尺度条件下的特征提取。
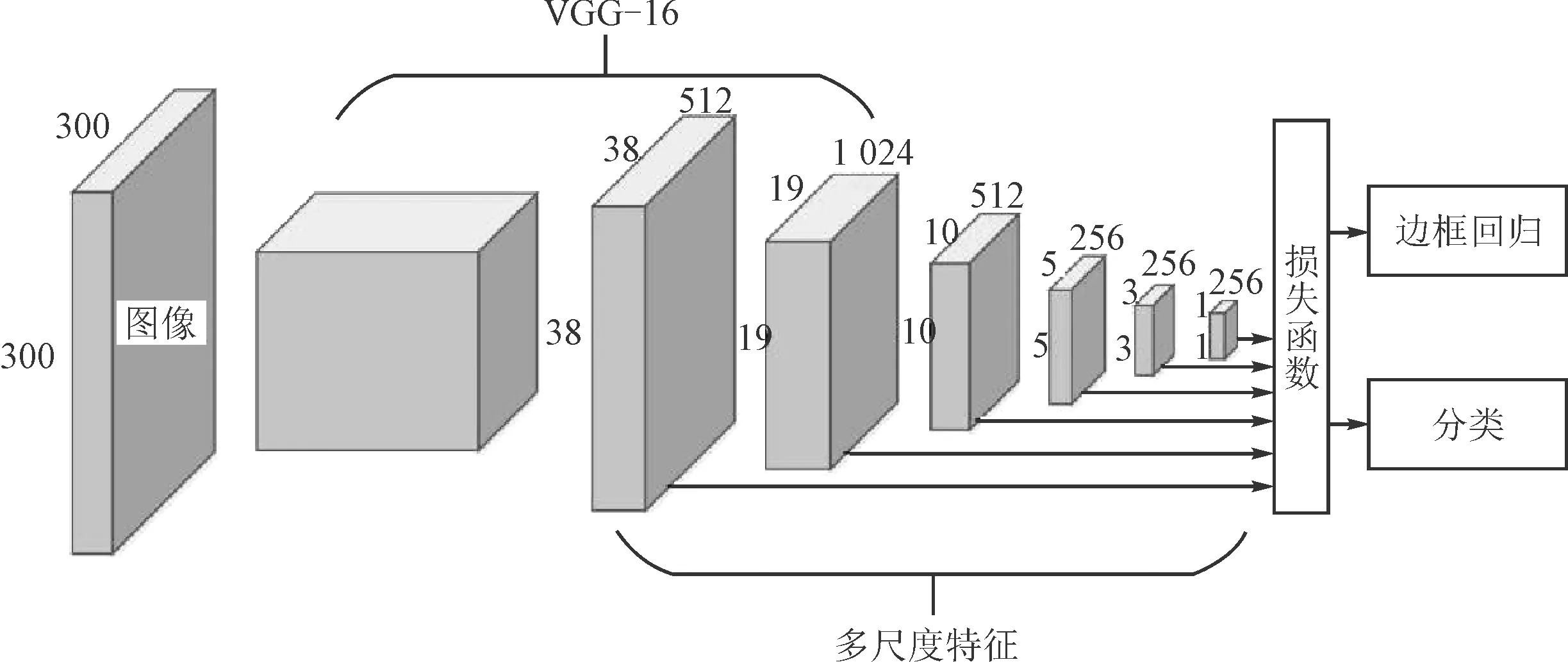
图2 二值-单点多盒检测车辆检测网络结构图
在网络训练期间,其目标损失函数为置信损失和位置损失的加权和:
(1)
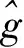
(2)
(3)
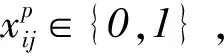
1.3 多任务孪生车辆识别网络
多任务孪生(MT-S)车辆识别网络由两个分类模型和一个验证模型组成,如图3所示,分类模型和验证模型相互关联。分类模型得到的车辆判别表达特征作为验证模型的输入,验证模型预测的结果在下一批中对分类模型的参数进行修正。 上下两个分类模型通过两个相同的ResNet-50网络共享权值。 网络参数在优化中受到这两类模型损失函数的共同约束,充分利用监督信息,从而使网络学习到的特征具有更强的判别性。
该网络受分类标签t和验证标签s的共同监督。 输入尺寸为224×224的图像对(正样本对或负样本对),用两个完全相同的ResNet-50[14]网络提取车辆特征,并输出1×1×2 048维的特征向量f1和f2。f1和f2分别用于预测两输入图像的车辆身份t。 同时计算f1和f2的欧氏距离,进行相似度判断,f1和f2共同预测验证类别s。
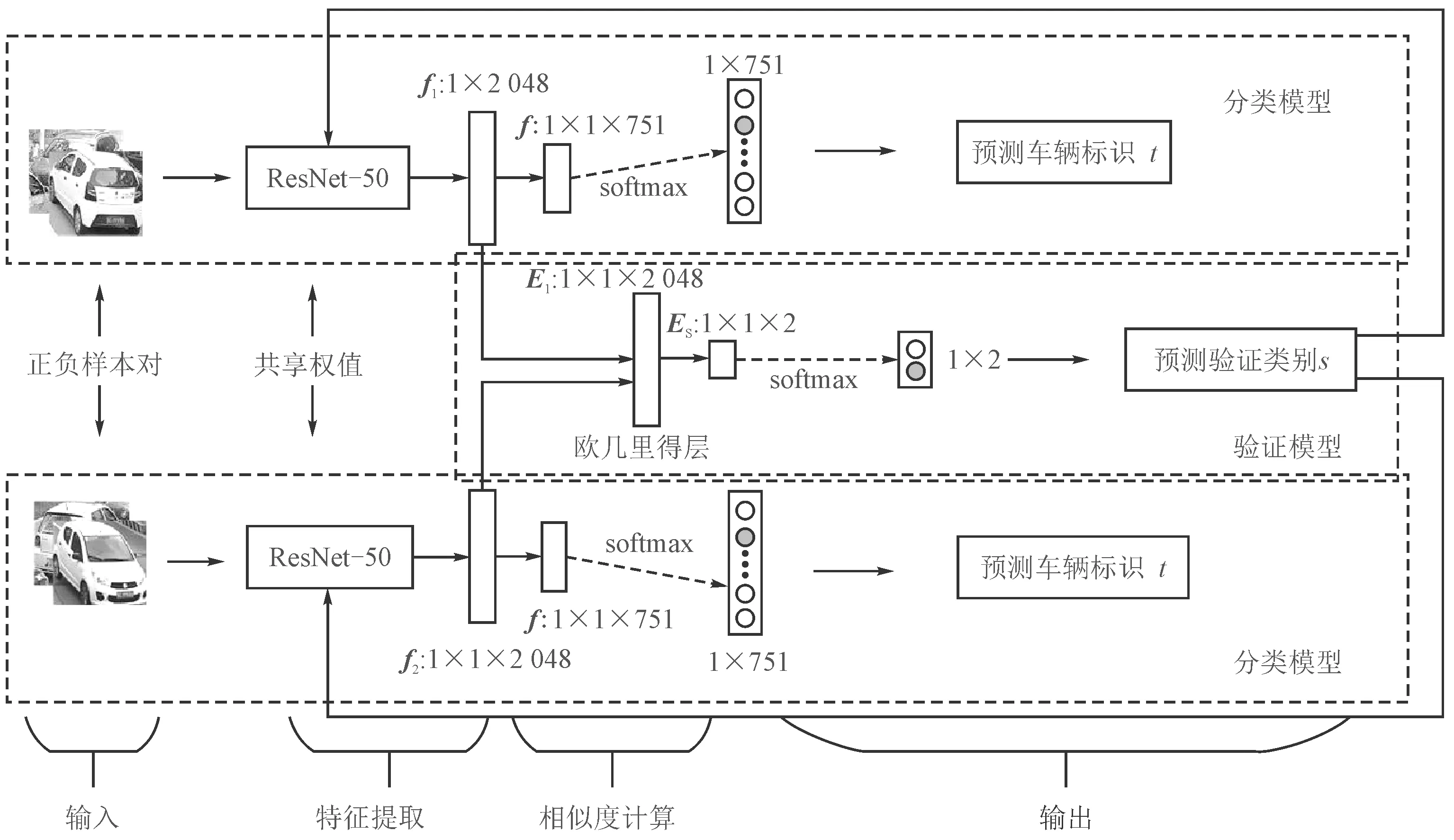
图3 多任务孪生车辆识别网络结构图
分类模型包含2个ImageNet[15]预训练的ResNet-50网络、两个卷积层和两个分类损失函数。其中,ResNet-50去掉最后一层全连接层,平均池化层输出1×1×2 048维的特征向量f1、f2作为车辆判别表达。 由于数据集中有751个训练标识,因此用751个1×1×2 048的卷积核对其进行卷积,得到1×1×751维的车辆身份表达f。 最后使用softmax函数和交叉熵损失进行身份预测,即
