
基于多目标蚁群算法的稳定参考点选择
2019-08-22 09:59曹建军郑奇斌李红梅
计算机技术与发展 2019年8期
张 磊,曹建军,刘 艺,郑奇斌,李红梅,冯 钦
(1.陆军工程大学 指挥控制工程学院,江苏 南京 210007;2.国防科技大学 第六十三研究所,江苏 南京 210007)
0 引 言
实体分辨是找到同一实体在同一数据源或不同数据源的不同描述,正确识别出不同实体的过程[1]。随着互联网数据产生能力的增强,异构数据成为大多数互联网应用和平台的基础数据结构[2]。例如一个互联网分享平台可能包括了视频、图片、文本标签等数据,并形成了图片分享、图片标注等关联交互关系。这些异构数据处在不同的特征空间,因此传统的直接比较特征相似度的方法不能适用于异构数据的实体分辨。
现有异构数据实体分辨方法主要是通过学习一个公共的空间,并将异构的数据映射到该空间,从而使得异构的数据能够在一个公共的空间进行实体分辨[3]。但该类方法需要大量的训练数据集,而异构数据的训练数据集获取成本高昂[4]。为了降低对训练数据的需求,同时保持较高的实体分辨准确性,Zheng提出了一种基于空间结构相似性的实体分辨方法[5]。该方法主要从两个异构的数据源中分别选择表示为同一实体的数据对象作为参考点,将异构的数据对象转换成其到各自参考点的距离向量,依据空间结构的相似性来判断是否为同一实体。在该方法中,参考点的选择将影响数据的空间结构表征,进而影响实体分辨的准确性。同时,参考点选择的稳定性也成为影响数据空间结构表征的重要因素。
参考点选择稳定性是指选择方法对训练数据的微小扰动具有一定的鲁棒性,即能够生成较为稳定的参考点子集。在基于空间结构相似性的异构数据实体分辨中,由于参考点集的选择将影响数据的空间结构表征,稳定的参考点集具有较好的数据空间结构表征能力,从而提高了实体分辨的准确性。提高参考点集选择的稳定性可以选择出较为稳定的参考点集,从而提高数据的空间结构表征能力,提高实体分辨的准确性,增强结果的可信度。同时,如果仅采用实体分辨准确性评价参考点集的效果,在未知数据集上训练模型上易产生不稳定的泛化错误,通过稳定的参考点选择方法可以减少泛化错误,进一步提高模型的泛化能力。
文中主要对异构数据实体分辨参考点选择稳定性问题进行研究。为提高参考点选择的稳定性,进而选择出较优的参考点集,提高异构数据实体分辨的准确性,以实体分辨准确性和参考点子集稳定性最优为目标建立模型,使用多目标蚁群算法对模型进行求解,从而选择出较为稳定的参考点集。通过实验验证了该方法的有效性和优越性。
1 相关工作
为了解决异构数据实体分辨问题,近年来学者们提出了大量的解决异构数据实体分辨的方法,其中以利用学习公共空间的方法最为广泛,因此文中主要介绍学习公共空间的异构数据实体分辨方法。
