
基于图形处理器的形态学重建系统
2019-09-04 10:14何希吴炎桃邸臻炜陈佳
计算机应用 2019年7期
关键词:并行计算
何希 吴炎桃 邸臻炜 陈佳

摘 要:形态学重建是医学图像处理中非常基础和重要的操作。它根据掩膜图像的特征对标记图像反复进行膨胀操作,直到标记图像中的像素值不再变化为止。对于传统基于中央处理器(CPU)的形态学重建系统计算效率不高的问题,提出了使用图形处理器(GPU)来加速形态学重建。首先,设计了适合GPU处理的数据结构:并行堆集群;然后,基于并行堆集群,设计和实现了一套基于GPU的形态学重建系统。实验结果表明,相比传统基于CPU的形态学重建系统,基于GPU的形态学重建系统可以获取超过20倍的加速比。基于GPU的形态学重建系统展示了如何把基于复杂数据结构的软件系统高效地移植到GPU上。
关键词:图形处理器;形态学重建;并行计算;并行堆;并行数据结构
Abstract: Morphological reconstruction is a fundamental and critical operation in medical image processing, in which dilation operations are repeatedly carried out on the marker image based on the characteristics of mask image, until no change occurs on the pixels of the marker image. Concerning the problem that traditional CPU-based morphological reconstruction system has low computational efficiency, using Graphics Processing Unit (GPU) to quicken the morphological reconstruction was proposed. Firstly, a GPU-friendly data structure: parallel heap cluster was proposed. Then, based on the parallel heap cluster, a GPU-based morphological reconstruction system was designed and implemented. The experimental results show that compared with traditional CPU-based morphological reconstruction system, the proposed GPU-based morphological reconstruction system can achieve speedup ratio over 20 times. The proposed system demonstrates how to efficiently port complex data structure-based software system onto GPU.
