
基于多区域中心加权卷积特征的图像检索
2019-10-15 02:21杨海龙张娜包晓安桂江生
软件导刊 2019年8期
关键词:特征提取
杨海龙 张娜 包晓安 桂江生

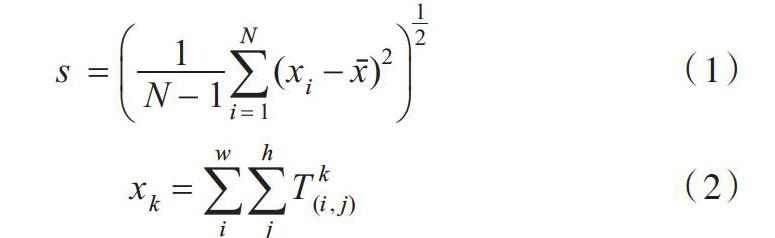
摘 要:针对图像特征局部信息描述不足问题,提出一种基于多区域中心加权深度卷积特征提取方法。首先通过卷积神经网络提取输入图像的卷积层激活特征图,然后通过计算不同通道特征图的差异,选择具有区分性的区域特征图,最后通过多区域权重进行加权聚合,生成用于检索图像特征向量。在不同的建筑物数据集进行实验,结果表明检索精度分别提升了1.2%、0.9%。
关键词:卷积特征;特征加权;特征提取;图像检索
DOI:10. 11907/rjdk. 182855 开放科学(资源服务)标识码(OSID):
中图分类号:TP317.4 文献标识码:A 文章编号:1672-7800(2019)008-0204-04
Image Retrieval Based on Multi-region Center Weighted Convolution Feature
YANG Hai-long, ZHANG Na, BAO Xiao-an, GUI Jiang-sheng
(School of Information Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China)
Abstract:Aiming at the problem of insufficient description of image feature local information, a multi-region center weighted depth convolution feature extraction method is proposed. Firstly, the convolutional layer activation feature map of the input image is extracted by the convolutional neural network, and then the discriminative regional feature map is selected by calculating the difference of the different channel feature maps. Finally, the multi-region weights are used for weighted aggregation to generate the image feature vector for retrieval. After experiments in the image dataset, the retrieval accuracy was increased by 1.2% and 0.9%.
Key Words:convolution feature; feature weighting; feature extraction; image retrieval
基金项目:国家自然科学基金项目(61502430,61562015)
作者简介:杨海龙(1993-),男,浙江理工大学信息学院硕士研究生,研究方向为图像处理。
0 引言
伴随着计算机及互联网技术的发展,各种便携设备逐步普及,图像数据日益增加,如何从海量的图像数据中高效、准确地检索出用户所需要的相似图像成为图像检索研究热点。
以传统手工特征SIFT(Scale-Invariant Feature Transform)为代表[1],出现了如词袋模型(Bag-of-Words,BoW)[2]、费雪向量(Fisher Vector,FV)[3]以及局部聚合向量(Vector of locally aggregated descriptors,VLAD)[4]等局部特征编码方法,BoW局部特征视為视觉词,随后使用K-Means无监督聚类算法“视觉词典”,最后将统计图像中关键视觉词出现频率的直方图作为图像的全局视觉描述。FV算法通过高斯混合模型对不同的局部特征进行聚类,构建需要的视觉特征词典,并使用关键视觉词的均值和方差梯度信息表示图像的全局特征,同等长度的特征检索性能优于BoW算法[5]。VLAD改进了BoW全局特征编码过程,将局部特征与字典中心距离信息累积编码作为图像特征向量。