利用学习公共空间的方法进行实体分辨主要是通过学习一个公共的空间,通过将异构的数据映射到该空间进行实体分辨的过程。Rasiwasia等[6]运用典型相关分析(canonical correlation analysis,CCA)进行异构数据的实体分辨,该方法主要通过提取异构数据的底层特征,找到一个统一的线性空间,使得异构的数据对象之间的相关性最大。Andrew等[7]提出了利用深度学习的方法来找到异构数据的潜在联系,从而使得异构数据关联起来。Kang等[8]提出了一种利用条件随机场的方法来学习异构数据的统一表示,从而使得异构的数据关联起来。
Pereira等[9]提出了三种异构数据实体分辨方法:相关性匹配(correlation matching,CM)、语义匹配(semantic matching,SM)、语义相关匹配(semantic correlation matching,SCM)。CM是一种利用底层特征来学习异构数据之间关系的方法,即针对每条异构数据对象学习一个映射到公共空间的变换,通过最大化公共空间的相互联系来保证数据表示之间的语义联系。SM是通过对数几率回归将异构数据映射到同一个语义空间,然后直接在这个语义空间中进行数据的拟合与匹配。而SCM则是两者的结合,即建立一个联系最大的语义空间,并通过对数几何回归将异构数据映射到该语义空间,从而更好地反映数据的语义之间的关系。
为了降低对训练数据的需求同时能够保持较高的实体分辨准确性,Zheng等[5]提出了一种基于空间结构相似性的异构数据实体分辨方法。通过从异构的数据集中选取表示为同一实体的对象作为参考点,将数据对象转换为其到参考点的距离向量,之后依据空间结构的相似性进行实体分辨。在该方法中,较好的参考点集具有更好的空间表征能力,从而提高实体分辨的准确性。为了使得参考点集具有更好的空间结构表征能力,需要选择较为稳定的参考点集,将选择稳定性方法用于上述参考点选择问题,从而提高参考点集的稳定性。
2 多目标蚁群算法稳定参考点选择
本节主要以实体分辨的准确性和参考点集的稳定性作为优化目标,使得在异构数据实体分辨中能够选择出较为稳定且能够使得实体分辨准确性较高的参考点。
2.1 优化目标及数学模型
基于空间结构相似性的实体分辨方法主要是从两个异构的数据源中分别选择表示为同一实体的数据对象作为参考点,将异构的数据对象转换成其到各自参考点的距离向量,依据空间结构的相似性来判断是否为同一实体。在该方法中,需要选择出能够使得实体分辨准确性较高且较为稳定的参考点集。
在上述问题描述中,优化目标有2个,一是实体分辨的准确性,二是参考点集的稳定性。文中把实体分辨看作二分类问题,正类表示待分辨的对象为同一实体,使用F1值作为实体分辨准确性指标。
设参与分类的样本总数为Num,正类正确区分为正类的样本数为P_num,负类正确区分为负类的样本数为N_num,正类区分为负类的样本数为FN_num,负类区分为正类的样本数为FP_num,则查全率R、查准率P、F1指标分别为:
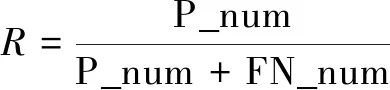