Key words: Graphics Processing Unit (GPU); morphological reconstruction; parallel computing; parallel heap; parallel data structure
0 引言
形态学重建(morphological reconstruction)是医学图像处理中非常基础和重要的操作。它根据掩膜图像的特征对标记图像反复进行膨胀操作,直到标记图像中的像素值不再变化为止。其中的标记图像(Marker Image)和掩膜图像(Mask Image)是两张尺寸相同的高像素医学图像。在标记图像的膨胀操作中,符合扩散条件的像素点会不断地向邻接的像素点传播其像素值。假设I(e)、I(f)是标记图像中相邻的两个像素点,J(e)是掩膜图像中与I(e)位置相对应的像素点,那么I(f)对I(e)发生扩散的条件如下:
如图1(a)所示,标记图像中像素点O的像素值(32)比其邻接像素点C的像素值(17)大,而且C在掩膜图像中位置相对应的像素点C1的像素值(45)也比C的数值大,于是O的像素值在膨胀操作中扩散到了它的邻接像素点C(如图1(c))。接着,C的像素值又会通过其邻接像素点进一步地扩散。这种像素值的扩散会不断迭代地进行下去,直到标记图像中的像素值不再变化为止。形象地理解形态学重建,标记图像中较大的像素值会像“水”一样四处扩散。如果没有掩膜图像,那么当形态学重建结束时标记图像里所有的像素值都会变成标记图像中某个最大的像素值,而掩膜图像就像“高山”一样阻挡了标记图像中像素值任意的传播,使得像素值扩散只在若干个隔绝的区域中发生。由于标记图像,掩膜图像的超高分辨率(有些图像分辨率可以达到51200×51200,102400×102400),并且随着传感器技术和扫描设备的提高,图像的分辨率会越来越高,形态学重建是一个计算量很大的问题。考虑到形态学重建里像素值扩散的迭代特性,传统的算法使用了队列来跟踪像素点的扩散过程,然而队列是按照像素值的扩散顺序而不是像素值的大小来决定下一次迭代中像素值扩散的先后顺序,使用队列会导致频繁出现对于同一个像素点的多次像素值扩散。形态学重建的计算量会因此大幅度提高。这个问题促使了在形态学重建中使用以像素值大小为优先级的优先队列,由优先队列先选出具有较大像素值的像素点让其像素值先扩散以避免较小像素值的扩散,从而可以大幅度减少形态学重建的计算量。
现代的NVIDIA图形处理器(Graphics Processing Unit, GPU)是一個可编程的基于众核架构的处理器。每一个图形处理器包含若干个流处理器(Streaming Multiprocessors)。每个流处理器上有32个或者更多的计算单元以及存取速度很快但数量有限的寄存器和共享内存(Shared Memory)。同时,每个图形处理器上还配有所有流处理器都可以访问的全局内存(Global Memory)。运行在图形处理器上的CUDA(Compute Unified Device Architecture)程序可以启动成百上千线程同时执行任务。这些线程是以线程组的形式组织起来的,每个线程组会由图形处理器的硬件调度系统分配到最空闲的流处理器上执行。图形处理器强大的计算能力使得很多传统问题的计算时间缩短了十几倍甚至是几十倍至原来的十几分之一甚至几十分之一此处表述不当,应该为缩短至原来的十几分之一甚至几十分之一。形态学重建问题涉及的是高像素图像以及由此产生的很多的细粒度任务,它非常适合使用图形处理器来加速其计算过程,而如何设计基于图形处理器并且适合形态学重建的并行优先队列决定了能否高效地把形态学重建以及别的类似应用移植到图形处理器上进行加速处理。
