
基于因子分解机的灰色产业服务网页过滤方法
2019-10-18 02:57付强裴佩丁永刚
软件导刊 2019年9期
关键词:特征选择
付强 裴佩 丁永刚
摘 要:互联网灰色产业服务日益泛滥,而传统的网页过滤算法无法准确高效地过滤掉灰色产业服务网页。为解决这一问题,基于TF*IDF提出一种改进的网页特征提取和权重计算方法,利用因子分解机模型对网页进行分类,并以代孕网站为例进行实验和评估。实验结果表明,该方法精确率达到98.89%,召回率达到98.63%,且对海量网页的过滤能够在线性时间复杂度内完成,大大提高了灰色产业服务信息过滤精度和效率。
关键词:灰色产业服务;网页过滤;特征选择;权重计算;因子分解机
DOI:10. 11907/rjdk. 191195 开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)009-0150-04
A Factorization Machine-based Filtering Approach
for Gloomy Industry Service Webpages
FU Qiang1,PEI Pei2,DING Yong-gang3
(1. Wuhan Marine Communication Institute,Wuhan 430072,China;
2. School of Computer, Central China Normal University, Wuhan 430079,China;
3. School of Education,Hubei University,Wuhan 430062,China)
Abstract: In recent years, Internet gray industry has become rampant. Unfortunately, traditional webpage filtering algorithms are not able to filter the webpages of the gray industry efficiently and accurately. To solve this problem, we first propose an improved method of webpage feature selection and weight calculation based on TF*IDF, and then classify webpages using Factorization Machines. Taking surrogacy website as an example, we conduct extensive experiments and evaluations in the real-world scenarios. The experiment results show that this method achieves a precision of 98.89% and a recall of 98.63%, and is able to filter gray industry webpages in linear time, which greatly improve the accuracy and efficiency of filtering.
Key Words:gray?industry service; webpage filtering; feature selection; weight calculation; factorization machines
0 引言
