
基于DCNN的井下行人监测方法研究*
2019-09-03 07:23张应团郑嘉祺
计算机与数字工程 2019年8期
张应团 李 涛 郑嘉祺
(西安邮电大学计算机学院 西安 710061)
1 引言
行人检测是一种能够通过输入图片或视频帧来判断其是否存在行人,并将行人的位置信息表现出来的技术,它在智能视频监控领域、车辆辅助驾驶领域以及人体行文分析领域中的第一步[1]。传统目标检测的方法一般“三步走”:第一,在被检测的图像上划分出一些候选的区域。第二,对这些区域进行特征提取。第三,使用已经训练好的分类器模型进行分类[2]。利用传统的目标检测方法设计一个能够适应目标的形态多样性、光照变化多样性、背景多样性等影响的特征并不是那么容易,但是分类好坏的决定性因素就在于特征的提取。传统目标检测方法中常用的特征有尺度不变特征变换(Scale-invariant feature transform,SIFT)[3]、方向梯度直方图(Histogram ofOriented Gradient,HOG)[4]。常用的分类器主要有SVM、Adaboost等。近几年在图像识别和视频监控领域中,深度学习和神经网络大显身手。深度学习是近十年来人工智能领域取得的最重要的突破之一[5],它在语音识别、自然语言处理、计算机视觉、图像处理与视频分析、多媒体等诸多领域都取得了巨大的成功[6]。
图像分类方面,2012年ImageNet大规模视觉识别挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Competition)上,由Geoffrey Hinton教授和他的学生Krizhevsky首次提出使用卷积神经网络来处理ILSVRC分类任务,将Top-5 error降低到了15.3%,而使用传统方法的第二名top-5 error高达26.2%[7],卷积神经网络第一次在图像处理中展现了其强大的实力。2014年,来自Facebook的科学家Ross B.Girshick使用Region Proposal加上CNN(Convolutional Neural Network)代替传统目标检测使用的滑动窗口加手工设计特征,设计了R-CNN(Region-Convolutional Neural Network)框架,使得目标检测取得巨大突破。R-CNN在PASCAL VOC2007上的检测结果从DPM HSC的34.3%直接提升到了 66%mAP(mean Average Precision)[8]。2015年何凯明等在Spatial Pyramid Pooling in Deep ConvolutionalNetworks for VisualRecognition论文中提出了SPP-NET[9],它优化了R-CNN的检测流程,大大提高了R-CNN的速度。