
降低车道偏离预警系统误报率方法研究*
2019-09-03 07:22妮山
计算机与数字工程 2019年8期
孟 妮山 岩
(1.陕西工业职业技术学院 咸阳 712000)(2.长安大学汽车学院 西安 710064)
1 引言
车道偏离预警系统(Lane Departure Warning System,LDWS)目的是帮助驾驶人使车辆保持在车道内行驶,在车辆偏离车道时发出警告。通常车道偏离预警系统通过图像识别技术采集车道线位置,通过识别车辆与车道线的距离关系判断车辆是否发生偏离。车道偏离预警系统对于预防因为驾驶人分心或疲劳引起的无意识车道偏离具有良好的效果。但是许多驾驶人在换道过程中不开启转向信号灯,这导致车道偏离预警系统无法有效地区分驾驶人换道和无意识车道偏离行为,进而导致车道偏离系统在车辆换道时产生误报。误报率偏高会对驾驶人的正常行驶构成干扰,进而迫使驾驶人关闭车道偏离预警系统。
因为驾驶人换道过程中不开启转向灯现象普遍,国内外针对换道识别进行了大量研究,其中具有代表性的有:C.Jeol等利用车辆横向运动和头部姿态数据建立了基于稀疏贝叶斯方法换道识别系统[1]。Oliver等通过在换道模型中加入驾驶人眼动数据改善了模型换道识别效果[2]。Kuge等利用方向盘转角向量值、方向盘转动角速度和方向盘转矩作为输入,建立了基于隐马尔科夫理论的换道意图识别模型[3]。吉林大学侯海晶基于隐马尔科夫理论建立了高速公路上不同类型驾驶人的换道意图识别模型[4]。清华大学王玉海根据驾驶人的换挡行为特征对驾驶人换道行为进行识别[5]。Doshi等利用车辆运动状态、驾驶人眼动参数和周围车辆运动参数,建立了基于相关向量机的驾驶人换道预测模型[6]。
当前的研究只是集中于辨识车道变换与车道保持,将驾驶人无意识车道偏离简单地划分到车道保持当中去,但是驾驶人无意识车道偏离与换道具有较大的相似性,容易被误识别为换道行为[7]。为此本文基于支持向量机理论着重研究驾驶人无意识车道偏离与换道行为的辨识。
2 模型建立
2.1 SVM理论
支持向量机(Support Vector Machine,SVM)是常用的模式分类方法。SVM的主要目的是通过寻找一个分类超平面作为模型的决策曲面,使得不同类别之间的隔离边缘距离最大化[8]。支持向量机属于通过特征空间里区域特性来分割不同类别的判别式模型。
SVM模型中最常见的是二分类SVM模型,本文也是采用二分类SVM模型区分驾驶人无意识车道偏离与换道行为。其具体计算过程如下。
1)建立已知训练集:

其中xi表示特征向量,yi表示分类标签,本文中换道标签为0,无意识车道变换标签为1。
2)选择合适的核函数K和适当参数C用来求解最优化问题:
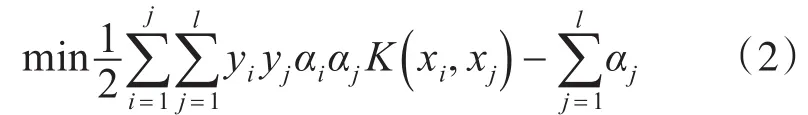


4)决策函数的构建:

