
基于随机森林算法的对外汉语文本可读性评估
2019-09-09 07:43杨文娣曾致中
中国教育信息化·基础教育 2019年7期
杨文娣 曾致中
摘 要:可读性指文本易于阅读的程度或性质,评估对外汉语文本可读性在对外汉语教学中十分重要。文章针对对外汉语文本可读性难以人工评估的问题,提出了一种基于随机森林算法的对外汉语文本可读性自动评估方法。该方法从基础特征、词性特征、等级特征和语法特征这四个维度提取特征,进行特征选择后在训练集上利用随机森林算法训练分类器,并在测试集上证实了该方法的有效性。
关键词:对外汉语;可读性评估;随机森林
中图分类号:G40-057 文献标志码:A 文章编号:1673-8454(2019)14-0089-08
一、引言
发展阅读能力是学习语言的重要组成部分[1][2],阅读材料对发展阅读能力的重要性不言而喻。为了确保阅读材料符合潜在读者的熟练程度,准确预测L2(第二语言)学习者阅读材料的可读性对于教育工作者、作者、出版商等非常重要[3]。然而对L2学习者和教师而言,预测阅读材料的难度非常耗时且常常带有主观性。随着自然语言处理与机器学习的发展,文本可读性的研究也随之进步,并可以在一定程度上解决这一问题。
可读性是文本材料中影响读者理解、阅读速度和对材料感兴趣程度的所有要素之和[4]。影响文本可读性的因素可分为主观因素和客观因素两大方面,其中主观因素主要指读者因素,如读者自身的阅读水平,客观因素是指那些脱离具体对象、不因人的主观意志为转移、一切实际存在的影响文本易读性的因素的总和[5]。
与可读性研究历史悠久的英语不同[6][10],中文的可读性分析只有少数研究[11][12]。对外汉语(Chinese as a Foreign Language)文本可读性评估是中文可读性研究的重要分支,至今为止,对外汉语文本可读性评估的研究大都针对客观因素,且大致可以分為两类:
1.基于传统文本特征的可读性公式方法研究
“可读性公式只是一个通过回归分析得出的数学公式”[9],它“通常可以给出数字得分以评价书或者篇章型阅读材料的难易度,并可以按照其难易程度进行排序”[13],是一种“预测性的手段”[14]。在对外汉语领域中,该研究方法包含但不限于以下成果:①王蕾针对初中级日韩学生制定了一个可读性公式[15];②杨金余研制了高级精读教材的可读性公式[16];③郭望皓制定了对外汉语文本可读性公式[5];④左虹和朱勇针对中级欧美留学生制定了一个可读性公式[17]。
2.基于机器学习的可读性评估