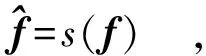
(4)
(5)

验证模型包含一个无参的欧几里得层、一个卷积层和一个验证损失函数。 其中欧几里得层定义为El=(f1-f2)2,El是欧几里得层的输出张量。 验证模型通过欧几里得层将相同标识的车辆特征映射到欧几里得空间中相近的点,将不同标识的车辆特征映射到欧几里得空间中相隔较远的点。笔者没有采用对比损失函数[16],而是将车辆验证视为二元分类问题,这是因为直接使用对比损失函数容易造成网络参数过拟合。 因此,用2个1×1×2 048的卷积核对El进行卷积,得到1×1×2维的相似度表达E。 最终验证损失函数的表达式为
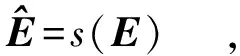
(6)
(7)
这里s是验证类别(不同/相同),
是预测概率,Ej是目标概率。 如果输入的一对图像属于同一标识,则Ej= 0;否则,Ej=1。
在网络训练期间,整体损失函数为分类损失和验证损失的加权和:
(8)
权重系数α通过交叉验证设置为0.5。在识别标签t和验证标签s的共同监督下,网络学习到的特征具有更强的判别性。
1.4 VeRi-1501数据集
在车辆重识别任务中,经常使用的两个数据集是VehicleID[4]和VeRI-776[1]。 其中,VehicleID数据集仅考虑了车辆的前后两种视角,无法满足复杂环境下的需求。每种车辆仅包含8.4张图像,无法满足查询要求。VeRI-776数据集只包含776个标识,样本标识数量不充分,严重影响模型的准确率。

图4 VeRi-1501数据集中的样本
