
基于Scrapy和Hadoop平台的房屋价格数据爬取和存储系统
2019-10-09 05:48丁志毅
电子技术与软件工程 2019年17期
文/丁志毅
随着大数据、云计算、人工智能等新兴计算机技术的急速发展,所产生的数据呈爆炸性增长,如何实现存储和计算能力的分布式处理,摆脱目前传统的计算技术和信息系统的处理方式,是目前数据分析领域亟待解决的问题。Hadoop 是使用 Java 语言开发的分布式计算存储系统,是一个由Apache基金会支持的开源项目,提供可靠的,可扩展的分布式系统基础架构,能够跨计算机集群分布式存储海量数据,允许使用简单的编程模型分布式处理数据。用户可以像操作本地文件系统一样透明的访问HDFS,常应用于海量数据的场景。
1 爬虫系统的设计与实现
1.1 爬虫基本原理
网络爬虫的主要作用是依据一定的爬行策略自动的从网上下载网页镜像到本地,并能够抓取所有其能够访问到的网页以获取海量信息,解析其中的数据进行分析挖掘等。其基本工作原理如下:首先初始化一个URL作为爬行的开始位置,如果该 URL没有被抓取过,解析其DNS信息,尝试与这些 URL链接所在的服务器建立连接,自动提取页面上的信息保存至本地,同时提取新的 URL,根据一定的遍历算法将其去重过滤后加入待爬取队列,重复以上步骤遍历所有的网页数据,直到待爬取的队列中没有可用的 URL,满足停止的条件时结束爬取。
1.2 爬取模块
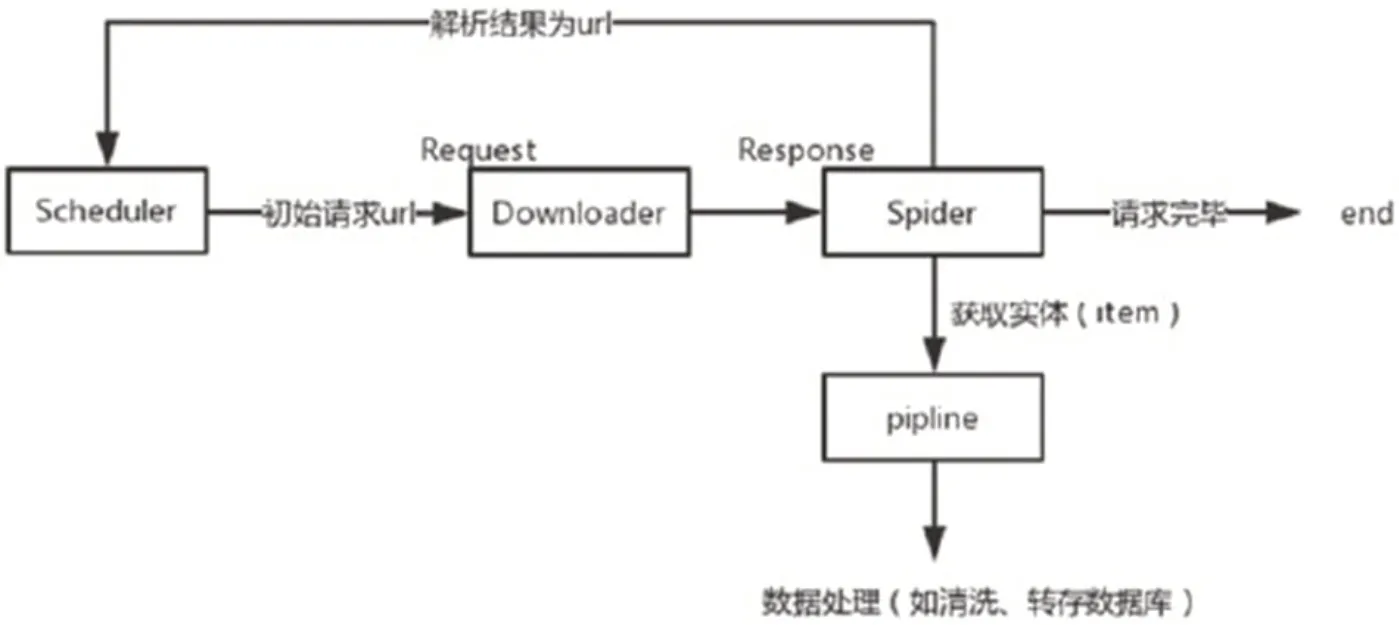
图1:Scrapy爬虫的流程
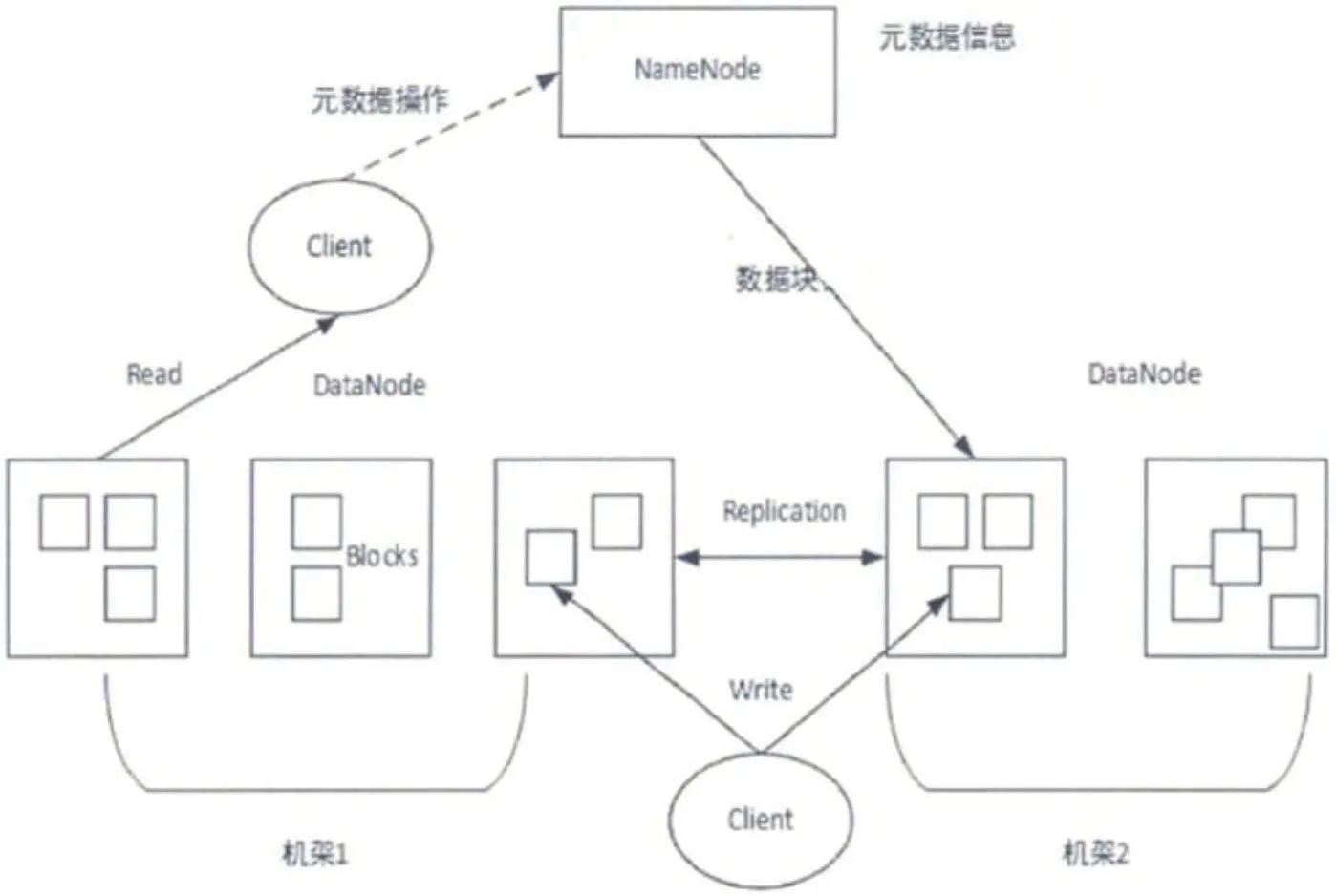
图2:HDFS系统结构
Scrapy是一款开源的网络爬虫框架,是使用python 语言开发并封装的一个强大的自动数据采集框架,目的为了爬取网站内容,提取结构性数据。无需再从零开始去设计爬虫框架,而是可以简单、高效的搭建python 的 Scrapy 框架,通过 Scrapy 框架提供的功能进行定向的数据爬取工作。在 Scrapy 项目中,可以方便地自定义爬虫的爬取规则,即可快速获得所需要的网页数据,同时一些固定的前置后续处理可由一些稳定的开源库帮助解决,并可根据需要将关键数据保存为特定的数据格式。Scrapy 爬虫的流程如图1所示。