互聯网产业蓬勃发展,一些不符合国家法律法规的互联网灰色产业也夹杂其中,如代孕、论文买卖等。这些灰色产业使用不正当手段非法盈利,不仅违背伦理道德,而且扰乱互联网正常秩序。从海量网页中迅速有效地过滤互联网灰色服务信息,阻止其传播,确保互联网绿色产业有序发展,成为网络内容安全研究的重要课题之一[1-3]。
在网页文本过滤中,文本特征提取算法好坏直接关系到过滤效果优劣,而灰色服务信息文本过滤不同于普通文本过滤,其主要困难在于灰色服务信息文本特征的选择需考虑多类特征词与一般特征词的区别以及在不同类别文档中的重要性,因此本文首先基于TF*IDF提出一种改进的特征选择与权重计算方法,以期获得较好的灰色服务信息文本特征选择与权重计算效果。
文本过滤一般采用近邻法(KNN)[4]、贝叶斯分类(NB)[5]、支持向量机(SVM)[6-7]和神经网络(BP)[8]等文本分类方法,这些方法效果较好,但KNN算法在样本集较大的情况下,系统时间复杂度和空间复杂度都较高;NB算法在属性个数较多或属性之间相关性较大时,分类效率不理想;SVM算法虽然能解决高维问题,但对缺失数据敏感,且对非线性问题没有通用解决方案; BP算法在高维数据和大数据量的情况下,算法开销非常大。针对上述问题,本文基于因子分解机模型提出一种有效的分类算法,该算法在高维数据和数据稀疏情况下仍能在线性时间复杂度内获得好的分类精度。实验表明,将该算法应用于灰色服务信息过滤能取得满意的效果。
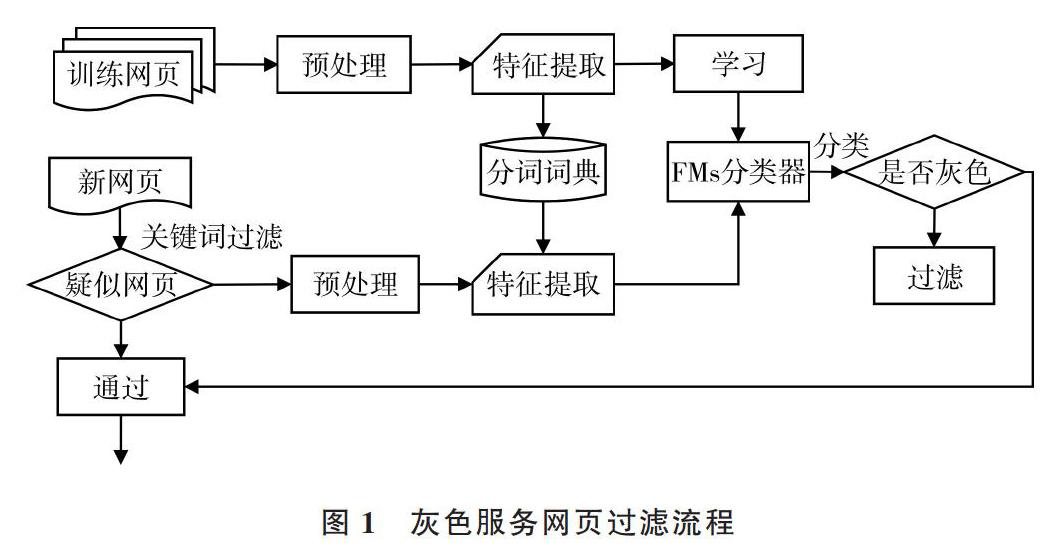
1 灰色产业服务网页过滤流程
灰色产业服务网页过滤流程分为训练和过滤两个阶段,其流程如图1所示。
训练阶段最重要的是建立灰色产业分词词典。首先收集大量灰色产业服务网页,使用分词软件进行分词,统计词频, 得到词频最高的k个词,然后去除停用词、平凡词、稀有词和词频小于3的词,把剩下的词作为关键词;增加一些描述灰色产业的专有名词,以代孕服务为例,增加如“试管婴儿”、”捐卵”、“ 体外授精”和“借腹生子”等词,以及反映产业服务网页特征的重要词,如“联系电话”、 “在线咨询”、“会员“、“报名”、“流程”、“服务”、“客服”、“价格”等词。
在过滤阶段,使用上述得到的灰色产业关键词过滤掉与灰色服务完全无关的网页,剩下的网页为灰色服务网页及相似网页。以代孕服务为例,与之相似的网页可能是介绍有关生育知识的合法医学类网页,或仅是报道代孕产业的相关新闻网页。由于描述灰色服务的词大多是专业词汇,所以可使用训练阶段建立的分词词典进行机械式分词和特征提取,最后使用因子分解机模型分类器进行分类过滤。
2 灰色产业网页特征提取与权重改进算法
2.1 特征提取
网页文本特征通常采用向量空间模型表示[9],其半结构化特点使其即使经过初始化处理后,仍会留下很多高维特征向量。不是所有特征对分类学习都有用,且向量的高维特性还会增加机器学习时间。因此,特征选择用于排除特征空间中那些被认为无关或关联性不大的特性,以降低向量空间维数,简化计算,防止过分拟合。特征选择好坏直接影响文本分类的准确率。
灰色服务网页的特征提取不同于普通网页的特征提取,其主要困难在于灰色服务网页文本特征的选择,除了要提取代表灰色产业服务的高频词外,还要考虑多类特征词与一般特征词的区别及其在不同类别文档中的重要性。比如灰色产业最显著的特点是它的交易特性,因此其网页除了包含关于该灰色服务信息的高频词外,还会包含一些呈现交易特性的重要词。以代孕网页为例,除了出现 “代孕妈妈”、“婴儿”和“胚胎”等高频词外,还会出现一些诸如“联系电话”、“在线咨询”、“会员“、“报名”、“流程”、“服务”、“客服”、“价格”等具有显著交易特性的词,而这些词也可能出现在合法网页中,即这些词为多类特征词。这类特征词在灰色服务网页中出现的频度一般较高,能够代表灰色服务网页的特征。因为某一网页即使出现了“代孕妈妈”、“婴儿”和“胚胎”等高频词,如果没有该类具有显著交易特性的特征词,则可认为这样的网页可能只是相似网页而不是灰色服务网页。因此,需要一种新的特征提取和权重计算方法,既能提取反映灰色服务信息的高频特征词,又能将多类特征詞与一般特征词加以区别,还能体现其在不同文档类别中的重要性。