针对以上不足,在VehicleID和VeRi-776数据集的基础上构建一个新的数据集——VeRi-1501。其具有以下3个特性:①图像均在真实复杂的交通场景中捕获,具有车牌信息和时空关系信息;②包含由6个分辨率为1 280×1 080高清图像的监控摄像头捕获的1 501辆车的37 491张图像,其中训练集包含751辆车的17 190张图像,测试集包含750辆车以及干扰物,共计17 178张图像,查询集包含750辆车的2 915张图像;③每个标识最多可被6个摄像机以不同角度、不同光照以及在遮挡情况下捕获,确保每个标识车辆至少在两个摄像机中出现过,以便可以执行跨摄像机搜索。
图4给出了VeRi-1501数据集中的样本,以“0001_c1s1_102004103.jpg”为例,图像命名遵循以下规则:①“0001”表示车辆的标识编码;②“c1”表示1号摄像机;③“s1”表示摄像机中的第一时间序列,“c1s1”和“c2s1”处于同一时期;④“102004103”表示用视频软件截取视频帧生成的默认名。
2 实验结果与分析
2.1 实验设置
(1)图像预处理。将所有训练图像的大小调整为256×256,并采用去均值操作进行数据归一化处理。 在训练期间,所有图像被随机裁剪为224×224大小,乱序排列并按随机顺序抽取图像组成正负样本对。 由于正样本对的数量有限,为防止过拟合,将正样本对和负样本对之间的初始比率设置为1∶1。每个历元之后正样本对以1.01倍的比率增加,直到正负样本对的比率达到1∶4。
(2)训练。在Caffe深度学习框架中实现多任务孪生车辆识别网络。 实验环境为配有NVIDIA Quadro M2000和2.2 GHz Intel Xeon E5-2650 CPU的设备。 历元设置为155,批次设置为4。 学习率初始化为0.001,然后在最后5个历元后设置为0.000 1。采用小批量随机梯度下降(SGD)来更新网络参数。
2.2 与现有方法的比较