首先提取可读性相关指标,使用特征向量对文本进行表示,然后应用机器学习中的算法,在训练集上进行训练后得到分类模型,最后将测试集输入该分类模型并预测测试集文本对应的可读性等级。随着信息技术的发展,可读性分析领域的学者们逐渐意识到基于机器学习的文本分类可以评估文本的可读性,而且也从相关研究中了解到,单独使用传统的可读性公式并不可靠[18][23]。在对外汉语可读性评估研究中应用机器学习方法的成果相对较少,具有代表性的成果有我国台湾地区学者YAO-TING SUNG等人提出的“基于多层次语言特征与CEFR相结合”的分类方法:首先对外汉语专家教师团队将1,578个对外汉语文本分类到适当的CEFR(欧洲语言共同框架)级别;然后从文本中提取30个对外汉语可读性特征,并使用以F-scores为依据的重要性对特征进行排序;最后,SVM分类器通过将特征顺序地集成到模型中以优化性能而训练得到;该方法得到了精度为74.97%、相邻准确率为99.62%的对外汉语文本可读性评估模型[24]。
本研究收集了6个系列的教材,整理得到文章共计578篇,使用文本分析工具并编写代码从基础特征、词性特征、等级特征和语法特征这四个维度提取特征共计86个,在训练集上使用随机森林算法进行训练,并在测试集上进行性能评估,得到了精度为65.51%、相邻准确率为92.52%的分类模型。
二、数据
1.数据收集
刘珣[25]指出新一代对外汉语教材的编写应参考以下四条原则:①以熟练运用为导向,以培养交际能力为基本目标;②以学生为中心,较好地体现语言习得的过程和规律;③坚持并不断发展结构、功能、文化相结合的原则;④教材的现代化与立体化。
我们参考以上原则,选取了表1中6个系列的对外汉语教材。这6个系列教材在网络上只能找到影印版PDF,有的甚至不能找到完整的影印版PDF(以下简称PDF版),遇到这种情况时我们使用扫描仪对教材进行扫描得到对应电子版(以下简称扫描版)。紧接着我们使用光学字符识别(Optical Character Recognition,以下简称OCR)工具对教材PDF版和扫描版进行文字识别,并将识别出来的内容存储在txt格式的文件中。
然而这些txt格式的文件不能直接作为数据集使用,因为OCR工具识别得到的文字并不能保证100%的准确率,并且PDF版和扫描版中存在着大量的插图、页码、表格等干扰信息。所以必须要对这些txt文件进行数据处理,以保证数据的有效性。
2.数据处理
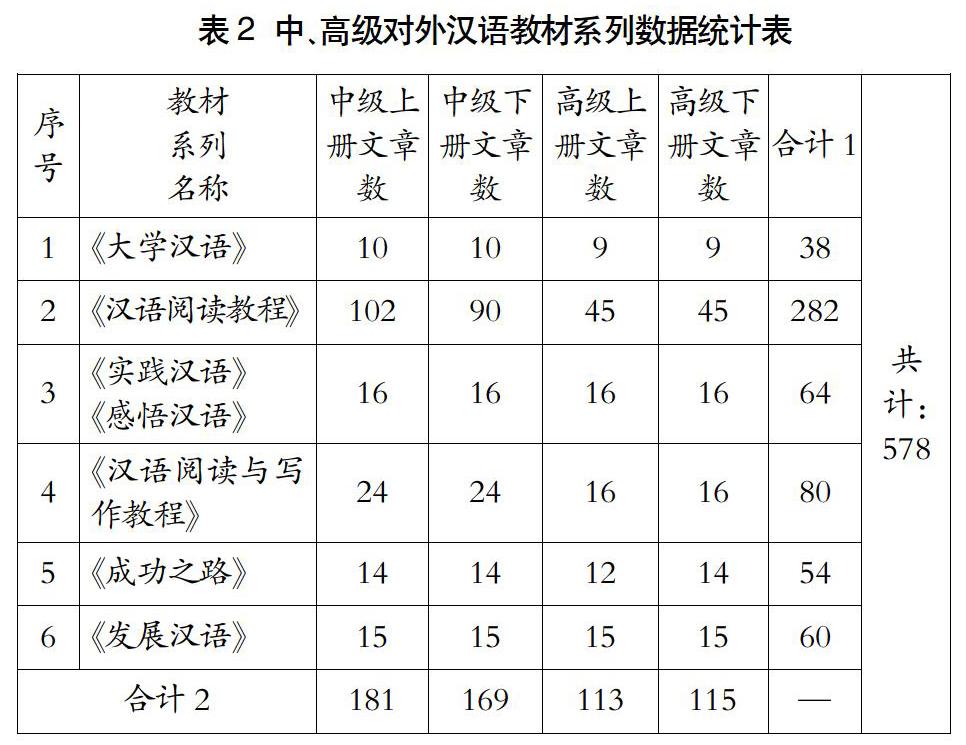
在数据处理的过程中我们进行了3次人工排错:第一次检查排版格式,去除多余的换行符、空格;第二次通读全文与原文对比,排除明显的文字错误;第二次检查易错误识别的文字,如“拔”(易错误识别为“拨”)、“王”(易错误识别为“玉”)等会因字形相似导致OCR工具错误识别的文字。在人工排错中发现《汉语阅读教程》中有22篇文章是表单形式的应用文,这些文章重点在于教会L2学习者掌握汉语在日常中的应用。这些应用文汉字数量较少且不是连续的句子、段落,不适用于作为本研究的数据集,所以从数据集中剔除了这些文章,得到的中、高级对外汉语教材系列统计表如表2所示。
3.数据集打标签与划分
由于原始数据集中包含有中级上册(M1)、中级下册(M2)、高级上册(H1)和高级下册(H2)这四个由易到难的等级,所以笔者就以样本本身所在的等级为样本标签,如《故都的秋》这篇文章来自《大学汉语高级精读》(下),即高级下册,所以样本《故都的秋》的标签为高级下册(H2),其他文章以此类推。