(1)
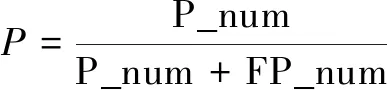
(2)
(3)
稳定性的度量指标[10]主要包括谷元距离、邓恩稳定性指标、权重一致性指标和扩展昆彻瓦相似度度量指标等[11]。由于扩展昆彻瓦相似度度量指标能够度量不同规模的子集,具有良好的可扩展性,因此文中采用扩展昆彻瓦相似度指标对参考点集的稳定性进行度量。设由同一选择方法生成的两个参考点集合为s和s',它们的扩展昆彻瓦指标值的计算如下:
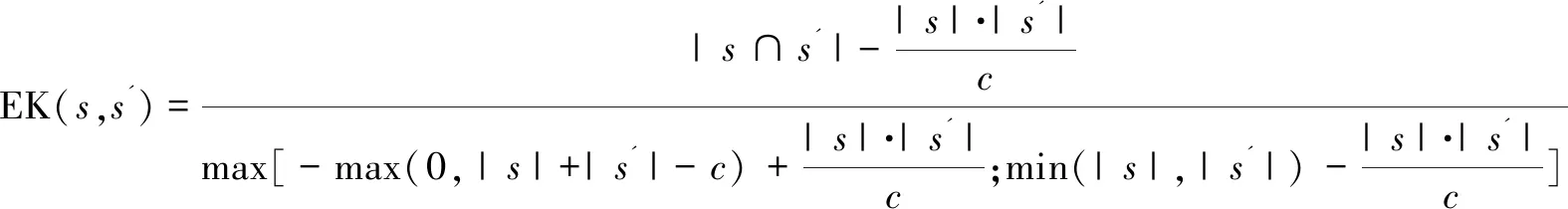
(4)
其中,c为参考点的对数。
文献[12]分别通过集成卡方检验、信息增益和ReliefF和SVM-RFE等Filter方法对特征子集进行选择,发现采用卡方检验、信息增益和ReliefF的集成方法(简称Ensemble1)选择特征子集的稳定性较好,其主要步骤是分别采用上述三种Filter方法对样本进行排序,最后通过中值法集成多种排序的结果。
文中采用Ensemble1方法来选择参考点子集。假定存在c对参考点集合对R={U,V},其中U={u1,u2,…,uc},V={v1,v2,…,vc}分别来自两个异构数据集。为了从R中选择出较为稳定的参考点子集,分别利用卡方检验、信息增益和ReliefF方法对参考点集R中的对象进行排序选择,之后通过中值法集成多种结果,得到Ensemble1方法选择出来的参考点子集Rn={Un,Vn},其中1≤n≤c。为了确保文中方法能够选择出较为稳定的参考点子集,令s'=Rn,即用Ensemble1方法选择出来的参考点子集s'与文中方法选择的参考点子集s进行比较,以指导文中的参考点稳定性选择方法,使其能够选择出较为稳定的参考点子集。
扩展昆彻瓦相似度指标的取值在[0,1]之间[13],指标取值越大,两个参考点集合相似度越高,说明选择方法的稳定性越好。
因此,建立如下两目标优化数学模型
maxF1
(5)
max EK(s,s')
(6)
s.t. 1≤|s|≤c,1≤|s'|≤c
上述模型中,s和s'为同一参考点选择方法生成的两个参考点集合。式5、式6表示基于参考点集s的F1指标最高同时子集的稳定性最好。上述优化模型可以看作一个两目标子集问题进行求解。
2.2 模型分析及多目标蚁群算法求解
由于两目标优化问题通常并不存在各目标都为最优的解,而存在一非劣解集,称为Pareto解集。多目标优化的目标就是找出一组解,尽可能全面地逼近Pareto解集,决策者可按需求选择出自己的满意解。
对于求解多目标优化模型,文献[14]提出了一种求解子集问题的基于图的蚂蚁系统。针对子集问题,定义了构造图和等效路径,提出了基于等效路径增强的信息素更新策略,克服了蚂蚁寻找解的有序性与问题解的无序性之间的矛盾,并以多维背包问题为例验证了该系统的有效性和优越性。文中将该蚁群算法用于求解式5、式6。

图1 基于图的蚂蚁系统
