
基于数字图像处理的字迹识别技术
2019-10-11 01:38陈锦玉
电子制作 2019年18期
陈锦玉
(北京市第四中学,北京,100043)
0 引言
字迹识别是对人通过落笔形成的字迹进行鉴别和分析的活动,也叫笔迹鉴定[1]。不论年龄大小,在一定时间内,人的书写习惯都会具有一定的特征性和稳定性,并反映在字迹中。通过对笔迹的观察和分析,可以分辨出文件中的字迹来自于几个人,是否是本人所写,利用笔迹进行一个人身份的认定,查证文件的真伪。在一般鉴定中,要先了解案件的大致情况,明确鉴定的要求;再观察分析笔迹有无异样,有无伪装或因为其他原因而导致的字迹问题;然后要选择能反映出本人书写的稳定的习惯的特征;最后,将选材中的特征和样本中提取出的特征进行比较,找出相同点和问题点并制做鉴定书,提出问题点形成原因的综合评断并提出意见[2]。
字迹识别作为人们的另一种身份证明,应用广泛,每年约几万个案件涉及字迹识别技术,在生活中也常用到[3]。但相对于人脸识别、指纹识别等,字迹识别技术的发展和应用并没有受到太多重视[4],无论是在刑事案件上还是民事诉讼上,一旦需要字迹鉴定都只能到司法机关鉴定,且需要一年的时间才能出鉴定结果。过程之长增加了很多问题的复杂度。本文将利用计算机代替人工鉴定,使字迹识别过程更快更准确。
因为现阶段大部分字迹识别还仍靠字迹专家观察鉴定,于是就存在字迹识别的主观臆断、人才短缺、酬金过高、申请流程复杂、分析时间过长等问题。专家鉴定这种人为观察判断很容易受主观心理的影响而使分析结果有一定的偏差,而现阶段国内字迹专家人数相对较少,不能保证技术的全覆盖和便利性,这一点对民众来说也是极大的困扰。如,很多人因为借款方不承认欠条上的签名是自己签的而拿不回应得的借款,若他们拿欠条去做鉴定,更是需要长达一年的时间才能得到结果,很多人因此放弃打官司,使不法分子逍遥法外,而为了保证质量,人工鉴别必须需要大量重复性工作来验证结论。而如今随着计算机技术的迅速发展,特别是图像处理技术的日益成熟,为字迹识别与鉴定提供了条件良好的基础。
结合上述问题,通过了解和研究后,本文考虑到可以用图像处理的方式来解决这个问题,这样就能够极大地解决在字迹识别方面出现的很多问题。现阶段对于基于图像处理的字迹识别技术方面的研究相对较少,大多数是从整体到局部分析笔画间的结构,用纹理分析法获得全局特征,从特征字的比较提取局部特征的方法,把整体和局部特征进行整合综合决策。本文也将运用图像预处理法,结合构建大数据数据库的方法,通过笔记采集的方式采集样本,提供后台的数据支持。在后续的技术完善中,我们构想将这些技术编入APP 或设备中,直接通过设备拍摄图像,直接鉴别,做到速度更快,成本更低。
基于图像预处理的字迹识别技术将一定程度上解决国内字迹识别主观臆断、专家短缺和流程复杂的问题,极大地便利了各地警方破案的效率。同时,在民事诉讼方面,如在借条、合同造假等问题的分析和解决上更是提供了捷径,加快了法律流程的速度,使人民积极参与法律活动,更便利快捷和有效地维护自身利益。本文运用大数据分析法,通过笔记采集的方式,利用计算机更快捷有效地解决问题。在此之后,我们可以构建全国字迹大数据数据库,录入每个人的字迹,使之成为继脸部识别、指纹识别后,又一个认证身份的有力证据。
1 图像预处理
1.1 图像拍摄与灰度化
由于获取图像的工具或手段的影响,最开始得到的图像会受到多种条件的限制和不同的干扰,一般不能直接使用,必须要在视觉信息处理的早期阶段对原始图像进行灰度化处理、二值化处理等的矫正,使矫正后的图像选择性地体现原始图像上的信息,滤掉影响因素,增强某些对于往后的处理中比较重要的图像特征。因此图像预处理就显得尤为重要,本文也将先运用灰度化、二值化的方法对图片进行初步处理。
