
半自动构建扶贫领域知识图谱工具的研究*
2019-09-03 07:22云红艳张秀华
计算机与数字工程 2019年8期
胡 欢 云红艳 贺 英 张秀华
(1.青岛大学计算机科学技术学院 青岛 266071)(2.青岛大学电子信息学院 青岛 266071)
1 引言
进入21世纪,随着互联网的蓬勃发展以及知识的爆炸式增长,搜索引擎被广泛使用。但面对互联网上不断增加的海量信息,仅包含网页和网页之间链接的传统文档万维网已经不能满足人们迅速获取所需信息的需求[1]。人们期望以更加智能的方式组织互联网上的资源,期望可以更加快速、准确、智能地获取到自己需要的信息。为了满足这种需求,知识图谱应运而生[2]。当然,知识图谱并非是一个全新的领域,早在2006年,万维网之父Berners-Lee就提出了链接数据的思想,人们可以将开放链接数据(linked open data)项目中去,通过将不同资源以URL来标识,来实现数据的无缝互联和知识融合。
2 研究问题
近些年,学者在各个角度对扶贫领域做了研究。如从文化扶贫视角、金融扶贫视角、游扶贫视角、精准扶贫视角等对扶贫领域的研究成果进行了梳理。但是,上述研究的内容都是从比较单一的角度对文献回顾[3]。知识图谱能够有效地组织多源数据源,将其内部隐含的单层乃至多层关系,通过目前较为流行的图数据库,展现在网页端。使知识更加凝聚,内容更加明显,有利于整合资源、查看资源、获取资源。本文基于重庆的贫困数据源,构建一套半自动化生成知识图谱以及查询知识图谱的工具。
由于手工构建知识图谱的不便和自动构建图谱的不可实现性。本文基于重庆贫困数据源,构建一套半自动化生成知识图谱以及查询知识图谱的工具。完成的功能包括导入数据、语义映射、查看图谱。导入数据功能模块解析关系数据库中的数据源转化为csv文件,且自动生成图数据库Neo4j中生成图节点的LOAD语句。语义映射功能模块通过语义映射算法,得到关系数据库中表与表之间存在的关系,用于自动生成在图数据库Neo4j中生成关系节点的MATCH语句。查看图谱功能模块中,首先,将存储在Neo4j中的关系图用Echarts组件显示在前端界面;其次,用户输入关系或人物关键字,通过Echarts组件将计算封装的数据显示成对应的知识图谱。
3 结构及框架设计
3.1 总体结构设计
系统的整体框架(如图1所示)遵循三层架构的设计思想,从下到上依次为数据层、业务层、表现层,按照“强内聚,弱耦合”的思想将业务领域进行划分。数据层主要将关系数据库中数据源,自动生成LOAD语句导入图数据库Neo4j中;获取关系数据库中的表名以及字段名,解析构建的OWL文件,自动生成MATCH语句导入图数据库Neo4j中,为上层的业务逻辑提供数据来源。业务层是连接表现层与数据查询层的桥梁,它主要是面向功能服务的,根据业务的需求进行数据的封装、处理和分析等。表现层主要是面向用户提供可视化的界面,负责收集用户的请求数据和对系统的返回数据进行前端渲染。

图1 系统设计框架
系统整体采用B/S结构,后端采用Spring Boot框架构建微服务,提供RESTful接口。前端采用HTML5和Echarts相关技术构建可视化界面,数据库采用Neo4j图数据库和MySQL关系数据库。数据层主要采用Spring Data模块操作Neo4j图数据库,javaCSV API或SQL语句操作MYSQL关系数据库,自动生成LOAD语句导入Neo4j图数据库,jena API解析OWL文件在与关系数据库创建关系,自动生成MATCH语句导入Neo4j图数据库中。业务层主要进行的是数据的处理,通过调用数据层对返回的数据进一步封装,完成数据的统计分析和格式规范。根据需要完成的相关功能进行业务逻辑的编写,并将封装后的数据传递给表现层,数据交换格式采用JSON。表现层将接收到数据传递给前端进行渲染,利用Echarts组件和HTML5实现查看图谱、图谱检索功能。
3.2 功能设计框架
本文设计了半自动化生成知识图谱工具,其功能设计框架(如图2所示)该图谱系统主要包含三个功能模块:导入数据、语义映射、查看图谱。
第一个模块是导入数据。首先,将关系数据库的数据库表转为csv文件,在用文件上传函数接口上传到Neo4j中的import文件夹中。其次,自动生成导入图数据库Neo4j生成图节点的LOAD语句。最后,在将生成的LOAD语句导入Neo4j图数据库,生成图节点。
第二个模块是语义映射。首先,对MySQL关系数据库进行解析,获取数据库表名和字段名。其后,解析构建扶贫领域的OWL文件,利用Jena API解析构建的本体文件,获取其类名以及类与类之间的关系属性。再者,人工确定多张数据库表名,在勾选与其对应的本体中的类名,再通过语义映射算法,映射出结果,其为选中的数据库表之间存在的关系。然后,自动生成导入图数据库Neo4j生成关系节点的MATCH语句。最后,在将生成的MATCH语句导入Neo4j图数据库,生成关系节点。

