
面向中文歌词的音乐情感分类方法①
2019-08-22 02:30朱贝贝
计算机系统应用 2019年8期
王 洁, 朱贝贝
(北京工业大学 信息学部,北京 100124)
1 引言
随着计算机网络与多媒体技术的快速发展,互联网上涌现了越来越多的文本、图像、音频和视频等多媒体数据. 音乐是多媒体数据的重要组成部分. 面对音乐作品数量的爆炸式增长,音乐种类的不断增多,如何有效的管理音乐成为一个值得关注的问题,对音乐资源进行合理的分类是一个有效的解决办法. 音乐是情感的载体,情感是音乐最重要的语义信息,音乐的情感分析广泛应用于音乐检索、音乐推荐和音乐治疗等领域[1]. 音乐情感的自动识别属于音乐心理学和计算机学科的交叉领域[2],至今已有十几年的历史,国内外众多学者都对该领域做了深入的研究,并取得了一定成果.2010年,Kim等曾对当时音乐情感识别研究的进展做了全面综述[3]. 2012年,Yang等对音频音乐情感识别研究做了详尽的总结[4]. 2017年,陈晓鸥等人回顾了最近几年音频音乐情感识别的研究进展情况,提出了若干问题及可能的解决方案[5].
音乐主要由音频信号与歌词文本这两种模态的数据组成. 目前大多数研究者致力于使用机器学习方法研究音频信息对音乐情感分类的作用[6-8]. 2003年,Li等提取音色、节奏和音阶等音频特征,并最早使用SVM (Support Vector Machine)对音乐情感分类[9].2014年,Weninger等提取MFCC (Mel Frequency Cestrum Coefficient)等底层音频特征后,使用LSTM(Long Short-Term Memory)对音乐情感分类[10].2017年,Jakubik等使用GRU(Gated Recurrent Unit)对音频进行特征学习,并引入语义嵌入的思想[11]. 同年,邓永莉等提出基于中高层特征的音乐情感识别模型[12].
采用现有频域和时域特征的机器学习方法,很难使音乐情感识别的性能再提高[5]. 一些心理学研究表明歌词文本中确实蕴含着一些特有的语义信息,包括情感信息[13]. 结合歌词进行音乐情感分类可以进一步提高分类性能,基于歌词的情感分类也逐渐成为热门的研究方向. 歌词本质上属于文本的范畴,词语的情感判别是歌词情感分析的基础. 构建一部合理的音乐情感词典,实现词汇的情感分析是歌词情感分析的前提和基础. 国内情感词典构建起步较晚,情感词典的领域特性也日趋明显. 已有研究构建的情感词典主要集中在中文评论领域,如微博评论和商品评论,评论情感分析一般只判别情感极性,即褒贬性,而歌词具有更加丰富的情感,目前还没有被广泛认可的音乐领域的中文情感词典. 2010年,夏云庆等基于文本向量空间模型提出了情感向量空间模型,并利用实验验证了情感向量模型在解决稀疏性、特征表示能力、表示效率和特征歧义消除等方面具有较明显的优势[14]. 2014年,蒋盛益等利用 HowNet中语义相似度计算的思想,构建音乐领域的中文情感词典,再进行音乐情感分类[15],2015年,Furuya等通过对非情感词加权构造情感向量,使用聚类方法进行音乐情感分类[16]. 2017年,黄仁等基于Word2Vec建立情感词典,用构建的情感词典对互联网商品评论进行情感分类[17],该词典仅包含词的情感极性,不包含词的情感强度,没有考虑情感词本身的分类影响程度. 在基于歌词文本的情感向量的构建过程中,夏云庆等仅统计每个情感类别的情感词个数,忽略了情感词的情感强度是不同的. 蒋盛益和Furuya等均未考虑实词词频和词性的影响作用.
