
基于聚类的反恐情报异常数据分析方法研究
2019-11-07 09:28李勇男
现代情报 2019年10期
李勇男

摘 要:[目的/意义]通过异常检测可以在海量涉恐数据中发现异常信息,为反恐预警提供重要情报。[方法/过程]首先利用聚类将基础数据分为不同的簇,识别出其中区别于大部分数据对象的异常人员,然后设计一种专门的相似度综合度量参数用于计算与恐怖分子最相似的人员。[结果/结论]该方法为检测异常人员数据提供了一种可以参考的思路,用于从多种来源数据中快速找出涉恐敏感程度较高的人员,有望提高反恐情报分析的效率,实现精准打击重点涉恐人员和恐怖活动。
关键词:数据挖掘;异常检测;聚类分析;相似度;反恐情报
Abstract:[Purpose/Significance]Outlier detection from mass fundamental data could provide important information about latent terrorists for early warning of counter-terrorism.[Method/Process]Abnormal people that differed from most data objects must be identified by using clustering method to classify mass terror related data with composite properties.Additionally,abnormal people acted as the basic data source to find terror related people.These subjects who were excavated out had the larger degree of similarity with terrorists.[Result/Conclusion]This method provided an idea to detect high sensitivity people from multiple data streams.It could accelerate the speed of handling counter-terrorism intelligence and provide reference for counter-terrorism disposition by means of swiftly finding the terror related people.
Key words:data mining;outlier detection;clustering;degree of similarity;counter terrorism intelligence
国新办于2019年3月18日发布了《新疆的反恐、去极端化斗争与人权保障》白皮书,其中提到90年代以来我国新疆等地至少发生了数千起暴力恐怖袭击案件,对大量无辜群众的生命财产造成巨大伤害[1]。基于大数据技术从海量涉恐数据中挖掘情报信息,对恐怖活动提前做出预测,打早打小进而将恐怖活动消灭在萌芽中,有效减轻或者避免恐怖主义活动带来的影响,实现情报主导的预防性反恐策略,是我国反恐工作的重心。《中华人民共和国反恐怖主义法》[2]专门设置了第四章“情报信息”对反恐情报信息工作提出了明确的具体要求。通过各种渠道收集到海量的涉恐数据后,如何充分利用这些数据发现涉恐线索是一个值得研究的问题。