Scrapy 强大的功能得益于他的构架,他总共有 8 个部分组成:
1.2.1 Scrapy Engine 组件
爬虫框架的引擎组件,是整个框架的“大脑“,负责所有组件的数据流动。
1.2.2 Scheduler 组件
调度器组件,负责接收并创建请求队列。
1.2.3 Downloader 组件
下载器组件,负责下载网页数据。
1.2.4 spiders 组件
爬虫模块,其功能在于从特定的网页结构数据中获取指定信息,在 Scrapy 中被定义为实体(Item)。
1.2.5 Pipeline 组件
负责对数据进行清理、验证以及持久化(转存数据库)的处理。
1.2.6 Downloader middlewares
其在引擎和下载器组件之间,功能是负责引擎发出的请求,以协调下载组件工作。
1.2.7 spider middlewares
负责处理爬虫数据的输入和输出,主要是为了提高爬虫质量,可以同时使用不同功能的下载中间件。
2 HDFS存储模块
HDFS 采用典型的主从式(master-slave)设计,在该设计中主要包含两种节点:主节点(NameNode)和数据节点(DataNode)。主节点负责管理整个文件系统的命名空间;另外一种 DataNode是从节点,为数据提供真实的存储、管理服务。DataNode 最基本的存储单位是 Block,文件大于 Block 时会被划分为多个 Block 存储在不同的数据节点,其元数据存储在NameNode中,全局调度数据块的读写操作,主要用于定位block与DadaNode之间的对应关系。用户如果操作 HDFS 文件时,需要先访问 NameNode 节点,读取元数据(metaData)信息,得到存储位置后再访问 DateNode 。其架构如图2所示。
