
基于用户画像的科学数据管理模型研究
2019-10-09 05:49王显斌
电子技术与软件工程 2019年17期
文/王显斌
现阶段国内外图书馆领域用户画像研究主要以技术为主,主要包括了两个层次,即User Persona和User Profile,使用的算法模型大致可分为3大类:
(1)基于概率主题的用户文本建模推断模型;
(2)基于排序的启发式函数推断模型;
(3)基于分类器结合特征工程的预测模型。
Gauch S等将用户画像描述为一组加权标签、概念层次结构或语义网的集合,包括用户基本素养、文化水平、社会背景、社交情况、工作情况、可支配时间等因素[1]。Zaugg H认为图书馆的空间与服务的设计应该关注用户需求,可以借鉴营销领域和产品设计中用户画像的应用,进行图书馆空间与服务的设计[2]。国内曾建勋认为图书馆精准服务需要用户画像,用户画像可以更好地认识网络中的用户、改善网络信息组织、发现信息传播规律[3]。胡媛认为数字图书馆知识社区用户画像可分为读者基本信息、用户兴趣爱好、用户活跃度三类标签模型,提出了数字图书馆知识社区综合服务能力评价指标体系[4]。
现阶段国内图书馆领域用户画像研究主要以个案研究为主,针对具体不同应用场景和目标,构建不同用户画像模型,针对科学数据管理场景的用户画像研究目前还非常少。本文综合心理学、信息学等多学科知识,从科学数据用户画像概念和内涵分析出发,构建用户数据驱动相结合的科学数据用户画像模型和系统,深入探讨用户画像在科学数据管理领域的应用。
1 科学数据用户画像内涵分析
1.1 科学数据用户群体边界具有动态性
用户画像的目的是通过对特定行为群体特征的总结和提炼,为精准化服务提供量化支撑。因此,用户画像对目标用户群体边界的界定越明确,画像结果越有针对性。在科学数据管理中,学术行为和学科背景对科研用户群体边界的界定产生重要影响,导致科研用户群体边界处于动态变化中,原因有两个:
(1)科研人员跨学科研究行为越来越频繁,所跨学科对象也处于动态变化中;
(2)科研人员研究方向也处于变化当中。
1.2 用户画像关注的是“典型用户”