灰度化处理是指,使具有色彩的图像转化成灰度图像的过程。在彩色图像中,每一个像素的色彩都取决于R、G、B 三个分量,其中,每个分量都另有255 个中值可以取到,这样处理后,每个像素点就有255*255*255 种变化范围变化色彩。灰度图像就是由相同的这三个分量组成的一种特殊的图像,其中,像素点的变化范围就有255 种。虽然灰度化后的图像在原图的基础上改变了大部分的色彩,但它同样可以反映图像整体和局部的色度和亮度等级的分布特征。因为R、G、B 三个分量代表的是彩色值,我们需要将它们转化成灰白图像。这里,我们采用RGB 和HIS 的转换,在算法中,HIS 和RGB 的转换公式如下:
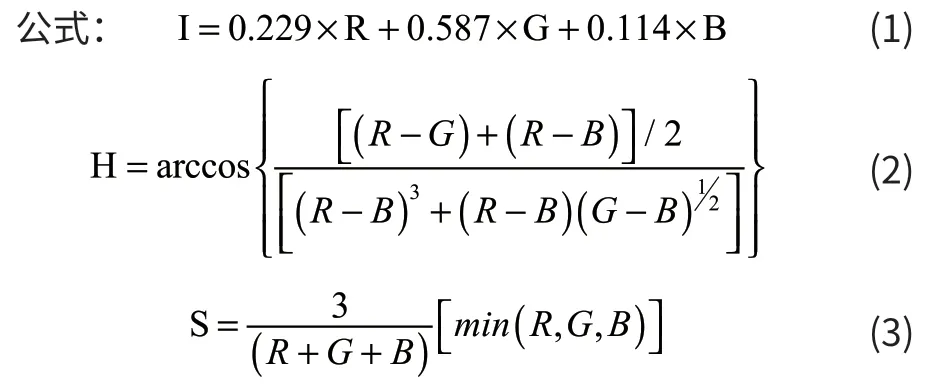
在公式(1)中采用了加权平均法进行灰度化。
灰度化处理图片的方法有很多:①分量法(做三个灰度图像,灰度值分别选取原图中的三个分量的亮度,再根据需要选一幅图像)。②最大值法(灰度值采用三个分量中亮度的最大值)。③平均值法(灰度值采用三个分量亮度的平均值)。④加权平均法(灰度值选取三个分量亮度的加权平均)。本文运用第三种平均值法,希望能快速简易并合理地处理图像,并结合灰度拉伸技术,使图像的细节更加突出。
图像二值化(Image Binarization)指将整个图像呈现出明显的黑白效果的过程,也就是将图像上的像素点的灰度值设置为0 或255。经过二值化处理过后的图像在关于字迹识别的图像处理中同样地位重要,经过二值化处理后,图像中的数据量大幅度降低,因此,处理后的图像轮廓更鲜明。

1.2 图像的滤波去噪
对于经过灰度化和二值化处理后的图像,为了减少图像灰度的尖锐变化,减小噪声,在字迹识别的图像处理过程中,图像的滤波去噪技术同样是一个重要的步骤。通过图像的滤波去噪,可以更便于观察。如今图像滤波去噪有很多途径值得参考:运用均值滤波器、中值滤波器、最大值滤波器、最小值滤波器。通过对比可以发现:最大值滤波器和最小值滤波器都存在一定程度上忽略细节的问题,最大值滤波器使图片过亮,最小值滤波器使图像更暗,两者都造成了很大程度上的失真,而对于均值滤波器来说更是存在边缘模糊的问题。这些问题看似很小,但在字迹识别,一个比较注重细节的问题上却会造成很大的影响。对比下来,用中值滤波器进行滤波去噪虽然也存在忽略细节的问题,相对于这两种算法,中值滤波器忽略的细节会相对少一点,失真也没有那么严重。同时中值滤波器在边缘上也比均值滤波器清晰。于是,通过对比,本文将运用中值滤波器来处理字迹图像。中值滤波器的原理就是将各个颜色点排序,在一个特定的范围中取中值,使这个特定范围中的颜色点都和中值颜色一样。在中值滤波器中,有3*3、5*5、9*9、15*15、35*35 的处理,为了减少图像模糊的问题,我们选用3*3 的处理方法。
1.3 图像的归一化
图像归一化,顾名思义,就是将图像的格式统一,让它转换成有一固定标准形式的图片的过程,而这种处理后的图像就被称作是归一化的图像。最开始的图像在经过了几步特殊的处理后就能成为副本图像,而标准图像就是由这些图像经过相同参数的图像归一化处理后得到的。
在字迹识别方面,我们需要应用图像归一化来调整字迹和字迹之间的间距和行距,使字迹看起来更工整,也更方便对字迹进行特征的提取和对比。
2 字迹特征提取识别
2.1 建立字迹数据库
为提取字迹特征,首先需要用建立数据库对各种已知出处的笔迹进行归纳整理。本文事先采集了五十个不同出处的字迹原件,形成一个小型数据库。为了更方便更快捷地从数据库中找到对应的字迹,在处理时我们会先将数据库中的字迹原件进行先一步分类,提高处理效率。
首先通过整体纹理,再通过汉字局部识别。在实验中,选取了50 个不同的字迹,建数据库,从中随机选取一个作为待识别的字迹。对于字迹纹理识别,我们选用分类的方法,在处理前将收集到的字迹分成三类:左倾、右倾、竖直。经过纹理识别后可提前获知被分配的类别以减少后续工作量。
傅立叶变换也称傅氏变换,是一种常用的信号分析方法,它可以分析信号的成分,也可以用来合成信号,傅立叶变换选用了正弦波作为信号的成分。傅立叶变换在概率学、声学、海洋学、密码学、结构动力学等领域都有着广泛的作用,甚至可以将一首曲谱用波的形式来表示。