图2 功能设计框架
第三个模块是查看图谱。针对本工具知识图谱的可视化方面,采用ECharts组件可以实现力导向布局图,描述知识图谱中帮扶人与贫困户之间的关联情况。在图谱检索中,实现按人物查询、按关系查询。如帮扶人与贫困户之间关系查询。首先,发送查询请求;解析请求参数。其次,调用数据查询层,发送最短路径请求给图数据库。然后,Neo4j图数据库返回数据,计算并封装数据。最后,Echarts组件进行渲染。
4 功能实现介绍
4.1 导入数据
Neo4j是由Neo Technology开发的开源图数据库,它是当前主流的图数据库之一,具有高性能、高可抗性、可扩展、支持事务等特点。知识图谱本质是一个图结构,其表现形式主要分为两种:RDF图和属性图[4~8]。RDF图是W 3C官方推荐的语义表示的模型,是用来描述资源以及其关系的三元组的集合,是语义网技术栈中的基石。属性图是由节点、关系和属性三要素构成的图谱,通过这三个元素可以完成任何描述。针对数据间关系的复杂性和动态变化等问题,考虑到后期知识图谱的扩展和维护,本文采用Neo4j图数据库对知识图谱进行持久化存储。Neo4j图数据库具有强性能、易扩展、支持事务、后台可视化等特点,能够有效地组织、存储和更新动态数据及其关联,并提供给高效的遍历算法支持多层复杂查询,在知识存储和知识表现方面具有重要作用。
实现导入数据功能。首些,需要将重庆扶贫数据源生成csv文件。本文中,提供两套方法。第一种方法通过javaCSV API(如表1所示)。

表1 生成csv文件主要方法
第二种方法通过SQL语句生成CSV文件,如使用如下SQL语句将家庭表(jiating)生成csv文件。
SELECT*FROM(SELECT‘表头名’union all select*from jiating)jiatingINTOOUTFILE‘D:\cypher\import\jiating.csv’FIELDSTERMINATED BY‘,’OPTIONALLY ENCLOSED BY‘"’ LINES TERMINATED BY‘ ’.)
其次,将生成的csv文件上传到Neo4j的import文件夹中。采用Apache开源的common-fileupload.jar和common-io.jar实现多文件上传,上传文件用到的主要方法(如表2所示)。

表2 上传csv文件主要方法
自动生成LOAD语句的核心代码如(LOADCSVWITHEADERSROM “file:///pkh_helpperson.csv”AS row CREATE(n:HelpPerson)SET n=row)。最后,将生成的LOAD语句导入图数据库Neo4j中。
4.2 语义映射
实现语义映射功能。首先,需要解析MySQL关系数据库中的数据库表名以及字段名。Java操作Mysql的驱动主要为ODBC和JDBC,本文所采用的是JDBC驱动。由工具的环境是基于SpringBoot微服务,可在程序包中的pom.xm l文件中配置mysql-connector-java,配置版本为5.1.6。配置好驱动,利用 SQL 查询语句:(stmt.executeQuery(“se-lect*from”+“”+tableName);stm t.executeQuery(“select*from”+“ ”+tableName))解析据库的表名以及字段名。其次,解析构建的本体。本体作为领域概念模型的建模工具,形式化的描述领域内的概念及概念之间的关系,是领域知识共同理解的基础,是知识图谱中重要的组成部分。使用本体对数据集进行描述,可以解决知识图谱构建过程中数据集成遇到的语义异构问题。在本文中,我们将以本体扶贫数据源为基础,描述本体构建的相关过程。本体描述语言可以清晰地对领域内概念与概念间的关系进行规范的描述,具备以下特点:明确的语法、丰富的表达能力、对推理的支持、便捷表述。目前主流的本体语言包括XML、RDF(S)、OWL等。
对本文要研究的领域概念进行抽取,主要抽取出类、对象属性、数据属性。结合领域中概念与概念之间的关系,本文抽取的部分三元组如{帮扶人帮扶项目 贫困户}、{贫困户家庭信息家庭成员}。确定了概念与概念之间的关系之后,利用Python第三方库pygraph绘制出扶贫本体的RDF图(如图3所示)。其中类与类之间的对象属性用实心箭头的实线标识,类的数据属性使用实心箭头的虚线标识。

图3 扶贫领域本体
本文构建的OWL文件类有Helper、PoorHouseholds、GovHelp、Family;对 象 属 性 有 has_helper、has_govhelp、has_family。由于本体文件中的类与对象属性为语义映射的输入,则需要对本体文件作进一步的解析。本文采用Jena API,主要方法(如表3所示)。

