
海量散乱点云数据的模糊聚类挖掘方法研究
2019-11-18 05:22陆兴华刘文林吴宏裕冯飞龙
计算机技术与发展 2019年11期
陆兴华,刘文林,吴宏裕,冯飞龙
(广东工业大学华立学院,广东 广州 511325)
0 引 言
随着云计算技术和物联网技术的快速发展,在物联网环境中通过云存储方式进行海量散乱点云数据的集成处理,通过模糊聚类方法实现散乱点云数据的信息融合和自适应调度,提高云计算和云组合服务的质量。海量散乱点云数据的准确挖掘和分类管理是保障云服务质量的关键,采用智能挖掘和信息处理算法进行海量散乱点云数据的优化挖掘和调度,提高用户进行数据检索和管理的能力,并根据海量散乱点云数据的挖掘结果,构成最优的服务组合,提高数据检索和调度的准确性[1]。
对海量散乱点云数据的挖掘是建立在对大规模数据集的特征提取和关联规则特征分析基础上的。根据网络传输的流量特征进行海量散乱点云数据挖掘,采用相关的信息处理和数据检测方法,提高海量散乱点云数据挖掘的准确性和抗干扰能力[2]。传统方法中,对海量散乱点云数据的挖掘主要采用分集检测和谱分析方法[3],采用自相关特征谱分解方法进行海量散乱点云数据的信息融合和相关性检测,结合模糊数值分析和簇聚类方法实现海量散乱点云数据挖掘。根据上述原理,相关人员进行了数据挖掘算法研究。文献[4]中提出一种基于简化梯度算法的海量散乱点云数据挖掘模型,采用相关检测器进行3D云数据的干扰滤波,结合简化梯度算法进行云数据的输出信道均衡设计,提高数据挖掘的抗干扰能力,但该方法存在带宽受限和维数较大等问题;文献[5]中提出一种基于模糊指向性聚类的海量散乱点云数据挖掘方法,采用模糊K质心方法进行海量散乱点云数据的模糊加权,在保留海量散乱点云数据集内在的不确定性的条件下实现数据优化聚类,提高数据挖掘的模糊决策性,但该方法存在计算开销较大和复杂度较高的问题。
针对上述问题,文中提出一种基于支持向量机的大数据分类挖掘技术。首先采用分段向量量化编码技术进行海量散乱点云数据空间存储结构分析,结合闭频繁项集检测方法进行海量散乱点云数据的信息融合处理,然后对高维融合数据进行语义特征分析和关联规则特征提取,结合尺度分解方法对分类输出的海量散乱点云数据进行降维处理,采用模糊聚类方法实现对海量散乱点云数据的分类挖掘。最后通过仿真证明了该方法的有效性。
1 海量散乱点云数据的数据结构分析和特征提取
1.1 海量散乱点云数据的数据结构分析
为了实现对海量散乱点云数据的优化挖掘,首先分析海量散乱点云数据的数据结构和相似度特征信息。采用C4.5决策树模型,构建海量散乱点云数据的分类决策模型[6],进行海量散乱点云数据的相似度分解,如图1所示。

图1 海量散乱点云数据的数据结构分解决策树模型
根据图1的决策树模型,对海量散乱点云数据进行模糊特征识别和数据分类,构造海量散乱点云数据的混合属性模糊分类模型[7],根据数据的混合分类属性进行相似度分析,对模糊信息的分段属性集X进行奇异值(SVD)分解:
X=UDVT
(1)

(2)
(3)
其中,AH、AHB和θH、θHB分别是前p个元素是数值属性值以及系统函数H(z)和HB(z)的离散化数值属性和向量量化特征量。
求得海量散乱点云数据的语义概念集的分布矩阵XTX,取非零特征值作为训练子集,进行数据信息流模型重构。采用混合相似度特征分析方法,对海量散乱点云数据进行特征重组和向量量化分析,得到云数据特征重组后输出的平均互信息特征表达式为:
(4)
其中,psq(si,qj)表示海量散乱点云数据的语义本体概念集si和数据概念集qj的联合分布概率。
定义海量散乱点云数据的簇中的信息分布模型为[s,q]=[x(t),x(t+τ)],得到模糊信息的闭频繁项,结合闭频繁项集检测方法进行海量散乱点云数据的信息融合处理[8]。
1.2 闭频繁项特征提取
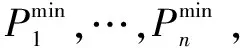
xn=x(t0+nΔt)=h[z(t0+nΔt)]+ωn
(5)
其中,h(·)为海量散乱点云数据分布式时间序列,表示为一个具有多维数据结构模型的函数;ωn为大数据的测量误差。
构建海量散乱点云数据分布的时态结构模型,将挖掘的海量散乱点云数据按照五元组进行关联规则项特征重建,海量散乱点云数据的分布结构模型的分布函数描述式为:
Xp(u)=
(6)
其中,p为分布式海量散乱点云数据存储结构的阶数;α为统计信息采样的频繁项集。
采用统计回归分析方法进行海量散乱点云数据的闭频繁项检测[10],检测模型表达如下:
(7)
结合闭频繁项集检测方法进行海量散乱点云数据的信息融合处理,构造海量散乱点云数据挖掘的线性规划模型[11]。
2 数据模糊聚类挖掘实现
2.1 数据模糊聚类处理
在采用分段向量量化编码技术进行海量散乱点云数据空间存储结构分析的基础上,对高维融合数据进行语义特征分析和关联规则特征提取和模糊聚类处理。采用分段向量量化编码技术进行海量散乱点云数据空间存储结构分析和关联规则特征提取[12],构建需要挖掘的海量点云数据的量化编码分析模型:
(8)
(9)
根据数据的不同属性在聚类的差异性,进行海量散乱点云数据特征识别[13]。数值属性特征和分类属性特征分别为:
RβX=U{E∈U/R|c(E,X)≤β}
(10)
RβX=U{E∈U/R|c(E,X)≤1-β}
(11)