2.2 表征参数获取
本文通过实车试验分别采集了车辆在换道和无意识车道偏离状态下的运动数据,考虑到实验过程中具有一定风险性,本文选取在试验场内完成实车试验。相关研究表明分心是造成驾驶人无意识车道偏离的主要因素之一,在驾驶人正常驾驶过程中,通过让驾驶人处于分心状态来使驾驶人出现无意识车道偏离的现象。本文中共选取了12名驾驶人。其中驾驶人的平均年龄为35岁,平均驾龄为5年,健康状态良好。为保证实验结果的客观性,事前并没有告知驾驶人实验目的。
通过在试验车辆上安装方向盘传感器、车道线识别系统、GPS和陀螺仪等。可以采集车辆行驶过程中的方向盘转角、方向盘转动角速度、方向盘转动力矩、车速、横向位移、横摆角速度和横向速度等参数。参考相关研究成果以及结合自身研究特点,选择方向盘转角、横向速度、横向距离作为模型的辨识参数[9]。
1)方向盘转角θ:方向盘转角能够直接体现驾驶人对于车辆运动方向的控制意图,在车辆换道过程中方向盘转角会表现出明显的波动变化。但是在车辆经过弯道时,无意识车道偏离与换道的方向盘转角变化类似,仅依靠方向盘转角难以区分两者区别。
2)横向距离d:本文中横向距离表示车辆距离车道中心线的距离,横向距离可以直接体现车辆在道路中的横向位置变化。
3)横向速度v:横向速度能够表现车辆的横向变化趋势,车辆在换道时其横向速度普遍高于无意识车道偏移。
2.3 扩展卡尔曼滤波
传感器在实际测量过程中会受到环境等因素的影响而在数据中夹杂有随机噪声,同时在数据采集过程中受到传感器精度的影响产生数据不连续的现象。为了最大限度地消除随机噪声并使数据连续化,本文采用了扩展卡尔曼滤波器对获取的数据进行滤波。传统的卡尔曼滤波器利用线性高斯模型对目标状态做最优估计,但这仅仅局限于线性问题或者近似线性问题的非线性问题[10]。车辆的车道偏离识别与相应的方向盘转角、横向速度、横向距离参数是一种复杂的非线性映射关系,为了能够精确地估计目标状态,必须建立合适的非线性滤波器算法。
对于复杂的非线性问题,扩展卡尔曼滤波器采用线性变换将问题转化成近似线性滤波器的问题。扩展卡尔曼滤波器的原理是围绕滤波值对非线性函数展开成泰勒级数,通过去除二阶以上项可以得到线性化模型,利用卡尔曼滤波器完成对数据的滤波处理。通过Matlab软件中的卡尔曼滤波工具箱对方向盘转角、横向速度、横向距离进行扩展卡尔曼滤波处理结果如图1、图2和图3所示。

图1 方向盘转角滤波结果

图2 横向速度滤波结果

图3 横向距离滤波结果
2.4 归一化处理
方向盘转角的变换范围通常在-60°~60°之间,横向位移的变换范围在-200cm~200cm之间,横向速度的变化范围在-6m/s~6m/s之间。方向盘转角、横向速度、横向距离的单位不同,其变化范围也不同,横向位移的变换范围明显大于方向盘转角和横向速度[11]。若是不作处理直接输入到SVM模型当中,横向位移的变化趋势就会一定程度的掩盖方向盘转角和横向速度的变化趋势。因此在建立模型前需要对输入数据进行归一化处理。将所有的数据都转化到[0,1]范围之内,归一化处理公式如下:

