
基于Web的科技信息管理系统开发与管理
2019-10-23 03:20郑宇
微型电脑应用 2019年10期
郑宇
(国网福建省电力有限公司 电力科学研究院, 福州 350007)
0 引言
随着互联网信息技术的快速发展,通过网络获取科技信息以其快速便捷的优势成为信息获取的重要途径之一,对科技信息管理系统的开发与实现成为研究的热点,能够实现科技信息的自动跟踪管理,通过对互联网科技信息的跟踪与获取,并据此完成分析与处理,便于其掌握科技信息的焦点最新动向,完成网络信息简报的自动生成,满足用户的信息获取需求。
1 系统设计
1.1 总体架构设计
系统主要由信息管理、信息采集、数据库等服务器构成,相互间的通信均通过互联网实现,系统主要面向两类用户:普通用户和系统管理员(按照操作权限可细分为操作员和管理员),普通用户只有查看和下载相应文档的权限,管理员登录信息管理服务器可对采集任务进行创建,并将相关配置数据存入数据库,信息采集服务器负责读取采集任务相关配置数据后对信息进行采集和分析,再将分析结果存储至数据库中;信息管理服务器读取采集任务结果后完成相关统计和展示,系统总体拓扑结构如图1所示[1]。
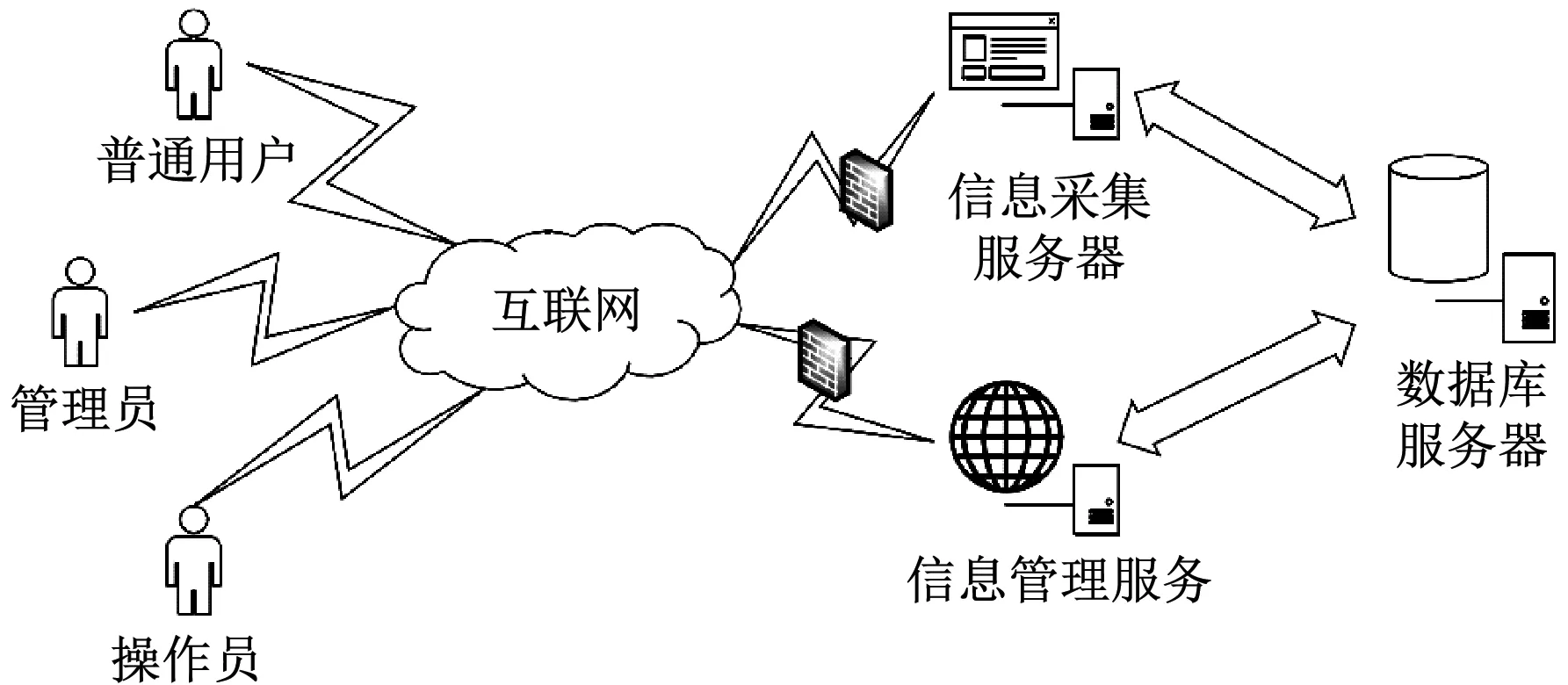
图1 总体拓扑结构图
1.2 功能模块设计
系统功能主要划分为信息采集、信息处理、信息分析、信息服务四个子系统,具体如图2所示。
(1) 信息采集子系统
系统抓取收集指定范围的网站内容(定向采集),支持动态内容分页抓取(JSP、ASP、PHP、Word、PDF等),抓取信息后单独保存为文件方式,或存储于数据库的字段中,采集过程中可采集部分栏目、版块内容也可整站采集。在主流的搜索引擎中通过关键词自动进行数据搜索,根据实际需要对采集的数量、状态及开始/结束采集数据进行设置,具备添加、修改、删除、查找站点资源数据等管理操作;对要采集的主题进行自动识别后据此完成采集任务的跟踪,可从多角度对该

图2 系统功能划分
主题进行后续跟踪[2]。
(2) 信息处理子系统