通过傅立叶公式,将图像信号变成频率信号,再处理后得到p 值。它的大小及方向能体现纹理的大小与粗细,体现图像的排列规律。在频率域图像分析法中,用傅立叶特征来分析图像纹理是一种典型方法。研究者们经常用研究谱成分的方法来研究它的物理意义。具体公式如下:
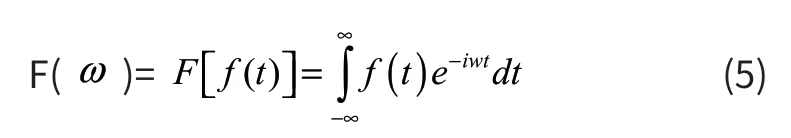
经过傅立叶公式转换后就能用二维图像反应空间中频率的强度。得到的图像就是转换完的功率谱图像。图像中幅值的变化方向和图像的纹理有一定的关系。字迹纹理粗的话,幅值就会比较大。图像的镜像值能体现纹理的方向。由此可知,得到的值在范围内,值的大小和镜像的值能分出粗细与方向。
傅立叶图像转化后可以根据图谱建立坐标,以坐标原点为0,粗纹在原点附近有较高的值,细纹的能量谱向周围散开,坐标轴范围通常为(-N/2,N/2),显出来即可分析纹理的粗细和方向。
通过傅立叶的方式衡量纹理,是字迹的初步识别,属于整体分析。
2.2 字迹局部特征识别
从上文所述的50 种字迹中,本文任意挑选了一种字迹中的一个字和原来的50 个字作对比。步骤如下:
(1)调整图像亮度、色度和饱和度,将50 幅图像的背景统一起来。(2)调整图像大小,统一格式,将图像预处理。(3)将50 个字迹分成了三组:左倾、右倾、竖直。(4)将待测字体大致归为一类或多类后,一对一的拟合。
首先通过整体纹理,再通过汉字局部识别。在实验中,选取了50 个不同的字迹,建数据库,从中随机选取一个作为待识别的字迹。
对于拟合的方法我们选取了数待测字迹中端点、交叉点和拐点的个数,看已知字迹中是否有字迹的三个数据完全一样或相差一点。但在分析端点、交叉点和拐点之前,我们还需要做字迹骨架的优化。
简化后是端点提取。端点可以等效为交叉数,一个黑色像素点的八邻域,当八邻域中只有一组黑白像素交替的话,此黑点就是一个端点。我们设黑像素为(w,z),交叉点数为x,则x 的公式如下所示:
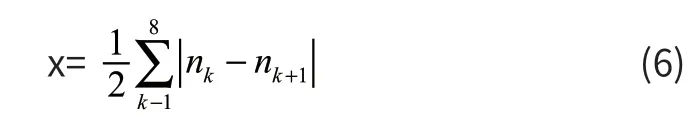
利用这个公式来判断,当x 为1 时为端点,x 等于3 时是交叉点。其中,nk为这个点的八个相邻的点,nk∈{0,1},且n9=n1。在x=1 时,(w,z)就是一个端点。
交叉点与端点提取方法类似,而因为拐点的电脑计算十分复杂,本次采用了计数法。在算出端点、拐点和交叉点后,利用如下公式,计算相似度:
最终我们发现,图1(待测)和图2 的相似度为百分之百,而图1(待测)与图3 的相似度为百分之七十。

图3
最终我们得出结论:图1 和图2 是一个人写的。
3 结论
本文通过对字迹进行预处理、图像纹理识别、图像局部特征识别的方法,实现了笔迹识别与判断,可以解决字迹鉴别不够客观、分析时间长、操作不便利等问题,虽然在准确性上还有待优化,还无法做到百分之百的正确率,但用图像预处理和建立数据库的方法识别字迹能为以后智能化的字迹识别技术提供了参考的依据。希望我的努力,能为字迹识别走向智能化提供参考依据和解决办法,更能为维护广大人民群众利益、提高法律实效性做出一定的贡献。希望字迹识别不再成为法律鉴别里的一道鸿沟,而是作为无辜者建立最坚实的证据出现在法庭上,成为法网编织中不可或缺的、起指向性的重要一环。
猜你喜欢
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
语数外学习·高中版中旬(2020年8期)2020-09-10
作文新天地(初中版)(2020年2期)2020-04-10
装备环境工程(2020年3期)2020-04-03
中学生百科·小文艺(2020年2期)2020-01-13
中学生数理化·教与学(2019年8期)2019-09-18
数学大王·中高年级(2018年7期)2018-08-29
电子设计应用(2004年9期)2004-09-17