Ross B.Girshick教授又提出了Fast R-CNN,它在SPP-NET的基础上加入了多任务损失函数,在训练过程中直接使用softmax代替SVM分类,提高了训练和测试的速度和便捷性[10]。基于回归的目标检测算法代表是YOLO目标检测系统。
2 YOLO目标检测系统
YOLO方法是在2016年CVPR(IEEE Conference on Computer Vision and Pattern Recognition,IEEE国际计算机视觉与模式识别会议)上提出的一种目标检测方法。YOLO系统的理论基础就是卷积神经网络。其最大的不同就是它将物体检测的框架设计成了一个回归问题,YOLO系统将目标检测所需要的各个部分全部放入到了一个神经网络当中,神经网络使用整幅图像的特征去预测每一个范围框的参数,同时也能够预测整个图片里包含的所有目标种类的范围框。也就是说只需要使系统“看”一次图像,就能够得出目标的种类以及它所在图片的位置,因此这个方法才取名YOLO(You Only Look Once)[11]。YOLO系统的设计能够让训练成为端对端的并且速度非常快,同时又能够满足较高的平均检准率(mean Average Precision,mAP)。
YOLO系统的网络包含卷积层和全连接层。卷积层负责提取图像的特征,全连接层负责输出范围框的中心点坐标及长宽和检测概率。YOLO的网络结构借鉴了GoogLeNet的图像分类模型,去掉了GoogLeNet中起始模型(Inception Module)里的预先层(Previous Layer)[12],只简单地在3*3卷积层后面接了一个1*1的卷积层来降低特征空间。整个网络结构包含24个卷积层和2个全连接层。
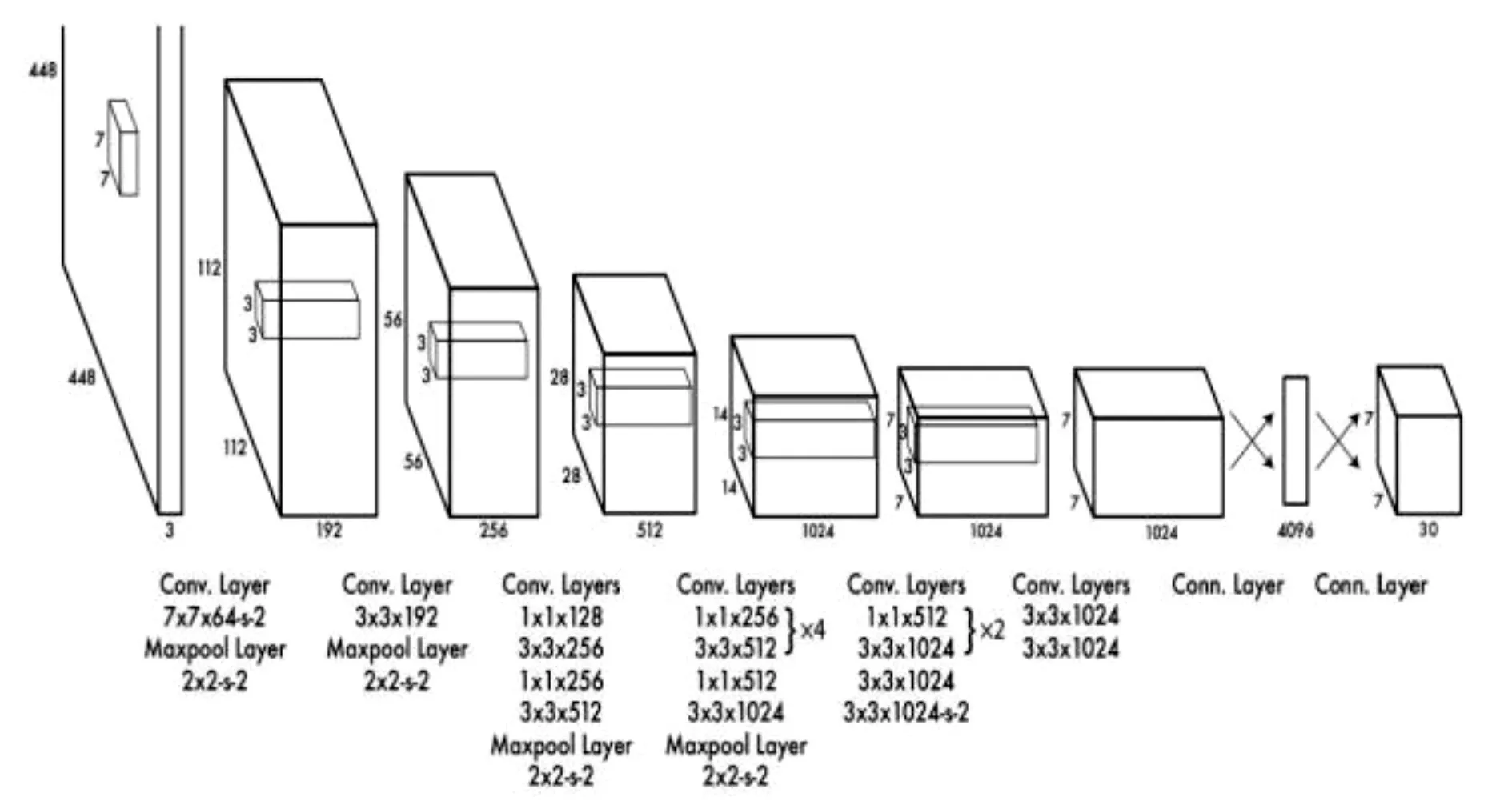
图1 YOLO基本网络结构示意图
YOLO的最大优势是它的检测速度非常快,这受益于将检测问题转换为了回归问题,所以它不需要太复杂的结构。以上述结构为例,在Titan X GPU上检测的检测速率能够达到45帧每秒。
目前最快最好的检测方法FastR-CNN比较容易误将图像中的背景区域检测成物体,因为它检测的范围比较小。YOLO的背景误差要比Fast R-CNN小一半多。虽然YOLO在检测的速度上已经非常快了,但是在检测精度上仍然落后于目前最好的检测系统。因为其强烈的空间约束,导致YOLO在对小目标和多重目标上的检测精度还不够好。
3 YOLO的改进及测试