通常,我们通过测试集来测试分类器的泛化能力,因此,我们需要将数据集划分成训练集和测试集两部分。其中训练集参与特征选择、分类器训练等步骤,测试集只参与最终分类器泛化能力评估。为了保证训练集和测试集数据分布的一致性,我们在578篇文章中随机抽取测试集,并按照训练集:测试集=7:3的比例划分数据集,得到训练集数据404个、测试集数据174个。

三、特征工程
1.特征提取
众所周知,中文文本没有英文空格这种天然的词边界标志。所以想要分析中文就要进行中文分词,简单地说,中文分词就是要由机器在中文文本的词与词之间自动加上空格[26]。词性是词的句法功能类别,在各种中文的自然语言处理过程中,几乎都要进行词性标注[27]。由于词汇也是本研究中重要的研究对象,所以在对数据集进行特征提取之前首先需要进行分词和词性标注。现有的中文分词、词性标注的工具有很多,其中,由大数据搜索與挖掘实验室研发的NLPIR汉语分词系统是国内深受业界好评的自然语言处理平台,主要功能包括中文的分词、词性标注、命名实体识别、关键词提取等。并且NLPIR汉语分词系统还支持多种编码、多种操作系统,同时能够兼容多种开发语言和平台。
本文根据对外汉语的特点编写代码,提取了适用于对外汉语文本可读性评估的特征,包括基础特征、等级特征、词性特征、语法特征这四个维度的特征共计86个。接下来我们详细介绍这四个维度的特征:
(1)基础特征
基础特征指文章中较为浅显且易于提取的特征。基础特征最初广泛使用在可读性公式的研究中[28]。其中,金凯德(Flesch-Kincaid)公式是微软办公软件Word的内置可读性公式[10]。本文根据英文可读性公式、对外汉语可读性公式的研究成果,提取了21个基础特征,如表3所示。

(2)词性特征
词的语言学特征在表征文本方面也是至关重要的,例如不同词性的词对文本的表征能力是不同的[29]。所以,我们使用PyNLPIR(NLPIR汉语分词系统提供的Python接口)进行词性标注。NLPIR汉语分词系统提供的《计算所汉语词性标记集》分别有一类22个、二类66个、三类11个(共计99个),基本满足了本研究提取词性特征的需求,本文提取了所有的一类词性(如表4所示)以及国内外第二语言文本可读性评估重要特征(如表5所示),共计34个,但后期将特征全部提取出来后发现“字符串”特征值全部为0,所以该特征无意义,因此去除这一特征,词性特征最终有33个。
(3)等级特征
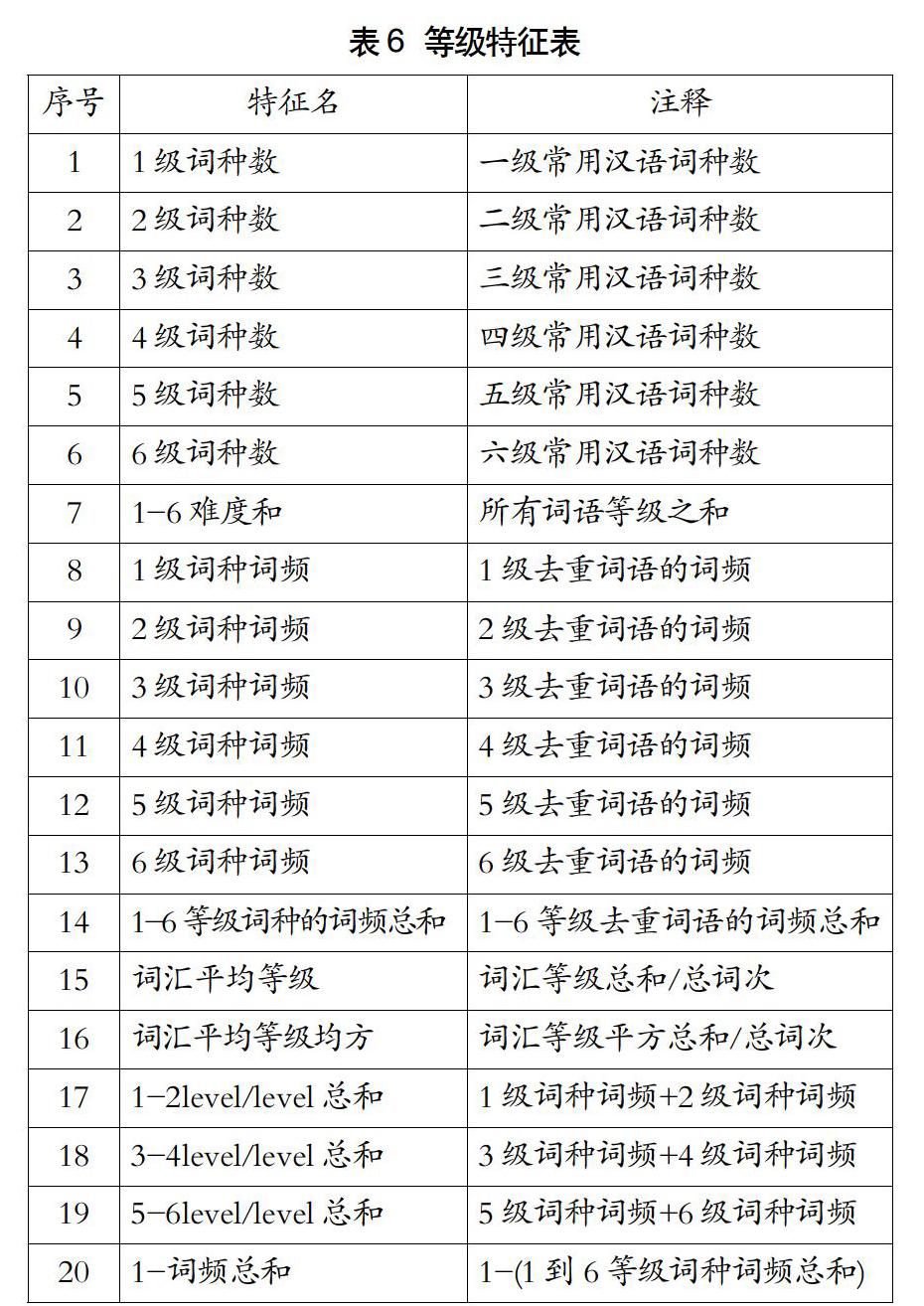