该子系统的功能在于:对不同网站站点(包括报纸类、行业用户信息类)进行开发时可设置优先级,信息分类和管理可通过专题的设置完成(支持多级分类),根据需要对数据进行管理和维护(包括整理、编辑、删除、新增等);按照媒体来源、版面、时间等分类整理目标媒体所收集到的信息,分类统计后生成平面媒体信息目录;采集到的具体信息内容以平面媒体报告集萃的形式展现,可按天、月自动生成目录或集萃;系统同时支持手动录入后生成简报的功能,己生成的信息简报可进行编辑;为简化采集配置过程,对可配置的采集模板(包括平面媒体目录和报告集萃)进行开发,据此实现地址中指定内容的获取;对于需要采集的站点数据可进行导入导出操作。
(3) 信息分析子系统
该子系统的功能在于:分析采集到的信息,系统自动识别出主题后进行多角度信息跟踪具体通过聚类、热词(包括热点技术、话题、事件、词汇等)等分析方法,提取所需内容或预判其发展趋势;在此基础上对所采集内容按照采集时间、站点分布等进行统计,以图表等形式展示给用户。
(4) 信息服务子系统
该子系统的功能在于:管理系统的账户及权限,设置具体的信息采集热词;进行专题(用户设定)采集监测及信息详情显示;收藏关注信息以便用户后续使用。
1.3 整体业务功能流程
整体业务功能的运作流程如图3所示。

图3 信息分析过程
分别对专题采集和网站采集进行更加深入的配置说明(根据专题、词频出结果),包括网站(针对指定的科技网站)、专题(针对网站具体的栏目板块,需提前设置)、和全网(针对主流的搜索引擎,如百度、搜狗等搜索引擎)三种采集方式,需指定采集的数据类型,全网采集时需指定具体关键词[3]。
系统的使用效果取决于信息采集的效率,为提高系统信息采集的效率,本系统采用多线程方式完成总体信息采集框架的设计,不同操作由各线程执行(可并发执行),提高服务器对系统资源的操作效率,系统采集时支持六类线程及多个队列数据结构,同一队列只能由一个线程访问通过各队列由多个线程加锁的方式实现,系统采集框架总体结构如图4所示。
2 数据库设计
以具体的数据库支撑环境为依据,根据系统的实际需求(包括业务、功能、用户等需求),实现最优数据库模式的构建,从而实现对数据的有效存储和管理工作,考虑到系统涉及的数据表较多,均衡负载的实现需采用多表分离方式,因此选用了安全高效、易操作的MySQL数据库解决数据存储及检索问题,以便后续对信息进行分析统计及管理。数据库字段的建立与完善可使查询数据的准确性和全面性得以有效提升。

图4 采集框架结构图
2.1 逻辑结构设计
采集任务信息表占据核心地位,数据库逻辑结构如图5所示。
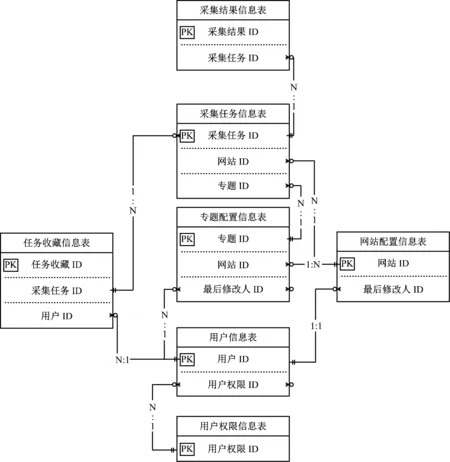
图5 数据库实体一关系图