针对以上问题,本文基于Word2Vec构建音乐领域的中文情感词典,并基于情感词加权和词性进行中文音乐情感分析. 本文首先以VA情感模型为基础构建情感词表,采用Word2Vec中词语相似度计算的思想扩展情感词表,构建中文音乐情感词典,词典中包含每个词的情感类别和情感权值. 然后,依照该词典获取情感词权值,基于TF-IDF构造特征向量,并进一步考虑词性对情感分类的影响,最终实现音乐情感分类.
2 基于歌词的音乐情感分类
2.1 构建情感词表
音乐是情感的载体,情感是音乐最重要的语义信息,不同的音乐必然与不同的情感相联系. 为了更准确的描述音乐情感,与人的情感体验一致,需要选择合适的音乐情感模型.
选择VA模型作为音乐情感分类的依据. VA模型(也称为环形情感模型)是由Russel提出的,是广泛采用的通用连续维度模型[18,19]. 该模型认为情感状态是分布在一个包含效价度(valence)和激活度(arousal) 的二维环形空间上的点,如图1所示. 其中横轴表示效价度,纵轴表示激活度,圆心代表中性的效价度和中等水平的激活度.
为了适应中文情感分类,结合VA模型的情感类别以及音乐表达情感的特点构建情感词表. 情感词表如表1所示,第1列为情感类别,即本文用于情感分类的标签. 其它列为对应每一个情感类别的情感词汇.
2.2 中文音乐情感词典
情感词表中的词是经过提炼而成的情感词,而歌词中包含的情感词是有限的,因此,需要对情感词表进行扩展以满足歌词情感分类的需求. 借助Word2Vec计算词语相似度,使用《哈工大同义词林》和歌词语料库对情感词表的38个情感词汇进行扩展,从而构建出一部适用于中文歌词情感分类的词典,用于歌词文本分析.
2.2.1 计算词语相似度
情感词一般是指能表达情感的形容词,如“喜悦”、“悲伤”、“愤怒”. 歌词中包含的情感词较少,而歌词中的某些非情感词也能表达情感. 比如,“夜”可以表达“静”的情感,“告别”可以表达“悲伤”的情感. 因此,可以通过计算有情感倾向的实词(包括名词、动词、形容词和副词)与情感词表中的情感词汇的词语相似度,对实词进行情感分类,从而实现对情感词表的扩展.

表1 情感词表
采用Gensim的Word2Vec进行相似度计算,并用搜狗实验室的语料数据训练模型. 因为该语料库规模较大,训练好的模型可以涵盖尽可能多的词语. 因此,可以利用训练好的模型计算任意两个词语的相似度,相似度值在0-1之间.
2.2.2 构建音乐情感词典
首先使用《哈工大同义词林》对情感词表进行扩展,构建基础情感词典. 并结合歌词语料库对基础情感词典做进一步扩展,构建音乐情感词典.
使用《哈工大同义词林》对情感词表进行扩展,扩展后的词典仅包含情感词,称为基础情感词典. 首先,从《哈工大同义词林》获取情感模型中的情感词对应的同义词列表. 然后,计算同义词列表中的实词与情感词的词语相似度,选择相似度值最大的情感词与实词对应. 最后,提取相似度高于0的实词构成基础情感词典. 实现过程如图2所示. 情感词典的存储结构为四元组(实词,情感词,情感类别,情感权值),比如(伤感,忧伤,-V-A,0.91). 其中,“伤感”是选自《哈工大同义词林》的实词; “忧伤”是选自情感词表的情感词; “-V-A”是“忧伤”对应的情感类别; 0.91对应于情感权值,即“忧伤”与“伤感”的词语相似度. 基础情感词典共包含1527个词汇,其中4类情感的词汇量分布情况如表2所示.