1 相关工作
1.1 形态学重建
文献[1]详细描述了传统上形态学重建的几种算法,本文简单地介绍三种。
第一种算法称为顺序重建法(Sequential Reconstruction),这种算法依赖不断地正向扫描和反向扫描标记图像,直到在一轮扫描以后再也找不到符合扩散条件的像素点为止。正向扫描指的是从图像中最左上的像素点开始,到最右下的像素点为止,以从上到下、从左到右的顺序扫描图像中的每一个像素点,而反向扫描恰恰和正向扫描相反,它是从图像中最右下的像素点开始,到最左上的像素点为止,以从下到上、从右到左的顺序扫描图像中的每一个像素点。在扫描过程中,一旦发现某个像素点符合扩散的条件,就会立即执行像素值扩散操作,将其像素值赋给邻接像素点。
第二种算法称为快速混合重建法(Fast Hybrid Reconstruction)。这种算法首先会运行一次正向扫描和一次反向扫描,对标记图像执行初步的膨胀操作,并把有扩散可能的像素点收集起来放进一个先进先出队列中,然后,对于队列里的像素点,快速混合重建法会逐个取出来,尝试把像素点上的像素值向其邻接像素点扩散,并且把被扩散的邻接像素点添加到队列里。上述操作会持续进行下去,直到队列为空为止。对比顺序重建法,快速混合重建法更加有效率,因为它只需要处理有扩散可能的像素点,而不需要像顺序重建法一样反复进行全局的扫描,但是快速混合重建法也有可以提高的地方,例如其中很多像素值的扩散操作是对同一个像素点执行的,因而是重复的计算。
第三种算法称为下坡过滤器(Downhill Filter)[2],与第二种算法不一样的是,它使用了一个队列,把有扩散可能的像素点按像素值大小进行排序,先处理像素值较大的像素点,避免了像素值较小的像素点的扩散,从而减少了整个形态学重建的计算量。
1.2 基于图形处理器的并行数据结构
基于中央处理器的数据结构已经被研究了很多年,但是基于图形处理器的并行数据结构研究还是非常有限。考虑到本文涉及了图形处理器上并行数据结构,首先对这个领域作一个简述。
当图形处理器开始应用于解决一般问题时,研究人员尝试把各种传统数据结构转变成适合众核架构的并行数据结构。文献[3]按照广度优先的顺序构造KD(请补充KD的英文全称。回复:这个从原来的英文名字翻译过来的。原来的名字叫kd-trees或者k-d tree. 国内的文献一般叫KD树或者kd-树(在中国知网上搜索"KD树"可以看到相关文章). 我觉得就叫KD树吧。)-树,并且对大节点采用了新颖的构造算法以充分利用图形处理器的计算能力。文献[4]针对前者在构造KD-树过程中消耗了过多图形处理器内存的问题提出了按照部分广度优先的顺序构造KD-树,牺牲一部分并发性以换取内存的大量节省。文献[5]中提出了一种在图形处理器上表面积启发式构建KD树的并行方法。其他基于树的数据结构,例如八叉树(Octree)[6-12]、决策树[13-14]、层次包围盒(Bounding Volume Hierarchy)[15]也已经在文献中被讨论了如何移植到图形处理器上。文献[16]通过把包含指针的操作转化为数组操作,设计出了一种高效率、适合图形处理器的跳表结构(Skiplist)。