2.2 权重改进算法
2.2.1 传统TF*IDF 算法及不足
文本特征常用加权关键词矢量的向量空间模型(VSM)表示。VSM将文本文档视为由一组词语[(t1,t2,?,tn)]构成,每一词语都赋以一定的权值。这样,一个文档[di]可以表示成由一组词语矢量组成的向量空间中的一个向量:[di=t1,w1;t2,w2;...;tk,wk;?;tn,wn],其中[tk]表示词语,[wk]表示词语[tk]在文档[di]中的权重。文档[di]中词语[tj]的权重采用[tf-idf]公式计算如下:
其中,词频[tfij]是词语[tj]在文档[di]中出现的次数,逆文档词频[idfij=lnN/n]是词语[tj]在文档集中分布情况的量化,[N]为文档集的总文档数,[n]为出现特征词[t]的文档数。
从公式(1)可以看出,[tf-idf]主要从词频和逆文档词频两方面考虑:如果某个词在一个文档中出现的频率[tf]高,但在其它文档中很少出现,则认为此词具有很好的类别区分能力,适合用来分类;[idf]则表示为,如果包含某个词语的文档数较少,即[n]越小,[idf]越大,说明该词语具有很好的类别区分能力。进一步分析发现, 如果一个文本中的某个词语出现次数很多,即[tf]很大,则该词语在另一个同类文本中出现次数也会很多,反之亦然。因此[tf]可以体现同类文本的特点,但还应考虑词语区分不同类别文档的能力。逆文档词频[idf]认为一个词语出现的频率越小,区别不同类别的能力就越大,但如果其均匀分布在各个类间,这样的词语是不适合用来分类的;另一方面,如果一个词语在某个类的文档中频繁出现,则说明该词语能够很好地代表这个类的文本特征,这样的词语应该赋予较高权重,并选作该类文本的特征词以区别于其它类别文档。显然,[idf]没有考虑词语在不同类别中的区分能力,所以依据[tf-idf]得到的权值进行文本分类通常不能得到满意效果。
2.2.2 改进的权重算法
为克服[idf]公式缺陷,本文从以下两方面调整词语权重:
(1)引入类别文档频数[cdf]。 文献[10]把类别文档频数[cdf]定义为:
该公式表示特征词[t]在类别[Cp]的文档集中的[idf]值,其中[Kp]表示[t]在[Cp]中的类别文档频数。公式(2)不但能反映出多类特征词和一般特征词区别,而且能反映一个多类特征词在不同类别文档中的重要性。改进的词语权重计算公式如下:
其中,[wij]表示特征词[tj]在文档[di]中的权值,[tf(ti)] 表示[ti]在[di]中出现的次数。假设[di]属于类别[Cp(p=1,2,][?,m)],[Kp]表示[ti]在类[Cp]中的文档频数,[N]为文档集中的总文档数,[n]为出现特征项[t]的文档数。
(2)引入信息增益调整权重。文献[11-13]从信息论的角度出发,把信息增益公式引入到文档集的类别间,即把文档集看作一个符合某种规律分布的信息源,依靠训练数据集的类别信息熵和文档类别中词语的条件熵之间信息量的增益关系,确定该词语在文本分类中所能提供的信息量,并把这个信息量反映到词语的权重中。公式如下:
其中,C为文档的类别集合,[p(Cp)]表示类别[Cp]的概率,可基于文档统计进行计算,也可基于词频计算,[(Cp/tj)]表示词语[tj]在类别[Cp]中出现的概率。
当词语[tj]在文档集合的类别中分布不均时,即在某个类别中分布较高,其它类别中分布较少,词语带有较大的类别信息时,应用信息增益公式计算可得到较高的信息增益值,用公式(7)计算所得的权重值就会较高,从而提高词语[tj]的权重;另一方面,如果词语[tj]在文档集合中的数量虽小,但如果其均匀分布在各个类别间,则其带有的类别信息少,对系统的不确定性程度影响小,则由信息增益公式计算得到的信息增益值较小,用公式(7)计算词语[tj]的权重也相对较低。因此,改进的权重公式能很好地反映词语在类别间的分布情况。
