
分布式空间Top-K频繁关键字查询系统
2019-09-10 07:22姚远肖锐
现代信息科技 2019年19期
姚远 肖锐




摘 要:随着地理数据量的不断增大,传统的空间数据库已经无法满足实际应用的需要。为此,该文围绕矢量数据的Top-K频繁关键字问题,设计了一个分布式空间数据库系统。主要内容为分布式矢量数据存储模型设计,基于Hilbert排列码的矢量数据划分策略,分布式空间数据的索引结构以及索引算法设计。
关键词:分布式数据库;矢量数据;关键字查询
中图分类号:TP393.04 文献标识码:A 文章编号:2096-4706(2019)19-0007-05
Abstract:With the increasing amount of geographic data,the traditional spatial database has been unable to meet the needs of practical application. For this reason,this paper designs a distributed spatial database system around Top-K frequent keyword of vector data. The main contents are the design of distributed vector data storage model,vector data partition strategy based on Hilbert permutation code,index structure of distributed spatial data and index algorithm design.
Keywords:distributed database;vector data;keyword query
1 問题描述
空间Top-K频繁关键字查询定义。
输入:
(1)数据:空间对象集合D={O1,O2,…,On},Oi=(loci,kwi,1,…,kwi,m)包含位置loci和一组关键字kwi,1,…,kwi,m。
(2)查询:Q=(RQ,k),RQ是查询范围,k是正整数。
输出:在查询范围RQ内的对象中出现频率最大的k个关键字。
2 系统设计
本文设计的系统是分布式的,即对于一个空间查询Q,不再单单是在一个计算节点上的R树中查找与查询Q相交的或包含的范围内的前k个关键字,而是针对整个分布式系统各个节点上存储的所有数据进行查询。系统的总体架构如图1所示。
2.1 数据存储
2.1.1 数据划分
基于Hilbert空间排列码的空间划分策略进行划分。空间数据划分方法是多维数据分布式存储的基础,目的是通过一定的数据划分规则,将多维数据集分割成多个独立的数据分片,分布式存储在集群中的计算节点上。
本系统采用的是一种空间填充曲线的划分方法,主要思想是使用一条连续的曲线穿过空间中的每个离散单元,且只穿过一次,然后将每个空间数据按照填充曲线的规则进行编码,然后将编码值相近的空间数据对象划分到同一数据块中,以此来对空间数据进行降维。在空间上相邻的离散单元,在填充曲线上依然是相邻的。Hilbert曲线是目前比较常用的空间填充曲线,具有良好的空间连续性。由于每个对象包含的关键字个数不同,所以它们的数据量大小可能不同,但可以通过数据预处理,将一些数据大小过大的对象去除。在划分空间数据集时,这里只考虑每个数据分片的空间对象个数,假设一个数据分片的总大小与其空间中对象个数成正比。