在文献[17]里,研究者们在完美哈希表(Perfect Hash)[18]和布谷鸟哈希表(Cuckoo Hash)[19]的基础上设计出了一个适合图形处理器的并行哈希表。文献[20]中提出了在图形处理器中实现布隆过滤器(Bloom Filter)的方案。对于集合,文献[21]中提出了图形处理器中新颖的集合数据组织方式以及实现集合相交的算法。在图方面,文献[22]使用了多层队列的方式在图形处理器中加速了广度优先图的遍历。文献[23]解决了如何并行计算最小生成树的问题。
1.3 并行优先队列
单线程优先队列有不同的实现方式,包括二元堆(Binary Heap)[24]、二项堆(Binomial Heap)[25]、斐波那契堆(Fibonacci Heap)[26]等。一般来说有三种方式来并行化优先队列。
第一种方式是使用多个计算单元来并行化单个元素的入队列或者出队列操作[27],缩短了單个操作的时间。
第二种方式是允许优先队列里同时有多个单线程入队列和出队列操作[28],减少了单个操作的平均时间。
第三种方式则是既允许入队列操作和出队列操作同时进行,又使用多个计算单元来并行化入队列和出队列操作[29]。
本文的主要工作有两点:
1)在图形处理器上设计和实现了并行堆集群。并行堆是并行优先队列在图形处理器上的实现,而并行堆集群则是并行堆的集合,出于性能考虑而设计,可以理解为并线优先队列在图形处理器上的近似实现。
2)基于并行堆集群,在图形处理器上设计和实现了形态学重建系统。
2 基于图形处理器的形态学重建系统
2.1 系统概述
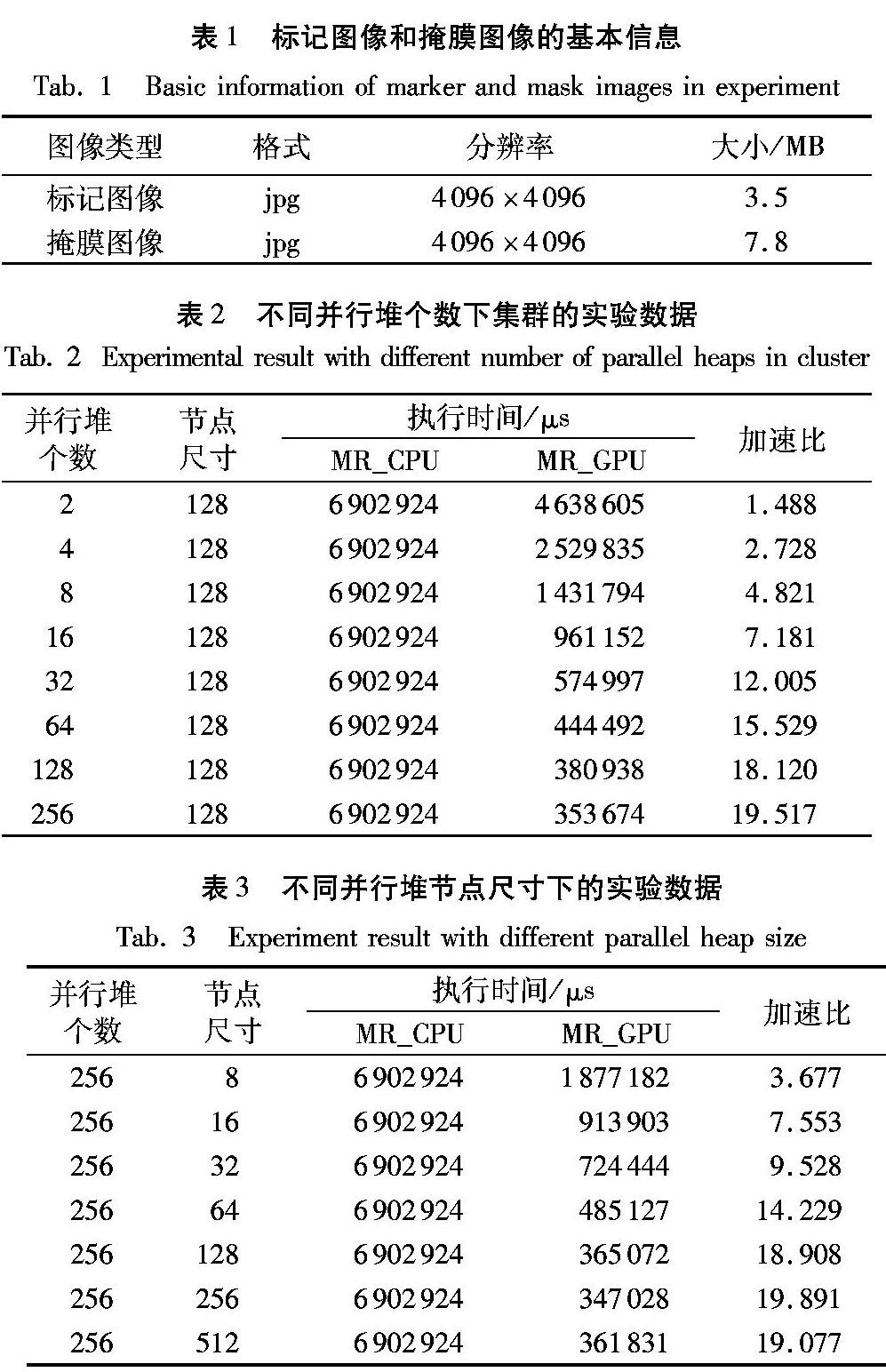
为了充分利用图形处理器的并行计算能力以缩短形态学重建的计算时间,本文设计开发了一套基于图形处理器的形态学重建系统,取名为MR_GPU(Morphological Reconstruction_GPU)。MR_GPU设计的一个重要原则是把计算量大、适合使用并行计算的操作放在图形处理器端处理,而中央处理器端则负责系统的初始化、输入输出以及与图形处理器的协调工作。图2展示的是MR_GPU的流程。r是并行堆节点可容纳的最大像素点个数。系统的输入是一张标记图像和一张掩膜图像,输出是一张膨胀后的标记图像。系统内的处理主要分为三个阶段:准备阶段、建堆阶段和迭代膨胀阶段。在准备阶段,系统会完成初始化和数据准备的工作。初始化工作主要包括配置系统参数,初始化系统中引用的各种外部类库和在中央处理器和图形处理器两端计算并分配存储空间。数据准备工作则包括:1)从标记图像和掩膜图像文件里把图像信息数据读取出来,并存放在二维数组里;2)对图像信息进行必要的类型转换和数据清洗;3)把图像信息传输到图像处理器端的全局内存;4)扫描图像信息,找出符合扩散条件的种子像素点,并且把这些种子像素点均匀地分组。在建堆阶段,上一阶段留下的每一个像素点组,会被按照像素值进行排序以构造一个最大并行堆。在迭代膨胀阶段,每一个最大并行堆都会独立地、迭代地执行膨胀操作,其步骤如算法1所示。细节会在介绍并行堆时一起讨论。
2.2 并行堆