随着深度学习的发展,深度卷积神经网络(Convolutional Neural Network,CNN)在图像检索领域效果卓著[6]。早期Babenko 等[7]将CNN用于图像检索,提出使用预先训练的CNN提取全连接层特征作为图像特征用语检索,取得了优于传统特征的精度。随后分析了卷积特征包含的局部信息,提出对CNN特征进行池化SPoC(Sum Pooled Convolutional Features)[8],检索精度优于全连接层特征,结果表明卷积层特征比全连接层特征包含更多的图像局部信息;Tolias 等[9]提出了基于区域卷积激活特征最大化的R-MAC(Regional Maximum Activation of Convolutions)特征提取算法,采用不同尺度的区域池化生成图像的全局特征;Kalantidis 等[10]提出了CROW方法(Cross Dimensional Weighting),将卷积层特征按照通道、空间分解,分别计算卷积层特征对应的权重值,最后将其累加求和获取图像描述特征,提升了检索性能;王利卿等[11]为了克服图像尺度变化问题,提出了多尺度神经网络提取特征,并通过压缩模型降低计算复杂度,在商品数据集上精度良好;Li等[12]提出了对多个卷积层特征进行融合的方法,检索精度有所提升;Jimenez 等[13]将CAM(Class Activation Map)中学习的类别信息融合进图像特征中,通过提取每个类别中判别性语义区域对特征加权操作。
但此前的研究忽略了目标位置信息,对此,Wei等[14]提出了选择性卷积描述聚合SCDA(Selective Convolutional Descriptor Aggregation),通過获取检索目标物体位置区域,丢弃无关的背景区域,最终根据筛选后的特征区域经过池化形成图像特征向量。董荣胜等[15]受此启发对Crow进行了改进,先提取出区域位置,再对该区域卷积特征进行空间和通道加权,提升了特征的判别性。
为提升特征局部信息描述能力,本文提出一种基于多区域中心加权的卷积特征提取方法,通过对卷积激活响应,从通道维度的卷积特征图进行筛选,去除差异较小的特征图,提取具有代表性的语义区域卷积特征图,丢弃不相关的噪声图像区域,最终根据筛选后的特征进行加权生成图像特征向量。在不同的建筑物数据集上进行实验,结果表明提出的算法取得了较优的检索精度。
1 提取方法
1.1 符号定义
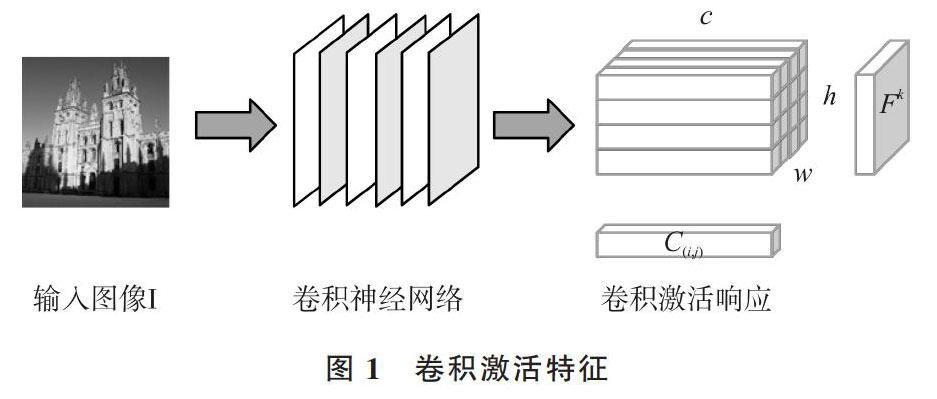
如图1所示,将尺寸大小为[H×W]的图像I作为整个网络的输入数据,输入图像经过CNN网络处理后,抽取出图像的卷积层激活响应(Activations),其为 [h×w×c] 大小的三维卷积特征张量T。从通道维度划分,张量T视为包含c个二维卷积特征图(Feature Map),将卷积特征图记为[Fk=Tk?,k=1,?,c]。从空间维度划分,张量T视为具有 [h×w] 个维度为c的卷积通道向量,记为[C(i,j)=T(i,j)?,][i∈1,?,h,j∈1,?,w],其中i,j对应卷积激活响应中的位置坐标。
图1 卷积激活特征
1.2 图像特征提取流程
卷积特征图筛选阶段,先将数据库中图像传入卷积神经网络进行处理,抽取所有图像的卷积激活响应。然后空间维度求和获取c维向量,对所有求和后的向量获取标准差数据,选取偏差较大的卷积核作为选取后的区域特征提取器,最后对选择后的区域提取器等信息进行保存,见图2。
图2 特征提取流程
在特征加权阶段,先通过提取器提取语义区域特征图中的响应值进行排序,然后通过响应值计算语义区域中心位置,最后根据位置生成权重对卷积激活响应进行加权操作,获取图像的全局特征描述。
1.3 区域特征图选择策略
卷积层不同的卷积核可被特定的模式(Pattern)激活,多个卷积核非线性组合可以提取特定的图像语义区域信息。通过对卷积特征图进行筛选,可以提取出包含语义区域的响应值。筛选具有区别性语义区域的特征图,去除部分无关的卷积特征图,减少信息冗余和噪声。卷积核在不同目标上的响应存在显著差异,因此特征图之间的差异可以衡量响应值中目标的信息。以此为基础,采用计算c个通道二维特征图之间的数值标准差[s∈Rc],保留偏离值较大的通道特征图,计算公式如下:
其中,[s,N,xk] 分别代表所求的标准差向量、训练数据集中图像的数量、通道维度c对其它维度进行求和得到的c维特征向量。
随后对获取的标准差向量进行排序,获取偏离程度大的通道位置。该通道对应的卷积核在不同图像上的响应值有显著差异,提供了目标的相关判别性信息,将此卷积核称之为区域特征提取器。为查看选取的区域特征提取器的有效性,对相同位置卷积核产生的卷积特征进行可视化操作。
可视化后的特征图像素点越白表示响应值越大,越黑则响应值越小。从图3可看出,具有检索目标的位置颜色偏白,而没有的颜色则较黑。经过筛选后的卷积特征图能有效抑制背景噪声并突出该特征图中包含的检索目标。随后对提取器的选取数量进行实验,分析对比选取方式与数量对检索精度的影响。