虽然新版本的YOLO性能表现良好,其检测速度和精度都有了提升,然而在井下的环境中,光照环境差、背景单调、检测目标较为单一、且监控视频数据为单通道、图片噪声比较大,如果直接使用YOLO检测系统来对井下环境的目标进行检测,会导致精确度不高,而且检测效果非常差,如图2,使用原YOLO系统无法检测出井下环境中的人。

图2 使用原YOLO系统的检测结果
3.1 改进的思想
矿井下的环境与自然光场景下有着极大的不同,所以训练集必须要符合井下的环境要求。局限于YOLO的缺陷,其检测小目标和多重目标的效果较差,针对这一点,调整其网络结构来改进最后网络的检测结果。所以本文对YOLO的改进主要包含两个方面,一是选择新数据集重新训练模型,二是改进其网络结构。
2016年12月YOLO在其官网上发布了新版本YOLOv2[13],在新版本中对原有的YOLO系统进行了许多改进。所以本文的改进是基于新版本的YOLO系统的。
3.1.1 数据集的选择
数据集选择井下的监控视频转换生成的图片集。真实生产环境的图片可以减小由于网络泛化能力对检测结果带来的影响。这样训练出的神经网络模型在应用时能够直接作为实际应用的模型,不用再做更多的调整。
3.1.2 网络结构上的改进
YOLO对于临近物体的检测效果不好,对于图片细节上的处理还有待于提高,调整其网络结构,能够使其更好的保存网络的细节特征。
在深度神经网络中,网络的层数越深,其提取的特征就越抽象,图像的语义信息就越清晰。所以如果能够结合来自深层的语义信息和来自浅层的表征信息作为网络的最后输出,在理论上就能够提升原YOLO网络中对于细节上的处理。
原YOLO系统的网络结构共包含22个卷积层,通过大量的实验发现,提取第8层卷积层的特征与输出结合效果最好。在此基础上,根据如上的改进思想,本文提出了二种改进方案:
方案一:先卷积后下采样,考虑到卷积后生成的特征图经过采样会丢掉一部分原有的信息,因此交换卷积层和下采样层的顺序,即在原YOLO网络结构中的第8个卷积层后的下采样层后再添加一个下采样层,然后再接一个卷积层,这时的卷积后的输出特征图大小直接就为13*13,再与网络最后的输出相加作为整个系统最后的输出。方案一的网络结构如图3所示。
方案二:考虑到采样对于特征图信息的损失,在此方案中,仍然在第8层卷积层后的下采样层添加一个卷积核大小为1*1,数量为30的卷积层,不再添加下采样层,这时此卷积层的输出特征图大小为26*26。然后将原网络的输出特征图大小由13*13调整为26*26与新添加层的输出匹配,最后将这两层的结果相加作为整个检测系统的输出。本文中将大小为13*13的特征图调整为26*26所采用的方法为反卷积的方法[21]。方案二的网络结构如图4所示。