异常检测是数据挖掘中的一种常用方法,是指给定若干对象,发现其中明显不同或与其他数据不一致的部分对象。利用异常检测可以在海量基礎数据中将“疑似”恐怖分子和与之相关的暴恐线索找出来,再由情报专家研判对应的情报线索是否有参考价值。在谷歌学术搜索中涉及反恐情报异常检测的外文文献主要包括适用于各类犯罪调查的不同异常检测技术综述[3]、恐怖犯罪模式研究[4]、行为分析[5]、隐私保护[6]、网络入侵检测[7]等方向。在中国知网、万方、百度学术搜索等知名中文文献数据库中,相关的研究主要包括恐怖袭击模式的异常检测[8]、视频异常[9]、网络入侵检测[10]、通话记录异常挖掘[11]、动物嗅觉探测异常[12]等。本文将研究如何利用异常检测的方法在基础数据中挖掘“疑似”涉恐人员数据。
1 异常检测理论
异常检测(Outlier Detection)又称异常挖掘、离群点检测、例外挖掘、稀有事件检测等,是指发现与大部分其他对象不同的对象[13]。具体的数学表述为给定N个数据点或对象的集合,预期的异常点个数k,找出其中不一致的排序前k个对象或数据点[14]。一般系统中异常数据的成因主要包括测量、输入错误或系统运行错误等。异常检测目前常用于医疗诊断、保险或银行业的欺诈检测、海关或民航等部门的安全检查、电子商务中的犯罪检测、网络安全中的入侵检测、灾害气象预报等领域。
2 反恐情报中的异常数据分析
一般的异常数据的挖掘分析主要需要解决两个子问题[15]:1)如何度量异常;2)如何有效发现异常。对于反恐情报分析中的异常检测,目标是从大量基础数据中将“疑似”的涉恐人员数据找出来,首先要解决如何度量涉恐人员的问题,其次解决选择何种有效的异常检测方法进行涉恐人员数据挖掘。在发现异常的方法选择上又要同时考虑涉恐属性特点和基础数据类型。因此反恐情报中的异常人员数据检测必须分别考虑3个子问题:1)如何度量异常;2)如何根据涉恐人员数据属性特点选择检测方法;3)如何根据基础数据类型选择检测方法。本节将从这3个子问题分别论述基于聚类的异常检测较适合反恐情报中的异常人员数据检测。
2.1 反恐情报中的“异常”度量标准
度量涉恐人员要根据反恐情报分析专家的经验和统计数据设定具体“异常”的度量指标。由于异常产生的机制是不确定的,通过异常检测的方法挖掘出的仅仅是“疑似”异常数据,这些“疑似”数据是否是实际的涉恐异常数据,只能根据具体应用由领域内的专家来判断,而不是由异常检测方法本身来解释说明。在反恐情报分析中,通过一些常用的异常度量方法只能找出系统中的异常人员,这些异常人员可能是盗窃团伙分子、贩毒人员、黑社会背景人员、诈骗嫌疑人等涉及其他犯罪的人员,与反恐情报分析的目标数据不符。反恐情报的异常检测必须能找出涉及暴力恐怖袭击的人员,这就要求必须通过已破获暴恐案件中的统计数据和反恐专家的经验总结出涉恐特征。异常检测就是找出最符合这些涉恐特征的数据,即与这些涉恐数据的相似度最大或相异度最小的数据。
2.2 适合涉恐人员属性特点的异常数据挖掘方法
选择有效方法要符合涉恐人员的属性特点,适合混合属性数据挖掘分析。涉恐人员的属性特征中既包含连续数值属性也包含分类离散属性[16],属于混合属性数据。从技术路线角度来看,常用的异常检测主要包括基于统计、距离、密度、聚类等方法[17]。基于统计的方法假定数据符合某种分布,例如正态分布、泊松分布等,建立在标准的统计学基础上,一般对于单个属性数据非常有效,而涉恐基础数据属性众多且统计分布未知,并不符合这类方法;基于距离的方法和基于密度的方法较适合具有连续数值属性的数据,涉恐数据属性中的确存在一些连续数值属性,但是更多的是大量分类离散属性,同时这种方法计算复杂度比较高,所以不建议采用;基于聚类的方法是将大量数据进行分簇处理,分簇后每个簇内的数据更接近,各个簇之间的数据相差较大,聚类完成后远离大簇的小数据量簇或者孤立数据点即为异常数据。聚类方法中有一部分适合于分类离散属性的处理,涉恐基础数据中含有大量的分类离散属性,少量连续数值属性例如身高、体重、年龄、财产状况等也可以按照区间离散化的方式转换为分类离散属性,所以可以考虑采用聚类的方法进行涉恐人员的异常检测。先选择适合分类离散属性的聚类方法将海量基础数据聚类分簇,找出异常数据,然后再在异常数据中检测涉恐人员。