并行堆是专门为图形处理器设计的优先队列,可以看成是二元堆的升级版本。与二元堆类似,并行堆实际上是一棵完全二叉树,并且同样维护堆的属性,即每个节点里元素的值都比孩子节点元素的值要大(最大堆)或者小(最小堆)。在本文中,所讨论的并行堆都为最大堆。与二元堆不同的是,并行堆里的节点可以包含多个元素。实际上,在本文的形态学重建系统里,并行堆节点的元素数是几十甚至上百,这样可以方便分配多个线程同时对并行堆进行操作,也符合图形处理器中通过多线程调度来解决内存存取延迟问题的硬件特性。
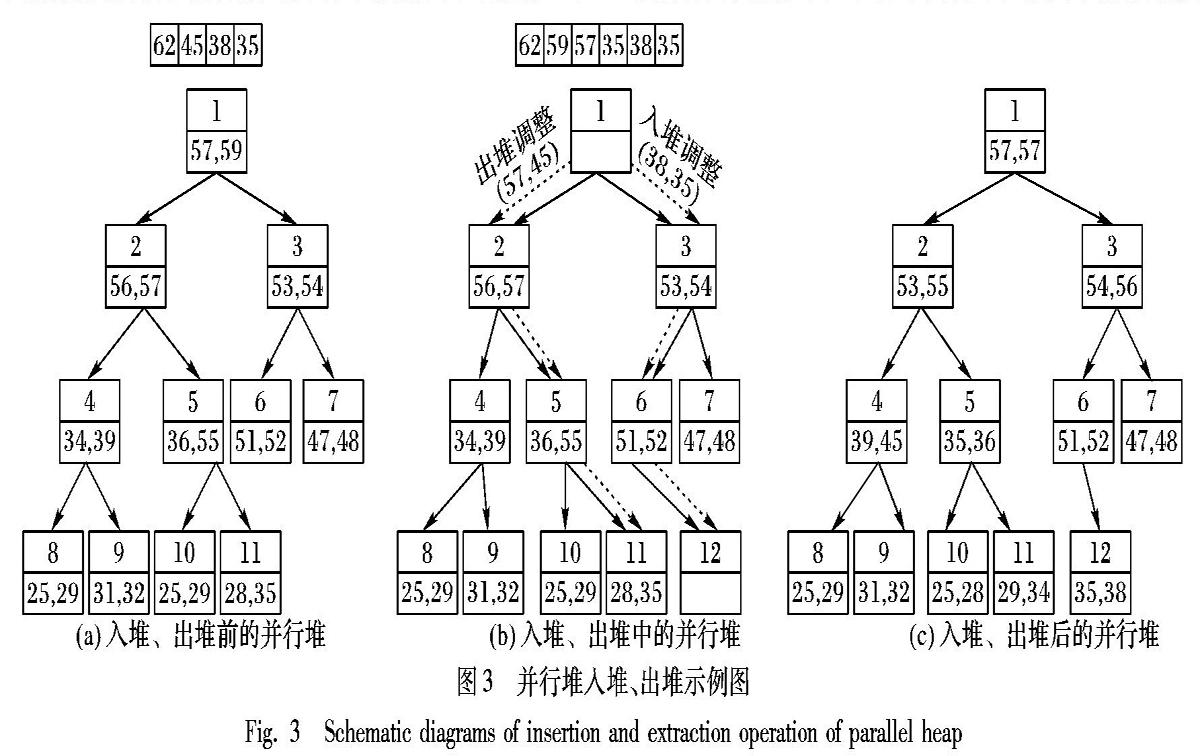
与二元堆类似,并行堆也有入堆和出堆操作。出堆操作从缓冲区内取回r个元素并放到根节点上,然后执行出堆调整操作,使并行堆保持堆的属性。具体的调整方案是把根节点上的r个元素和它的两个孩子节点n1、n2内的2r元素合并。假设n1里的最小元素比n2里的最小元素要小,那么合并后最大的r个元素存放在根节点,最小的r个元素放在n2节点,其余的r个元素放在n1节点。可以证明只有n2节点及它的子节点需要继续调整[28]。出堆调整操作会继续迭代地调整n2节点及其子节点,直到到达了叶子节点。
入堆操作是要把新的r元素添加到并行堆现有元素之后,并且调整并行堆使其保持堆的属性。具体的调整方案如下:计算一条从根节点到待插入节点之间由上往下的入堆路线。从根节点开始,新的r个元素与根节点的r个元素合并。较大的r个元素留在根节点,较小的r个元素继续流向入堆路线上的下一个节点里,然后在下一个节点上继续合并,保留较大的r个元素,让较小的r个元素继续流向再下一个节点。上述步骤持续进行,直到较小的元素到达待插入节点。
传统的二元堆入堆调整由下往上进行,而出堆调整是由上往下进行的。由于在多线程环境下会存在多个出堆调整和入堆调整线程,这种出堆、入堆调整方向不一致的情况会导致死锁问题的出现。实际上,并行堆根据图形处理器同步的特点,采用了流水线(Pipeline)的并行策略,堆中每一个层次同时都有一组入堆调整线程和一组出堆调整线程在运行,因此,在并行堆中,把出堆、入堆调整的方向都设计为由上到下以避免死锁的出现。
在形态学重建系统里需要一个缓冲区,缓冲区内存放的是最近产生的待扩散的像素点。每次迭代中,并行堆根节点的像素点会被取出来,与缓冲区内的像素点合并成有序序列,然后最大的r个像素点会被取出进行扩散处理,次大的r个像素点会被放在并行堆的根节点,然后进行由上到下的出堆调整操作。另外的r像素点则会沿着计算好的路径由上而下,最终把经过调整后较小的像素点添加到并行堆的待插入节点中。
图3(a)显示的是一个简化版本的并行堆例子。它共有11个节点,每个节点都有一个编号,最多可以包含2个像素点,缓冲区内有上次迭代收集的4个像素点(62,45,38,35)。在当前迭代中,出堆操作会从并行堆取出根节点内的像素点(57,59)放到缓冲区内,然后对缓冲区内的像素点的值进行排序,然后,如图3(b)所示,对于像素值最大的2个像素点(62,59),系统会对它们进行扩散处理,并把扩散所涉及的邻接像素点收集到缓冲区为下一轮迭代做准备。对于缓冲区像素值排第3第4的像素点(57,45),系统会把它们放回到并行堆的根节点,然后从根节点开始对并行堆进行出堆调整。至于剩下的像素点(38,35),则会执行入堆操作。调整后具有较小像素值的两个像素点(35,38)将会被放到节点12上去。因为待插入节点已知,系统由此可以计算入堆路线,并由上往下进行入调整。图3(c)显示是入堆、出堆调整后的并行堆。
2.3 并行策略