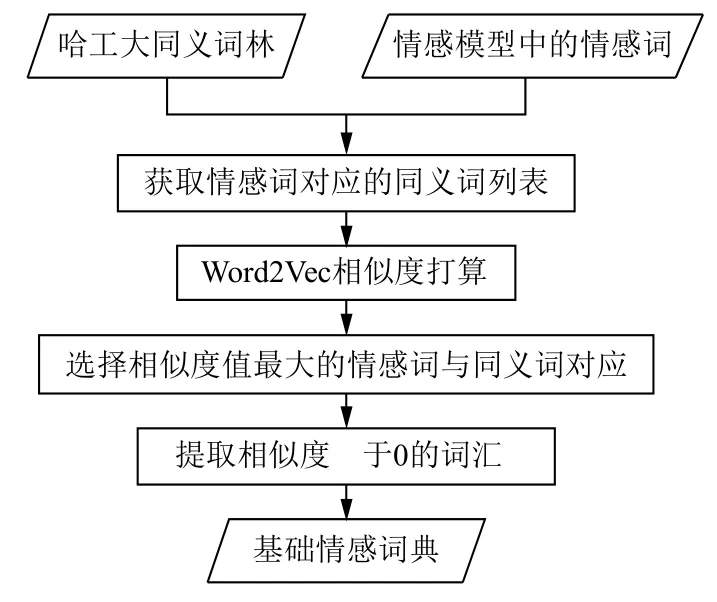
图2 基础情感词典构建流程

表2 基础情感词典词汇量分布
基础情感词典仅包含情感词,而歌词中所包含的情感词较少,但歌词中的某些非情感词也有情感倾向.因此可以利用包含一万首中文歌曲的歌词语料库对基础情感词典做进一步扩展,以更适用于中文歌词情感分类,扩展后的词典称为音乐情感词典. 首先,将歌词语料库中的歌词进行处理,并提取实词构建歌词词汇语料库. 然后,计算歌词词汇语料库中的实词与情感词的词语相似度,选择相似度值最大的情感词与实词对应. 最后,提取相似度高于0的实词与基础情感词典合并,构成音乐情感词典. 实现过程如图3所示. 音乐情感词典的存储结构与基础情感词典相同. 音乐情感词典共包含45 374个词汇,其中4类情感的词汇量分布情况如表3所示.

图3 音乐情感词典构建流程

表3 音乐情感词典词汇量分布
2.3 构建基于歌词的特征向量
本文依照所构建的情感词典获取情感词权值,基于TF-IDF构造特征向量,并进一步考虑词性对情感分类的影响,将特征向量扩展到16个维度.
2.3.1 TF-IDF
基于情感向量模型,采用情感词表的4类情感类别作为音乐的情感特征向量,共4个维度. 该特征向量的每个维度表示音乐与每类情感的相似关系. 将歌词中的实词与情感词典进行匹配,可以得到每个实词的情感类别和情感权值,从而计算出每个情感类别的统计值.
采用TF-IDF规则计算情感特征. TF-IDF是一种统计方法,TF表示词频,可以评估歌词中某个实词在特定歌词文件中的的情感重要程度. IDF表示逆向文件频率,可以评估某个实词对于区分特定歌词文件和其他歌词文件的情感重要性.
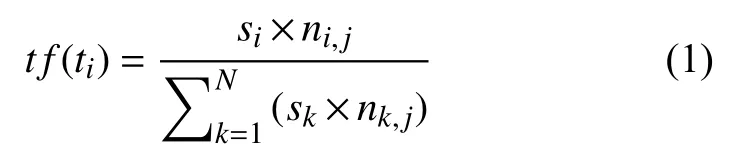
对于歌词文本中的实词ti,tf(ti)表示ti对情感类别的重要程度,反映出一个实词在特定歌词文件中的局部统计特征. si表示ti在情感词典中对应实词的情感权值,如果ti匹配失败,si值为0. ni,j表示ti在该歌词文本中的出现次数. N表示该篇歌词经过分词后得到的词语总数.
IDF由式(2)计算:

对于歌词文本中的实词ti,idf(ti)表示ti对于区分特定歌词文件和其他歌词文件的情感重要性. |D|表示歌词文档总数表示歌词中出现ti的歌词文档数.