(12)
(13)
Si=Sb+Sω
(14)
其中,p(ωi)为数据挖掘的分配规则向量集;μ=E(x)为散乱点云数据的分布稀疏度。
2.2 基于支持向量机的数据挖掘
文中提出一种基于支持向量机的大数据分类挖掘技术,采用自适应加权算法,得到支持向量机进行大数据特征分类器的加权系数为:
(15)
采用支持向量机的学习算法[14],得到海量散乱点云数据分类的自适应学习过程为:
(16)
在B⟹D,A∩B⟹D等规则约束项下,得到海量散乱点云数据模糊挖掘的量化参数满足:
(17)
数据的统计量化集为(u,v)∈E,设A⊂V,B⊂V且A∩B=∅,采用支持向量机分类器进行模式识别,实现对海量散乱点云数据重组和数据结构重排。对高维融合数据进行语义特征分析和关联规则特征提取,对提取的海量散乱点云数据的关联规则采用支持向量机分类器进行模式识别[15],数据准确挖掘的概率密度函数为:
其中,λS为在采样时刻进行数据采集的相似度系数;p2D为簇中的信息分布概率密度。
海量散乱点云数据簇中心之间的相异度为:
(19)
其中,Dis(A)表示聚类中心的欧氏距离;Dis(B)表示语义本体集。
采用基于模糊质心相异性度量方法构建海量散乱点云数据的分类模糊集。根据上述分析,实现了海量散乱点云数据的模糊聚类挖掘。
3 仿真实验分析
通过仿真实验测试文中方法在实现海量散乱点云数据优化挖掘中的应用性能。实验采用Matlab设计,测试数据集选用KTT数据集,实验中的大数据样本库采用Olivetti-Oracle Research Lab (ORL)海量散乱点云数据库,每个高维融合数据子块阈值YHW=0.15,对海量散乱点云数据采样的占空比为0.34,样本训练集规模为26 kbps,海量散乱点云测试集为100 kbps,稀疏度为0.56。根据上述仿真环境和参数设定,进行海量散乱点云数据模糊聚类和挖掘仿真,得到数据采样的时域分布如图2所示。
采用分段向量量化编码技术进行海量散乱点云数据的信息融合,实现数据模糊聚类和挖掘,得到的挖掘结果输出如图3所示。

图2 数据采样的时域分布
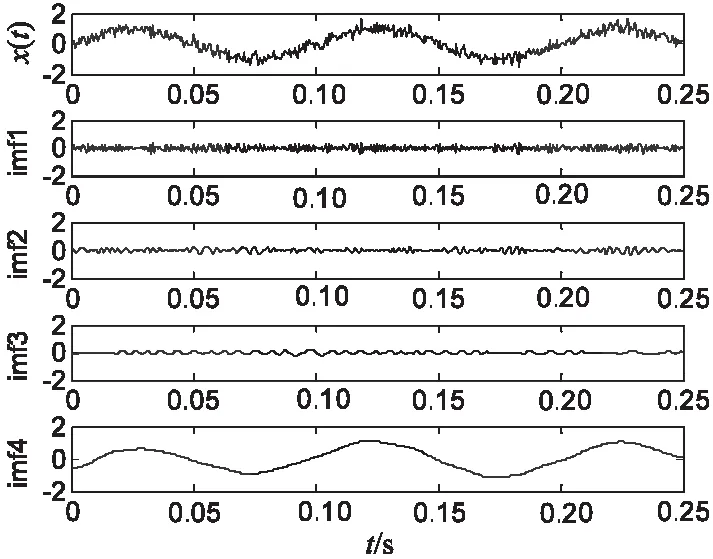
图3 数据模糊聚类挖掘输出
分析图3得知,采用文中方法能有效实现对海量散乱点云数据的分类挖掘,特征的聚类性较好。测试不同方法进行数据挖掘的召回率,得到的对比结果如图4所示。

图4 数据挖掘的召回性对比
分析图4得知,文中方法进行数据挖掘的召回率较高,说明数据挖掘精度较高,挖掘的收敛性较好,具有很好的模糊聚类挖掘性能。
4 结束语
文中提出一种基于支持向量机的大数据分类挖掘技术。采用分段向量量化编码技术进行海量散乱点云数据空间存储结构分析,结合闭频繁项集检测方法进行海量散乱点云数据的信息融合处理,对高维融合数据进行语义特征分析和关联规则特征提取。对提取的海量散乱点云数据的关联规则采用支持向量机分类器进行模式识别,结合尺度分解方法对分类输出的海量散乱点云数据进行降维处理,采用模糊聚类方法实现对海量散乱点云数据的分类挖掘。仿真结果表明,该方法进行数据挖掘的召回性能较好,挖掘精度较高。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
导航定位学报(2022年2期)2022-04-11
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
当代陕西(2019年14期)2019-08-26
雷达学报(2018年5期)2018-12-05