在实验中采用两个评估指标:平均精度和Rank系列精度[17]。 平均精度用来度量重识别方法的整体性能, rank-1精度表示识别结果中排名第1的图像是正确的概率。 rank-5精度表示识别结果排名前5的图像中包含正确图像的概率。 表1给出了笔者所提的多任务孪生车辆识别网络与其他先进网络在VeRi-1501上的性能对比。 从表1数据可以看出,多任务孪生车辆识别网络在平均精度、rank-1、rank-5中均性能最优,说明该网络可以准确地进行车辆重识别。
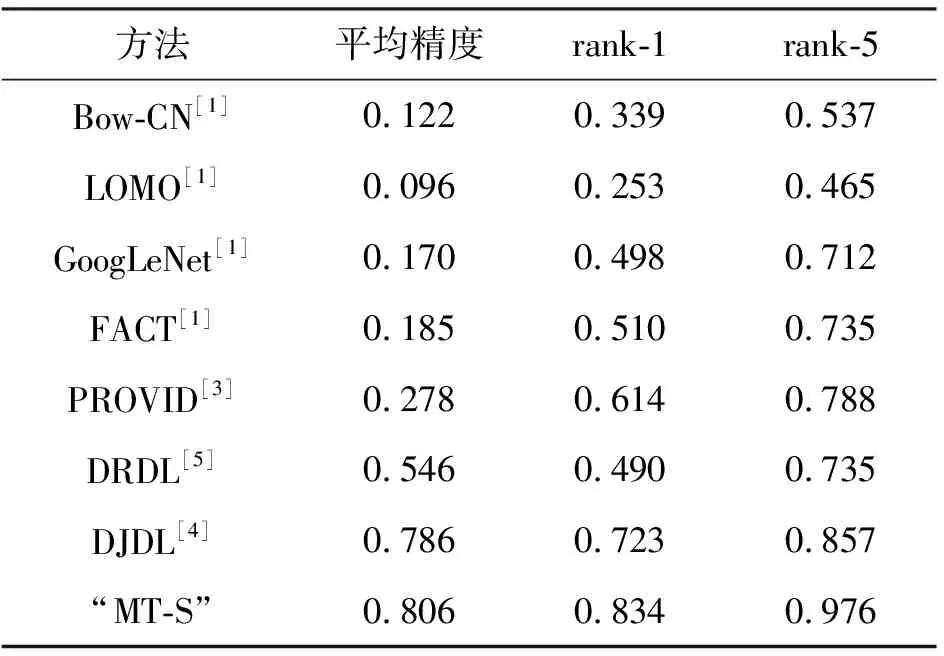
表1 多任务孪生与其他先进算法的对比
2.3 多摄像机识别结果分析
为了进一步评估多任务孪生车辆识别网络的性能,提供了图5中所有相机对之间的重识别结果。共放置了6个摄像机,相机分辨率为1 920×1 080。 图5的水平轴和垂直轴分别代表目标车辆所在的初始相机位置和待检索的相机位置。 从表1中可以看出,交叉相机的平均精度和平均rank-1精度分别为81.16%和83.56%。 笔者提出的方法在很大程度上改善了重识别性能,并且观察到相机之间的标准偏差较小。 这表明多任务孪生车辆识别网络能够在不同视角下进行高效的车辆重识别。
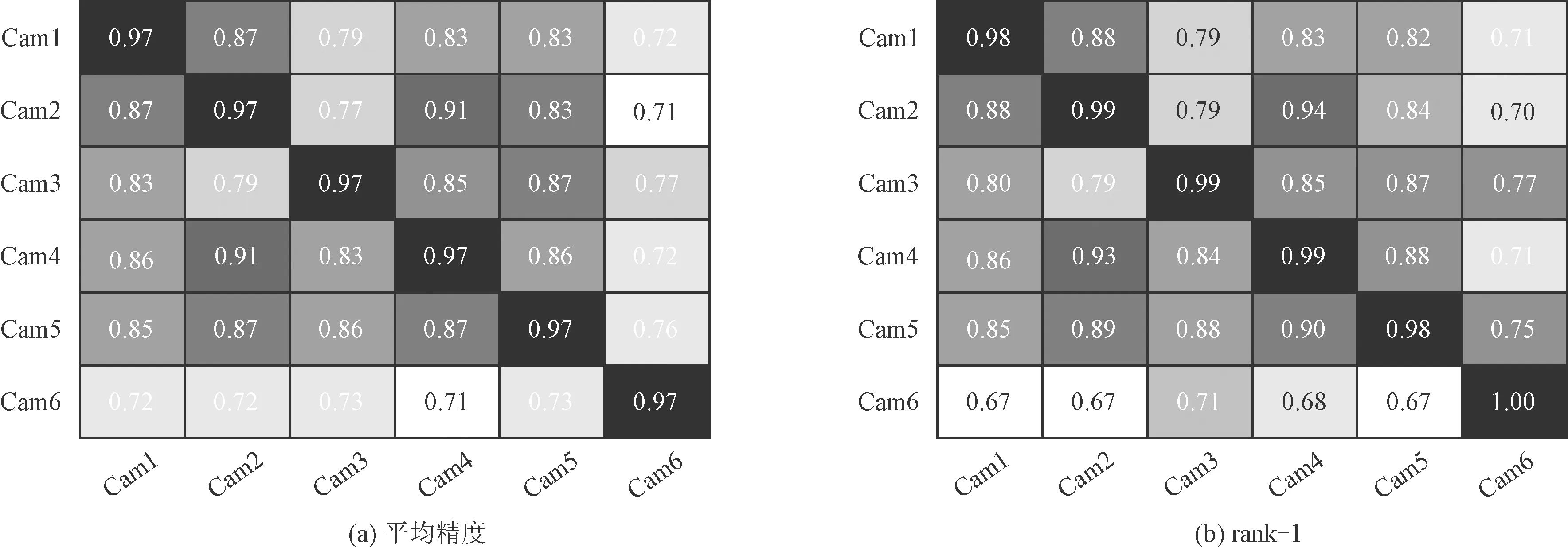
图5 多任务孪生车辆识别网络在摄像机对之间的识别性能
2.4 公共安全监控场景下的应用
为进一步验证笔者提出的面向公共安全监控的车辆重识别方法在实际场景中的有效性,在校园内拍摄若干组监控视频用于验证,如图6所示。 目标车辆从校园北门(摄像机1)进入,沿北京路—天津路顺时针绕行,途经图中所示的6个摄像头,摄像头的分辨率为1 920×1 080。 算法实时性可达25帧/秒。 具体步骤如下:
(1)获取无标注视频流v0,v1,…,vi;
(2)在给定无标注视频序列v0的当前帧中标定目标车辆;
(3)利用B-SSD车辆检测网络读取此后的每一帧图像,提取图像中所有的车辆边界框ID0,ID1,…,IDi,并在线生成候选车辆数据库;