行之有效的并行策略是MR_GPU中重要的一环。在准备阶段,分配了数量众多的线程来并行扫描标记图像和掩膜图像。由于图形处理器独特的硬件线程调度实现,数量众多的线程不但不会因为线程调度而影响性能,反而可以隐藏读写内存带来的延迟从而提高整体的性能。在建堆阶段和迭代膨胀阶段,适用的并行策略可以分为三个层次。
并行策略的第一层次是在图形处理器集群上。图形处理器集群上部署了多个图形处理器,可以切割大图像文件并分配到每个图形处理器上,由这些图形处理器独立地、并行地进行形态学重建。同时,图形处理器间有同步策略,可以在不同图像文件分割块间进行同步。
并行策略第二層次是在每个图形处理器上运行的并行堆集群上,可以配置多个并行堆同时执行形态学重建中的膨胀操作。在最开始的设计中只维护了一个并行堆。一个并行堆可以保证具有较大像素值的像素点首先可以得到扩散的机会,从而避免很多较小像素值不必要的扩散,但是问题在于如果一个图形处理器中只维护一个并行堆的话,图形处理器的计算能力远远得不到充分的利用,整个形态学重建的效率并没有得到最大化。现在MR_GPU中设计的并行堆集群中各个并行堆是相互独立的,保证了效率不会因为并行堆之间的相互依赖关系而下降。每个并行堆内部也是保证具有较大像素值的像素点首先可以得到扩散的机会从而减少了不必要的计算,而并行堆之间由于是相互独立,没有同步的机制,会导致一些重复的像素值扩散操作。然而,相对于采用并行堆集群而获取的图形处理器计算能力的充分利用,这些重复计算的代价是可以承受的。
并行策略的第三层次是在并行堆内部。在建堆阶段,需要对初始化阶段找出的首先扩散的像素点进行并行排序从而构造并行堆。在图形处理器上并行排序是一个已经有很多研究者在研究的课题[30-33]。可以直接采用已经优化的并行排序方案。在迭代膨胀阶段,采用了流水线(pipeline)的并行机制,出堆和入堆调整线程从根节点开始,一层一层往下对并行堆进行调整。当一组出堆调整和一组入堆调整线程完成了对根节点的调整,开始对并行堆的第二层进行调整时,系统会启动另外一组出堆调整和一组入堆调整线程执行下一轮出堆入堆操作。一般来说,对于一个有n层的并行堆,会有n组出堆调整线程和n组入堆调整线程。每一个出堆或入堆调整线程组内会有r个线程,r是并行堆节点里最大的元素数,而为节点里每一个元素分配一个线程无论从实现角度还是效率角度来看都是不错的选择。出堆和入堆调整线程还涉及了并行合并操作和并行收集像素点操作,对于前者,别的研究已经提供了解决方案[30,34]。对于并行收集像素点到缓冲区问题,本文的策略是为每个产生待扩散的像素点的线程分配临时空间存放待扩散像素点,然后统计像素点的个数。线程同步以后使用并行扫描的方式统计像素点总的个数以确定每个线程产生的像素点在缓冲区内的位置,然后让每个线程分别把各自的像素点从临时空间拷贝到缓冲区内。
猜你喜欢
软件导刊(2017年1期)2017-03-06
计算机应用(2016年12期)2017-01-13
科学与财富(2016年15期)2016-11-24
大经贸(2016年9期)2016-11-16
中国新通信(2016年16期)2016-10-18
计算机辅助工程(2016年3期)2016-08-01
电脑知识与技术(2016年14期)2016-06-30
科技视界(2016年11期)2016-05-23
电脑知识与技术(2015年12期)2015-07-18
湖南大学学报·自然科学版(2015年2期)2015-04-20
