
机器学习在收单系统信用卡套现侦测中的应用分析
2019-09-18 03:58陈泽瀛于卫国
中国科技纵横 2019年14期
关键词:机器学习
陈泽瀛 于卫国


摘 要:随着互联网金融的迅猛发展,交易欺诈手法呈现出快速多变的发展趋势,而受制于人力、时间、空间等多种因素,仅凭专家经验的方式难以应对复杂多变的外部风险。为更好适应收单业务互联网化的发展趋势,防范各类欺诈风险,需要将以经验驱动为主导的工作方式转变为以数据驱动为主导的工作方式,通过应用大数据、人工智能等技术将沉淀的数据转换成有用的风控模型,提高智能化风险管控能力。本文研究利用机器学习的方法,识别收单业务中信用卡套现行为,并对建模方法给了完整呈现。
关键词:风险管理系统;机器学习;信用卡套现
中图分类号:TP181 文献标识码:A 文章编号:1671-2064(2019)14-0058-03
1 建模过程
1.1 业务问题定义
信用卡套现是指在银行卡收单业务场景中,商家和持卡人合谋以虚构交易的形式消费,然后商家以现金返还给刷卡人。传统的反信用卡欺诈依赖于专家规则,需要大量的人工核查成本,并且具有明显的滞后性。利用机器学习方法构建分类器,从大量、高维历史数据中学习套现行为模式,并精准识别存在典型套现行为的商家,打击此类违法行为。
1.2 数据基础
收单机构在业务过程中积累了大量的商户数据,交易数据和样本数据。结合以往的业务经验,对这些数据进行分析,尽可能的构建更多特征来刻画商户行为,形成最终特征宽表。本业务构建的特征宽表包含静态特征21维,动态特征979维。动态特征可按照日期间隔动态配置为天、周、月、季、年等不同的维度。
1.3 数据抽取
在2016年1月至2017年12月的流水数据和商户数据基础上,构建特征宽表。由于2016年和2017年黑样本数量差距过大,数据分布不同,所以选择2016年数据进行建模。训练集选取2016年2月到2016年7月的样本,测试集分别选取2016年8,9月的样本。模型更新测试选取2016年4月到2016年9月的样本為训练集,选取2016年10月的样本为测试集。数据抽取为分层采样,抽取10%的白样本和100%黑样本,采样比例约为1:50。特征宽表样本数量分布如表1所示。
按照业务要求,定义以商户、日期为一个样本,每个样本需要涵盖商户过去交易、商户画像等特征信息。由于样本特征都是按天统计的结果,所以首先需要将流水表里的数据按照商户和日期分组,然后对金额、笔数等字段进行汇总,从而得到特征宽表。
1.4 分析建模
1.4.1 冗余处理
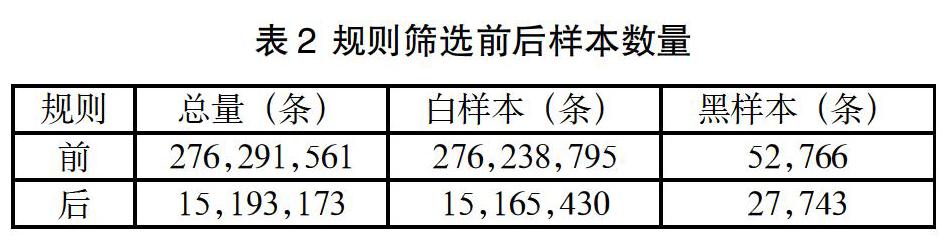
为了剔除明显没有套现风险的白样本,在数据进入模型之前采用一些规则过滤部分数据。原则是在减少少量黑样本的条件下大幅减少白样本。方法是首先筛选黑样本,然后观察商户当天信用卡交易笔数、金额、最大交易金额、交易笔数占比、商户分店数、终端数的分位数分布,取值大于等于1/4分位数的那些样本。规则筛选前后样本数量(2016-02到2016-12)分布如下。
从上表2可以看出,规则筛选后,黑样本减少了约40%,白样本减少了约90%。事先用规则剔除样本的作用有三点:
(1)减少数据量,提高模型运算速度,减少模型运算时长。
(2)保证在训练集抽样过程中,尽量抽取到与黑样本较难区分的白样本,使模型的训练更有针对性,提高模型预测精度。
(3)剔除不准确标记的黑样本,减少错误标记对模型的干扰。
1.4.2 异常值控制
建模过程中涉及对样本数据的异常值确认。一般通过大量的统计工作,将明显异常的观测值排除出建模样本,或者采用分位数来确定数据的正常值范围。树模型对异常值不敏感,因此当选用GBDT模型来构建分类器时,无需对异常值进行处理。
1.4.3 特征选择
过高的数据维度往往增加了模型训练和预测时的资源消耗,甚至降低模型效果。根据树模型输出的特征重要性排序,通过多次实验,使用模型输出的前100个重要特征重新建模,依然能维持甚至提升模型效果。
利用原始特征建立模型,然后根据模型的输出对变量重要性进行评估。线性模型系数通常反应特征对响应变量的影响程度,GBDT模型可以输出入模特征的重要性,数值越大表示该特征重要性越强。
1.4.4 模型训练
