
基于概率参数的Apriori改进算法
2019-10-18 02:57孙帅刘子龙
软件导刊 2019年9期
关键词:关联规则
孙帅 刘子龙


摘 要:关联规则可在庞大的数据集中找出不同事务之间隐藏的关系,其中Apriori算法是关联规则分析中较为有效的办法。然而,Apriori算法产生候选项集的效率较低且扫描数据过于频繁,造成算法计算需要耗费较长时间。另外,初始定义的最小支持度与最小置信度也不足以过滤无用的关联规则。针对以上问题,利用概率理论与有效的参数设置,在原有Apriori算法基础上,提出一种基于概率事务压缩的关联规则改进算法。数值算例结果表明,新算法可在第二次迭代之后,大幅减少低效候选项集,从而提升经典Apriori算法效率。
关键词:关联规则;Apriori改进算法;概率参数
DOI:10. 11907/rjdk. 191099 开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2019)009-0085-03
Research on Improvement of Apriori Algorithm Based on Probability Parameter
SUN Shuai,LIU Zi-long
(School of Optical and Computer Engineering,University of Shanghai for Science and Technology, Shanghai 200093,China)
Abstract:Association rule mining is to find interesting hidden associations from huge number of initial data. Apriori algorithm is the effective way to find these association. Howerer,the original Apriori has its own drawbacks,such as low efficiency of candidate item sets and scanning data frequency. The minimum support and confidence are not enough to filter useless association rules. To recover the deficiencies,this paper proposed an improved algorithm based on marked transaction compression by probability and parameters. Experiments show that this algorithm has much better capability than the original Apriori algorithm. After the second iteration of the algorithm,the candidate sets are reduced 50%,it shows that the improved algorithm was more efficient than the original one.
Key Words: association rule;improved Apriori algorithm;probability parameters
1 Apriori算法简介
关联规则首先是由 Agrawal等提出的,该算法用来在庞大的初始数据库中发现有趣的隐藏关联[1]。其经典应用是通过对“啤酒”和“尿布”两种商品的关联分析[2],使超市获得了可观的经济收益。
Apriori 算法是关联规则的经典算法,其最终目的是在所有事务集中找出最大频繁项集[3],再通过条件概率找出不同事务之间的关联,通过层层迭代搜索,直到获得满足最小支持度与最小置信度的事务集[4],同时保证该事务集中所含项数最多[5]。该算法核心理论是:“频繁项集的子集仍然是频繁项集,非频繁项集的超集仍是非频繁项集[6]”。算法实现过程包含连接和剪枝两个步骤[7],即首先在K项频繁集的基础上,通过连接形成k+1项候选项集,因为频繁项集的子集仍是频繁项集,对每个k+1项候选项集的子集进行验证,删除不满足条件的候选项集,即剪枝[8]。直到候选项集合中不再存在任何项,便产生了最大频繁项集[9],算法结束。
然而,经典Apriori算法存在着扫描数据库频繁、产生候选项集多、耗时较长等不足[10],针对以上不足,国内外学者提出了一些算法改进方案,例如:约束性关联规则算法[11]、增量式关联规则算法[12]、多层关联规则算法[13]、关联规则ECLAT算法[14]等。為过滤掉经典Apriori算法中无效与关联程度较弱的候选项集,提升算法效率,本文尝试引入相关概率计算与参数约束,通过对候选项集进行压缩实现对Apriori算法的改进。数值算例实验结果表明,改进算法相比经典Apriori算法大幅减少了候选项集,从而降低了算法复杂度。