3 基于因子分解机的灰色服务网页过滤方法
3.1 因子分解机
因子分解机(Factorization Machines,FMs)是Steffen Rendle[14]提出的一种通用因子分解模型,它通过使用分解交互参数对具有目标值的所有成对变量进行维度为d的嵌套交互建模,用于解决各种分类和预测问题[15-18]。假设将预测问题的数据描述为二元组[(x,y)],其中[x∈?p]是一个特征向量,[y]是预测目标。当d=2时,因子分解机模型定义如下:
其中,[p]是输入特征向量[x]的维度,[<?,?>]是两个特征向量的内积,[β0∈?],[βi∈?P],[θ∈?p×k]是可以通过训练集估计的模型参数,[β0]是一个全局偏置量,[βi]是特征变量[xi]的权重,[βi,j≈<θi,θj>]是成对变量[xixj]的权重。通过变换可以发现,FMs能够在[O(kn)]线性时间内进行有效计算。
3.2 灰色服务网页过滤建模
可将文本文档视为由一组词语[(t1,t2,?,tn)]构成,每一词语都赋以一定的权值[w]。根据因子分解机定义,可将文档的特征向量用其权重进行扩展[19],由此构造因子分解机的输入特征向量如下:
3.3 过滤算法学习
使用下列目标函数训练因子分解机分类器[20]:
4 实验结果与分析
为验证本文过滤方法的准确性与有效性,分别采用文献[10]、文献[11]和本文提出的权重计算公式计算词语权重,然后分别采用KNN、SVM和FMs分类算法对3种权重计算方法的分类效果进行比较。实验所用数据集来源于真实网络环境,训练数据由人工挑选,共挑选2 500个网页,其中1 500个网页为正常网页,1 000个网页为代孕网页。测试数据通过网络随机爬取800个网页。实验结果选择精确率、召回率作为指标评价,计算公式如下:
其中,[P]为精确度,[Tp]为正确分类的灰色网页数量,[Fn]为将灰色网页分类为非灰色网页的数量。[R]为召回率,[Fp]为将非灰色网页错误分类为灰色网页的数量。
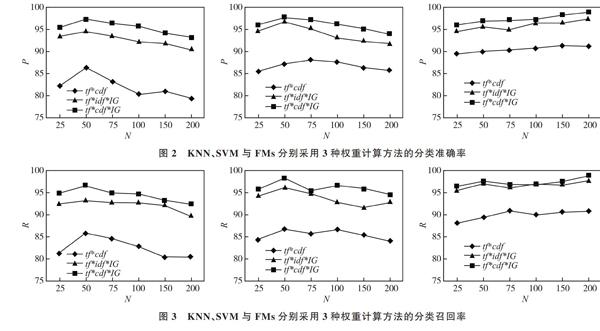
实验参数设置:对于KNN分类算法,[K]=15;对于SVM分类算法,选用多项式核函数;对于FMs,[β0=1],[β1=2],[β2=2]。实验结果分别如图2、图3所示。
從图2和图3可以看出,使用权重计算公式[tf*cdf*IG]计算权重,分类得到的精确率和召回率都比文献[10]和文献[11]高;同时可以看出,3种分类方法中,FMs的分类效果最好。值得注意的是,随着特征向量的增加,KNN分类和SVM分类的精度有所下降,这可能是向量维数增加引入了噪音所致,而FMs的分类精度则随着特征向量的增加而提高,这是因为FMs考虑了所有特征的成对交互作用,使得分类精度更高, 且其时间复杂度为O(kp),即它可以在线性时间复杂度内完成分类。
5 结语
本文针对互联网灰色服务网页特点,在TF*IDF特征选取与权重计算方法基础上,提出了一种基于因子分解机的互联网灰色服务网页过滤方法。该方法克服了传统方法中存在的高维文本分类困难和时间复杂度高的问题。以代孕网站为例,在真实环境中对该方法进行了大规模实验和评估。实验结果表明,该方法能有效表示灰色服务网页特征,且对海量文本分类能够在线性时间复杂度内完成,大大提高了灰色服务信息过滤的精度和速度。实际上,要判别一个网页是否为灰色服务网页,除了根据网页文本进行判别外,还可从其链接结构、可视化特征等进行判别。如何将这些特征建模到向量空间,进一步提高FMs的分类精度,是下一步工作需要解决的问题。
参考文献:
[1] 俞浩亮,王秋森,冯旭鹏,等. 基于特征加权的网络不良内容识别方法[J]. 现代电子技术,2016(3):76-79.