(4)利用多任务孪生车辆识别网络提取ID0与ID0,ID1,…,IDi的车辆判别特征,并依次计算ID0与ID0,ID1,…,IDi之间的相似度得分;
(5)相似度得分最高的即为目标车辆;
(6)在视频序列v1,…,vi中重复步骤(3)到步骤(5)。
实验结果如图6所示,实线框代表目标车辆, 灰色框代表检测出的候选车辆,黑色框代表在不同摄像机下用笔者所提出的方法定位到的目标车辆。

图6 面向公共安全监控的多摄像机车辆重识别在公共安全监控场景下的应用
3 总 结
针对公共安全视频监控领域中无标注的原始监控视频,提出一种结合车辆检测与识别的多摄像机无标注车辆重识别方法。 首先提出二值-单点多盒检测车辆检测网络,获取车辆边界框并在线生成候选数据库;其次设计一个多任务孪生车辆识别网络以提高重识别精度;最后组建“VeRi-1501”车辆数据集,其在现有数据集上扩充车辆标识数量,并均衡每个标识在不同摄像机下的图像数量。 笔者在VeRi-1501数据集和实际交通场景中对该方法进行验证,结果表明该方法识别准确且精度高。
致谢
感谢中国矿业大学保卫处对此课题研究的无偿支持;感谢滕跃同学对此次课题研究的帮助。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
中国惯性技术学报(2020年2期)2020-07-24
山东冶金(2019年5期)2019-11-16
中国生物医学工程学报(2019年6期)2019-07-16
中国公共安全(2017年11期)2017-02-06
办公自动化(2016年18期)2016-12-17
山东工业技术(2016年15期)2016-12-01
自动化学报(2016年3期)2016-08-23
中国惯性技术学报(2015年1期)2015-12-19
新闻前哨(2015年2期)2015-03-11