对于Hilbert空间编码,确定合理的编码阶数是提高划分效果的关键步骤。本系统采用双层格网的Hilbert空间编码构建数据划分。基本思想是:根据初始设定的每个数据分片大小,对数据集进行初始格网划分,然后统计每个格网的对象个数,对初始格网进行二次划分。之后基于复杂平衡将所有数据分片平均分到各个计算节点。具体算法见第3节的关键算法部分。
2.1.2 数据备份
采用的是类似Hadoop的同构热备份方式对主节点进行备份,主节点有一个存储相同数据的备用节点。当主节点出现故障时,快速使用备用节点,防止数据错误发生。系统中的计算节点采用的是异构热备份方式,即在主节点将数据划分成很多分片后,将每个分片备份到多个计算节点,一般选择将一个分片存储在3个不同的计算节点上。
主节点通过对各个计算节点进行心跳检测,更新有效节点的个数,如果某个计算节点出现问题,需要根据其他计算节点的负载,将异常计算节点上的数据分片存储在其他有效的计算节点上,保证每个分片至少有3个备份。
2.1.3 新数据导入
在2.1.1节中,使用了算法将数据集划分成数据分片,并且对每一个数据分片都有一个Hilbert空间编码值。所以当有新数据导入时,先要计算一下新数据所对应的空间范围的Hilbert空间编码值,将该数据发送其Hilbert编码值所对应的数据分片所在的计算节点中。如果某一个计算节点有溢出或崩溃的情况,那么就在新的全体数据集上运行2.1.1节中的算法,进行数据的重划分。
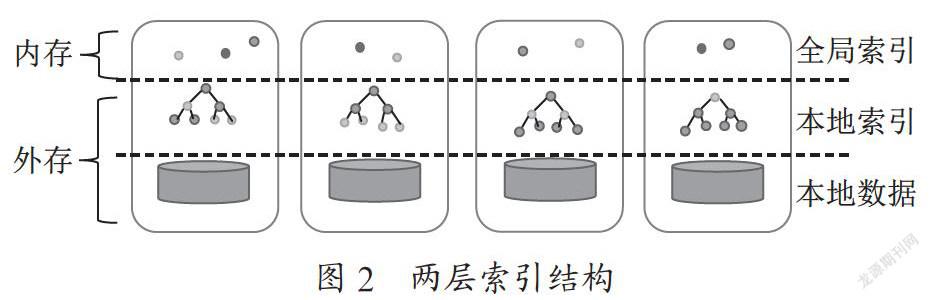
2.2 索引结构
本系统采用一个两层的索引结构,如图2所示。
在计算节点的本地索引的R树上选择其中的一些节点作为全局索引,然后将全局索引发布到各个计算节点的内存中去,并且在内存中为全局索引创建一棵R树,以便后续查询快速找到全局索引。这里将这个两层索引结构简称为R索引。
2.2.1 R索引结构概述
系统将原始的数据集划分到计算节点中,然后计算节点Ni存储分配给它的数据Di。对于每一个计算节点Ni,在其内存储本地数据Di和本地索引的R树Ti。节点Ni在本地上建立好一棵R树之后,从中选取出一些节点作为全局索引,全局索引的格式为(ip,port,address,region)。其中,ip是该索引所在计算节点的ip地址,port是该索引所在节点的端口号,使用ip地址加上端口号就可以定位到全局索引所在的位置了。Address是全局索引所在R树中的位置在计算节点外存中的地址。region是索引对应的R树中节点的空间区域。
全局索引从本地索引中选择出来并发布到计算节点中,在全局索引发布中,被选出的本地索引被添加ip和port等信息,然后再发给各个计算节点。然后,每一個计算节点接收到全局索引后,将其保存到自己的内存中,同时在内存中为全局索引维护一个R树,便于后面的查询快速地查找到相应的数据。
当使用R索引查找数据时,主要分为两个阶段(全局索引获取和本地数据获取)。首先,查询在系统中的空间划分找到满足查询空间条件的计算节点,然后从计算节点的内存中提取出在查询范围内的全局索引。然后,根据全局索引的ip和port找到全局索引所在的计算节点,找到后,根据address信息从该点的R树中提取出相应的数据。后面2.2.3节将会具体阐述查询过程的处理。
2.2.2 全局索引到计算节点的映射
计算节点Ni从本地的R树Ti中获取一个全局索引的集合S(Ni),然后,计算节点将集合S发布到系统中的一部分计算节点中去,对于每一个接收到全局索引的计算节点,将该全局索引保存到自己的内存中,便于后续查询的快速反应。首先,将当前的数据空间划分到各个计算节点Ni上,即每一个计算节点Ni都会维护一个划分空间Space(Ni)。