对所涉及的比较关键的数据库表进行关联设计,并依据系统功能结构设计说明了数据库表间的关系,展示了各数据库表的关键字段及表间的主外键关系。
2.2 数据表设计
本文完成了数据库中各表的内部结构设计,对字段名称、数据类型等要素进行了定义,由于涉及到的数据表较多,只对较为重要的表进行阐述,其中用户权限信息表如表1所示,采集任务信息表如表2所示,网站配置信息表如表3所示,任务收藏信息表如表4所示,采集结果信息表如表5所示,用户信息表如表6所示[4]。
3 系统主要功能的实现
3.1 用户管理功能的实现
系统主要面向两类用户:普通用户和系统管理员(按照操作权限可细分为操作员和管理员),普通用户只有查看和下载相应文档的权限;系统管理员权限最高,可对各模块内容进行管理(包括增、删、改、查等操作),完成采集时间权限的设置。操作员对用户管理模块没有操作权限,可对自己在其他模块中建立的内容进行增、删、改查等操作。根据系统需求在功能实现过程中,需先确定系统中各模块的功能,对这些功能点完成排序标号操作,并组合成对应的三种不同用户类型后存储于数据库的user right表中,降低功能点的耦合度,在此基础上将指定的用户类型同新建用户进行关联匹配,实现了权限的可配置化管理,同时提高了系统的扩展性。

表1 用户权限信息表
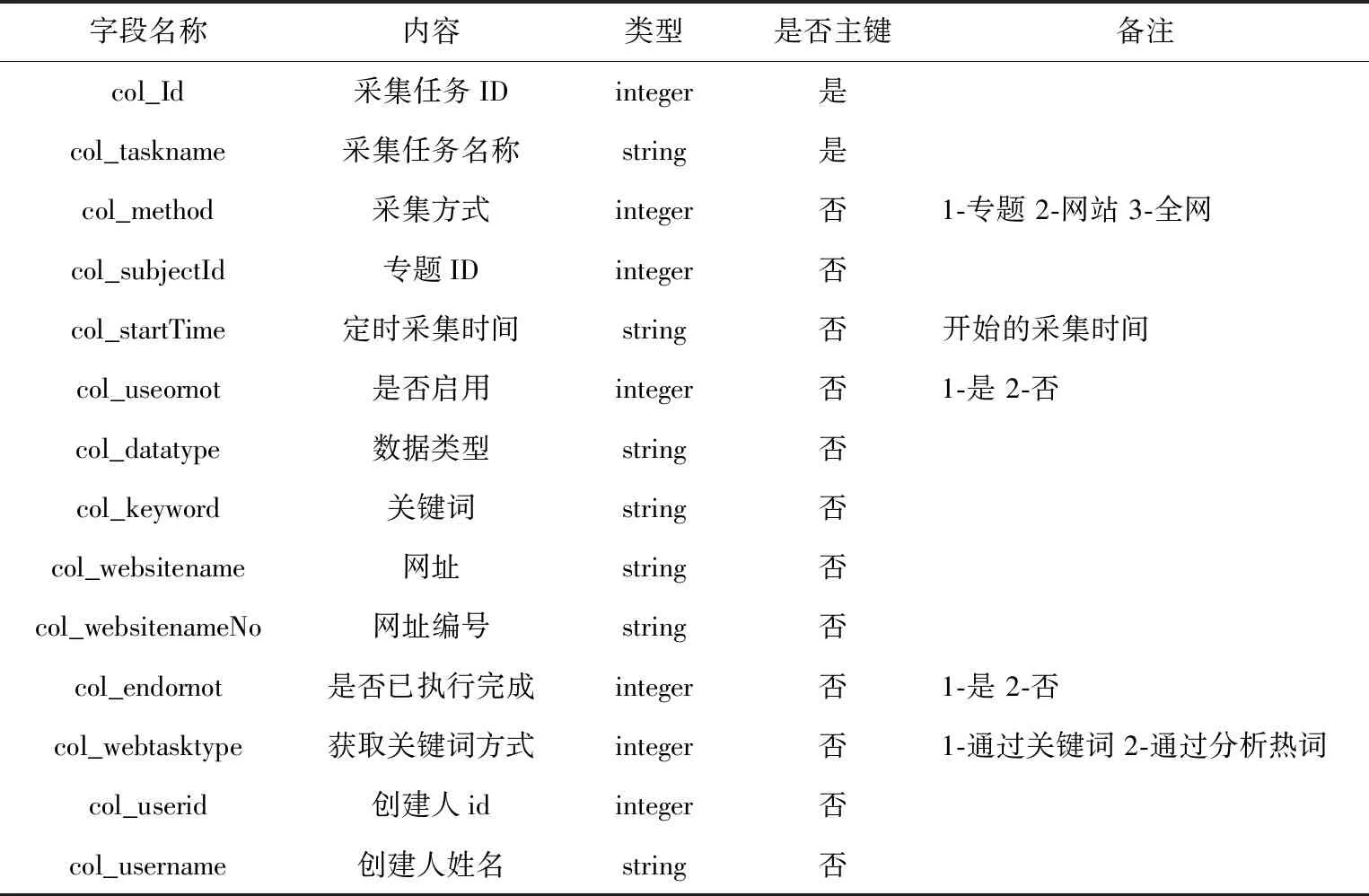
表2 采集任务信息表

表3 网站配置信息表

表4 任务收藏信息表
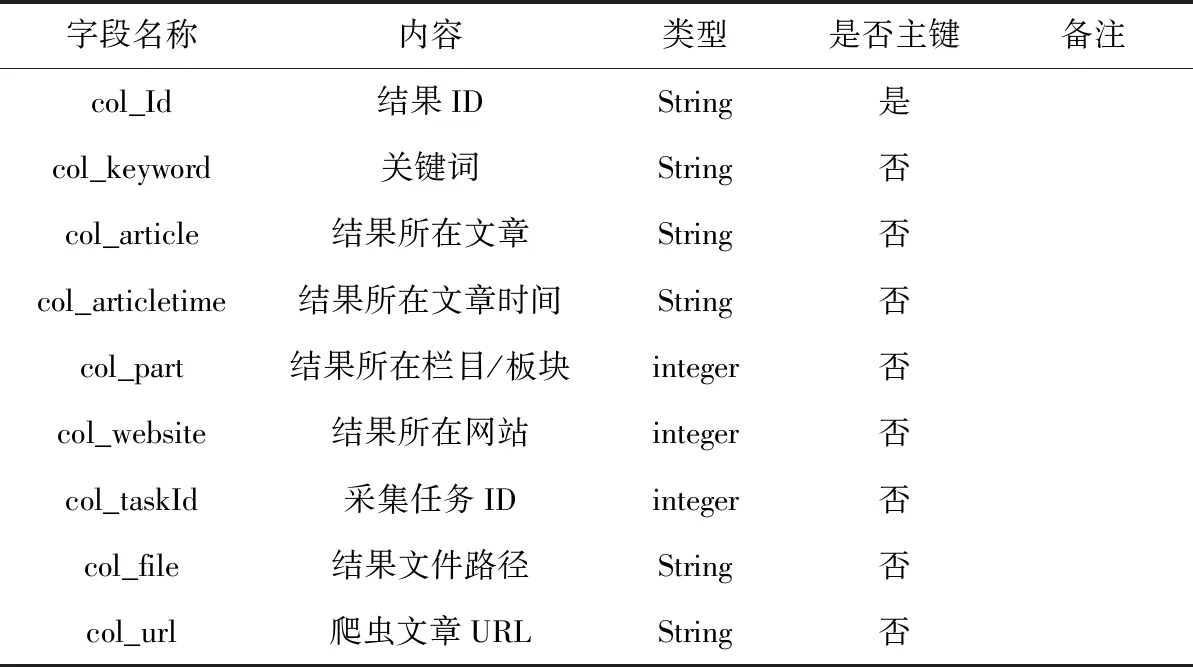
表5 采集结果信息表
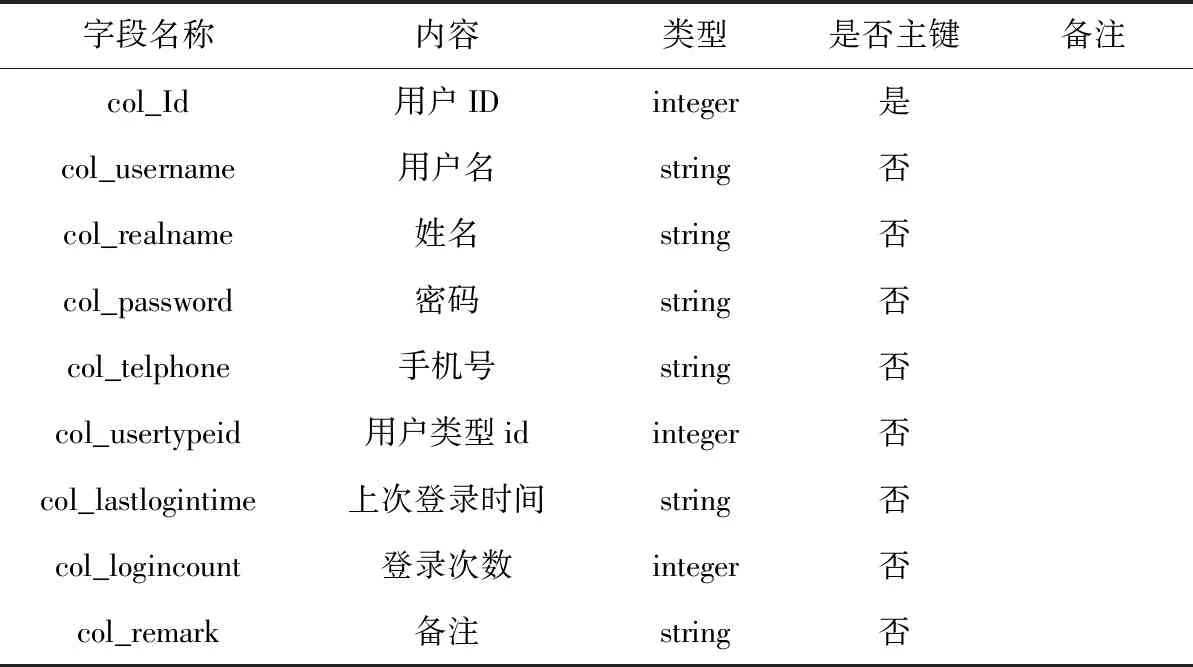
表6 用户信息表
3.2 采集与分析功能的实现
(1) 采集网站的解析配置
对所需采集的各网站进行分析,在此基础上完成信息的采集规则和处理流程的定义,对各科技网站在RootDir/spiders/目录下,完成相应.pY格式配置文件的自定义,然后对相应网站的处理代码进行编写,采集网站各板块URL配置的核心代码如下[5]。
1. def parse(self, response):
2. '从给定的开始url爬取网页,并根据取得信息确定爬取指定模块'
3. global n_url, keywords, taskId, webType, last_keyword, now_keyword