2.3 适合无监督类型基础数据的异常数据挖掘方法
本文主要考虑基础数据中没有涉恐人员类别标号的情况。从异常数据是否具有类标号(正常或异常)以及类标号的利用程度分类,异常检测方法可以分为有监督的异常检测方法(可以理解为有涉恐人员类别和其他正常人员或普通人员类别的信息)、无监督的异常检测方法(可以理解為基础数据中没有人员类别信息)以及半监督的异常检测方法(可以理解为基础数据中有正常人员的类别信息,但是没有关于涉恐人员的类别信息)[18]。有监督的方法本质上属于根据基础数据训练数据挖掘分类模型,然后利用建模对未知人员数据分类识别涉恐人员,作者已经做过此类研究[19-20]。本文将重点研究基础数据没有涉恐人员类别信息的情况,即无监督和半监督的情况。前文所述的聚类方法在海量未知类别数据快速分类时处理速度较快,这一点也非常适合反恐情报分析。
3 基于聚类的反恐情报异常数据分析
通过前文的分析可知,反恐情报分析中的异常数据挖掘可以分为两步。第一步采用聚类的方式将原始海量基础数据分为几个簇,找出其中的小簇和孤立数据作为待判断的样本数据。第二步定义一种适合涉恐人员数据混合属性特征的相似度或相异度度量方法,找出与已有恐怖分子特征最接近的数据,即为通过异常检测找出来的涉恐人员。笔者曾做过关于涉恐数据聚类分析的研究[21-22],核心内容是将涉恐人员基础数据分簇,然后基于每个簇判定涉恐等级,所有的连续数据属性按照区间划分转换为分类离散属性,离散属性之间按照广义雅卡尔系数或者公共链接数计算相似度。这一方法也可以直接用于未知类别的基础人员数据分簇,因此下文将不再讨论聚类过程的细节,感兴趣的读者可以查阅笔者发表的相关文献。
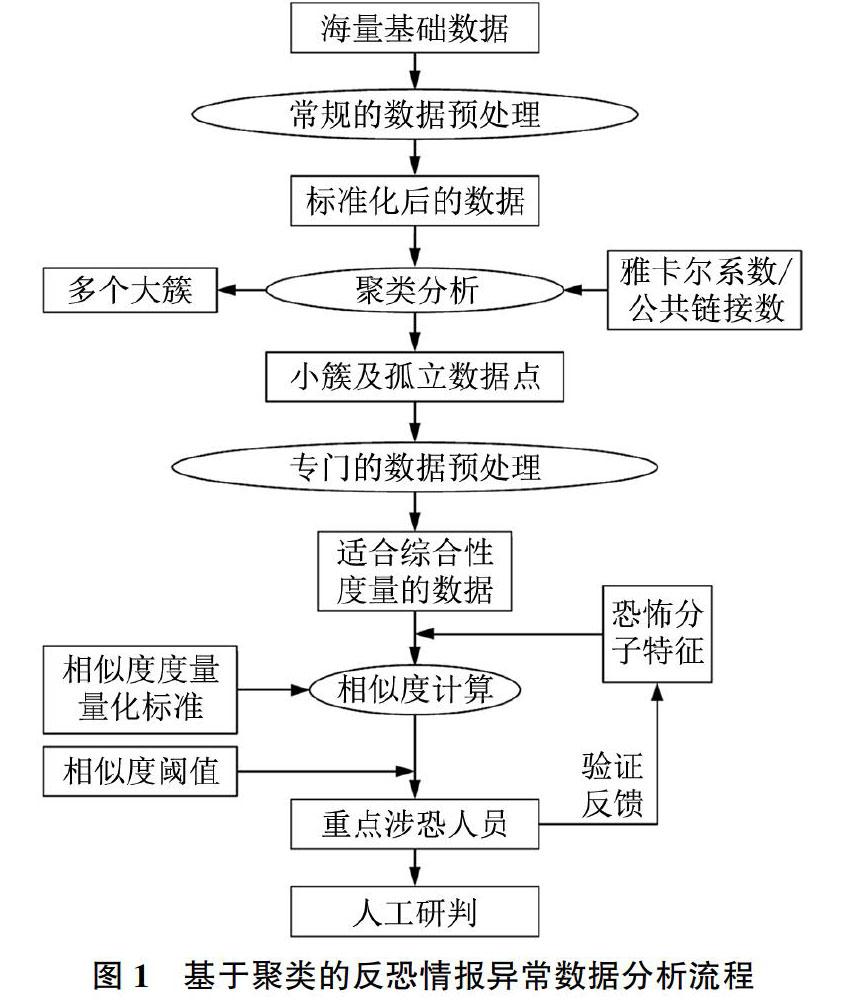
如图1所示为本文设计的反恐情报异常数据挖掘流程。首先要收集到海量的基础数据作为情报分析的数据来源。原始的数据不适合直接展开异常检测,要进行数据的预处理将其转换为标准化数据,便于展开挖掘过程[23]。第一次数据预处理除了常规的数据清洗、数据集成等操作外,还要进行数据离散化处理即将所有的连续数值属性全部转换为有序的分类离散属性。数据预处理的过程中,不同数据之间满足独立性,可以采用并行计算的方式分别处理,提高处理效率。准备好基础数据后利用适合分类离散属性的聚类方法,将标准化的数据分簇,大数据量的簇被认定为正常数据或普通数据,小簇和孤立数据点保存作为下一步异常检测的基础数据。
为使最后异常检测的结果更加精确,获得下一步开始前的基础数据后,再次进行数据预处理,将所有的数据属性特征做进一步转换。如果在第一次数据预处理时将所有数据的格式转换一步到位,则数据量太大会消耗过多的计算时间和计算资源,降低情报分析的效率,所以数据预处理过程可以分两次进行。第二次数据预处理将所有分类离散属性进一步分为有序离散属性、二元离散属性和其他普通多元离散属性。第二次数据预处理后生成适合综合计算所有属性相似度的数据。
最后根据已有的恐怖分子的属性特征值统计,计算每个异常数据对象的相似度,并设最小相似度阈值,找出其中满足最小阈值的即为涉恐人员。其中恐怖分子的属性特征值统计为已知量,由已破获暴恐案件中的数据计算得出。评估数据相似度的过程必须综合考虑多重涉恐属性,具体的量化标准由下文讨论的涉恐敏感程度度量方法计算得出。计算出满足阈值的“疑似”重点涉恐人员后,继续由有经验的情报分析员进行人工研判。此外,还要进行验证反馈,根据实际调查结果,更新恐怖分子特征统计数据,不断提高异常检测的准确度。
4 涉恐敏感程度度量方法
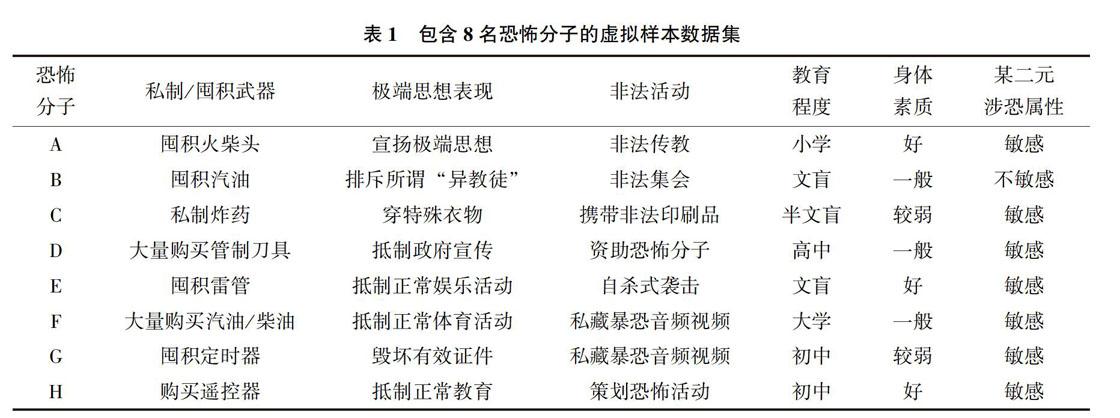