使用机器学习平台构建的完整建模流程图如图1所示。
HiveTable:从Hive表中读取带有标记的特征宽表。
TimeFilter:按时间切分,把特征宽表中数据分为训练集和测试集,以2016-08-01为切分时间点,前6个月的数据(2016-2-1到2016-7-31)为训练集,后1个月数据为测试集。
QuataRandomSample:对数据进行抽样。当输入为训练集时,表示对训练集按照某一列进行抽样。
GbdtClassification:调用GBDT模型,输入为抽样之后的训练集数据。
EvaluateClassificationModel:观测模型在训练集中的表现,评估模型效果, 默认阈值为0.5。
PredictClassification:对测试集数据进行预测。
EvaluateClassificationModelOnly:评估模型预测效果,展示在不同阈值下模型的Precision,Recall,F-Score,Auc等指标。
1.5 模型评估
表3是GBDT模型在相同训练集条件下不同测试集中的表现结果。在2016年8月份的测试集中,阈值为0.5时,模型精度和召回分别能达到0.32和0.35。精度和召回两项指标中套现场景更加注重模型的精度表现,在提高阈值后,模型在多个测试集中的精度均能达到0.5以上。
随着时间增长,模型效果呈下降趋势,但整体保持稳定。表4显示了用2016年4月到9月数据训练模型之后,效果有显著提升。阈值为0.9时,更新之后的模型将精度和召回分别从原来的0.53和0.05提升到了0.66和0.11。因此为了保证模型有较好的预测水平,应该定期对模型进行更新,用最新的数据训练模型。随着阈值提高,模型召回率在下降,精确率在提升。对精度要求高于召回要求的场景,应该设置较高的阈值,提高黑样本的置信度。
2 应用分析
现有场景中只设置了规则,规则需要经验丰富的业务专家来设置调整,并且这个过程需要一定的时间要求和人员能力要求。现有规则触发量大,面对风险交易无法及时阻断调查,对于风险交易需要一定的人力去调查。
机器学习模型系统对于现有规则系统的主观经验是一种替代和强化。机器学习模型的方式可以极大的增加预测的准确率,并且在一定程度上可以弥补规则的短板,模型的输出是概率值,可根据实际业务情况调整阈值,比较灵活。
在现有的模型中,主要能起到以下几个作用:
(1)能够提供及时的预测,提高业务效率。
(2)能够输出套现概率,有利于业务人员的决策。
(3)能够对规则进行补充,捕捉到大量灰样本。
3 結语
一方面,目前模型的效果在以往规则基础上提升了十余倍,极大地降低了业务人员案例核查成本。另一方面,模型仍然有很大的提升空间。优化的方向可以参考以下几点:
(1)本次建模过程中测试过集成模型,具体思路是用第一个模型识别出大量的白样本,用第二个模型针对性识别预测为黑的样本,但效果提升不大。未来可以进一步分析该种集成方法的可行性和具体集成模型构建方案。
(2)有监督模型训练集抽样时,先利用聚类方法,从不同的类簇中抽取白样本,使抽取到的白样本更能准确代表总体白样本分布,从而提高模型识别精度。
(3)根据业务风险,构建更具相关性的特征,对建模过程多次迭代优化。
(4)更进一步分析不同的套现场景,建立各自不同的特征,不同的黑白样本标注准则,对每个场景分开建模。
(5)对每个分支机构单独建模。
参考文献
[1] 方向,肖晓飞.数据仓库和数据挖掘技术在CRM中的应用研究[J].太原科技,2008(02):39-40.
[2] 谢平,邹传伟.互联网金融模式研究[J].金融研究,2012(12):11-22.
[3] 刘镇.人工智能和机器学习在金融领域的发展及对金融稳定的影响[J].吉林金融研究,2018(02):36-38.
[4] 吴载斌.互联网时代的信用卡欺诈风险管理浅析[J].中国信用卡,2017(04):15-17.
[5] 蔡文学,罗永豪,张冠湘,钟慧玲.基于GBDT与Logistic回归融合的个人信贷风险评估模型及实证分析[J].管理现代化,2017,37(02):1-4.
猜你喜欢
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
