
基于Hadoop平台的数据挖掘算法的研究
2019-11-03 14:07王红勤潘正军袁丽娜
电脑知识与技术 2019年23期
关键词:大数据
王红勤 潘正军 袁丽娜
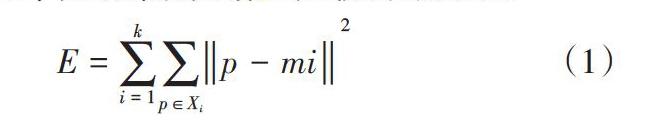
摘要:在深入分析传统数据挖掘方案已经不能满足大数据的挖掘任务的基础上,为了提高大数据环境下的数据挖掘速度,对分布式计算构架 Hadoop 进行分析与研究。文中搭建了Hadoop云计算平台的数据挖掘系统,对数据挖掘算法中聚类算法K-Means进行了设计,在Hadoop平台上实现了K-Means算法的优化,使用Hadoop分布式系统进行数据挖掘任务具有良好的效率,分析结果表明了其具有较大的潜力。
关键词:数据挖掘算法;大数据;Hadoop平台
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2019)23-0009-03
开放科学(资源服务)标识码(OSID):
随着移动互联网的发展,每日所产生地数据量呈现指数级增长,对于海量的非结构的数据来说,传统的数据挖掘技术已经无能为力。如何从这些数据中获取有用的信息,便成了关键问题。开源云计算平台Hadoop的出现,适应了这种海量数据挖掘的需求。
根据大数据环境的特点,为进一步提升数据挖掘的效率,研究相应的数据挖掘算法变得十分的迫切。本文选择将数据挖掘的算法运行在Hadoop分布式[1]云计算平台上,对聚类算法K-Means进行研究,并且在该平台上实现了K-Means算法[2],由于较合适的初始K值难以确定,在Hadoop平台上对该算法进行改进,改进后的K-Means算法,计算速度快,可以高效地处理海量数据[3]。
1 相关技术介绍
1.1 Hadoop简介
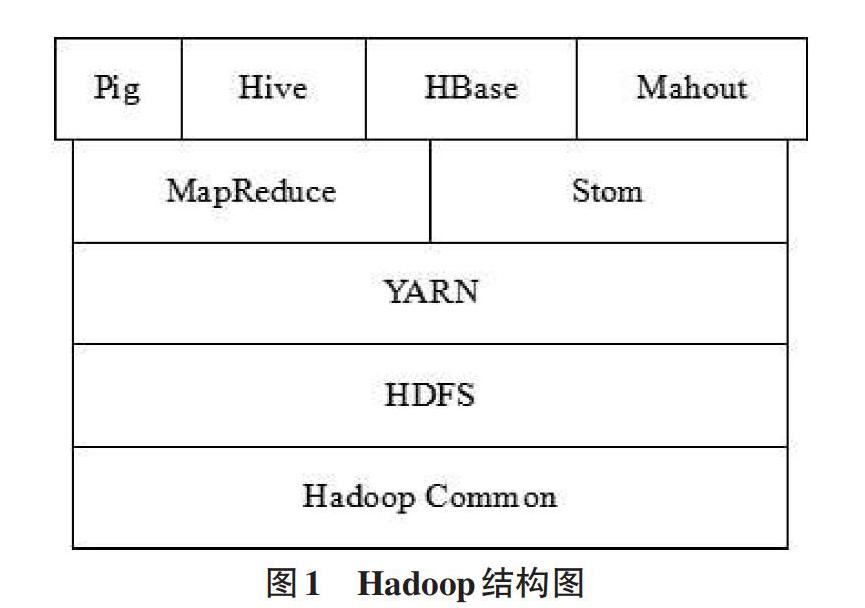
Hadoop是一款稳定的、可扩展的、可用于分布式计算的开源软件。它是一个允许使用简单编程模型实现跨越计算机集群进行分布式大型数据集处理的框架。Hadoop结构如图1所示,Hadoop核心模块主要由HDFS、MapReduce两大模块组成,其中HDFS实现多台机器上的数据存储,MapReduce实现多台机器上数据的计算[4]。
Hadoop 2时代中,HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)与资源管理器YARN(Yet Another Resource Negotiator)结合,使得HDFS上存储的内容可以被更多的框架使用,提高资源利用率,YARN也为MapReduce大型数据集并行处理技术提供了便利。
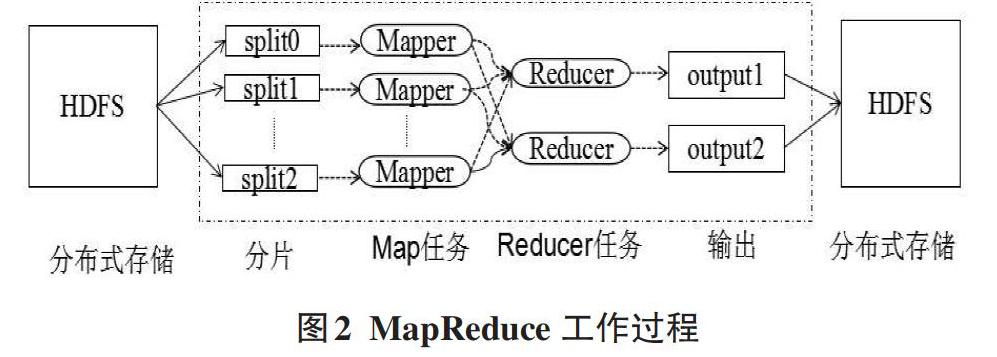
MapReduce是一种分布式计算框架,它用于并行地处理大规模的数据集,它利用Map和Reduce函数来完成复杂的并行计算。MapReduce在处理数据时,首先从HDFS中取出数据块,进行分片,每个分片对应一个Mapper任务,Mapper计算的结果通过Reducer进行汇总,得出最终的结果进行输出。Hadoop的MapReduce工作过程如图2所示。
1.2 数据挖掘
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取有用的信息。通常数据挖掘需要有数据清理、数据变换、数据挖掘实施过程、模式评估和知识表示等8个步骤。数据挖掘的过程需要反复执行,从而达到提取有用数据的目的。
数据挖掘根据数据的类型和数据的特点,选择相应的挖掘算法。常用的数据挖掘算法有K-Means,C4.5,SVM,Apriori, PageRank等等。
2 基于Hadoop平台的K-Means挖掘算法
2.1 Hadoop数据挖掘平台的搭建
数据挖掘接合Hadoop平台,采用并行化计算的思维,构建Hadoop集群的数据挖掘平台,该平台集成了数据的存储、分析与处理过程。基于的Hadoop 集群的数据挖掘平台如图3所示。