其中,xmin表示数据当中最小值,xmax表示数据当中最大值。
方向盘转角原始数据:7.438,7.438,7.438,7.438,7.438,5.95,5.95,5.95,5.95,8.925,8.925,7.438,7.438,7.438。
方向盘转角归一化后数据:0.5,0.5,0.5,0.5,0.5,0,0,0,0,1,1,0.5,0.5,0.5。
横向距离原始数据:-1.445,-1.511,-1.578,-1.632,-1.691,-1.696,-1.624,-1.553,-1.444,-1.337,-1.299,-1.316,-1.379,-1.463,-1.539。
横向距离归一化后数据:0.632,0.465,0.297,0.161,0.012,0,0.181,0.360,0.634,0.904,1,0.957,0.798,0.586,0.395。
横向速度原始数据:-0.541,-0.629,-0.551,-0.432,-0.272, 0.053,-0.461, 0.527, 0.521,0.447,0.064,-0.832,-1.071,-0.783,-0.630。
横向速度归一化后数据:0.331,0.276,0.325,0.399,0.5,0.703,0.381,1,0.996,0.949,0.71,0.149,0,0.18,0.275。
2.5 K均值聚类
本文中传感器采集方向盘转角、横向速度、横向距离参数数据的采样频率为10Hz,在1s中就会产生30个数据值,但是这些数据当中信息大部分是重叠的,直接输入模型会增加模型的计算量,同时大量重叠信息有可能会导致模型出现过拟合现象。为了提高数据质量,选择具有代表性的数据同时去除冗余数据,选择K均值聚类法对输入数据进行优化。
首先选取k个数据点作为初始聚类点,计算剩余数据点与初始聚类点之间的距离,将它们分配到最近的聚类当中。之后不断进行迭代,每次对聚类的数据点求平均值,计算新的聚类中心。重新计算数据点与聚类中心的距离,若数据点距新聚类中心的距离小于上次聚类的距离,就将该数据点移至新的聚类当中。这个过程反复进行直到满足收敛条件为止。
选取了换道时1s之内的数据为例进行K均值聚类,其中具体数据如表1所示。
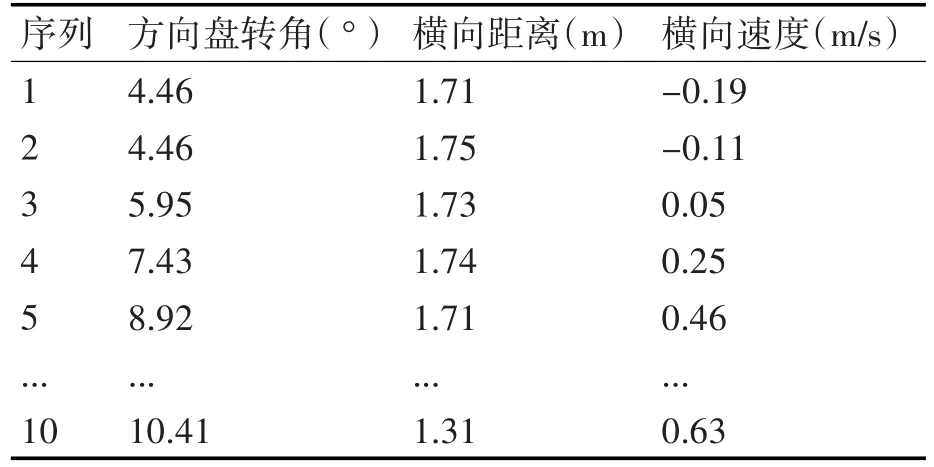
表1 输入表征参数数据
利用K均值聚类法将方向盘转角、横向速度、横向距离参数数据分为三类。因为输入的表征参数都是按照一定规律渐变的,在选取初始聚类中心时分别选取了序列为3、6和9的数据作为初始聚类中心,如表2所示。

表2 初始聚类中心
利用Matlab软件中kmeans函数对数据进行K均值聚类后得到的新聚类中心如表3所示。

表3 最终聚类中心
将最终的聚类中心作为输入样本。通过对原始数据进行精简,在去除冗余信息的同时保留了关键信息。
3 模型训练与测试
从试验数据中挑选出换道和无意识车道偏离样本数据共738组,其中换道包括417组数据,占总样本的56.5%。无意识车道偏离包括321组数据,占总样本的43.5%。从417组换道样本中随机挑选了367组样本用于SVM模型训练,剩余500组换道样本用于测试。同样从321组无意识车道偏离样本中随机选取271组样本用于SVM模型训练,剩余50组换道样本用于测试。
3.1 最优时间窗口选取
时间窗口的大小控制着输入SVM模型中的信息量的多少,输入信息量太少,模型不能够做出有效的识别。输入信息量太多,可能会同时输入不同运动状态的信息也会影响模型识别准确率。时间窗口的选取对于SVM模型的识别准确率与识别效率有重要的影响。对采集到的417组换道样本的换道时间进行统计可知,换道时间大部分集中于3s~14s之间,平均换道时间为7s。对321组无意识车道偏离样本的持续时间进行统计可知,无意识车道偏离的持续时间主要集中于2s~7s之间,平均无意识车道偏离持续时间为4.7s。为了能够有效地识别无意识车道偏离,时间窗口长度就需要小于平均无意识车道偏离持续时间,这样才能保证模型能够有效快速地识别大部分的无意识车道偏离行为[12]。因此选择时间窗口宽度在0.5s~5.0s范围之内,以0.5s为时间间隔,分别计算了不同时间窗口下模型的识别准确率。