经Scrapy采集到的数据需要持久化到hdfs中,python语言来访问Hadoop HDFS时,需要引入pyhdfs库,通过pyhdfs提供的API接口实现对hdfs的操作。HdfsClient这个类可以连接HDFS的NameNode,用来读、些、查询HDFS上的文件。代码示例:
Client=pyhdfs.HdfsClient(hosts="192.168.1.108,9000",user_name="hadoop")
从本地上传文件至集群
client.copy_from_local("D:/test.csv","/user/hadoop/test.csv")
打开一个远程节点上的文件,返回一个HttpResponse对象
HttpResponse response = client.open("/user/hadoop/test.csv")
3 结语
在房地产市场领域,浩瀚的网络资源已经呈现出大数据的特点,传统的信息处理技术已经无法适应需求。针对无法进行有效数据分析的现状,本文研究利用Scrapy网络爬虫框架和HDFS 分布式文件系统进行数据的采集和存储。HDFS 能为不断增长的数据提供高度的容错、高吞吐量和分布式储存服务。通过提升大数据分析技术在房地产行业中的应用水平,充分利用 Hadoop 平台的优势,转变数据存储方式和计算模式,加强数据的分析和挖掘,提高政府及有关部门对房地产市场分析的广度和深度,更好的为政府决策、行业管理提供决策依据是下一步的主要研究工作。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
北京航空航天大学学报(2022年8期)2022-08-31
现代信息科技(2021年21期)2021-05-07
创新作文(1-2年级)(2019年3期)2019-09-03
当代陕西(2019年14期)2019-08-26
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
上海理工大学学报(社会科学版)(2015年3期)2015-11-30