4. switch_urls={}
5. switch_urls["1"]="http://www.bjtest.org.cn/News/List.aspx?cid=01"
6. ……
请求网页下载功能实现的核心代码如下。
1. def parse_content(self, response):
2. '获取网页内容,并调用相应Pipeline'
3. global n_url, keywords, taskId, webType, last_keyword, now_keyword
4. item=ItemLoader(item=BJTESTItem(), response=response)
5. item.add_value('url', str(response, url))
6. item.add_xpath('title_time','//td[@class="GCItemTitle"]')
7. item.add_xpath('text', '//table/tr/td/div')
8. item.add_xpath('hit_time','//table/tr[5]/td/span/text()')
9. ……
(2) 采集任务读取
读取时需先连接数据库,然后编写SQL语句,部分代码如下:
1. def main():
2. ……
3. conn=MySQLdb.connect(host=setting.HOST, user=setting.USER, passwd=setting.PASSWD, db=setting.DB, charset='utf8')
4. cur=conn.cursor()
5. cur.execute("SELECT col_id, col_method, col_keyword, col_websitenameNo, col_useornot, col_webtasktype FROM tbl_task where col_useornot=1")
6. data=cur.fetchall()
7. ……
(3) 采集信息
解析读取采集任务中的采集方式、关键字、时间间隔、网站模块ID等,并据此开启采集线程执行采集任务,核心代码如下:
class Mythread(threading.Thread):