表4 不同时间窗口下SVM识别率
由表4可知,SVM总体识别准确率是随着时间窗口的增加先增加后减小的,其中SVM模型对于换道识别的准确率要普遍高于对于无意识车道偏离的识别率。在时间窗口为3.5s时,总体识别率达到最高为83%。但是当前SVM的识别准确率难以满足LDWS系统的要求。
3.2 粒子群优化算法
粒子群优化算法(PSO)是一种群体智能优化算法。PSO算法受到生物种群行为的启发并将其运用到寻找最优化的问题上。PSO算法当中每一个粒子代表了SVM模型中一组可能最优参数。选择SVM模型的误差值作为适应度函数,每一个粒子的适应度值由适应度函数决定,粒子适应度的大小决定了该粒子品质的优劣。粒子的速度表示了粒子在PSO算法当中的移动距离和方向。速度跟随其自身以及周围粒子的经验进行动态调整[13]。通过速度、位置和适应度指标来表示粒子特征。粒子在参数空间运动过程中,利用群体极值Gbest和个体极值Pbest不断更新粒子位置,群体极值表示所有粒子寻找到适应度最优的坐标,个体极值表示个体搜寻过程中得到的适应度最优的坐标[14]。粒子位置每变更一次,对于适应度、群体极值和个体极值都需要重新更新[15]。最终获取空间内的SVM最优化参数。其中PSO算法优化SVM模型的流程如图4所示。
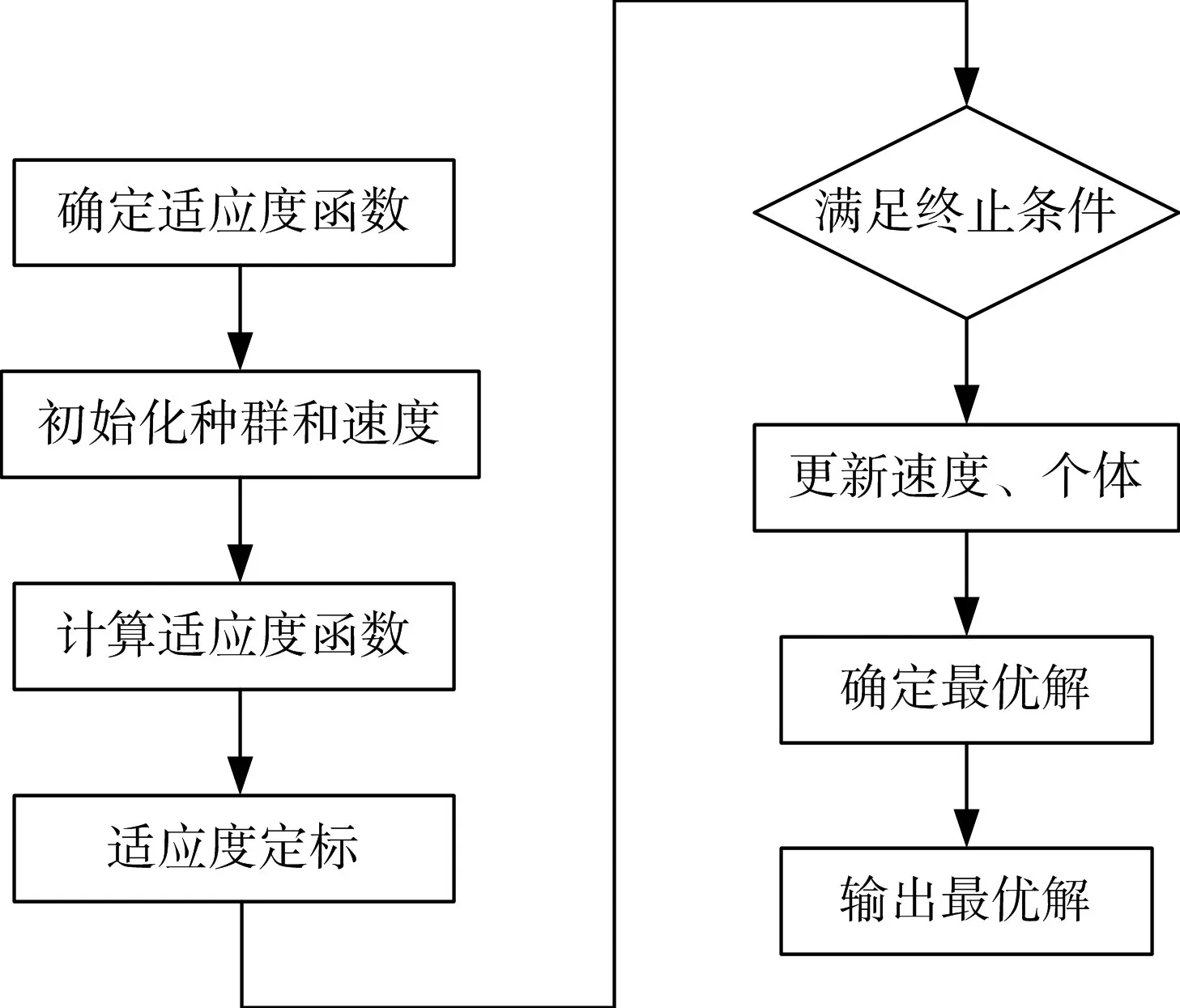
图4 PSO算法优化SVM模型流程图
SVM模型参数经过PSO算法优化后,计算出了SVM算法在不同时间窗口下对于换道和无意识车道偏离的识别准确率。
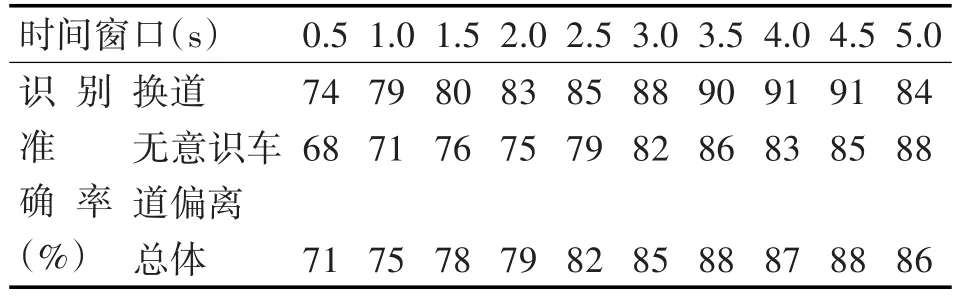