在等级特征提取的过程中,我们用到了以下标准:《国际汉语教学通用课程大纲》(2013年修订版)(以下简称《大纲》)中的《常用汉字表(一-六级)》《常用汉语词语表(一-六级)》(以下简称分别为《汉字等级表》《词语等级表》)。《大纲》由孔子学院总部组织研制,用于梳理对外汉语教学课程目标与内容,旨在为汉语教学机构和教师在制订教学计划、测评L2学习者语言掌握能力、编写教材等众多方面提供参考依据和标准。《大纲》中的《汉字等级表》《词语等级表》对于将汉语作为L2学习者而言是标准等级字词表,在对外汉语教学领域具有普适性、权威性[30]。我们参考国内外第二语言文本可读性特征指标提取的等级特征如表6所示。
(4)语法特征
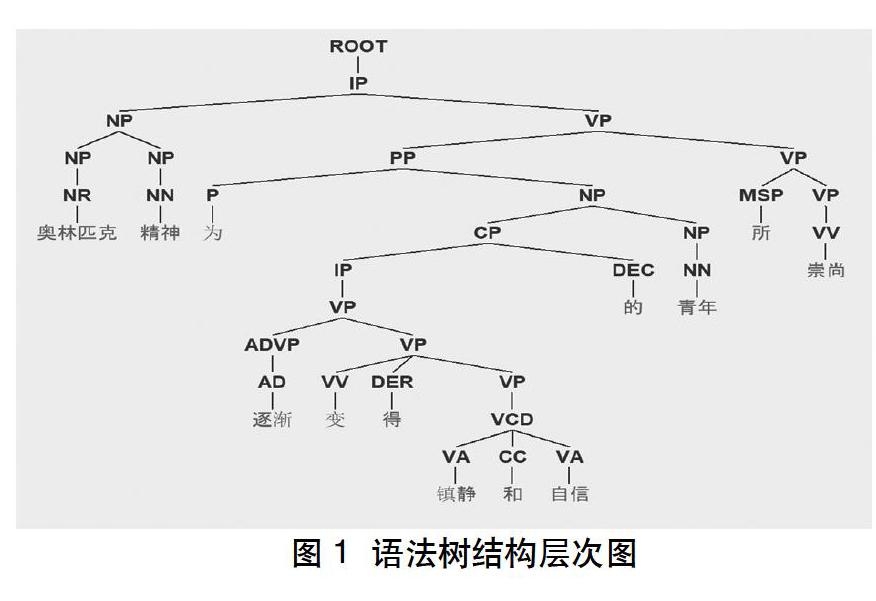
以上“基础特征”“词性特征”“等级特征”都是基于统计的特征,并没有提取语义、语法等层次的特征。试想一下,在学习英语时,即使在所有单词都掌握了的情况下,如果句子的语法复杂,我们仍然会对这句英文一知半解,无法真正掌握句子的意思。同样,一个语法结构复杂的中文句子亦会对L2学习者造成困惑,即这个句子的难度较高、可读性较低。所以接下来着重介绍一下“语法特征”的提取。我们采用斯坦福NLP小组研发的斯坦福解析器进行对外汉语文本的语法分析,具体工具使用的是NLTK提供的斯坦福语法解析器的python接口。该工具可以将一句话分析成语法树,将句子结构用图形表示,代表了句子的推导结果,可用于分析句子语法结构。简单来说,语法树就是按照某一规则进行推导后形成的树状图,树状图的层级是指将语法分析的结果转换为树状图后各节点的层次,以此类推[31]。语法分析树的结构层次如图1所示,接下来我们根据语法树的分析结果提取了语法特征12个,如表7所示。
2.特征预处理
将以上86个特征提取完毕后发现,特征数据差异较大,如特征“总字次”的取值区间为[109,4621],特征“语法分析树平均节点数”的取值区间为[39.493151,180.6],所以在对特征进行特征选择之前,需要对特征进行数据预处理。本研究中采用了区间缩放法,公式表达为:
x'= 公式1
采用区间缩放法后,每个特征的取值范围都在[0,1]区间,避免了由于特征取值范围差异巨大而影响后期的特征选择、分类器训练。
3.特征选择
特征選择定义如下:给定一组候选特征,选择出在某个分类器下最佳的子集[32]。特征选择可以去除无关特征和冗余特征,防止分类器过拟合[33]、泛化能力降低。此过程不仅可以通过减少需要收集的特征数量来降低计算成本,而且在某些情况下,由于样本大小有限,它还可以提高分类器性能[34]。
想要在初始特征集中找到一个合适的特征子集,最直接的方式就是遍历所有特征子集,即穷举搜索,但这样会消耗大量的计算资源,一般在计算上是不可行的。常见的特征选择方法大致可分成嵌入式(Filter)、过滤式(Wrapper)和包裹式(Embeded)三种。