本节将设计一种计算涉恐人员敏感程度的量化方法,通过计算与恐怖分子的相似度来量化敏感程度,该方法能够覆盖各种类型的涉恐属性特征。我国涉恐人员的特征比较明显,具体可以参考《识别宗教极端活动(75种具体表现)基础知识》[24]、2016年1月1日起正式施行的《中华人民共和国反恐怖主义法》、2017年3月29日颁布的《新疆维吾尔自治区去极端化条例》以及一些媒体公开报道的暴恐案件。表1中的虚拟样本集即参考这些特征随机生成,下文的相似度计算也以这些属性特征为例展开。本文声明,这些虚拟样本数据完全根据涉恐数据的特征随机生成,不包含任何敏感数据。同时,表中的数据仅用于表述异常检测分析的流程,实际反恐情报分析中涉恐属性更多,必须列举出所有重要涉恐属性,提高异常检测的科学性和准确性。
4.1 合并同类项
这些涉恐特征中有一部分存在一定的共性,为了提高情报分析的效率,可以将具有一定共性的涉恐特征合并,使得涉恐特征更集中,计算相似度时目标性更强,结果更精确。例如表1中的虚拟样本数据集,“极端思想表现”属性中“抵制正常体育活动”、“抵制正常娱乐活动”可以合并为“抵制正常文体活动”,“非法活动”属性中“携带非法宣传品”、“私藏暴恐音频视频”可以合并为“持有非法宣传资料”。表2所示为合并同类项后的虚拟样本集。以“私制/囤积武器”属性为例,恐怖分子的统计特征值为{5/8囤积易燃易爆物+2/8囤积炸弹零件+1/8囤积冷兵器}。在反恐情报分析的异常检测中,这些均作为已知数据,在多次异常检测时无需重复计算,只需对原始基础数据统一计算1次即可。两表中的数据仅用于说明恐怖分子涉恐特征的统计方法。在大量数据统计中,可将比例非常小的特征值直接舍弃,提高计算效率。
4.2 初步聚类的相似度度量
初步聚类过程中的相似度度量采用广义雅卡尔系数。在聚类过程中,为了快速完成初步分类过程,连续数值属性转换为分类离散属性,所有离散属性的处理没有区别,直接代入公式计算雅卡尔系数。当通过聚类选出所有异常数据后,基础数据量已经变小,再直接用雅卡尔系数统一计算相似度则不够精确。在计算基础数据与恐怖分子相似度时将分类离散属性进一步分为有序离散属性、二元离散属性以及其他多元离散属性。
4.4 连续数值属性的度量
恐怖分子的连续数值属性主要包括身高、体重、年龄、财产状况等。一般情况下,连续数值属性最简单、最精确的度量是采用各种标准距离例如曼哈顿距离、欧几里得距离、切比雪夫距离等进行计算。但是,与其他思想倾向、极端活动等属性特征不同,恐怖分子的这些连续数值属性没有一个明确的可参考值,一种比较可行的方式是按照统计数据将这些连续属性离散化,部分属性还可以合并同类项,例如身高、体重、年龄综合为身体素质,设为是否适合实施暴恐活动,例如分为{好,一般,较弱},还可根据实际需要进一步细分,显然离散化后的涉恐属性特征依然是有序的。
4.5 二元离散属性的度量
通过新闻报道中可以看出,欧洲的恐怖袭击很多与中东难民有关,纯粹的原住居民较少[26-27]。从国际宗教极端主义的传播来看,这些暴恐分子的宗教信仰、文化背景、生活习俗等各方面也与“伊斯兰国”、“基地组织”等恐怖组织更接近,因此更容易被宗教极端主义洗脑。所以根据其特征可以设定二元离散属性的值,一种为敏感属性值(值为1),其他全部设为非敏感属性值(值为0)。我國也可以参考欧洲的情况根据暴恐案件的统计数据,将一部分属性筛选出来,采用二元离散属性度量。二元离散属性的度量一般采用简单匹配系数或二元离散属性的雅卡尔系数。涉恐二元离散属性在度量时,显然敏感涉恐属性值对反恐情报分析更有意义,且原始基础数据中非敏感属性值占大多数,本文采用更关注敏感属性的雅卡尔系数来计算两个数据的相似度。即s2=f11/(f11+f10+f01),角标的0和1表示两个数据对应属性值分别为0和1的情况。
5 结 语
