
基于K-m eans算法的案件预测应用*
2019-09-03 07:23王健豪
计算机与数字工程 2019年8期
王健豪 苏 勇
(江苏科技大学计算机学院 镇江 212003)
1 引言
现在大数据与云计算是计算机发展的主流,那么在新时期背景下,公安信息化成为了公安工作的重要内容[1]。面对大量案件物证信息的堆积,那么如何充分挖掘这些数据中隐含的规律,提高公安部门办案效率,有效降低犯罪率,为公安部门提供决策依据,而不是仅仅进行一些基础的查询和统计。聚类分析是数据挖掘的一项重要技术[2],目的在于分析事物的内在联系和本质。所以是一种不错的选择。聚类算法分为基于划分的、密度的、分层的、网络的、模型的等类型[3]。K-means算法是一种基于划分的的聚类算法,其算法易于实现、效率高、可以高效处理大数据集合[4]。经典K-means算法由于其选择初始簇中心具有随机性,会导致以下一些缺点:1)随着数据集合的改变,聚类可能会失去稳定性[5];2)聚类结果很多情况下是局部最优,而不是我们要求得全局最优[6];3)聚类分析的总耗时会随着迭代次数的增加而增加[7]。很多K-means的优化算法为了削弱这些缺点而相继产生,如文献[8]提出的K-means算法,是基于最优划分的。其核心思想:在数据集中取出样本,然后根据样本的特性把它分为不同的类型,最后根据样本类型的不同来确定初始的聚类中心。该改进算法优化了算法的效率,提高的聚类的准确率,但其缺陷也很明显,比如如果数据集需要超高维度,那么算法的复杂度会呈几何度增加。文献[9~11]提出对不确定性数据集的挖掘方法。文献[12]提出的高效聚类算法,使得K-means具有局部最优性。该算法主要是利用了数学上的图的优点,通过构建加权连通图,然后利用这种由子簇交集产生的连通图的特性去合并,进而优化聚类效果,但其着重点在于局部,而不是全局,所以其聚类精度还是有所欠缺。文献[13]提出的改进方法在于利用样本的局部密度去初始聚类中心从而提高聚类效果;文献[14~20]也是在K-means算法的初始化上做了优化;那么考虑到在某市尝试案件物证信息分类的作用是为相关部门提供决策,准确性是第一位的,通过对多方面改进算法的学习和思考,本文采用在聚合度较高的样本中,选择聚类中心,然后求方差可以使聚类中心紧凑,实现分类的自动化、定时化,保证结果的客观性。
2 K-m eans算法
K-means算法[21]是一种基于划分方法的聚类算法。不同样本的相似性一般通过样本间的欧氏距离作为评价依据。其核心思想:1)在给定的数据集中随机的去选取一定数量的的初始聚类中心(数量假设为k),然后计算数据集中样本到初始聚类中心的欧式距离d,根据欧式距离d与初始聚类中心的远近来确定当前样本属于哪个聚类中心的范围,继而初始的分为k个类;2)在每个类中重新计算(通常为各个类中样本的平均值)得到新的聚类中心,循环步骤1),知道聚类中心趋于稳定。
一般情况下,我们可以通过误差平方和来作为标准,其定义为

其中:k为簇的数量;Xi为簇Ci的聚类中心,即平均值。K-means算法步骤如下:
输入:簇的数量k、样本集中样本个数N,递归终止条件ε,最大递归次数tatal。
输出:算法终止后的聚类中心的个数k、递归次数s。
1)随机初始化k个簇中心。
2)对数据集中的每个对象,计算其与各个聚类中心的距离,并选择距离最小(相似度最大)的聚类中心,将该对象归入该聚类中心所处的簇。
3)通过平局值重新计算每个簇的聚类中心,并使用式(1)得出测度函数值E。
4)如果达到最大递归次数或满足:

则算法结束;否则返回2),继续循环执行。
其中:E1和 E2分别代表前后两次递归的测度函数值,ε值极小,上式表示簇内误差平方总和已经收敛,即聚类中心基本上不发生变化。
3 本文核心算法原理
数学领域中,通常使用方差和标准差来测算样本离散趋势。样本方差或样本标准差越大,数据的浮动就越大。方差用来度量随机变量与其数学期望(即均值)之间的偏离程度,是测算数值型数据离散程度的最重要方法。因此通过方差可以降低孤立点对聚类中心的一些影响。
本文算法与经典K-means算法随机确定聚类中心不同,在于确定的聚类中心位于比较密集区域中。
算法步骤:设D为数据集
1)确定K个聚类中心
(1)求出样本集中不同样本间的平均距离ave-Distance:

其中dis(xi,xj)为样本 xi与样本 xi之间的欧式距离,n为样本总个数。
(2)在数据集中找出一个样本 x1,使得dis(x1,xi)< aveDistance,其中1<i<n;并且令:

(3)重复(2)直到找到K个聚类中心。
2)按照经典K-means算法步骤即可。
4 实验结果
在某段时间阶段内的某个地域上的人工模拟数据集上的聚类准确率如图1~2(图1和图2分为为数据集为1000,2000时的实验数据)。
经过对比,可以看到本文改进的K-means算法相对于经典的K-means算法具有较为准确的分类效果。
5 案件预测
根据上述方法,并结合以往时间段、地域等因素,我们可以得出不同时间不同地域不同案件的发生数量、发生比例,相关部门便可以根据曲线图的趋势做出对应的决策,维护社会治安。

图1 数据集为1000时的实验数据
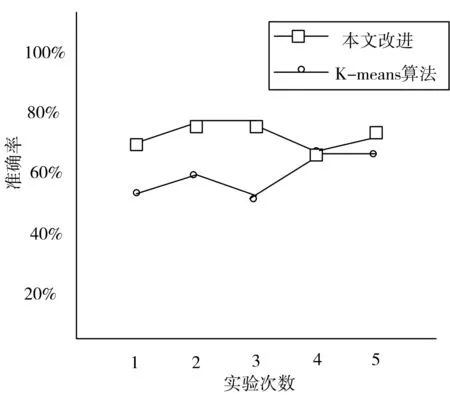
图2 数据集为2000时的实验数据
6 结语
本文着重通过算法上初始聚类中心的自动化选择上去改进K-means算法,提高算法聚类的准确率,尽量降低传统K-means算法中孤立点对聚类的影响。由于主要目标是为了相关部门人员分配的参考,故这里聚类中心只需要几个。下一步的研究方向是针对本算法中的不足,研究如何自动确认适合的聚类中心,并优化算法分类的准确率,以便为相关部门提供以为有力的参考依据。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
健康体检与管理(2021年10期)2021-01-03
初中生世界·九年级(2017年10期)2017-11-08
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