歌词文本的特征向量表示为:
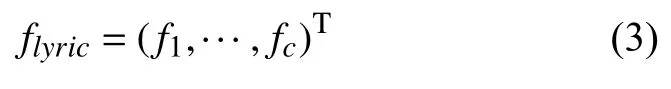
其中,c表示情感类别数,特征向量的每个维度由式(4)计算:
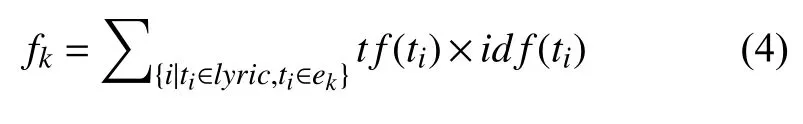
其中,ek表示特征向量第k维度对应的情感类别,lyric表示歌词经过分词后得到的词语.
2.3.2 词性
不同的词性表达情感的能力是不同的,比如,形容词比名词表达的情感更丰富. 因此,本文将结合词性信息构造特征向量. 我们将每篇歌词文本经过分词后得到的词语根据词性分为4类,每类词性对应的特征向量如式(5)所示. 将4类词性的特征向量结合得到最终的特征向量,如式(6)所示.
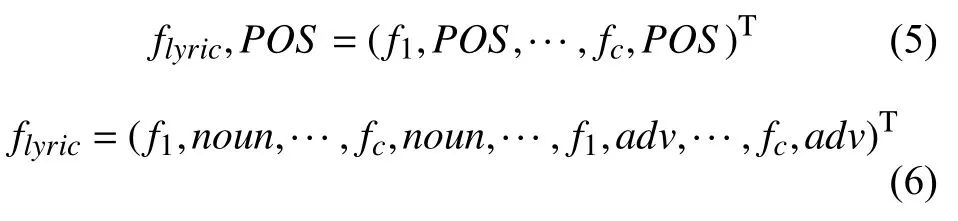
2.4 歌词情感分类
音乐情感分类通常采用标准的监督学习模型,如K近邻(KNN)、高斯混合模型(GMM)和支持向量机(SVM). 本文采用KNN分类算法用于歌词情感分类.
KNN的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中k通常是不大于20的整数.
选择中文歌词数据集中的80%作为训练集,20%作为测试集. 利用KNN分类的思想,对每个测试样例,计算它与所有训练样例之间的情感特征向量的欧几里德距离,以确定其最近邻列表,选择最近邻中出现次数最多一个类别作为测试样例的类别. 在本文实验中,当k=5时分类效果最佳.
3 实验结果及分析
3.1 数据集
数据集是200篇情感类别鲜明的中文歌词文档,每个情感类别约50篇. 每篇歌词的情感标签由多个人进行标记,选择标记人数最多的类别作为该歌词的标签.
3.2 评价指标
本文使用准确率、精确率、召回率和F值来评价分类效果. 以情感类别“-V-A”为例,正类(Positive)表示该歌词的预测结果是“-V-A”,负类(Negative)表示该歌词的预测结果不是“-V-A”. TP,FP,TN和FN的具体含义如表4所示. 则准确率A、精确率P、召回率R、F值的计算公式如下:


表4 TP,FP,TN和FN含义表
3.3 实验结果与评价
本文做了两组对比实验,所有实验均使用相同的数据集. 第一组对比实验中,情感词典的选择不同,分别使用2.2.2节构造的基础情感词典和音乐情感词典,构造特征向量均考虑词性的影响. 实验结果如表5所列. 可以看出,基于音乐情感词典的中文歌词情感分类能够达到更好的效果,所有情感类别的准确率以及4种情感类别的精确率、召回率和F值均高于基础情感词典. 同时,实验结果表明,基于歌词的音乐情感分类更适用于“+V+A”和“-V+A”这两类情感的识别.