[2] 王正琦,冯晓兵,张驰. 基于两层分类器的恶意网页快速检测系统研究[J]. 网络与信息安全学报,2017(8):48-64.
[3] 丁岩. 基于机器学习的钓鱼网页检测方法研究[D]. 乌鲁木齐:新疆大学,2018.
[4] 黄超. 基于Weka平台的改进KNN中文网页分类研究[D]. 上海:上海师范大学,2018.
[5] LIU P,ZHAO H H,TENG J Y,et al. Parallel naive Bayes algorithm for large-scale chinese text classification based on spark[J]. Journal of Central South University, 2019, 26(1):1-12.
[6] 张华鑫. 基于SVM的文本分类研究[J]. 情报探索,2015(5):133-135.
[7] 李村合,唐磊. 基于欠采样支持向量机不平衡的网页分类系统[J]. 计算机系统应用,2017(4):169-172.
[8] 火善栋. 用BP神经网络实现中文文本分类[J].计算机时代,2015(11):58-61.
[9] 如先姑力·阿布都热西提,亚森·艾则孜,郭文强. 维语网页中n-gram模型结合类不平衡SVM的不良文本过滤方法[J]. 计算机应用研究,2019,36(12):214-218.
[10] 康进峰,王国营,梁春迎,等. 用于色情网页过滤中的KNN算法改进[J]. 计算机安全,2009(9):17-22.
[11] 张玉芳,陈小莉,熊忠阳. 基于信息增益的特征词权重调整算法研究[J]. 计算机工程与应用,2007,43(35):159-161.
[12] 李学明,李海瑞,薛亮,等. 基于信息增益与信息熵的TFIDF算法[J]. 计算机工程,2012,38(8):37-40.
[13] 李海瑞. 基于信息增益和信息熵的特征词权重计算研究[D]. 重庆:重庆大学,2012.
[14] RENDLE S. Factorization machines[C]. IEEE International Conference on Data Mining. 2010: 995-1000.
[15] LIU X,ZHANG Y,LIU C. A nonlinear classifier based on factorization machines model[J]. Communications in Computer & Information Science,2014(483):1-10.
[16] HONG L J,AZIZ S,DOUMITH,et al. ACM international conference on web search and data mining[C]. Co-factorization machines: modeling user interests and predicting individual decisions in Twitter, 2014: 557-566.
[17] PAN Z,CHEN E,LIU Q,et al. Sparse factorization machines for click-through rate prediction[C]. IEEE International Conference on Data Mining, 2017:400-409.
[18] PAN J W,XU J,RUIZ,et al. Field-weighted?factorization?machines for click-through rate prediction?in?display?advertising[C]. Proceedings of the 2018 World Wide Web Conference:?2018:1349-1357.
[19] BABAK LONI,?YUE SHI,?MARTHA LARSON,?et al. ?Cross-domain collaborative filtering with factorization machines[C]. The 36th European Conference on IR Research, 2014:656-661
[20] RENDLE S. Factorization machines with LibFM[J]. ACM Transactions on Intelligent Systems & Technology, 2012, 3(3):1-22.
(責任编辑:杜能钢)
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
电信科学(2017年6期)2017-07-01
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
电测与仪表(2016年23期)2016-04-12
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
电测与仪表(2015年24期)2015-04-09
振动工程学报(2014年4期)2014-03-01