本文提出了一种基于聚类的反恐情报异常数据挖掘分析方法,主要研究了在反恐情报中如何度量异常和如何发现异常两个问题。其中度量异常的方式为与已掌握恐怖分子的属性特征统计数据计算相似度,相似度大的即为涉恐人员。如何发现异常则分两个步骤,第一步先用适合分类离散属性的聚类方法对原始数据进行聚类分簇,聚类过程中将原始数据集中的连续数值属性全部转换为分类离散属性处理,第二步在聚类分析结果的基础上逐一利用与恐怖分子的相似度检测异常数据点即涉恐人员,这种处理方式效率较高,非常适合大数据量的反恐情报分析。在第二步计算相似度时,每种属性所占的比重需要根据实际反恐经验和验证反馈不断调整,本文旨在说明这种处理方式,具体的比重参数只能由真实数据统计得出。文中使用一组虚拟数据描述了异常数据挖掘分析的详细过程,在实际的反恐情报分析中还要与其他的量化分析方法组成完整的方法体系,相互补充,才能提供最完整、最可靠的情报信息。期望本文的研究可以为提高反恐情报分析效率,精确打击恐怖主义活动提供有益的参考。
参考文献
[1]新华网.新疆的反恐、去极端化斗争与人权保障[EB/OL].http://www.xinhuanet.com//2019-03/18/c_1124247196.htm,2019-03-18.
[2]中国人大网.中华人民共和国反恐怖主义法[EB/OL].http://www.npc.gov.cn/npc/xinwen/2018-06/12/content_2055871.htm,2019-03-18.
[3]Singh K,Upadhyaya S.Outlier Detection:Applications and Techniques[J].International Journal of Computer Science Issues,2012,9(1):307-323.
[4]Khan N G,Bhagat V B.Effective Data Mining Approach for Crime-terrorpattern Detection Using Clustering Algorithm Technique[J].Engineering Research and Technology International Journal,2013,2(4):2043-2048.
[5]Cao L.Behavior Informatics and Analytics:Let Behavior Talk[C]//Data Mining Workshops,2008.ICDMW08.IEEE International Conference on.IEEE,2008:87-96.
[6]Challagalla A,Dhiraj S S S,Somayajulu D V L N,et al.Privacy Preserving Outlier Detection Using Hierarchical Clustering Methods[C]//Computer Software and Applications Conference Workshops.IEEE,2010:152-157.
[7]Agarwal A.Multi Agent Based Approach for Network Intrusion Detection Using Data Mining Concept[J].Journal of Global Research in Computer Science,2012,3(3):29-32.
[8]陈冲.反恐情报分析中的缺失数据处理和异常值检测[D].北京:中国科学院大学,2015.
[9]余昊.基于底层特征的视频异常事件检测算法研究与实现[D].上海:上海交通大学,2015.
[10]肖政宏.无线传感器网络异常入侵检测技术研究[D].长沙:中南大学,2012.
[11]王家定.基于复杂网络理论和通话记录的用户行为异常识别研究[D].合肥:中国科学技术大学,2013.
猜你喜欢
中国新通信(2016年22期)2017-01-13
计算技术与自动化(2016年4期)2017-01-11