嵌入式特征选择将特征选择过程与分类器训练过程同步进行,两者在同一优化过程中完成;过滤式特征选择与后续分类器无关,相当于先对初始特征集进行“过滤”,再用“过滤”后得到的特征子集来训练模型,具有选择快速等优势;与过滤式特征选择不同,包裹式特征选择直接将最终要使用的分类器的性能指标作为评价特征子集的标准,一般情况下,包裹式特征选择的最终分类器性能比过滤式特征选择的效果更好,但是由于包裹式特征选择过程中多次训练分类器,其计算开销也要比过滤式特征选择大得多。目前包裹式特征选择多与过滤式特征选择相结合辅助特征选择[33]。在本研究中我们采用了过滤式特征选择中的卡方检验法。
卡方检验(Chi-Square Test,CHI)是一种用途很广的假设检验方法,在文本分类中可以用于表示特征f与类别c的相关性,先假设f与c相互独立,然后通过比较理论值与实际值的偏差,来体现f与c的相关程度。其根本思想就是在于比较理论值和实际值的吻合程度或拟合优度问题。特征f与类别c的卡方统计量如公式2所示。
CHI(f,c)=公式2
其中:N是样本总数;A是属于类别c且包含特征f的样本频率;B是不属于类别c但包含特征f的样本频率;C是属于类别c但不包含特征f的样本频率;D是不属于类别c且不包含特征f的样本频率。
我们使用sklearn featureselection库的SelectKBest类结合卡方检验来计算每个非负特征和分类(M1、M2、H1、H2,共计四类)之间的卡方统计量,该统计量可以检验测量特征与分类之间的依赖关系,我们可以通过这个方法将独立于类的特征“过滤”。
四、随机森林算法
传统的机器学习分类算法有很多,如决策树、支持向量机、贝叶斯、K近邻等,但存在单个分类器的性能提升有限以及过拟合的问题。集成学习不同于传统的机器学习分类算法,它通过集成多个分类器来提高分类性能,集成学习算法中的随机森林算法以简单高效著称。
随机森林是基于决策树的一种非参数集成学习分类算法,只需通过对给定样本的学习训练分类规则,并不需要先验知识[35]。其中随机森林分类的基本思想是:使用bootstrap抽样从训练集全集D中抽取出k个样本;这k个样本分别建立k个决策树模型,将测试集数据输入这k个决策树模型后会得到k个分类结果;最后通过投票表决预测其最终分类。算法示意如图2所示。
五、实验
1.实验设计
本文实验主要分为四大模块。
(1)数据
数据收集:选取《大学汉语精读》《汉语阅读教程》《实践感悟汉语》(包括《实践汉语》和《感悟汉语》两套)《汉语阅读与写作教程》《成功之路》《发展汉语》等六个中、高级对外汉语教材系列;使用OCR工具、扫描仪将以上六个系列教材的影印版PDF文件、纸质书籍转化为存储在txt格式文件中的电子版,获取共计600篇文章。
数据处理:三次人工排错、去除22篇不适用于进行特征提取的文章,最终整理出共计578篇校对后的文章。具体文章数据统计详见表2。

数据集打标签与划分:将数据集打乱后按照训练集:测试集=7:3的比例划分数据集,得到训练集数据404个、测试集数据174个。
(2)特征工程
特征提取:使用PyNLPIR对文章数据进行分词、编写python代码提取基础特征、等级特征、词性特征、语法特征四个维度的特征共计86个,具体特征详见表3-表7。