表5 优化后不同时间窗口下SVM识别率
由表5可知,经过粒子群优化算法优化后,SVM模型的识别准确率有明显的提升。在时间窗口为3.5s时,SVM模型具有最高的识别准确率88%,其中换道识别准确率为90%,无意识车道偏离的识别准确率为86%,能够满足LDWS系统的要求。
4 结语
因为车道偏离系统会混淆无意识车道偏离与换道行为,对换道行为进行有效识别可以降低车道偏离预警系统的误报率。本文通过实车试验分别采集了驾驶人在换道和无意识车道偏离时的方向盘转角、横向位移和横向速度等数据。并通过扩展卡尔曼滤波、归一化和K均值聚类方对数据进行预处理。建立了基于支持向量机的车道偏离识别模型。为了进一步提高支持向量机对于车道偏离的识别准确率,采用粒子群算法对支持向量机参数进行优化。在时间窗口为3.5s时,支持向量机的总体识别率可以达到88%,降低了车道偏离预警系统的误报率,减少了因为系统误报对驾驶人造成的干扰。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
当代水产(2022年6期)2022-06-29
汽车实用技术(2022年7期)2022-04-20
汽车实用技术(2022年5期)2022-04-02
卫星应用(2021年11期)2022-01-19
小资CHIC!ELEGANCE(2019年20期)2019-07-02
新传奇(2018年47期)2018-08-09
中国建筑金属结构(2018年4期)2018-05-23
专用车与零部件(2018年1期)2018-03-25