图3 卷积特征图可视化
1.4 多区域中心加权聚合方法
SPoC算法假定高斯中心处于图像几何中心,没有考虑目标空间位置的关联性。因此本文提出了多区域中心的高斯权重生成方法。区域特征图选择策略能去除不相关的噪声干扰,突出了判别性目标位置信息和其近邻关系。高斯权重记为[wk(i,j)∈Rh×w]:
其中,[xk,σ,(i0,j0)] 分别表示选取的卷积特征图、高斯函数的标准方差函数和几何中心坐标。将标准方差设定为卷积特征图几何中心与边界距离的一半,由特征图响应值排序,选取响应值较大的确定中心点坐标,选取的百分比由参数 [α] 表示。提取特征图,选取排序后较大的响应值作为基准获取高斯函数的几何中心。获取区域中心后对卷积激活响应进行加权操作,获得图像的加权特征描述[f]:
最后在求得多个区域中心特征权重加权操作后,根据Crow方法对通道维度进行加权,最后将加权特征拼接成图像全局特征描述。为了方便后续特征间相似度计算,对图像全局特征进行了归一化和PCA特征降维操作。
2 实验
2.1 实验设计
为评估算法性能,本实验采用常用的建筑图像检索数据集:牛津Oxford5K、巴黎Paris6K以及增加了干扰数据的Oxford105k和Paris106k[17]。Oxford5k和Paris6k为研究者从网站上搜集的Oxford和Paris两地的著名城市地标建筑物图片。其中Oxford和Paris建筑数据集包含五千多张图像样本,所有的图像样本均对应一个类别标签,共11种不同的地标标签;每类地标图像包含5个相关的检索样本,总共包含55个检索图像样本,其余的图像为不包含目标的干扰样本。
实验采用keras搭建 VGG Net 16层网络模型[16],去除卷积层后的全连接层,提取最后一层卷积层的输出作为卷积激活响应。首先保留输入图像的原始尺寸,随后进行预处理操作。采用深度卷积网络模型提取实验图像样本的卷积激活响应,按照特征图筛选算法和多区域中心加权算法提取图像的全局特征描述。
实验评估步骤:先提取待查询图像全局特征描述,并计算与图像全局特征之间的距离,然后采用余弦相似度计算方法对得到的图像之间的相似度依据从大到小顺序进行排序,最后选取排名靠前的图像作为检索结果。
将平均精确度均值mAP作为图像检索性能评价指标[18]。为进一步提升检索精度,还进行了查询拓展QE(Query Expansion)[19],即對初步查询后得到的结果求平均特征,并使用该特征再进行检索,将其结果作为最后的查询结果。
2.2 实验结果与分析
2.2.1 区域提取器数量对比实验
为评估不同数量的提取器对检索性能产生的影响,进行排序后选择与随机选择方法对比实验,如图4所示。
图4 区域数目对比
图4对比了随机选择和排序选择两种策略,图中实线代表牛津数据集实验结果,虚线为巴黎数据集实验结果,实验结果表明排序选择优于随机选择策略。当选取的区域特征提取器数量较少时,检索精度较低,原因可能是丢失了过多的图像目标位置信息,在加权后产生判别性较弱的特征描述。与之相反,当提取器数量超过50%时,两种策略检索精度无明显差异,说明提取器过多产生了一定的噪声,检索精度也随之下降。实验结果表明特征筛选能够降低噪声干扰,提升特征描述能力,并且取得优于随机方法的精度。随后的实验中将提取器数值设定为通道总数的15%。
2.2.2 CNN算法对比
实验分别对比同等特征维度下的各种图像特征提取方法的性能,如表1所示,加黑的数字为性能表现最优的检索精度。从表1可以看出,采用提取全连接层的检索算法检索性能最低,而采用卷积层特征的算法性能上有一定优势。由于SPoC算法的特征维数较低,所以精度较低。在Paris数据集上,本文提出的算法比次优的 R-MAC 算法 mAP 超出一个百分点,在拓展的干扰数据集上高出两个百分点,而在Oxford数据集上,检索精度优于其它同类卷积特征算法。由于 R-MAC 算法进行了近似最大池化定位(Approximate Max-Pooling Localization,AML)操作,在Paris建筑物数据集上,本文方法的检索精度相差0.3%,但在Oxford数据集上,本文的算法依旧高于次优算法1%。实验证实,通过简单的查询拓展操作后,不同的特征提取算法性能都有所提升。
表1 不同算法检索mAP比较
3 结语
本文提出了一种新颖的图像卷积特征加权方法,区域特征图选择策略和卷积特征加权策略是本算法核心。实验结果表明,提出的图像特征提取算法在相同条件下取得了优于其它同类别CNN算法的检索性能。未来研究工作中将继续对图像特征提取方法进行改进,从增加网络深度、采用成对的样本微调网络参数等方向进行深入研究。
参考文献:
[1] LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2):91-110.