特征预处理:使用区间缩放法对所有特征进行区间缩放,使每个特征值都分布在[0,1]区间,详见公式1。
特征选择:使用过滤式特征选择中的卡方检验“过滤”得到卡方值在平均值以上的特征。
(3)分類器训练
将经过特征工程的训练集输入随机森林分类算法中,训练出分类器。
(4)性能评估
将测试集输入上一步得到的分类器中进行性能测试,使用精度(Acc)、相邻准确度(±Acc)、查准率(precision)、查全率(recall)、F1值(F1-score)这5个指标对实验结果进行评估。
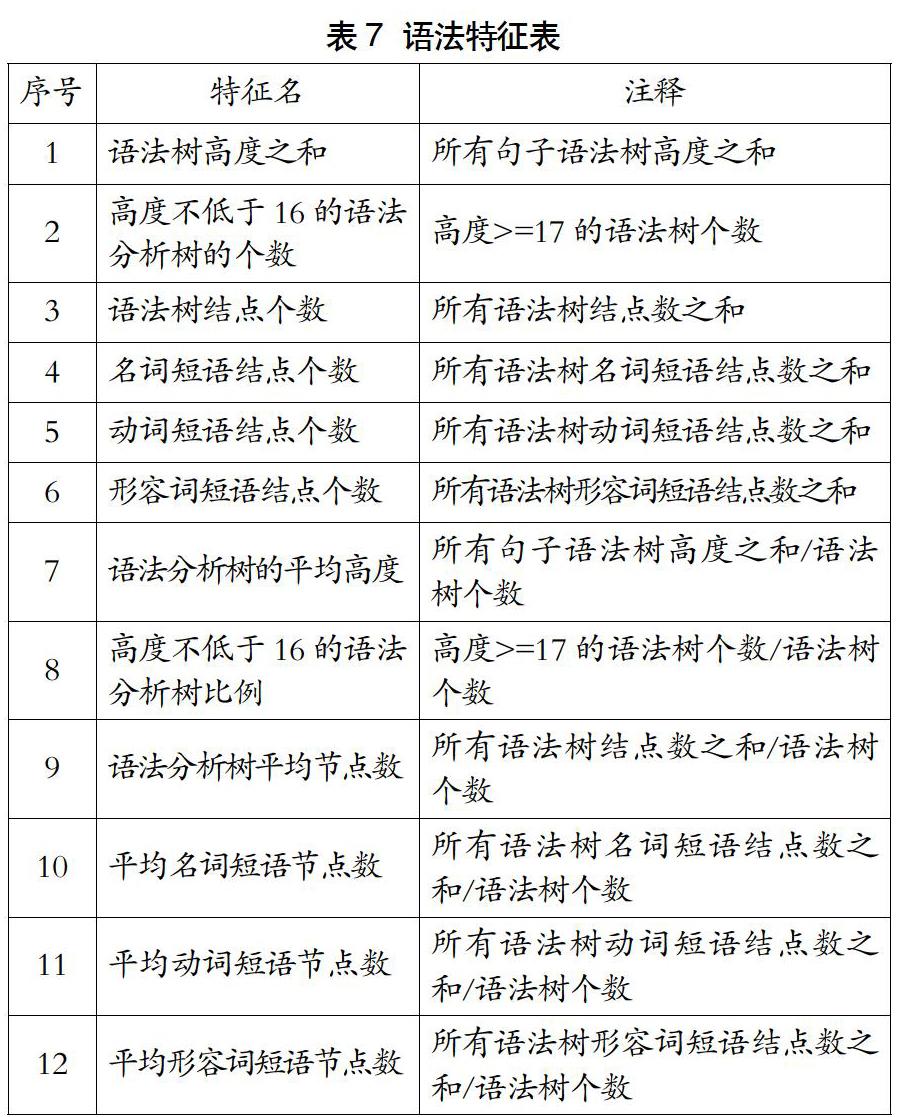
综上所述,对基于随机森林的外汉语文本可读性评估的整体流程如图3所示。
2.评价指标
文本可读性的评估与具体的应用场景有关,不同的应用场景有不同评价指标,本次实验采用了以下五个可以定量的评价指标:
(1)精度(Acc)
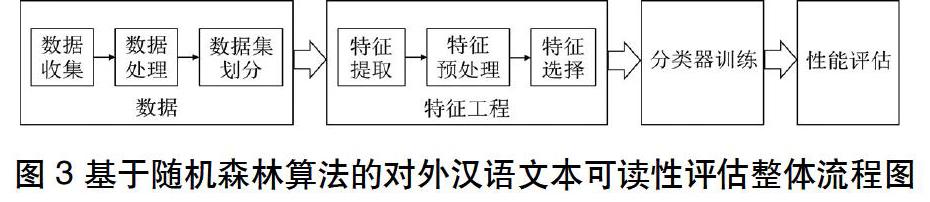
评价一个分类模型常用的指标就是精度,精度也是最为直观的指标,精度的计算公式为:
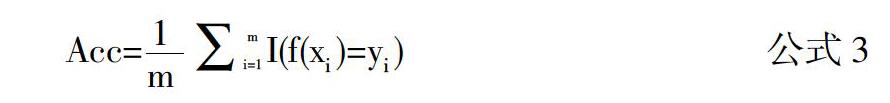
其中I(·)表示指示函数,当·为真时I(·)取值为1,当·为假时I(·)取值为0,简单来说,精度等于所有参与预测的样本总数中预测正确的样本数所占的比例。一般情况下精度越高表示分类器性能越好,但过于笼统粗糙,因此还需要相邻准确度、查准率、查全率和F1值等指标来辅助。
(2)相邻准确度(±Acc)
文本可读性的评估与其他的分类不尽相同,比如水果的分类,苹果被错误地预测为香蕉,错了就是错了,因为苹果和香蕉之间没有递进关系。而文本可读性的等级是存在递进关系的,以本研究的四个等级举例(M1、M2、H1、H2),比如一篇真实可读性等级为H2的文章被分类器错误地预测为H1和被错误地预测为M1是不同的。虽然从精度方面考虑,两者的情况是一样的,但是同样是误判,被误判为H1要比被误判为M1要好得多,所以使用相邻准确度作为评价指标之一是十分有必要的。
(3)查准率(precision,又称准确率)和查全率(recall,又称召回率)
这两个评价指标在实际研究中经常被使用。然而查准率和查全率是一对互相矛盾的评价指标,当其中一个值上升时,通常情况下,另一个值会对应下降。查准率和查全率可以通过分类情况混淆矩阵计算得出,混淆矩阵如表8所示。
其中,TP表示真正例,FN表示假反例,FP表示假正例,TN表示真反例。


3.实验结果与分析
我们完成上一小节中的实验步骤训练好分类器后,将事先划分出来的测试集输入分类器,得到的实验结果如表9所示。
从表9可以看出,通过随机森林算法,文本可读性评估四分类(M1、M2、H1、H2)中单类查准率最高的是H2,达到了0.81,单类查准率最低的是M1,为0.60,但M1的查全率为四类中最高的,达到了0.85。总体上说,此次四分类的精度为65.51%、相邻准确度达到了92.52%。