def_init_(self, name, Id, d, threadingSum):
super(Mythread, self)._init_()
self.name=name
self.Id=Id
self.d=d
self.threadingSum=threadingSum
def run(self):
with self.threadingSum:
conn=MySQLdb.connect(host=setting.HOST, user=setting.USER, passwd=setting.PASSWD, db=setting.DB, charset='utf8') #连接数据库
cur=conn.cursor()
……
cmd="python"+setting.Hot_words+"muti.py"+str(self.d[0]).strip()
a=subprocess.Popen(cmd, shell=True)
a.wait()
end_info="TaskId:"+str(self.d[0])+"end……"
time.sleep(s)
在提取成功采集到的结果中的主要内容时,以处理html网页为例,先根据文章位置完成正则表达式的编写,将结构化标签过滤掉后,对文章的主要文本信息进行提取。在RootDir/spiders/pipelines.py文件中编写代码如下:
1. class SDTJPTPipeline(object):
2. def process_item(self, item, spider, t_url, n_url, keywords, taskId, webType):
3. #处理网页正文
4. pattern2=re.compile(r'', re.S)
6. pattern4=re.compile(r'', re.S)
7. text=re.sub(pattern2, "", item['text'][0])
8. text=re.sub(pattern1, "", text)
9. text=item['title'][0].strip()+r' '+text
10. path=settings.SDTJPT_path+"/"+id
11. if os.path.exists(path):
12. pass
13. else:
14. os.makedirs(path)
(4) 信息分析
