
平行语料库检索软件SDAU-ParaConc设计与实现
2019-10-18 02:57葛晓帅翟红华
软件导刊 2019年9期
葛晓帅 翟红华

摘 要:当代语言研究离不开语料库,对语料库的检索需要计算机软件支持,但平行语料库检索软件数量极少,且存在不符合中国国情的情况。因此,有必要开发一款符合中国国情、适应大数據检索需求、减少语言研究中重复劳动的平行语料库检索软件。在考察现有4款平行语料库检索软件,对比分析它们各自的优势及不足后,结合中国国情及语言研究实践经验,提出了新的平行语料库检索软件SDAU-ParaConc设计理念。介绍了SDAU-ParaConc的实现方式与特点。与之前的软件对比结果表明,SDAU-ParaConc操作步骤平均简化了60%,检索效率平均提升了9.5%。
关键词:SDAU-ParaConc;平行语料库;检索软件;翻译记忆库
DOI:10. 11907/rjdk. 191027 开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)009-0112-04
The Design and Implementation of SDAU-ParaConc:
A Paralleled Corpus Concordancer
GE Xiao-shuai,ZHAI Hong-hua
(Foreign Language School, Shangdong Agriculture University, Tai'an 271000,China)
Abstract: Linguistic studies nowadays rely heavily on corpora, and computer applications are needed in searching corpora. Paralleled corpus tools are rarely found home and abroad, worse still the tools from abroad often do not fit for Chinese language. Therefore, it is necessary to develop a handy tool that deals with Chinese language and big data. After analyzing the four existing concondancers and taking the Chinese context their own experience into consideration, the authors, as language researchers,propose the design of SDAU-ParaConc and introduce its implementation and features. The results show that on average SDAU-ParaConc simplifies 60% operational steps and the searching rate is 9.5% higher.
Key Words: SDAU-ParConc; paralleled corpora; concordancer; translation memory exchange
0 引言
语料库是当代语言研究与教学[1]的一项重要参考,不论是翻译研究、词典编纂抑或是教材编写都离不开语料库支持[2]。
语料库指在一定原则下收集的批量口头或笔头语篇素材,以电子版本的形式存储在电脑中,用于语言的调查和质性分析[3]。当代语料库指电子语料库,语料库的快速发展主要是依赖电子计算机的快速发展与普及。语料库的规模从第一代电子语料库的百万词次级别发展到现在上亿词次级别[4],如此大规模的文本是不可能依靠人工去读取分析的,因此语料库检索软件在语料库研究中十分重要。