如图1所示,在基于图的蚂蚁系统中,t时刻在节点v1生成m只蚂蚁,每只蚂蚁根据边上的信息素和启发式信息独立地选择某一边向下一节点移动。c为可选边的数量,即为蚂蚁可选择的参考点对的数量,n为蚂蚁在一次搜索过程中寻找解的个数,即蚂蚁在一次搜索中找到n对参考点,eij表示蚂蚁在第j步选择第i条边。
在基于图的蚂蚁系统中,t时刻第m'只蚂蚁使用式7进行路径选择。
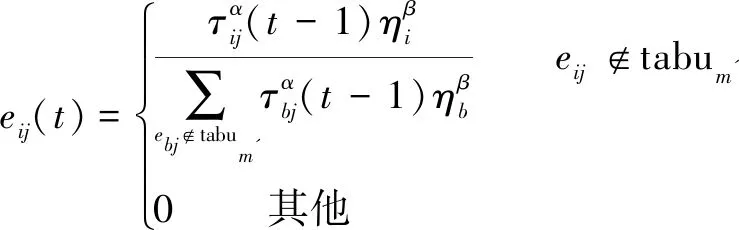
(7)
其中,禁忌表tabum'为第m'只蚂蚁走过的边,即蚂蚁已选择的参考点对;α和β为信息素量和启发式信息的重要程度;启发式信息ηi是外部信息,表示选择第i对参考点的希望程度;τij(t)为在t(t=0,1,2…)时刻边eij上的信息素量。
采用多个信息素矩阵能够获得较好的Pareto解,一般的设置方式为每个目标对应一个信息素矩阵,由于需要同时优化两个目标:F1指标与稳定性指标,因此需要设置2个信息素矩阵。2个信息素矩阵的设置意味着在计算条件转移概率的过程中,需要对2个信息素值进行聚合,因此需要将两个信息素值聚合成单个值计算路径选择概率,聚合采用式8:
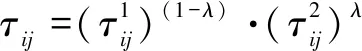
(8)
其中,λ(0≤λ≤1)是权重参数。
当蚂蚁每次迭代完毕后,使用帕累托档案解更新2个信息素矩阵时采用目标最好解方法,在t时刻拟对路径tabut的信息素增强,信息素更新如下:
τij(t)=

(9)
其中,Δ'(tabut)为信息素增量;ρ(0≤ρ≤1)为信息素挥发系数。
在蚁群算法中,启发式信息表示蚂蚁在路径选择中的先验偏好,能够有效提升蚂蚁获得较好的解的能力。基于异构数据实体分辨背景,提出了基于参考点之间的距离、方差和最大信息系数(maximal information coefficient,MIC)评估值相结合的启发式信息定义方法。
在基于空间结构的异构数据实体分辨中,参考点之间的距离较大或参考点之间的距离方差较大时,其实体分辨准确性较好[15]。同时,MIC是一种度量变量之间任意关系的方法,MIC的评估值越大,表明变量之间的相关性越强。文中利用MIC值度量参考点两两之间的相关性,MIC的取值在(0,1)之间,MIC的评估值越大,表明两个参考点之间的相关性越强,同时有MIC(ui,uj)=MIC(uj,ui)。因此,将参考点ui的MIC的评估值设置为:
MI(ui)=
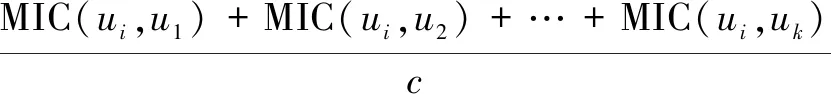
(10)
其中,c为数据集中参考点的数量。
综上,第i对参考点的信息素设置为:
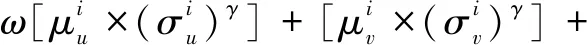
ε[ωMI(ui)+MI(vi)]
(11)
文中提出的蚁群算法选择参考点的伪代码如下所述:
算法:蚁群算法选择稳定参考点。
(1)BEGIN