六、总结
随着自然语言处理、数据挖掘、机器学习等相关技术的发展,基于机器学习的对外汉语文本可读性评估逐渐成为研究热点。机器学习从使用的个体分类器数量上来说又可以分为单分类器机器学习和集成学习,集成学习中的随机森林算法更是以易于理解、性能优异著称,在世界上多个数据挖掘竞赛上崭露头角。因此,本文提出了基于随机森林算法的对外汉语文本可读性评估研究。
由于数据的稀缺性,本文中使用的数据集相对较小,在小数据集上提取了基础特征、等级特征、词性特征、语法特征这四个维度的特征共计86个。进行了Filter特征选择后使用训练集训练随机森林分类器,使用测试集进行了性能评估,得到了精度为65.51%、相邻准确度为92.52%的对外汉语文本可读性评估模型。本研究也为同类型的实验提供了新的方向,可以在接下来的研究中尝试使用随机森林等集成学习进行对外汉语文本可读性评估。
参考文献:
[1]Petersen S E,Ostendorf M. A machine learning approach to reading level assessment[J]. Computer Speech and Language,2009,23(1):89-106.
[2]Xia M,Kochmar E,Briscoe T.Text Readability Assessment for Second Language Learners[C].San Diego:Proceedings of the 11th Workshop on Innovative Use of NLP for Building Educational Applications,2016:12-22.
[3]Crossley S A,Greenfield J,McNamara D S. Assessing Text Readability Using Cognitively Based Indices[J].Tesol Quarterly,2008,42(3):475-493.
[4]Dale E,Chall J S.The Concept of Readability[J]. Elementary English,1949,26(1):19-26.
[5]郭望皓.對外汉语文本易读性公式研究[D].上海:上海交通大学,2010.
[6]Dale E,Chall J S.A Formula for Predicting Readability: Instructions[J]. Educational Research Bulletin,1948,27(2):37-54.
[7]Flesch R.A New Readability Yardstick.[J]. Journal of Applied Psychology,1948,32(3):221-233.