在这个R索引系统中,对于一个给定的全局索引gi(ip,port,address,region),一个计算节点集合N,将全局索引gi映射到那些计算节点中的Space(Ni)与全局索引gi中的region相交的计算节点。
全局索引映射的形式表述:
对于一个全局索引gi=(ip,port,address,region)和计算节点集合N,R索引将gi映射到Ns中,其中,Ns= {Ni|Ni∈N,Space(Ni)∩region≠Ø}。
本系统中,使用一个接口用于获取节点中的划分空间区域与给定的gi中的region相交的计算节点。该接口记为GetNs(region)。当系统要发布全局索引gi到系统中的各个计算节点中时,发布该索引的计算节点Ni调用GetNs(gi.region)接口函数,获取要将gi发布到的计算节点集合Ns,然后对集合Ns中的节点,将gi插入到节点内存中的全局索引的R树中。
2.2.3 R索引查询处理
R索引的查询处理分为两个阶段:全局索引搜索和本地数据获取。当系统收到一个查询Q(RQ,K)后,查询Q被发送到所有与Q.RQ相交的计算节点上去。而对于每一个收到查询Q的计算节点Ni,在Ni的内存R树中的全局索引返回一个空间区域与Q.RQ相交的全局索引gi。然后计算节点Ni将查询Q发送到全局索引gi所在的计算节点,而收到查询Q的计算节点在本地的R树上对于Q进行查询。
如图3所示,图中有5个计算节点1,2,3,4,5,其中1包含全局索引A,2包含B,3和4都包含C,5节点包含D。查询RQ与全局索引A,C相交。这样就将查询RQ发送到所有A的拥有者中,然后在拥有者本地R树上对RQ做查询。而对于全局索引C,由于其与多个计算节点相交,所以3,4节点都会向拥有C的节点发送消息,这样就造成了通信代价,所以这里采取让离RQ更近的节点向拥有C的节点发送RQ查询。
查询算法:
输入:查询Q(RQ,K),计算节点集合N。
输出:所有与查询空间相交的本地节点的STL。
(1)判断与RQ相交的全局索引gi和gi所在的节点Ni;
(2)将查询Q通过全局索引gi=(ip,port,address,region)利用节点Ni发送到位置信息为ip+port的计算节点上;
(3)在本地索引R树上进行Q查询,利用3.2节计算节点的Top-K频繁关键字算法计算出每一个全局索引所在节点的所有STL;
(4)对于第3步中的STL,运用3.3节的FT算法进行查询算法。
2.2.4 全局索引的选择策略
首先,全局索引的选择需要满足以下条件:第一,每一个计算节点的全局索引的数量要有一定的限制,因为该分布式系统各节点内的内存空间是有限的,如果全局索引的数量过多,就会造成内存装不下的情况;第二,对于R树中的每一个叶子节点n,或选择n,或选择包含节点n的父节点,保证选取的索引空间能够覆盖整个R树,使查询结果具有完整性;第三,R树的节点n或n的祖先节点最多一个被选中为全局索引,这是因为重复选择相互覆盖的区域会造成不必要的全局索引的内存开销,从而降低计算性能。
由于选择全局索引的算法是一个NP问题,所以采用贪心算法去选择R树中的全局索引。首先,假设内存的全局索引限制大小为k1,取集合G作为选择的全局索引的集合,当限制大小未到k1时,自根节点开始,一直沿R树向下扩展,如果子节点加入集合G并且父节点从集合G被删除后的大小仍然小于全局索引限制k1,就将全局索引向下扩展,并将当前遇到的子节点放入集合G。否则,不进行扩展,到此节点结束。
3 关键算法
3.1 基于Hilbert空间排列码的空间划分策略
Algorithm1 Hilbert-partition(M,B,λ):