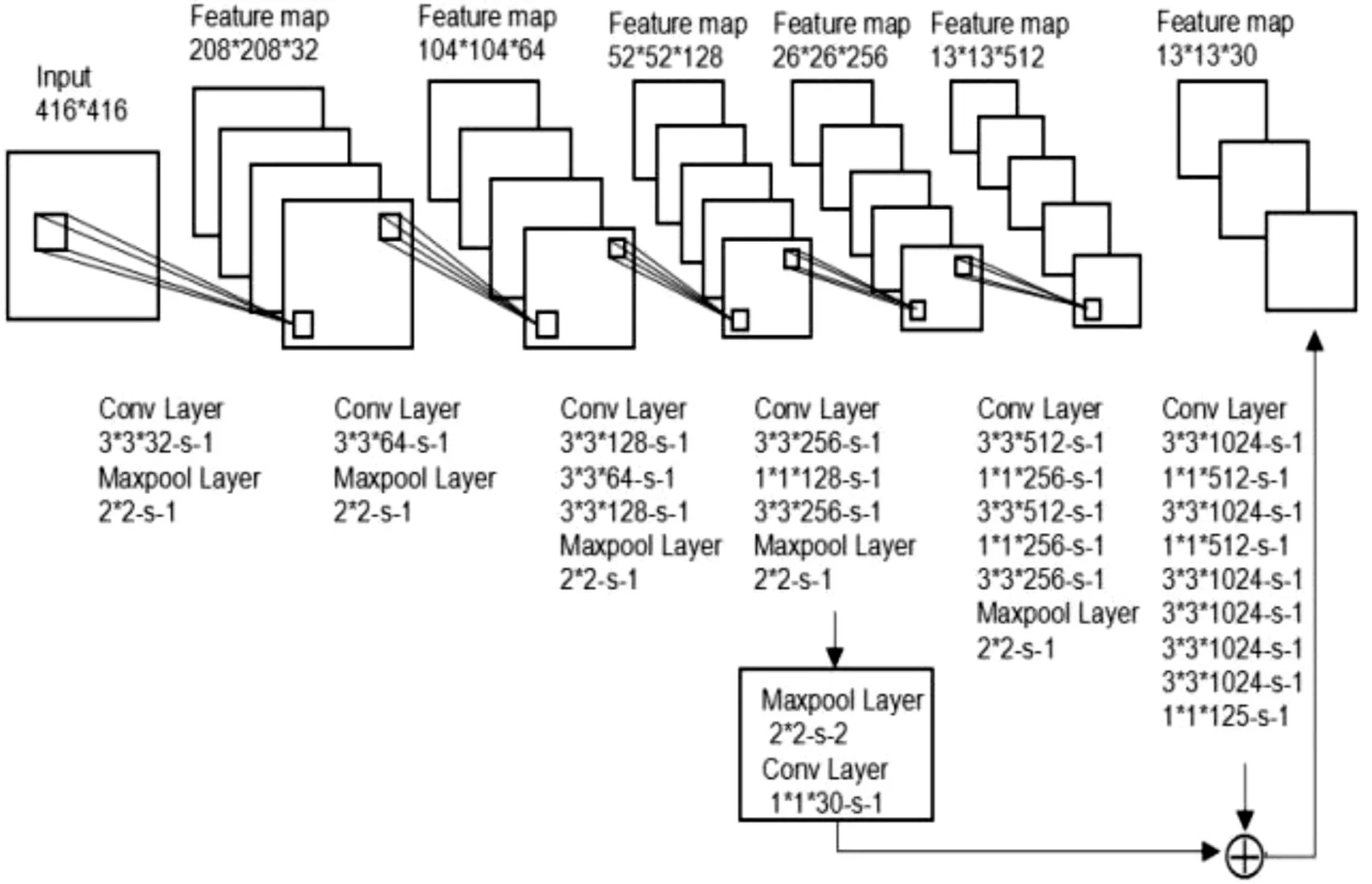
图3 方案一的网络结构

图4 方案二的网络结构
其中Deconv Layer为反卷积层[14],目的是扩大特征图的大小。
3.2 网络的训练
为了对比两种网络结构与原网络结构的结果,在训练中两个方案与原网络除网络结构和训练次数外,训练过程以及其他训练相关参数的设定都是相同的。
3.2.1 网络的预训练
本文所采用的预训练模型与原YOLO系统的预训练模型一致,都是在ImageNet上经过20万次训练的模型。
3.2.2 训练数据集处理
训练集采用正通煤矿副井底进车侧的监控视频,经过转换筛选共生成数据集11605张图片。网络的输入是静态二维的图片信息,摄像头采集到的视频需要预先处理成格式化的图片,以符合网络输入端的需求。
首先对摄像头采集到的原始图片进行预处理,对其进行统一缩放到416*416像素,缩放之后对人体轮廓信息损失不大,但有效地减小了网络的计算量,然后每张图片都利用LabelImg工具进行人工标注,标注后每张图片会生成对应xm l文件,深度网络需要的数据量非常巨大,于是使用Data Augmentation[15]技术对图片进行了扩增。
数据集的构成采用VOC数据集分割的基本思想,将全部数据集的百分之五十设定为验证集,剩下百分之五十中的一半设定为训练集,另一半设定为测试集。所以最终的数据集分为验证集共5800张图片,测试集共2900张图片,训练集共2900张图片。
3.2.3 损失函数的设计
网络中最后一层的输出负责预测目标种类的概率和范围框的坐标和长宽。首先对范围框的长宽与图片的长宽进行归一化处理,使得范围框的长宽取值在0~1之间。同样将范围框中的坐标通过栅格的偏移也归一化到了0~1之间。最后一层的激活函数选择了线性激活函数,其他层使用弱矫正函数作为激活函数(式(1))。最后使用误差平方和的方式来优化输出的结果。
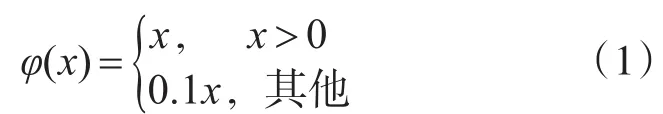
选择误差平方和的原因是它简单,但是用它无法达到最佳的检测效果,因为把范围框的位置误差和类别误差放到一起优化本身就是不合理的。而且将图片划分为n*n的栅格后,有些栅格里不包含任何的目标,这些置信度为0的栅格的梯度更新的范围会非常大,这样就会以压倒性的优势覆盖掉包含物体的栅格梯度的更新,这就会导致模型非常不稳定,而且有极大可能造成网络的发散。

图5 大小范围框敏感性曲线图

从上式可以看出,只有当栅格里存在待检测目标时,才会对分类错误进行惩罚,也只有当某个范围框对某个物体检测负责的时候,才会对范围框的位置参数进行惩罚。
3.2.4 其他训练参数的设定
1)训练次数的设定