该平台引入的HDFS分布式存储模式,主要对海量数据进行挖掘。数据挖掘初期,对数据进行查询、分析,接下来对数据进行预处理,任务分配,在Hadoop大数据处理层,采用MapReduce、HDFS,使用相应的数据挖掘算法(算法层主要包括K-Means、SVM等算法),进行数据建模,从海量的数据中,挖掘出有用的数据。经数据挖掘后,再进行数据分析,可以发现重要的数据流,得出一些重要的结论,
2.2 聚类算法K-Means
聚类是将一组数据按照相似性归成若干类别,这样的一组数据对象的集合叫作簇,对每一个这样的簇都要进行描述。它的目的是使得属于同一类别的数据之间的距离尽可能小而不同类别上的个体间的距离尽可能的大。
K-means算法, 也被称为K-平均或K-均值算法,是一种得到最广泛使用的聚类算法。 它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优(平均误差准则函数E),从而使生成的每个聚类(又称簇)内紧凑,类间独立。
K-means聚类算法使用平均误差准则函数来评价其聚类性能,给定数据集X,其中只包含描述属性,不包含类别属性。假设X包含k个聚类子集X1,X2,…XK;各个聚类子集中的样本数量分别为n1,n2,…nk;各个聚类子集的均值代表点(也称聚类中心)分别为m1,m2,…mk。E代表所有对象的平方误差总和,P代表数据对象,mi是数据集Xi的平均值。E值越小,说明聚类的結果质量越高。误差平方和准则函数公式如(1)所示。
[E=i=1kp∈Xip-mi2] (1)
3 改进后K-Means算法的设计与实现
由于原K-Means算法存在一些问题,如K值人工输入、K个中心的初始位置难以确定、孤立点会使类聚结果偏离中心等。我们将对K-Means算法进行优化,基于Hadoop,对其实现并行化优化。
3.1 K-Means算法的设计与实现过程
在Hadoop集群环境中,使用K-Means算法,并行化处理该流程。K-Means算法的并行化处理的过程:将所有的数据,分布到不同的节点上,每个节点只对自己的数据进行计算,每个节点能够读取上一次迭代生成的聚类中心,并计算本节点里的数据应该属于哪一个聚类中心,每一个节点迭代中根据自己的数据,产生新的聚类中心。
K-Means算法的并行处理是一个不断循环迭代的过程,分为三个阶段:Map阶段、Combine阶段和Reduce阶段。
Map阶段:该过程主要读取数据文件,且读取上一次迭代结果中的聚类中心值,编写map()函数处理,并产生新的聚类中心。在map()函数,构造全局变量centerString,centerString用于保存上一次迭代的聚类中心值,读取一个数据,函数就计算一次数据与原聚类中心的距离,将其中的最小值赋值给centerpoint,计算出来的centerpoint是新的聚类中心。
Map阶段的主要部分代码如下:
String str=value.toString();
String[] centerString=str.split("| | | | ");
double[] centerpoint=new double[m];
System.out.println(pointString.length);
if (pointString.length==60) {
for (int i = 0; i < m; i++) {
centerpointt[i]=Double.parseDouble(str[i]);
}
int minCent=-1;
double distance=0.0d;
double minDistance=Double.MAX_VALUE;
System.out.println(minDistance);
Combine阶段:在此阶段,将Map阶段处理后的聚类进行处理 ,求出所有聚类中心的平均值,当数据处理完成后,MapTask对所有的平均值进行一次合并,生成整个簇的平均值,即为整个簇的均值。