平行语料库由源语文本及平行对应的译语文本构成双语语料库[5]。平行语料库与单语语料库相比有其自身特点:①平行语料库包含两种以上语言;②语料之间按照特定层次平行对齐。这些特点决定了平行语料库的检索无法使用单语语料库软件,需要专用的平行语料库检索软件。
虽然语言研究者数量众多,但研究工具却十分匮乏。平行语料库的研究主要集中在翻译研究[6]、术语抽取和自动对齐等方面 [7]。国内外比较知名的平行语料库检索软件仅有4款,分别是ParaConc、AntPConc、CUC_Paraconc、BFSU ParaConc。近年的语料库应用有逐步向云端迁移的趋势,如最新开发的在线平行语料库检索系统有3款是在线的:OPUS Search Interface[8]、TANGO Concordancer[9]以及WebParaNews[10];另有一款桌面软件Bilingual KRC Concordancer只能找到一篇介绍性文献[11],无法获取该软件。在线版检索系统有速度快、检索方便等优点,但也存在无法满足研究者个性化检索的缺点。如上述WebParaNews只能检索系统设置好的英文—日文新闻语料库,无法自行添加修改语料库。本文主要针对桌面软件进行研究分析,故对在线系统不多着笔墨。上述4款桌面软件各有优点但也存在不足,笔者在使用过程中发现其无法满足中国语言研究者在大数据时代的需求,有必要开发一款更加简洁易用、能够处理大规模语料的检索软件。
1 现有平行语料库检索软件
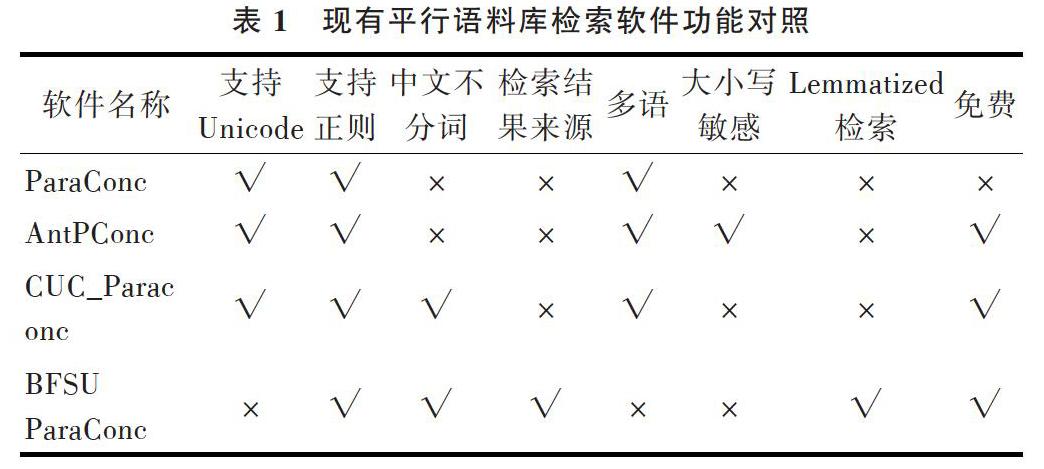
目前已开发出了优秀的平行语料库检索软件,如新西兰奥克兰大学Micheal Barlow[12]研制的ParaConc,Laurence Anthony [13]开发的AntPConc,程南昌[14]研制的CUC_Paraconc以及许家金、梁茂成、贾云龙[15]开发的BFSU ParaConc。下面对现有4款软件进行简要介绍:
ParaConc是最早且最著名的平行语料库检索和建设软件[16],其功能强大,除了检索功能外还有对齐语料功能,这一功能在早期没有自动对齐工具时期非常实用。该软件支持Unicode文件編码,并且有词频统计功能,但软件需要对汉语语料进行提前分词才能检索。该软件是收费软件,单机版价格49美元,对于普通语言研究者有一定经济负担。
AntPConc是最著名的免费语料库检索软件AntConc的同系列软件,作者是日本早稻田大学的Laurence Anthony教授。软件继承了作者一贯简洁明快的风格,界面十分友好,主要有建库和检索两个功能。检索结果界面分为上下两部分,第一部分呈现目标语料库检索结果,第二部分呈现参照语料库检索结果,可以保存检索结果,不提供索引行的来源文件,不支持正则表达式检索。该软件也需要对汉语语料进行提前分词。另外值得注意的是,软件存放的路径不能有汉字,否则无法运行。
CUC_Paraconc由中国传媒大学程南昌博士开发,可进行双语和多语平行语料库检索,支持任意编码的纯文本语料。软件界面语言可自主设定,可对检索结果进行排序。软件设计十分人性化,可自动识别双语保存在单文件中的对齐形式,支持字母语言正则表达式检索,汉语不用分词。每次检索软件都会对平行语料空行进行弹窗提醒,作者本意应该是提醒语料可能没有对齐,但在实际对齐中很多句子可能会没有译文,这时提醒就会给使用者带来不必要的麻烦。软件在处理大规模语料时可能会崩溃,检索结果不提供索引行的来源文件。
BFSU ParaConc由北京外国语大学许家金教授、梁茂成教授和贾云龙共同设计开发。汉语文本无需提前分词,支持正则表达式检索,支持英文词形还原检索。检索结果呈现索引行来源文本,支持包含或不包含检索,但仅支持ANSI编码文本。
将平行语料库检索软件最常用的功能按照各软件支持与否进行整理如表1所示。