2 基于概率事务压缩的改进Apriori算法
2.1 经典Apriori算法理论分析
经典Apriori算法会设定某些参数作为初始阈值,例如最小支持度与最小置信度[15],其中最小支持度定义为:衡量支持度的一个阈值,表示项目集统计意义上的最低重要性[16]。最小置信度定义为:衡量某个项集最低的置信程度[17],再将样本数据带入标准算法迭代,从而产生一些因果关联。然而,在某些情况下,仅通过最小支持度与最小置信度还不足以给出最终结果。通过以下例子说明该问题:用Support表示相应规则的支持度,Confidence表示置信度,假设购买一批商品,其中耳机(X)共有6 000件(包括耳机单件与电脑礼包中的耳机),电脑(Y)共有9 000台(包括电脑单件与电脑礼包中的电脑),电脑礼包4 000件,将最小支持度设定为30%,最小置信度设定为60%,通过计算可得出如下关联规则:
通过上述计算可知关联规则(X→Y)的支持度和置信度都大于设定的最小支持度与最小置信度,因此可认为关联规则成立,即在购买耳机的同时也会购买电脑。
通过计算,X→Y关联也满足事先设定的最小支持度与最小置信度的阈值,所以其两者之间也能构成关联规则,这两种截然相反的关联形成了悖论,可见仅满足最小支持度和最小置信度计算阈值,即认为关联规则成立是存在问题的。
通过上述实例,可发现仅通过设定最小支持度与最小置信度阈值,在某些特殊情况下会存在局限,主要由于经典Apriori算法并没有充分考虑反面事件的支持度与置信度。在实际使用中,相关事务的关联需要证明仅是正相关的,不存在负相关的可能,因此算法不但需要验证正相关的关联规则X→Y满足最小支持度与最小置信度的设定条件,同时其支持度与置信度也必须大于X→Y。只有同时满足正反两方面的设定条件,才能认为所获得关联规则是自洽的。
2.2 关联条件概率分析
本文通过结合概率论进行推导,以确定X→Y的支持度和置信度大于X→Y支持度和置信度的判定条件,具体指标概率计算如表1所示。
通过上述推导,本文对经典Apriori算法的改进是通过增强非关联的概率验证对候选事务集进行压缩,上述推导的C(Y→X)>[12]则变成一个固定阈值,具有方法应用的不变性。
实际使用中,首先对满足概率参数的候选项集进行标签计数,例如对于关联规则X→Y,若C(X→Y)>[12与]C(Y→X)>[12] 成立,则分别将X和Y计数为1,而在算法迭代结束后,为避免重复,所有项都需要减1,最后再删除标签个数为0的项,即该项不满足固定概率参数[12]的条件,通过标签计数删减候选项,一方面可以减少不必要的算法检验时间,另一方面也可避免产生无效候选集。
2.3 算法过程
为了增强负相关性,对Apriori算法进行删减,具体实施步骤如下:
(1)首先,读取数据库中所有数据集,确定每一项的支持度,利用设定的最小支持度进行过滤,得到一项频繁集L1。
(2)由于所有非空频繁项集的子集必须是频繁的,因此可以用一项频繁集L1产生两项候选集C2,通过C2计算每条规则的支持度。根据之前的概率理论,删除支持度C(Y→X)≤[1/2]的候选项,并且对支持度超过1/2的项添加标签1,统计所有项的标签数,在算法迭代结束后,所有项都需要减1,删除标有0的项,从而形成了两项频繁集L2′ 。
(3)由L2′ 生成三项候选集C3,再用改进后的算法进行迭代操作,得到三项频繁集L3′。当所有项的标签个数为0时,算法结束。
3 算例实验
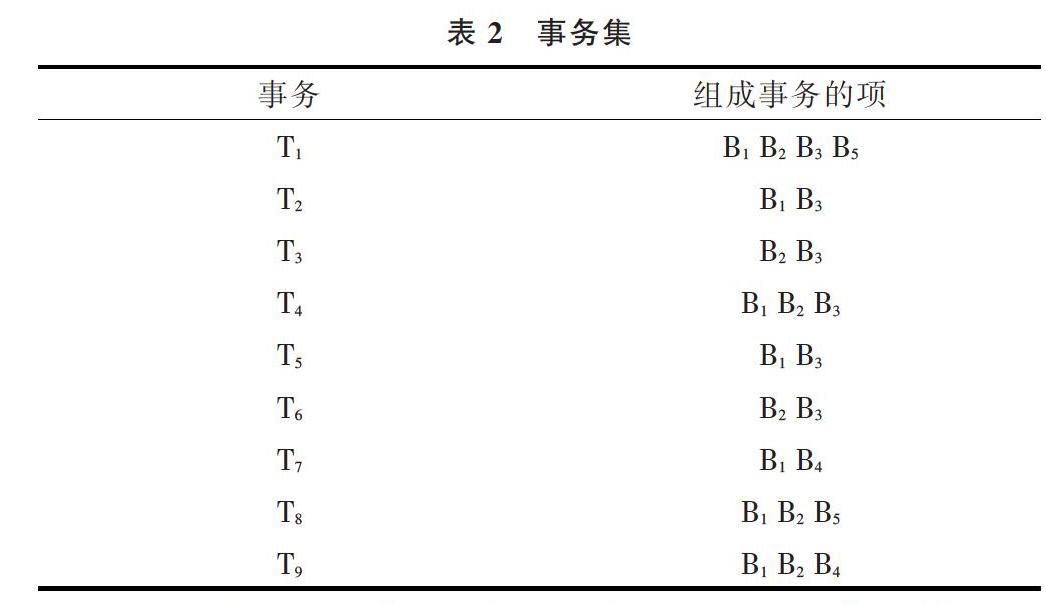
为验证改进算法的有效性,结合具体数据实例对算法有效性进行分析,如表2所示。表中包含T1~T9共9个事务,每个事务由B1、B2、B3、B4、B5中的若干个项组成,并设最小支持度为[29]。
两项候选集是在算法第二次迭代过程中,由一项频繁集L1′ 产生的[20]。表4显示了两项候选集的支持度,并且计算每个关联规则C(X→Y)和C(Y→X)的置信度(两项候选集中,前者对应为X,后者对应为Y),删除置信度C(Y[→X])≤[12]的候选项,而对于超过[12]的候选项通过贴上标签1,得到两项候选集。最后统计B1~B5的标签数,分别为2、2、2、1、2,再减1,删去为0的项(B4),得到两项频繁集如表5所示。
在算法的第三次迭代中,由两项频繁集L2′ 产生三项候选集L3[20]。由于改进算法的概率参数限制,只产生{B1 B2 B3}和{B1 B2 B5}2个候选项集,而经典Apriori算法则会产生4个。另外由于在此次迭代结束后,B1、B2、B3、B5的标签次数减1的结果均为0,因此该算法结束,从而避免了对{B1 B2 B3 B5}的扫描,而{B1 B2 B3}和{B1 B2 B5}两项候选集满足最小支持度,所以最大频繁项集为{B1 B2 B3}和{B1 B2 B5}。