用户画像关注的是“典型用户”而不是“平均用户”,其结果具有明显的区分度和针对性,可以更精准地识别特定用户的动机及行为偏好。在科学数据管理中,科研用户画像有效性体现在对目标用户群体的用户属性特征的提炼与总结。
1.3 科学数据用户属性包含知识属性
典型用户画像属性包括静态属性和动态属性。静态属性是相对稳定的用户信息,如人口属性、职业等;动态属性是用户不断变化的信息,如场景、媒介、路径等。在科学数据管理中,科研用户画像解决的是知识服务的精准化问题,关注的焦点和最后的评价不是“我是否提供了您需要的信息”,而是“是否通过我的服务解决了您的问题”。因此,科学数据用户属性应突出知识的特性,可划分为静态属性、动态属性和知识属性。
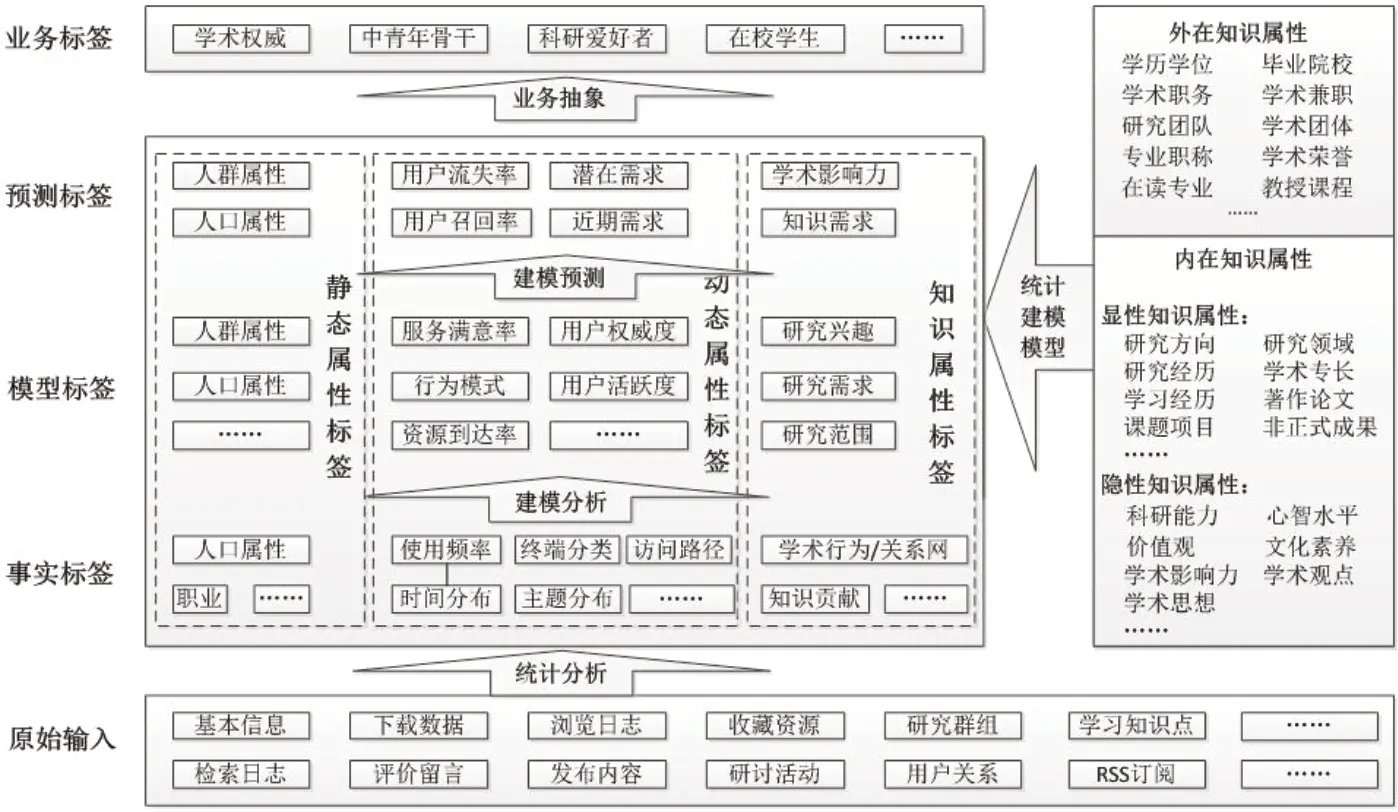
图1
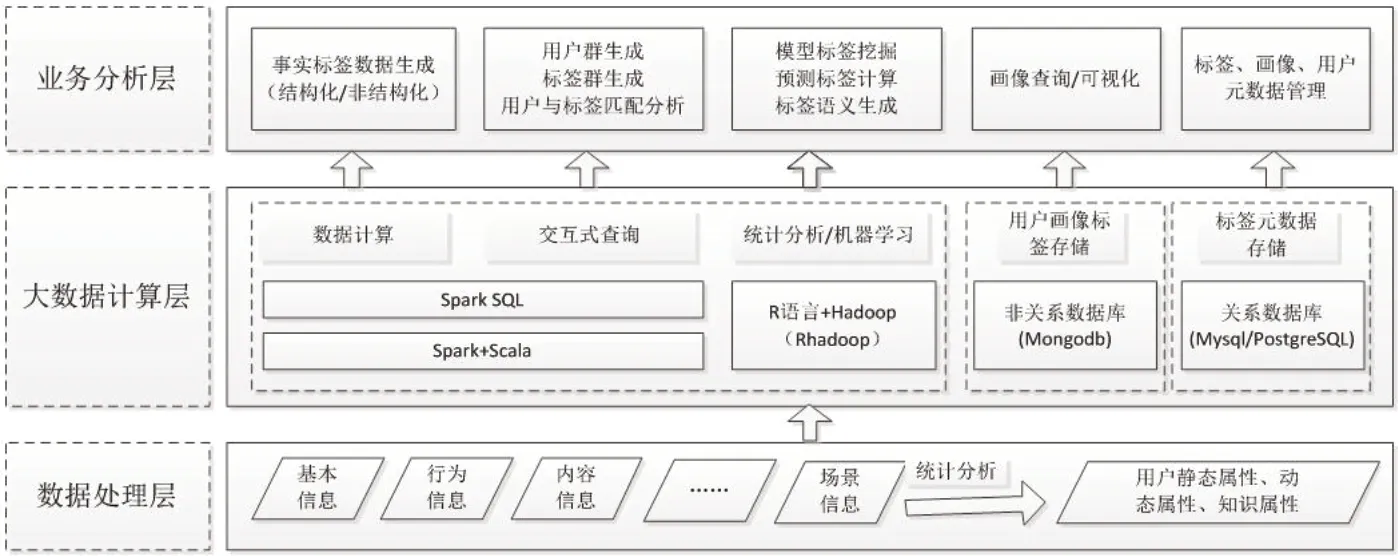
图2
2 科学数据用户影响因素分析
2.1 科学数据用户知识属性具有半动态性特征
科研人员的学科背景一般相对固定,但是随着跨学科研究的开展和研究方向的不断变化,科研人员往往需要具备多学科知识,需要不断了解新领域,补充新知识以支撑其研究活动。因此,科研用户知识属性的核心(学科背景)相对稳定,但其外延一直处于动态变化中,即一种半动态化状态。
2.2 科学数据用户知识属性的分类
科学数据用户知识属性可分为外知识属性和内知识属性两类。外知识属性是指外部环境作用于个体身上的各种与知识有关的元素集合,包括:学历学位、毕业院校、学术职务、学术兼职、参加学术团体、专业职称、学术荣誉等。内知识属性是指个体自身具有的各种与知识有关的元素集合,参照显性知识与隐性知识的概念,可分为内在显性知识属性和内在隐性知识属性。内在显性知识属性包括:研究领域、学术专长、著作论文、非正式成果等。内在隐性知识属性包括:心智水平、文化素养、学术思想、学术影响力等。科研用户的知识属性蕴含着较多的语义信息,需要在标签基础上引入语义表达。
2.3 科学数据用户受场景驱动和心理影响