从表1可以看出,国外的检索软件并不适合我国国情,比如汉语需要提前分词,AntPConc甚至不能在包含汉语的路径下正常工作,两款软件都不呈现索引行的所在文本。国内两款软件进行了大胆改进,都支持汉语不分词检索,支持正则表达式。这两款软件各有特色,如CUC_Paraconc 支持任意编码的文本文件,BFSU支持不包含检索,支持英文词形还原检索,并且是唯一呈现索引行文件的一款软件。4款软件都是非常优秀的软件,但也有各自的不足。因此,笔者借鉴其优势,根据翻译研究中的实践经验设计并开发了一款新的平行语料库检索软件SDAU-ParaConc。
2 SDAU-ParaConc设计
SDAU-ParaConc以山东农业大学英文缩写(SDAU)加平行语料库检索工具(ParaConc)命名(下载地址http://corpus.bfsu.edu.cn/tools),基于Aardio与 Javascript开发,在Windows操作系统运行。其核心设计理念是简洁易用。软件是免费软件,界面只有3个选项卡,创建语料库选项卡包含检索前语料的导入和语料数据文件的选择功能,检索语料库选项卡包含检索条件指定、结果呈现与保存功能,帮助选项卡有作者信息及帮助文档。
软件摒弃了ParaConc下拉菜单式的检索条件指定方式,在同一界面提供检索条件和结果呈现,方便迅速改变检索条件查询。
界面虽然简洁,但软件没有牺牲核心功能,如英文检索词提供了大小写敏感、正则表达式支持和英文词形还原检索功能,这些研究中最常用到的功能较完备,至于词频统计等功能完全可以结合AntConc,WordSmithTools等单语语料库检索软件实现。
下面从创建语料库和检索语料库两个方面介绍SDAU-ParaConc的特点。
2.1 语料库功能创建
2.1.1 智能识别文件命名
文本文件的平行语料库如果是双文件对齐的,也就是说两种语言分别存储在两个文本文件中,两个文件首先要进行匹配,否则无法进行双语对齐。国外两款软件的设计思路是两种语言的文件放在不同的文件夹中,按照文件排列顺序匹配。国内两款软件的设计思路是将两种文件放在同一个文件夹下,通过在文件名中添加前缀或后缀的方式进行匹配。CUC_Paraconc支持前缀命名,并且支持自定义前缀,如汉语文本命名为ch-abc.txt,其对应的英语文本命名为en-abc.txt。BFSU ParaConc支持特定后缀,中文文件名为*.ZH.txt,对应英文文件名为*.EN.txt。
通过借鉴两款优秀国产软件优点,SDAU-ParaConc支持更加灵活的文件命名方式,可以用前缀也可以用后缀,前缀后缀均可自定义。只要符合命名规则,软件将智能匹配两种语言的文本,方便语言研究者根据自己的需求对文件命名,减少不必要的重复劳动。
2.1.2 支持任意编码文本文件
平行语料库涉及至少两种语言[17],文件的存储形式可以分为两种情况:①两种语言存储在同一个文件内,按照一行A语言一行B语言进行对齐;②两种语言分别存储在两个文件内,两种语言按照行号对齐。文本文件的存储编码标准分为ANSI及Unicode。简单来说ANSI标准的文件节省存储空间,但有可能造成非英语文字的乱码情况,比如新建一个文本文件会默认保存为ANSI编码,输入“联通”两字保存后再打开就会出现乱码。Unicode标准根据不同编码方案又有一些变体,如UTF-8、UTF-16等[18]。其中最通用的是UTF-8编码方案,它保证了字符的准确存储,兼容ANSI标准,又根据不同字符变长,节省了空间。
在翻译实践中经常会遇到一些特殊字符,如希腊字母、数学符号、音标字符等,用ANSI格式存储会有乱码情况,破坏语料的准确性。
综上,SDAU-ParaConc设计为支持所有编码标准,比如英文文本可以用ANSI格式存储,节省空间;汉语文本用UTF-8存储,保证准确性。只要文本文件可以正常显示,软件均可正常识别,这样既提高了软件的灵活性,又兼顾了存储空间的经济性。
2.1.3 支持TMX记忆库文件直接导入
TMX是Translation Memory eXchange的缩写[19],是翻译记忆库交换格式。各大翻译辅助软件如Trados、MemoQ、Déjà Vu、Google Translate、雪人CAT等均支持TMX格式的记忆库。