表3 jena解析本体主要用到的方法
解析出了数据库中的表名、字段名以及本体中的类名以及类与类之间的关系属性。如算法1所示,人工确定多张数据库表名,在勾选与其对应的本体中的类名。再将对应的数据通过AJAX传入后台。由于类与类之间存在着确定的关系。依次判断,若存在相关类,则将解析出来的对象属性传递给结果集,作为数据库表与表之间的关系。若不存相关类,需要人工自定义选中表的关系。
算法1语义映射

得出语义映射[15~16]结果,组织生成导入图数据库Neo4j生成关系节点的MATCH语句(如MATCH(b:BasicInfo),(g:GovHelp),(b1:BangFuXiangMu)WHERE b.id= g.huzhu_id AND g.xiangmumingcheng=b1.xiangmumingchengCREATE (b1) [:BangFuXiangMu{fuchinianfen:g.fuchinianfen,jiansheneirong:g.jiansheneirong}]->(b))。 最 后 ,将MATCH语句导入图数据库Neo4j生成关系节点。
4.3 查看图谱
实现查看图谱功能。主要是采用Echarts控件来实现图谱的查看与检索。ECharts是百度开源的纯JavaScript图表库。目前,百度的ECharts项目已经进入国际顶级开源社区Apache孵化器,ECharts具有丰富的可视化图表类型和深度交互能力的开源可视化库,配置便捷并且支持灵活的定制功能,具备高达千万级数据的可视化能力[9~14]。Echarts控件生成图谱流程大致如表4所示。
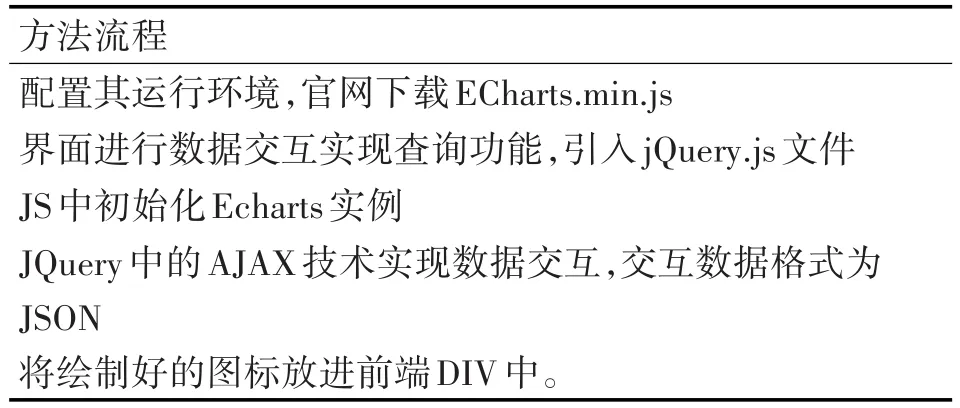
表4 Echarts控件生成图谱流程
图谱检索中,按关系查询,用户通过输入框指定需要查询的两个人名称,如果存在关系,则展示两个人之间存在的最短路径关系图谱,通过不同颜色的节点标识不同的实体类型,通过边的文字显示与方向标识不同的关系类型。如果不存在关系,则显示两个孤立的节点。帮扶人与贫困户之间关系图谱的查询过程如图4所示。

图4 关系图谱的查询过程
用户指定需要查询的两个人名并向服务端发起请求,服务端的业务逻辑层接收参数后进行校验和解析,校验通过后调用数据查询层的方法传入实参。利用Neo4j图数据库最短路径函数shortestPath()对两法人之间的路径进行查询并返回结果集。针对结果集解析和加工。封装成特定格式的JSON数据传递给ECharts组件进行渲染,最终以图谱方式展现。
5 结语
本文基于重庆的贫困数据源,构建一套半自动化生成知识图谱以及查询知识图谱的工具。首先,将存储在关系数据库中的结构化数据构建出扶贫领域本体,以及将结构化数据通过半自动化工具导入图数据库Neo4j中生成图节点。再者,本文提出语义映射算法,将解析的OWL文件中类与对象属性与查询的结构化数据表名之间映射出关系,再通过半自动化工具导入图数据库Neo4j生成关系节点。最后,用户可输入人物或关系关键字,通过Echart组件,将存储在Neo4j图数据库中的数据展现在用户界面,实现查看图谱和图谱检索功能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
齐鲁艺苑(2022年1期)2022-04-19
哈哈画报(2021年10期)2021-02-28
新城乡(2018年6期)2018-07-09
软件导刊(2016年11期)2016-12-22
青春岁月(2016年21期)2016-12-20
领导科学论坛(2016年9期)2016-06-05
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
中国报道(2009年12期)2009-01-15