[2] WU J,LI Z,QU W, et al. A new bag-of-words model using multi-cue integration for image retrieval[J]. International Journal of Computational Science & Engineering, 2016, 13(1):80-86.
[3] QI C,SHI C,XU J,et al. Spatial weighted fisher vector for image retrieval[C]. IEEE International Conference on Multimedia & Expo, 2017.
[4] 颜文,金炜, 符冉迪. 结合VLAD特征和稀疏表示的图像检索[J]. 电信科学, 2016, 32(12):80-85.
[5] 周文罡, 周文罡, 李厚强, 等. 图像检索技术研究进展 [J]. 南京信息工程大学学报:自然科学版, 2017, 9(6):613-634.
[6] ZHENG L,YANG Y,TIAN Q. Sift meets cnn: a decade survey of instance retrieval[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 40(5):1224-1244.
[7] BABENKO A, SLESAREV A, CHIGORIN A, et al. Neural codes for image retrieval[C].European conference on computer vision. Springer, Cham, 2014: 584-599.
[8] BABENKO A V,VICTOR L. Aggregating local deep features for image retrieval[C].IEEE International Conference on Computer Vision, 2016.
[9] TOLIAS G,SICRE R,JéGOU HERVé. Particular object retrieval with integral max-pooling of CNN activations[J]. Computer Science, 2015(9):2254-2261.
[10] KALANTIDIS Y,MELLINA C,OSINDERO S. Cross-dimensional weighting for aggregated deep convolutional features[C].European Conference on Computer Vision. Springer, Cham, 2016.
[11] 王利卿, 黄松杰. 基于多尺度卷积神经网络的图像检索算法[J]. 软件导刊, 2016, 15(2):38-40.
[12] LI Y,XU Y,WANG J,et al. MS-RMAC: multiscale regional maximum activation of convolutions for image retrieval[J]. IEEE Signal Processing Letters, 2017, 24(5):609-613.
[13] JIMENEZ A,ALVAREZ J M,GIRO-I-NIETO X. Class-weighted convolutional features for visual instance search[J]. arXiv preprint , 2017(1): 1707-2581.
[14] WEI X S,LUO J H,WU J,et al. Selective convolutional descriptor aggregation for fine-grained image retrieval[J]. IEEE Transactions on Image Processing, 2017, 26(6):2868-2881.
[15] 董荣胜,程德强,李凤英. 用于图像检索的多区域交叉加权聚合深度卷积特征[J]. 计算机辅助设计与图形学学报, 2018(4):2011-2021.
[16] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint,2014(5):1409-1556.
[17] RADENOVI? F, ISCEN A, TOLIAS G, et al. Revisiting Oxford and paris: large-scale image retrieval benchmarking[J]. arXiv preprint ,2018(2):1524-1530.
[18] 于俊清, 吴泽斌, 吴飞,等. 多媒体工程:图像检索研究进展与发展趋势[J]. 中国图象图形学报, 2017, 22(11):1467-1485.
[19] 柯圣财, 李弼程, 陈刚,等. 一种基于视觉词典优化和查询扩展的图像检索方法[J]. 自动化学报, 2018, 44(1):2141-2148.
[20] ARANDJELOVIC R, GRONAT P, TORII A, et al. Netvlad: CNN architecture for weakly supervised place recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017(99):1-2.
(責任编辑:杜能钢)
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
计算机工程(2015年4期)2015-07-05
制造技术与机床(2015年10期)2015-04-09
机电信息(2015年3期)2015-02-27
机械工程师(2015年10期)2015-02-02
噪声与振动控制(2015年4期)2015-01-01