原网络训练了45000次,每次训练8张图片(batch size=8)。考虑到改进后网络结构相比于原来更加复杂,所以方案一训练了50000次,方案二训练了60000次。
2)学习率的设定
学习率是负梯度的权重。在训练中,学习率在开始时会选择一个较小的值,因为若从较大的学习率开始,通常会因为其带来的不稳定的梯度导致模型发散。
3)动量(momentum)的设定
动量是上一次更新值的权重,它能够使得网络的权值更新更加平缓,使得学习过程更为稳定、迅速。动量设定为0.9。
3.3 测试网络结果及对比分析
搭建Caffe深度学习框架并配置好所有训练参数后,开始网络的训练。本文所使用的GPU型号为GTX980ti,平均每个模型的训练时间约为32h。训练完成后,对每个模型进行测试,得到其mAP值,然后根据mAP值来做模型的效果对比。
本文以VOC2007计算mAP为标准,当范围框与真实值的IOU达到0.5以上,就认为是已经检测出结果。表1为原YOLO与二种方案的mAP值对比。

表1 mAP值对比
由表1可看出,原YOLO在训练到35000次左右开始收敛,最大的mAP值能够达到0.818167。方案一的性能明显比原YOLO好,其mAP值最高达到了0.906555,说明方案一的改进是有效的。方案二的mAP值最高,达到0.908375,方案二在精度上是所有方案里最高的。
虽然精度上方案二最高,但是通过FPS对比可以发现,原YOLO的FPS能够达到50.2,由于方案二在原来的基础上添加了一层网络,其FPS能够达到40.0,比原来的速度稍低,而方案二的网络最为复杂,并且其中加入了反卷积,所以它的FPS只有6.2左右,这样的速度是无法满足实时检测的。
通过以上分析,在满足实时检测速度的前提下,本文选择了方案一中mAP值最高的模型(训练了47500次后的模型)作为整个井下行人检测系统的最终神经网络模型。图6、图7为此模型与原YOLO训练次数为35000次在单张图片上的检测效果对比。

图6 原YOLO测试结果

图7 方案二测试结果
4 结语
本文通过结合煤矿企业井下行人检测的需求与深度学习网络的优势,提出了一种采用深度卷积神经网络YOLO方法。本文对YOLO的网络结构和损失函数进行了改进,虽然其检测速度很快,但是其精度可以再提升。在后续的工作当中,应该将重点放在不损失速度的条件下,通过不断的设计和实验新模型,使得其精度能够进一步提升。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机系统应用(2019年9期)2019-09-24
电子制作(2019年24期)2019-02-23
科技视界(2016年18期)2016-11-03