输入:空间对象集M,预期每个数据分片的大小B,阈值λ。
输出:数据分片集合D。
(1)遍历M,得到对象总数据量sum以及M的最小外接矩形空间R;
(2)第一次网格划分的阶数为n0=[log4sum/B];
(3)根据R,构造2n0*2n0的初始网格,然后M中每个元素映射到初始格网;
(4)遍历空间格网单元,得到格网中单元最大数据量Gmax,如果存在数据量大于B*λ的单元,标记该单元,并且对初始格网进行阶数为n1=[log4Gmax/B*λ]的二次优化。如果没有,则n1=0;
(5)构造出n0+n1阶的Hilbert填充曲线,对最终的空间格网进行编码;
(6)初始i=0,对于标记单元,将该单元内的数据对象按照编码从小到大的顺序添加到当前数据块di,若di的大小大于B,则i=i+1;对于未标记的单元,将整个单元的数据对象添加到当前数据分片di,若数据块di的大小大于B,则i=i+1。即标记单元中的数据可以存在不同的数据分片中,但未标记的单元不可以。
3.2 计算节点的Top-K频繁关键字算法
节点存储数据结构如下。
(1)叶子节点n1的STL中存储Rn1对象的关键字聚集频率,并按频率降序排列。
(2)n1的STL大小为:|Vn1|,Vn1={Uo∈D,o.loc∈Rn1o.Terms}。对于Vn1中的关键字t,STL中存储的项为<t,t.ObjectEntries,t.Freq>;
(3)t.ObjectEntries中包含nl中包括t的对象,每一项格式为<Loc,Freq>,分别表示该对象的位置和包含t的频率;
(4)t.Freq为t.ObjectEntries中所有项的Freq分量之和。
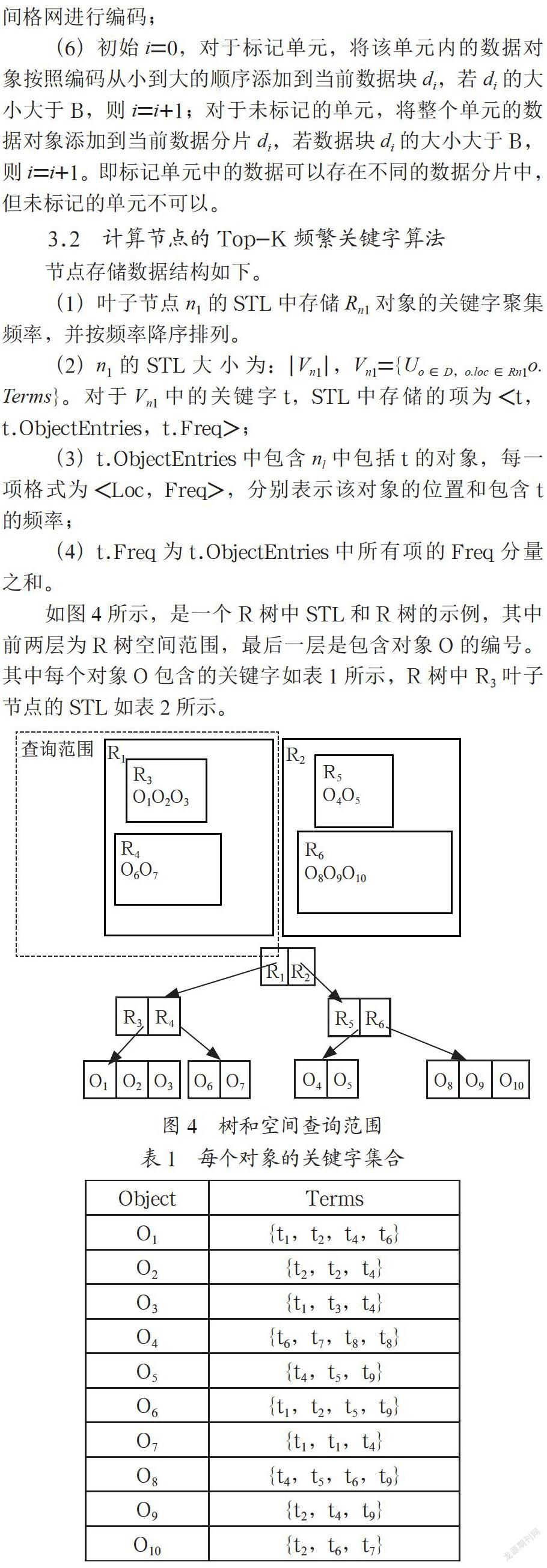
如图4所示,是一个R树中STL和R树的示例,其中前两层为R树空间范围,最后一层是包含对象O的编号。其中每个对象O包含的关键字如表1所示,R树中R3叶子节点的STL如表2所示。
Algorithm2计算节点Top-K查询算法(RQ):
输入:查询空间RQ。
输出:Top-K频繁关键字以及他们的频率值。
(1)从根节点开始,向下查找所有与RQ相交的叶子节点(n1,…,nm);
(2)如果叶子节点n1完全包含于RQ,则n1的STL全部用于后续计算;如果叶子节点n1部分相交于RQ,则n1的STL中与RQ相交的部分用于后续计算;
(3)对于每个<t,t.ObjectEntries,t.Freq>,利用ObjectEntries中的<Loc,Freq>计算RQ内的t.Freq;
(4) 為t在叶子节点与RQ相交部分出现的次数,利用所有参与计算的STL,使用RA或者NRA算法计算Top-K结果,Top-K计算函数为 。
3.3 基于FT算法的Top-K频繁关键字的查询算法
对于分布式系统来说,关键是如何将各个计算节点的结果整合到Master节点。
本系统选择了FT算法作为分布式系统Top-K频繁关键字的查询算法。先介绍两个概念,第一个是每个关键字的和(Ssum),关键t的和Ssum(t)=S1(t)+S2(t)+…Sk(t),如果第i个节点已经将它本地的关键词t的频率Pi(t)发到了中心节点则Si(t)=Pi(t),否则Si(t)=0。第二个是阈值Hi,其中Hi表示节点i中排名第k的关键字的出现次数,作为后续该节点排名k以后的关键词出现次数的阈值。
Algorithm3 FT(RQ)算法如下。
(1)每个计算节点i将排名前k个关键词、数值和Hi发送给Master,Master计算收到的所有关键字的Ssum,然后根据Ssum对关键字进行降序排序,取第k名的Ssum作为阈值P1。之后根据Hi计算第k后的关键字的上限值Usum(其中Ssum(t)=S1(t)+S2(t)+…Sk(t),Si(t)=Pi(t)或Hi),将Usum小于P1的关键字削减掉。
