
基于粒子群优化的三维CAD模型相似性评价*
2019-09-03 07:22韩文军李达锋姚明昇
计算机与数字工程 2019年8期
韩文军 张 苏 李达锋 姚明昇
(1.国网经济技术研究院有限公司 北京 102209)(2.北京博超时代软件有限公司 北京 102209)
1 引言
随着CAD/CAM等数字化产品发展,大量三维CAD模型成果得以累积,统计表明,产品结构更新时只有约20%为全新设计,而80%其他设计可以通过重用或局部修改来完成[1],因此,如何从海量产品的模型库中挖掘并重用典型结构有利于提高开发效率。
模型典型结构检索方法提供了全新的技术方式,已成为近年研究热点,其主要通过设计一套有效的匹配算法,在三维CAD模型库中搜索含有与需求结构具有最优相似度的模型用以设计重用。张田会等[2]将推理方法与设计知识相结合,提高典型模具的设计效率和重用率;张开兴等[3]利用属性邻接图建立关联图,通过模拟退火算法检索关联图中的最大主团完成相关结构的挖掘和相似评价;刘志等[4]通过视点集渲染模型的轮廓线视图,并构建Gabor变换响应特征库实现相似模型检索;白静等[5]用属性图统一表示模型的非线性特征,采用非线性层次聚类算法对属性图进行聚类。Kim等[6]以自由草图进行建模,对分辨率模型进行形状分布比较来提高模型的形状检索精度;Tao等[7]根据模型面的邻接关系将模型分为不同区域并编码,通过编码比较来度量两模型的相似性;皇甫中民等[8]以B-Re表示中的属性信息构建邻接图,并用图谱方法描述模型的局部特征,采用两层搜索方法检索模型的典型结构。
模型重用中,模型相似性计算起着重要的作用,直接关系到模型中典型结构检索的效率和可靠性[9],为此,在前人研究基础上,文中利用模型面组成边数差异,以此构建模型的面相似性评价矩阵,然后以粒子群算法来搜索矩阵中的的最优面匹配序列,通过最段匹配序列实现对源模型和目标模型的相似性进行评价,为三维CAD模型中主模型结构的智能化检索和有效重用提供依据。
2 模型面相似矩阵构建
三维CAD模型通常由面元素组成,面元素形状的差异,形成了模型的千差万别,因此通过累积两个模型间的面相似情况,可以得到重用前模型的相似情况[10]。如果组成两个面的边的数目相差较小,则两模型存在较高的相似度;反之则有较低的相似度。如图1所示为描述模型的面相似性使用的模型示例,图中模型A包含u1,u2,…,u7七个面,其中面u1与u5,u6,u2,u7四个面相邻接,则面u1的组成边数为4,同理可以得到,面u2,u3,u4,u5的组成边数为4,而面u6,u7的组成边数为5。则图1中两个示例模型的相似度可以通过式(1)来计算,即

式中,N(u)表示某模型的面u含有的组成边数,max(·)表示取最大值。
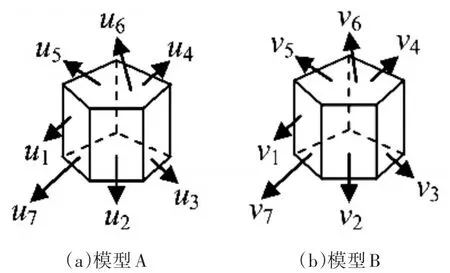
图1 模型面相似计算示例
式(1)说明当 S(ui,vj)值越大,说明两个面的边数N(ui)与N(vj)差异越小,两个面的形状越相似,使用S(ui,vj)可以构造待评价两模型的面相似度评价矩阵SAB,两模型的面序列分别为矩阵的行和列。
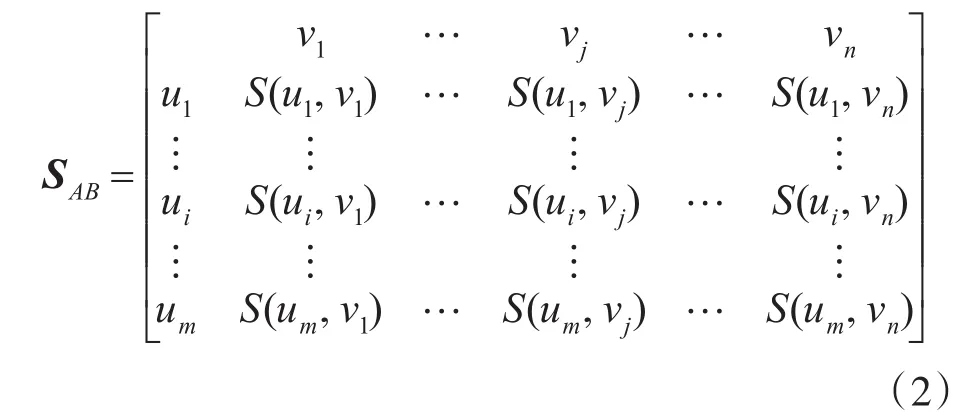
式中,m和n分别表示待评价的两模型的面数,为便于后续相似性分析,如果两模型面数不一致,则当m>n时,将SAB进行转置处理。
组成两模型的面的相似度影响着两个模型的相似性,两模型之间的面相似度越高,两模型之间的相似性越高[13]。根据式(1)和式(2),图1两模型中,u1,u2,…,u5与 v1,v2,…,v5分别与另外四个面相邻接,因此 SAB中其对应的相似度值为1,而u6,u7与 v6,v7分别与5个面相邻接,其与其他面之间相似度值为0.8,从而得到图1中两模型的面相似性评介矩阵为