所谓翻译记忆库,本质上就是一一对齐的双语句子,导入翻译辅助软件后,软件会将新的翻译任务与记忆库中的句子进行匹配,如果发现记忆库中有过同样或类似的句子,就会将翻译结果自动呈现出来,给译者带来极大方便,免去了很多重复劳动。对齐工具对齐后的文本也常用TMX格式保存。具有这种特性的TMX文件其实就是天然的对齐平行语料,对于建设平行语料库非常方便。
本文首创语料库检索软件支持TMX格式,无需将TMX格式转换为纯文本格式,直接将TMX格式文件导入软件即可进行检索分析,这对于翻译工作无疑是一项十分实用的功能。TMX记忆库现有多家平台进行共享和销售,研究者可直接购买TMX记忆库进行平行语料库的建库工作。
通过对比4款语料库创建过程,结果表明SDAU-ParaConc比其它4款软件平均简化了60%的操作步骤。
2.2 语料库检索功能特点
2.2.1 SQLite数据库检索
为了提高检索速度,将平行语料库导入SQLite数据库进行检索,检索效率明显提升。对一个3万句对的平行语料库进行检索对比测试,结果表明SDAU-ParaConc的检索效率平均提升了9.4%,且在进行大量文本文件检索时也不会崩溃。语料库的容量越来越大,适应了大数据时代的平行语料检索需求。
另外,SQLite数据库文件除了SDAU-ParaConc.db外可以以任何文件名保存备用,后续检索无需再次生成语料数据库,只需选择SQLite数据库文件导入即可,节省了语料导入分析时间。
2.2.2 支持中文不分词检索
英文等字母语言是依靠空格识别单词的边界,国外软件设计时都采用了空格作为词的边界,这样分词可以方便进行词频统计等分析[17],国外软件也因此无法对不分词的汉语连续文本进行检索分析[20]。但即使是现在最优秀的中文分词引擎也不能做到百分百的分词准确率[21],并且分词标准不同也会造成结果不同,如把“北京大学”是看成一个词还是“北京”和“大学”两个词?如果上述例子被分成了两个词,那么检索“北京大学”就无法得到正确结果。当然不分词也可能造成将不是词的连续文本识别为词的结果,如检索“中国”会将“发展中国家”也呈现出来。
为解决这一矛盾,设计的软件检索条件既要支持分词的汉语文本也要支持不分词的汉语文本,使用者可根据需要导入任何汉语文本。
2.2.3 自动定位检索结果句所在文件
4款软件仅BFSU ParaConc会在检索结果句后呈现文件名,其它3款只呈现索引行,使用者无法获知索引行出自哪个文件,但这一信息非常重要。在需要查看上下文时,如果文件数量很多,查找该句的出处就会很困难,需要点开文件夹反复查找。
SDAU-ParaConc不仅很清晰地呈现出索引行所在文件名,并且实现了点击文件名(File)即可打开句子所在文件的功能,如图1所示。
在翻译研究及教学过程中,如果单个句子无法给出确定信息需要进行上下文查阅,或是发现翻译错误需要修改原文时,这一功能会带来极大便利。
2.2.4 支持检索结果保存
现有软件对检索结果大多以纯文本格式保存,而该软件不仅提供纯文本格式保存,还提供HTML格式保存。HTML文件可以用任何浏览器打开查看,与在软件中查看效果一样,检索关键词时高亮显示。文件名以检索条件命名,可以避免同一条件的反复检索,也方便进行结果对比。
3 结语
SDAU-ParaConc开发并非重复劳动,而是在吸收前人优秀设计理念、摒弃不合理的繁琐功能,结合我国语言研究者使用实际设计开发的一款方便实用的平行语料库检索软件。该软件更加贴近一线研究者需求,简化重复性劳动,提升研究效率。我国语言研究者众多,但语言研究工具总体相对匮乏,SDAU-ParaConc的发布為语言研究者科研及教学带来了方便。
参考文献:
[1] CORTES V. Corpus tools for writing teachers[J]. The TESOL Encyclopedia of English Language Teaching, 2018(1): 1-6.