在Matlab实验环境下对上述实例进行验证,由于改进算法的概率参数与标签计数为固定的,在产生三项频繁集过程中,需要处理的候选项集数目相对经典算法减少了一半,同时通过标签计数又避免了一些项再次迭代,使改进算法与初始算法相比,较为明显地降低了计算复杂度。图1对比了两种算法不同迭代次数下的计算复杂度。
4 结语
本文针对传统Apriori算法的问题进行分析,通过概率推导提出一种基于固定概率参数的Apriori改进算法。该算法可以过滤掉关联程度较弱的候选项集,并筛选出负相关关联的候选项,从而减少了算法运算所需时间。可以预测,随着约束条件的增加,产生的无效候选项集会减少,算法效率也将得到提升。同时算例实验结果表明,改进算法在保证关联规则正相关的前提下,能有效降低候选项集个数,从而有利于减少扫描次数,既避免产生无效的关联规则,又提升了算法結果的有效性。
参考文献:
[1] 周英,卓金武,卞月青. 大数据挖掘系统方法与实例分析[M]. 北京:机械工业出版社,2016.
[2] 章艳,刘美玲,张师超,等. Apriori算法的三种优化方法[J]. 计算机工程与应用,2004(36):190-192.
[3] ALMAOLEGI M, ARKOK B. An improved Apriori algorithm for association rules[J]. Eprint Arxiv, 2014,3:21-28.
[4] 刘维晓,陈俊丽,屈世富,等. 一种改进的Apriori 算法[J]. 计算机工程与应用,2011(11):149-151,159.
[5] CHENG X,SU S,XU S,et al. DP-Apriori: a differentially private frequent itemset mining algorithm based on transaction splitting[J]. Computers & Security, 2015(8):74-90.
[6] 饶正婵,范年柏. 关联规则挖掘Apriori算法研究综述[J]. 计算机时代,2012,30(9):11-13.
[7] PRAKASH S, PARVATHI R M S. An enhanced scaling Apriori for association rule mining efficiency[J]. European Journal of Scientific Research, 2010(2):66-68.
[8] ZENG X W. The study of the association rules and data mining methods[J]. Computer and Modernization,2006(6):90-93.
[9] 廖芹,郝志峰,陈志宏. 数据挖掘与数学建模[M]. 北京:国防工业出版社,2016.
[10] 张慧霞. 常用数据挖掘算法的分析对比[J]. 河南科技,2014(19):22-23.
[11] 朱嗣珍. 基于FP-tree的多层关联规则挖掘算法的研究[D]. 西安:西安科技大学,2011.
[12] 范明,孟小峰. 数据挖掘:概念与技术[M]. 北京:机械工业出版社,2011.
[13] 王伟. 关联规则中的Apriori算法的研究与改进[D]. 青岛:中国海洋大学,2012.
[14] 刘敏娴,马强,宁以风. 基于频繁矩阵的Apriori算法改进[J]. 计算机工程与设计,2012,33(11):35-39.
[15] 戴珂,王占俊,张仁平. 关联规则挖掘算法的改进和实现[J]. 后勤工程学院学报,2008(2):78-81.
[16] 姚全珠,李如琼,王美君. 项约束先过滤的最大频繁项集挖掘算法[J]. 计算机工程,2012,38(4):73-75.
[17] ZENG X W. The study of the association rules and data mining methods[J]. Computer and Modernization,2006,9:90-93.
[18] CHEN Y S,DENG X G,JIANG X Y. Apriori algorithm for frequent itemsets mining in the realization[J]. Computer Technology and Development,2006,16(3):58-60.
[19] CHEN A,CHEN N. Data mining technology and application[M]. Beijing: Science Press,2006.
[20] 王振武,徐辉. 數据挖掘算法原理与实现[M]. 北京:清华大学出版社,2014.
(责任编辑:黄 健)