3 基于粒子群算法的模型面匹配
两模型的组成面相似度越高,则模型相似度也越高[12],为此以面相似矩阵,通过粒子群算法来匹配两模型之间的面最优匹序列,进而评价相似情况。
设算法在d维空间进行最优匹配搜索,种群规模为 p,xt为粒子t所在的位置,vt为粒子t的飞行速度,和表示算法经过k次迭代后全局和粒子个体的最优位置,相应的适应度函数分别表示为和。算法在实现过程中通过和不断迭代更新和实现最优匹配序列的搜索,其过程为[13]
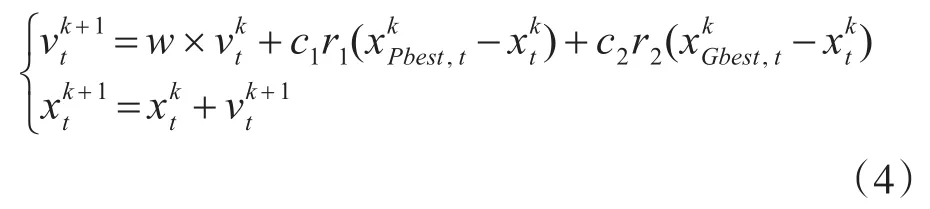
式中,k为当前迭代数,w为惯性因子,c1和c2为算法优化的学习因子,r1和r2在迭代过程中在[0,1]内随机取值。设粒子t在SAB中的位置向量为 xt=(j(1),j(2),…,j(m)),则其适应度函数计算式为

式中,j(i)为模型A中第i(i=1,2,…,m)个面经粒子群算法得到模型中的最优匹配面。
4 实验验证分析
为验证文提出算法的有效性,以Open CASCADE为平台构造几何造型,选取普渡大学的ESB模 型 库[14]中 的 部 分 模 型 ,在 Inte(R)Core™i5-7400HQ CPU,4G内存的计算机硬件下进行实验。
4.1 算法有效性实验
如表5所示为以典型盘形结构为实验源模型,文中算法与基于网络本体语言(Wol-Sim)[11]和基于蚁群算法(Acs-Sim)[15]的模型相似性评价算法在ESB模型库中进行相似性模型搜索实验结果,从表中结果可以看出,相对于基于蚁群算法的相似性评价方法,文中算法通过搜索两模型的最优匹配序列,从而可以搜索到模型库中含有多层次相似性的模型,其搜索结果更相似性感知,而基于蚁群算法的模型相似性评价算法的实验结果中,第2个和第6个模型并不是期望得到的重用模型,而相对于基于基于网络本体语言的模型相似性评价算法,文中算法搜索到的模型数量更多,且部分具有高复杂度的模型也被搜索到,便于设计人员更好地进行模型重用和深度挖掘。

表1 三种算法对盘形结构进行相似性评价实验结果
4.2 算法性能比较实验
为充分验证文中算法的模型相似性评介性能,选取20个经典重用模型结构,以70%的相似度为评价阈值,人通用ESB模型库中搜索存在经典结构的模型,每个经典结构进行50次重复实验,取平均值,然后20个经典结构的实验结果再进行平均,得到每个算法的平均查全率和平均查准率,获得PR曲线如图2所示,PR曲线的理想结果为查准率等于的恒定直线,对于实验结果,曲线位置越靠近理想曲线,说明算法的相似性评价性能越好,对模型的检索精度越高,从图2的PR曲线结果看出,文中所提算法的重用结构检索性能优于Acs-Sim和Wol-Sim算法。

图2 实验结果平均PR曲线
5 结语
为实现典型模型结构的高效重用,提出了基于粒子群算法优化的CAD模型典型结构相似性评价算法,算法首先由组成模型各面的边的数目构造相似性评价矩阵,通过粒子群算法搜索两模型的面最优匹配序列,并计算面相似度,整合为模型的相似度。实验结果表明,与已有算法相比,所提算法可以更准确地描述三维模型的典型结构相似性。
猜你喜欢
现代英语(2021年18期)2021-11-22
技术与创新管理(2020年5期)2020-10-09
初中生学习指导·提升版(2020年9期)2020-09-10
哈尔滨理工大学学报(2020年3期)2020-08-26
科学与财富(2019年27期)2019-10-25
意林(图解作文)(2019年6期)2019-07-16
科学与财富(2017年28期)2017-10-14
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
数理化学习·高一二版(2009年2期)2009-03-30