第二组对比实验中,特征向量的构造方式不同,均使用2.2.2节构造的音乐情感词典. 实验结果如表6所列. 可以看出,在构造特征向量时考虑词性的影响可以提高所有情感类别的准确率,“-V+A”和“-V-A”的评价指标值都有一定提高.

表5 情感词典对比实验结果(%)
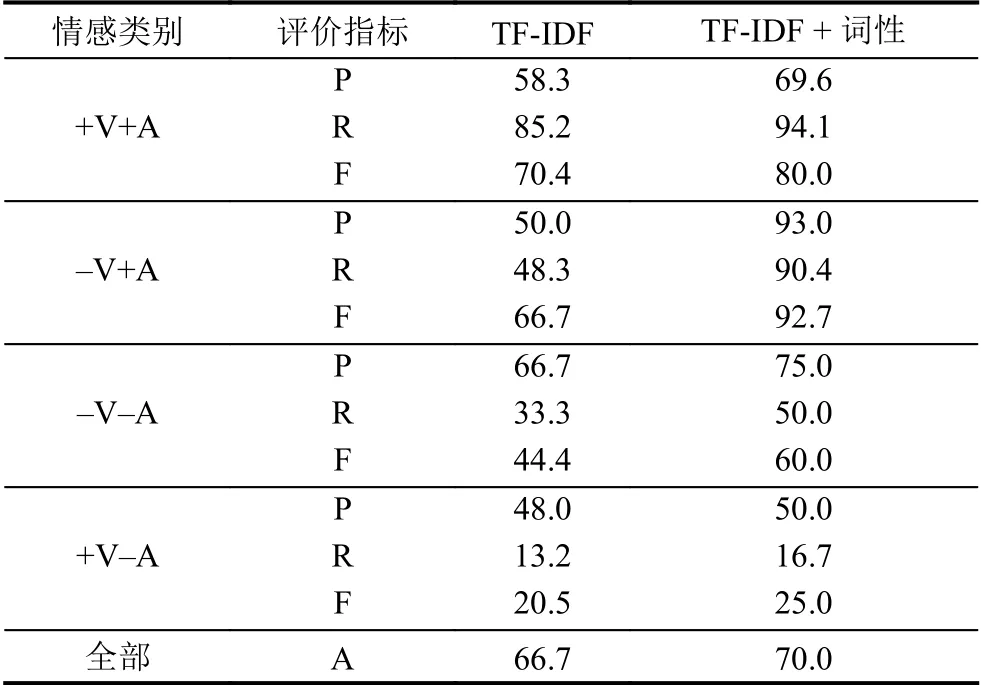
表6 特征向量对比实验结果(%)
4 结论与展望
本文基于Word2Vec构建音乐领域的中文情感词典,并基于情感词加权和词性进行中文音乐情感分析.首先以VA情感模型为基础构建情感词表,采用Word2Vec中词语相似度计算的思想扩展情感词表,构建中文音乐情感词典,词典中包含每个词的情感类别和情感权值. 然后,依照该词典获取情感词权值,基于TF-IDF构造特征向量,并进一步考虑词性对情感分类的影响,最终实现音乐情感分类. 实验结果表明基于所构建的音乐情感词典进行中文歌词情感分类能够达到更好的效果,同时在构造特征向量时考虑词性的影响也可以提高准确率. 但基于歌词的音乐情感分类更适用于“+V+A”和“-V+A”这两类情感的识别. 今后将研究结合歌词与音频的多模态融合的音乐情感分类,以实现多个信息源互补,从而提高所有情感类别的分类精度.
猜你喜欢
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
少儿画王(3-6岁)(2020年4期)2020-09-13
数学学习与研究(2018年15期)2018-11-12
东方教育(2018年20期)2018-08-22
读与写·下旬刊(2017年3期)2017-04-27
语文周报·教研版(2014年11期)2015-01-17
微型计算机(2009年4期)2009-12-23
试题与研究·高考语文(2009年1期)2009-04-16
中学数学研究(2008年11期)2008-01-05