[8]Fry E.A Readability Formula That Saves Time[J].Journal of Reading,1968,11(7):513-578.
[9]McLaughlin G H.SMOG Grading-a New Readability Formula[J]. Journal of Reading,1969,12(8):639-646.
[10]Gunning R.The Technique of Clear Writing[J]. McGraw-Hill,1952:36-37.
[11]Jeng C C.Chinese Readability Analysis using Artificial Neural Networks[D]. Dekalb:Northern Illinois University,2001.
[12]李绍山.易读性研究概述[J].解放军外国语学院学报,2000,23(4):1-5.
[13]Fry E. Readability versus Leveling[J].Reading Teacher,2002,56(3):286-291.
[14]Klare G R. Readability[J]. Handbook of Reading Research,1984(1): 681-744.
[15]王蕾.初中级日韩留学生文本可读性公式初探[D].北京:北京语言大学,2005.
[16]杨金余.高级汉语精读教材语言难度测定研究[D].北京:北京大学,2008.
[17]左虹,朱勇.中级欧美留学生汉语文本可读性公式研究[J].世界汉语教学,2014,28(2):263-276.
[18]Feng L,Jansche M, Huenerfauth M,et al.A Comparison of Features for Automatic Readability Assessment[C].Beijing:Proceedings of the 23rd International Conference on Computational Linguistics,2010:276-284.
[19]Lau T P. Chinese Readability Analysis and its Applications on the Internet[D]. Hong Kong:Hong Kong University,2006.
[20]Chen Y H, Tsai Y H, Chen Y T. Chinese Readability Assessment using TF-IDF and SVM[C].Guilin: International Conference on Machine Learning and Cybernetics, 2011:10-13.
[21]Heilman M,Collins-Thompson K,Callan J,et al. Combining Lexical and Grammatical Features to Improve Readability Measures for First and Second Language Texts[C]. Rochester: Proceedings of North American Chapter of the Association for Computational Linguistics– Human Language Technologies,2007:460-467.
[22]Kate R J,Luo X,Patwardhan S,et al.Learning to Predict Readability using Diverse Linguistic Features[C].Beijing: Proceedings of the 23rd International Conference on Computational Linguistics,2010:546-554.
[23]Collins‐Thompson K, Callan J. Predicting reading difficulty with statistical language models[J]. Journal of the American Society for Information Science and Technology,2005, 56(13):1448-1462.
[24]YAO–TING SUNG, WEI–CHUN LIN,SCOTT BENJAMIN DYSON,et al.Leveling L2 Texts Through Readability: Combining Multilevel Linguistic Features with the CEFR[J]. Modern Language Journal,2015,99(2):371-391.
[25]刘珣.新一代对外汉语教材的展望——再谈汉语教材的编写原则[J].世界汉语教学,1994(1):58-67.
[26]骆正清,陈增武,王泽兵,等.汉语自动分词研究综述[J].浙江大学学报(工学版),1997(3):306-312.
[27]洪铭材,张阔,唐杰,等.基于条件随机场(CRFs)的中文词性标注方法[J].计算机科学,2006,33(10):148-151+155.
[28]Kincaid J P,Fishburne Jr R P,Rogers R L,et al. Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel[R]. Memphis:Reasearch Branch Report,1975:8-75.
[29]施侃晟,刘海涛,宋文涛.基于词性和中心点改进的文本聚类方法[J].模式识别与人工智能,2012,25(6):996-1001.
[30]孫晓明.汉语国际推广背景下的词汇等级标准研究[J].民族教育研究,2012,23(1):110-114.
[31]杨鸿武,王晓丽,陈龙,等.基于语法树高度的汉语韵律短语预测[J].计算机工程与应用,2006,46(36):139-143+167.
[32]Jain A,Zongker D. Feature selection: evaluation,application, and small sample performance[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,1997,19(2):153-158.
[33]许尧,胡学钢,李培培.一种基于组策略的过滤式特征选择算法[J].计算机应用研究,2016,33(5):1322-1326.
[34]Jain A K, Chandrasekaran B. 39 Dimensionality and Sample Size Considerations in Pattern Recognition Practice[J]. Handbook of Statistics,1982,2(39): 835-855.
[35]贾斌,马严,赵翔.基于组合分类器的DDoS攻击流量分布式检测模型[J].华中科技大学学报(自然科学版),2016,44(S1):1-5+10.
(编辑:鲁利瑞)
猜你喜欢
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
青春岁月(2016年22期)2016-12-23
亚太教育(2016年35期)2016-12-21
青春岁月(2016年20期)2016-12-21
现代语文(学术综合)(2016年10期)2016-11-14
电脑知识与技术(2016年23期)2016-11-02
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