(2)Master将没有被削减的关键字(包括排名前k)再次发送到计算节点,计算节点接收到关键字列表后,找到列表中还未发送给Master的关键字j,并将j和j的值发送给Master。中心节点对收到的所用关键字再次进行求和,然后取第k名的数值作为阈值P2。如果P2≥H1+H2+…Hm(假设有m个计算节点),那么算法就结束了。否则(可能存在某个关键字在所有节点中都不排在前k,但总和排在前k),继续进行步骤(3)和步骤(4)。
(3)Master中令M=P2/m,循环比较所有Hi与M,如果Hi (4)类似第二阶段,Master将没有被削减的关键字(包括排名前k)再次发送到计算节点,计算节点接收到关键字列表后,找到列表中还未发送给Master的关键字j,并将j和j的值发送给Master。中心节点对收到的所用关键字再次进行求和,然后前k名的关键字即为精确解。 4 系统流程 主要分成数据建立和数据查询两个过程。 建立过程:首先,对于给定的空间中的数据集D,分布式计算节点个数k,利用基于Hilbert空间排列码的空间划分策略,将数据集D中的点分配到k个计算节点上,每一个计算节点维护一个区域划分。然后,在本地节点上利用本地数据建立一棵R树,R树的叶子节点上存储STL。然后,从各个计算节点的本地索引R树中取出一些点作为全局索引。再将全局索引分配到相应的计算节点的内存当中,其中内存中也为全局索引维护一个R树。 查询过程:以上的工作做完后,系统收到一个查询Q (RQ,K),将Q发送到所有空间区域与Q.RQ相交的计算节点中。每一个收到Q.RQ的节点在自己的内存中搜索全局索引,再根据全局索引gi(ip,port,address,region)中的ip,port和address信息找到gi所在的计算节点中的外存中的地址,隨后在本地R树中运行获取当前查询对应R树的叶子的所有STL信息。最后,利用对各个计算节点上的STL进行全局的Top-K过程,得到目标的Top-K输出,查询过程如图5所示。 5 结 论 在空间数据量越来越大的情况下,使用分布式框架可以有效节约计算资源,灵活存储数据。本文设计了基于Hilbert两层格网划分方法的分布式空间数据库集群,并且设计了两层索引结构,在索引算法中充分将大量计算工作分给计算节点。目前给出的算法和系统框架在理论上可以解决空间数据库Top-K频繁关键字的问题,具体实现整个系统并且调优测试,还有待今后进一步研究。 参考文献: [1] 王金宝.云计算系统中索引与查询处理技术研究 [D].哈尔滨:哈尔滨工业大学,2013. [2] AHMED P,HASAN M,KASHYAP A,et al. Efficient Computation of Top-k Frequent Terms over Spatio-temporal Ranges [C]//Acm International Conference on Management of Data.New York,USA:ACM,2017. [3] 李雷,李晓东,刘欣阳.分布式网络中的一种高效top-k求解方法研究 [J].计算机工程与应用,2010,46(18):89-92. [4] 余利峰.面向分布式空间数据库的矢量数据存储与查询处理关键技术研究 [D].杭州:浙江大学,2018. 作者简介:姚远(1998.06-),男,汉族,黑龙江大庆人,就读于计算机学院,本科在读,主要研究方向:大数据科学。