在spider/HotWords中将文本中的无用符号过滤掉后,先完成系统的通用词库的构建,具体通过Dir/spider/words.txt文件的创建实现,然后通过Python中jieba.analyse.set_ words方法的调用实现文本中的通用词的去除,然后再使用TextRank算法提取文本中的关键词,文章标题已存放在数据库中(信息采集阶段),文章正文已存放在磁盘上(信息处理阶段),对相关的文章信息(包括标题和正文)进行依次读取,并运用TextRank算法对其进行关键词分析,直到分析完所有同采集任务相关的文章后,提取五个关键词(热度最高)作为关键词[6]。
4 系统测试
为检测本文所设计的基于Web的科技信息管理系统的实用性和稳定性,采用黑盒测试法对信息采集、信息处理、信息分析、信息服务子系统的主要功能进行测试,测试结果表明系统管理员可实现对系统的有效管理,可根据实际用户需求对信息采集的主题、时间间隔、目标站点进行设置,可从多角度对指定主题进行后续跟踪,并且系统能够有效实现信息采集、信息读取、信息分析等功能,最终以平面媒体报告集萃的方式展现给用户,系统具备良好的稳定性和可拓展性,具备较高的实用价值,为科技信息管理的系统化提供参考。
5 总结
为有效满足科技信息管理的用户需求,本文主要研究了科技信息管理系统的开发路径,结合HTTP协议及WEB开发技术,完成了系统总体架构的设计,并对系统的总体功能进行划分和详细的阐述,在系统整体拓扑结构的基础上,采用MYSQL数据库完成了系统的信息采集、分析及管理过程的设计,使用Python、Javascript、HTML程序设计语言实现主要模块的功能,设计了系统高性能的采集框架。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
现代仪器与医疗(2022年3期)2022-08-12
当代陕西(2021年21期)2022-01-19
湘潮(上半月)(2021年4期)2021-07-20
汽车维修与保养(2019年7期)2020-01-06
智富时代(2018年6期)2018-08-06
智富时代(2018年6期)2018-08-06
电子技术与软件工程(2018年10期)2018-07-16
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