(2)在参考点训练样本中采用卡方检验、信息增益和ReliefF方法进行排序选择参考点子集
(3)集成步骤2中的三种参考点集选择结果(Ensemble1)
(4)计算训练样本中每个对象与其他对象之间的距离均值和距离方差
(5)计算训练样本中每个对象与其他对象的最大信息系数评估值
(6)利用式11集成上述两种信息作为启发式信息
(7)以F1值和蚁群算法选择的子集与Ensemble1选择的子集的扩展昆彻瓦相似度指标作为蚁群算法的优化目标,采用多目标蚁群算法搜索较好的参考点子集
(8)END
上述算法中,步骤2和步骤3主要是利用Ensemble1方法对参考点集进行排序选择,以此作为蚁群算法选择参考点的指导信息;步骤4~6是计算蚁群算法的启发式信息,以便蚂蚁能够选择较好的解;步骤7为蚂蚁根据图上的信息素值和启发式信息值搜索较优的参考点子集并更新其相应路径。
2.3 算法复杂度分析
在异构数据参考点选择问题上,蚂蚁寻找最优解的时间复杂度(最坏情况)为O(NC×m×c2),其中NC为算法的最大迭代次数,c为备选解的个数。因此蚂蚁在搜索参考点子集时最坏情况下的时间复杂度为O(NC×m×c2)。
上述方法中,蚁群算法中信息素表是占用存储资源最大的部分,其空间复杂度为O(c2),因此蚂蚁寻找最优解的空间复杂度为O(c2+m)。
3 实验与分析
在本节使用真实数据集进行对比实验,验证了文中方法的有效性。
3.1 实验数据
实验数据来源于公开数据集NUS-WIDE中的子集NUS-WIDE-LITE,NUS-WIDE-LITE是一个从Flickr上获取的图片数据集,包括大概27 000张图片。其中图像的颜色直方图数据Normalized_CH_Lite_Test中对象的特征个数为64,图像的文本标签数据Lite_Tags1k_Test中对象的特征个数为1 000。实验分别从以上两组数据中选取代表同一客观实体、并且文本标签数据不全为0的数据对象作为训练数据集。
3.2 实验设计
实验对以下三种方法进行比较。
方法1(文中方法):利用两目标蚁群算法对参考点进行选择,并考虑参考点集的稳定性,简称SSACO-SSM(stable selection based on multi-object ant colony optimized space structure matching);
方法2(文献[16]所提方法):在异构数据实体分辨中利用蚁群算法对参考点进行选择,但未考虑参考点集的稳定性,简称ACO-SSM(ant colony optimized space structure matching);
方法3(文献[5]所提方法):在异构数据实体分辨中使用随机选择参考点的方法进行异构数据实体分辨,简称SSM(space structure matching)。