不同的时间、地点、研究阶段等知识场景下,用户需求会有差异。例如:撰写论文时,会关注当前研究热点;而教学时,更想要梳理出该学科的知识体系。同时,用户心理状态不同,其知识需求也存在差异。例如:刚进入新研究领域时,一般对研究工作持乐观心理;随着研究的深入,会出现困惑或迷茫,心理上会变得焦虑,体现在行为上就是大量盲目地学习和收集资料;度过失望期之后,心理上才会逐步的平稳。这种心理和情感上的变化可以通过社会心理学进行分析。
3 科学数据用户画像建模
用户画像建模就是构建用户标签体系,可分为结构化标签体系和非结构化标签体系两类。非结构化标签体系彼此之间无层级关系,各个标签反应各自的用户兴趣,不仅能够涵盖结构化标签体系,更能细致地表达语义上的分类,如资源发现系统中的关键词、学术社区中的文档主题模型(Topic Model)等。科学数据用户非结构化标签体系可分为四个层级:即事实标签、模型标签、预测标签和业务标签。每上层标签都由下层标签抽象计算组合生成,其中业务层标签需要人工进行定义。如图1所示。
4 科学数据用户画像算法及系统设计
用户的静态属性反映着用户的基本情况,是连接线上和线下的纽带,定义函数表示其在一定场景下对标签的影响权重,则公式如下:
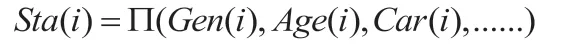
同理,可以推导出用户动态属性在一定场景下对标签的影响权重
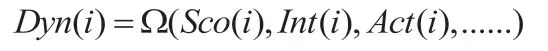
5 结语
本文从科学数据用户画像内涵出发,对科学数据用户影响因素进行分析,最后构建了科学数据用户画像模型和系统。其中的重难点有两个:
(1)多源异构数据导致数据融合困难,必须设计合适的降维方法、特征选择方法、模型融合方法;
(2)数据稀疏性较高导致属性特征组合困难。这将是下一步研究的重点。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
小哥白尼(神奇星球)(2022年3期)2022-06-06
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
铁道通信信号(2020年4期)2020-09-21
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