Reduce阶段:每个reduce收到某一个簇的信息,包括该簇 的id以及该簇的数据点的均值及对应于该均值的数据点的个数pointNum,经过Reduce后,输出当前的迭代计数、均值及属于该质心的数据点的个数。
Reduce阶段主要部分代码如下:
String strSting;
String[] pointString;
double[] center=new double[m];
for (int i = 0; i < m; i++) {
center[i]=0;
}
int pointNum=0;
for (Text vaule:values) {
line=values.toString();
pointString=line.split("| | | | | |");
for (int i = 0; i < m; i++) {
center[i]=Double.parseDouble(pointString[i]);
pointNum++;
}
for (int i = 0; i < m; i++) {
center[i]/=pointNum;
result=result+point[i];
}
result=result+Key.toString();
context.write(NullWritable.get,new Text(result));
}
}
3.2 实验结果
为了测试改进后的K-Means算法的性能,实验中分别设定10000、100000、1000000、2000000、3000000条记录的数据来进行测试,对每一组实验重复执行30次,计算平均值作为最终的结果。为了实验结果的准确性,实验采用由5台机器构成的集群环境和3台机器构成的集群环境进行测试,测试的结果如表1所示。
实验结果表明,在Hadoop集群环境中,使用优化后的K-Means算法,运行的效率远远高于传统的算法。数据规模越大,性能就越好。
为了验证数据的可伸缩性,实验将选择5组不同数目的节点进行实验,他们分别是1个、3个、5个、7个和9个。观察实验结果,我们会发现,随着节点数目地増加,完成算法的所用时间如图4所示,实验测试结果中,横坐标表示节点数,纵坐标表示完成时间且单位为103s。
从实验的运行结果可以看出,随着Hadop集群中节点数的不断增多,每个任务所需要的时间在逐渐减少。通过实验,说明优化后的算法,能够有效用于大数据的处理。
4 结束语
大数据时代已经到来,为了提高大数据环境下的数据挖掘速度,本文设计了基于 Hadoop平台的数据挖掘环境,研究了K-Means算法原理和执行流程,并使用MapReduce编程思想,对K-Means算法进行了优化,并通过实验证明了,在云计算平台的集群中,使用K-Means算法进行数据挖掘的处理,具有较好的挖掘高效率和良好的扩展性能。
参考文献:
[1] 王宏志,李春静.Hadoop集群程序设计与开发[M].人民邮电出版社,2018:32.
[2] 韩雅雯.kmeans 聚类算法的改进及其在信息检索系统中的应用[D].云南大学,2016.
[3] 黄奇鹏,卢山.海量關系数据去重处理技术研究与优化[J].计算机与数字工程,2018,10.
[4] 鲁焱.大数据共享平台的系统架构与建设思路[J].图书馆理论与实践,2017(04):86-90.
[5] 徐浙君.云计算下的一种数据挖掘算法的研究[J].科技通报,2018(11) :209.
[6] Issa J.Performance characterization and analysis for Hadoop K-Means iteration[J].Journal of Cloud Computing 2016,5 (1):1-15.
【通联编辑:代影】
猜你喜欢
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