共设计了1组对比实验,对比实验中共2组数据集,分别称为数据集1和数据集2。这2组数据中,匹配的数据对象数量c分别为600对和1 000对,分别用三种方法在2组数据集中测试其实体分辨结果和参考点稳定性。该对比实验主要验证SSACO-SMM的F1值和参考点集的稳定性指标EK(s,s')要好于ACO-SSM和SMM。
蚁群算法的参数设置如下:初始时刻信息素τij(0)=100,信息素和启发式信息的重要程度系数α=2,β=1,信息素挥发系数ρ=0.2,蚂蚁数量M=30。
实验选用SVM作为分类器,SVM中的核函数选用线性核函数。
3.3 实验结果
数据集1的F1值指标和稳定性分别如图2、图3所示。
数据集2的实验结果分别如图4、图5所示。
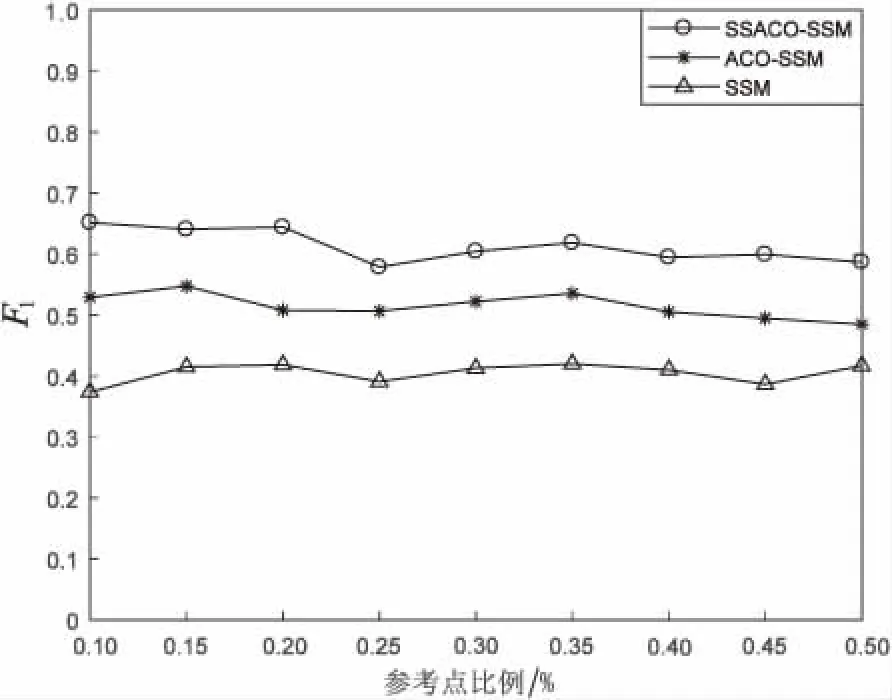
图2 数据集1中的参考点比例与F1值关系曲线
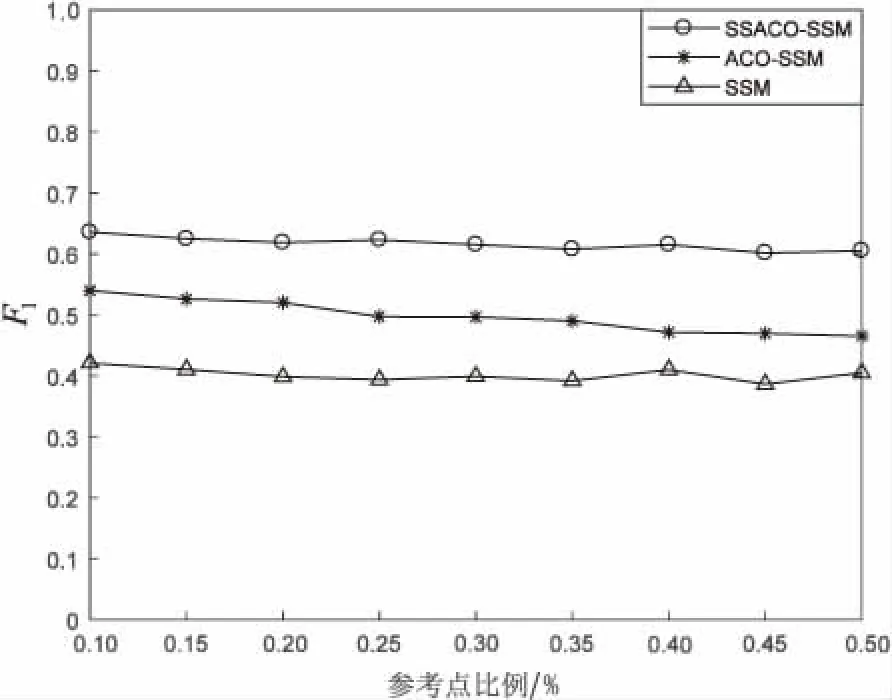
图4 数据集2中参考点比例与F1值关系曲线
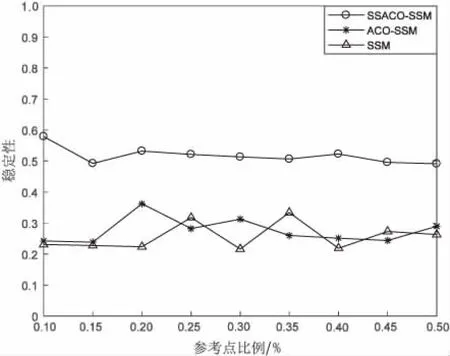
图3 数据集1中参考点比例与稳定性关系曲线
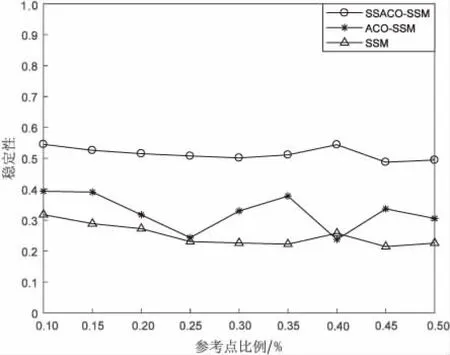
图5 数据集2中参考点比例与稳定性关系曲线
从图2、图4中可以看出,SSACO-SSM方法2个数据集上的F1值都要好于其他两种方法,说明SSACO-SSM方法能够有效提高异构数据实体的准确性。从图3、图5中可以看出, SSACO-SSM方法在稳定性指标方面都要好于其他两种方法,说明SSACO-SSM方法能够有效提高参考点集的稳定性。分别对比图2和图3,图4和图5,可以看出,当参考点集稳定性提高时能够有效提高异构数据实体分辨的F1值,即实体分辨准确性。
综上,文中方法在异构数据实体分辨选择参考点子集时具有良好的稳定性,同时也具有较高的实体分辨准确性。
4 结束语
为了提高异构数据实体分辨中参考点选择的稳定性,提出了一种基于多目标蚁群算法的参考点选择方法,实现了参考点子集稳定性和实体分辨准确性的综合最优。得到如下结论:
(1)在基于空间结构相似性的异构数据实体分辨中提高参考点子集的稳定性,能够有效提高异构数据实体分辨的准确性;
(2)使用实体分辨准确性和最大信息度量系数作为蚁群算法的启发式信息,使得算法能够有效利用蕴含的先验信息,从而提高算法获得更好解的概率;
(3)异构数据实体分辨的参考点选择多目标优化模型,综合考虑了实体分辨准确性和参考点子集的稳定性,实现了效果的最优。
该方法与业务领域无关,具有较强的通用性。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
好日子(下旬)(2020年6期)2020-08-04
福建基础教育研究(2019年11期)2019-05-28
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
数理化学习·教育理论版(2013年9期)2013-12-27
