
基于模板匹配和SVM的车牌字符识别研究
2019-10-19 22:24姜改新
汽车世界·车辆工程技术(上) 2019年4期
姜改新
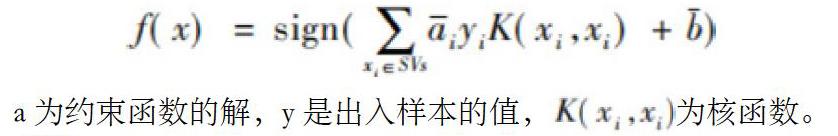


摘 要:对于车牌识别过程中的字符识别问题,提出了基于模板匹配和SVM(支持向量机)的方法,这两种方法各自有自己的特点,识别率都比较高。本文给出了这两种方法的性能比较,可以在具有不同需求的情况下采用不同算法。
关键词:模板匹配;SVM;字符识别;性能对比
1 引言
随着生活水平的提高的汽车行业的发展,家用汽车和其他类型的汽车越来越多,在很多方面造成了监管不便的问题。汽车的车牌号就犹如人的身份证件号一样是汽车唯一的身份识别信息,在交通系统,住宅小区,事业单位和学校等等许多地方为了信息监测和安全防范都需要检验汽车的身份信息,单单靠人工的方式识别显然十分困难,车牌识别系统的出现在一定程度上为汽车信息识别提供了很大的便利,应用市场也十分广泛。车牌识别系统的流程一般是首先进行车牌图像的获取,然后对图像进行预处理,而车牌定位、车牌字符分割和字符识别这几个部是比较核心的步骤,本文对字符识别这一部分提供了模板匹配和支持向量机这两种算法,给出了特点的介绍和性能的比较。
2 支持向量机
支持向量机方法的基本模型是定义在特征空间上的间隔最大线性分类器,学习的目标是在特征空间中找到一个分类超平面,能够将实例分到不同的类。分类特征要求分类内部样本距离足够小,类间样本距离足够大。根据以上原理構造的SVM判别函数为:
a为约束函数的解,y是出入样本的值,为核函数。
步骤:
(1)对测试样本进行预处理,使其便于获得特征;(2)再对字符图像求其特征参数;(3)根据SVM方法进行判别。
SVM着重于最小化训练集的结构误差,识别效率高,识别速度快,测试误差小,而且还具有较强的泛化能力,但是SVM是基于小样本统计理论的基础上的,对于数据量很大的训练样本,SVM的训练时间比较长。
3 模板匹配算法
我国普通汽车车牌的字符共有七位,第一位是各省或者直辖市的汉字简称,然后第二位是A~Z的字母,后五位是数字和字母的混合搭配,由于字符特征差距较大,采用不同的模板分别识别,提高了效率和准确性。在进行模板匹配之前,为了提高抗干扰能力,已经对图像进行了滤波去噪和二值化等操作。模板匹配操作步骤如下:
字符切割后,为了便于字符的识别,消除字符的大小对识别的影响,提高识别的精度,将每个字符的图片进行归一化,归一化包括位置归一化和大小归一化。常用的归一化有两种方法:一种是将字符图像的外边框按比例线性放大或缩小到规定尺寸;另一种是根据水平和垂直两个方向像素的分布进行大小归一化。
相似度计算方法选用最小距离相似度计算方法:
匹配二维离散图像中对应像素点p(x,y)和q(s,t),它们的欧式距离,也就是几何距离为:
图像总像素的欧氏距离和为:
计算出总的欧氏距离D,将结果存放在数组中,然后找到数组中的最小值,对应的图像就是匹配的字符。相对于神经网络算法,该模板匹配不需要特征提取过程,字符图像直接用作特征进行处理,具有最高相似度的即为识别结果,适用于大多数的识别,简单易行,并且可以并行处理。然而,模板只能识别相同的大小,相同类型的字符,不具有旋转不变性,尺寸不变,且计算量较大,速度较慢。对于特别小的图像,因为小的图像像素点比较少,导致相关性被极大的缩小,使得对特征的识别不明显,对结果产生很大的影响。右图为模板匹配法识别结果。
4 结语
字符识别是车牌识别过程中较为核心的一个步骤,该实验总共有图库400张,其中训练集中有300张,测试集中有100张。经过测试,由结果得到支持向量机算法和模板匹配法对汉字字符的识别率高达90%以上,对字母和数字的识别率则是更高,在现实的应用中具有很好的效果。
参考文献:
[1]刘永春.基于SVM的车牌字符识别算法研究[J].四川理工学院学报,2012(08).
[2]任德昊,陈超,李文藻.基于Gabor变换和支持向量机的手写体字符识别算法[J].成都信息工程学院学报,2009(08).
[3]史忠植.人工智能[M].机械工业出版社,2016(01).