[2] BREZINA V. Statistics in corpus linguistics: a practical guide[M]. Cambridge: Cambridge University Press, 2018.
[3] 何安平. 语料库辅助英语教学入门[M]. 北京:外语教学与研究出版社, 2010.
[4] 王克非. 语料库翻译学探索[M]. 上海:上海交通大学出版社,2012.
[5] 王克非. 双语对应语料库: 研制与应用[M]. 北京:外语教学与研究出版社, 2004.
[6] 王若枫. 基于平行语料库的计算机辅助翻译软件在翻译教学中的应用[D].哈尔滨:黑龙江大学,2015.
[7] 司莉,何依.2000年以来我国多语言语料库研究进展[J].现代情报,2016,36(6):165-170.
[8] TIEDEMANN J. Parallel data, tools and interfaces in OPUS[C]. LREC,2012: 2214-2218.
[9] REYNOLDS B L. Action research: applying a bilingual parallel corpus collocational concordancer to Taiwanese medical school EFL academic writing[J]. RELC Journal, 2016, 47(2): 213-227.
[10] CHUJO K, KOBAYASHI Y, MIZUMOTO A, et al. Exploring the effectiveness of combined web-based corpus tools for beginner EFL DDL[J]. Linguistics and Literature Studies, 2016,4(4):262-274.
[11] HMIDA F,MORIN E,DAILLE B, et al. A bilingual KRC concordancer for assisted translation revision based on specialized comparable corpora[C]. Terminology and Knowledge Engineering Conference,2016.
[12] BARLOW M. Paraconc: concordance software for multilingual parallel corpora[C]. Proceedings of the Third International Conference on Language Resources and Evaluation,Workshop on Language Resources in Translation Work and Research,2002: 20-24.
[13] ANTHONY L. Antpconc (Version 1.1.0) [D]. Tokyo: Waseda University,2014.
[14] 程南昌. CUC_Paraconc[D].北京:中国传媒大学,2013.
[15] XU J J,LIANG M C,JIA Y L. BFSU Paraconc 1.2[D]. Beijing: Beijing Foreign Studies University,2012.
[16] MOROPA K. Analysing the English-Xphosa parallel corpus of technical texts with Paraconc: a case study of term formation processes[J]. Southern African Linguistics and Applied Language Studies, 2007,25(2):183-205.
[17] 胡開宝. 语料库翻译学概论[M]. 上海:上海交通大学出版社,2013.
[18] UNICODE CONSORTIUM. The unicode standard, version 2.0[M]. Redwood City: Addison-Wesley Longman Publishing Co. Inc. 1997.
[19] WIKIPEDIA. Translation memory exchange[EB/OL]. https://en.wikipedia.org/wiki/Translation_Memory_eXchange.
[20] 胡开宝,邹颂兵. 莎士比亚戏剧英汉平行语料库的创建与应用[J]. 外语研究,2009(5): 64-71.
[21] 王建新. 计算机语料库的建设与应用[M].北京:清华大学出版社, 2005.
(责任编辑:杜能钢)
