
以学生为中心的“Hadoop大数据平台”课程的教学设计
2019-11-19 06:40曹素丽杨延广张翠轩
微型电脑应用 2019年11期
曹素丽, 杨延广, 张翠轩
(石家庄邮电职业技术学院 计算机系, 石家庄 050021)
0 引言
截至到2018年,开设“大数据技术与应用”专业的高职院校已达到208所,越来越多的学校加入到了该专业人才培养中来。我校于2015年开始筹建该专业,2016年正式开始招生(原名是:计算机应用技术——大数据技术应用方向),是全国最早招收该专业的高职院校之一,由于该专业是新设专业,可借鉴经验少,各教学环节都需要教师去摸索。三年多来,我校投入大量的精力对专业建设、实验室建设和课程建设等做了深入的调查研究与实践,截至目前,该专业在我校即将完成一个完整的教学周期。在教学中我们坚持以学生为中心的教学理念,以学生的目标岗位需求来确定教学内容,按照“以学生为主体,以教师为主导,充分发挥学生的主动性”原则来设计各个环节。本文将对该专业中核心课程《Hadoop大数据平台》的教学设计与实施方案进行讨论与总结。
1 面向实际应用的课程内容设计
在“大数据技术与应用”专业课程体系,“Hadoop大数据平台”是最核心的课程,目的是让学生在具备先修课“Linux系统管理”“关系数据库”“Java开发”“大数据与云计算概论”等技术基础课后,进一步学习分布式存储技术、并行计算框架技术等大数据系统相关技术课程,本课程计划课时为100学时。
大数据系统是一个庞大的生态系统,而Hadoop是生态系统的典型代表,其提供的分布式存储方案HDFS、并行计算方案MapReduce构成了大数据系统的基础架构,在此框架基础上,为了解决不同应用场景的问题又逐渐发展起了面向各种不同应用的生态组件,这就是学生毕业后要面对的主要系统,如图1所示。
根据高职教育的特点和目标岗位需求,我们秉承理论够用、重在实践的原则,通过分析企业的实际应用情况,我们精选最主流最常用的技术与组件来构成本课内容。Hadoop体系结构、HDFS、MapReduce属于大数据技术的基础性知识,是学习和理解其他技术的前提;Hive是一种简便开发MapReduce程序解决大数据离线分析的工具,能解决企业近一半应用,简单易用广受欢迎;HBase是适合大数据实时查询应用的非关系数据库,底层采用HDFS进行大数据存储;Sqoop可以将企业已经收集起来的大量的关系型生产数据导入到Hadoop中进一步处理,还可以将处理后的结果再传回到关系数据库,Sqoop在很多企业中有着硬性的应用需求;Spark是一种与Hadoop相似的集群计算环境,基于内存计算,从而数据分析速度更快,有逐步替代MapReduce计算的趋势,是Hadoop生态系统中重要的组成成员。由此我们将Hadoop框架和这6个功能组件共7个模块确定为本课的核心内容,见图1中的灰色部分,其中的YARN与ZooKeeper是学习7个模块过程中的辅助学习内容。

图1 Hadoop体系架构及教学模块
本课程包含的内容模块较多,对每个模块我们定位在初步认识和简单使用这一层面,让学生理解Hadoop及其各组件的基本工作机制、学会整个系统的安装部署与调试,具备一定的操作、维护与应用能力,后期学生可以在MapReduce开发、Hive数据分析等方面继续深入学习。
2 任务驱动的教学方案设计
Hadoop是由多个相互关联又相对独立的功能模块构成的,课程实践性、操作性强,非常适合采取任务驱动教学方式。任务驱动是一种以学生为主体,以教师为主导的教学做一体化的教学形式。学习过程中,由老师提出问题布置任务,学生在完成任务的过程中学到新知识和技能。在任务驱动下,学生变被动为主动,体现了“以学生为中心”的原则,是一种适合于学习新知识、掌握新技能的探究式学习方式。
任务驱动学习方式下,教学组织以“任务”为载体,老师需要根据教学内容要求,把知识、技能分解,根据学生水平和学习条件设计为一个个适当的任务,让学生逐个去完成,将教学内容蕴含于任务之中。该课程模块划分清晰,我们将每个模块设计成一项综合任务,每个任务中又包括知识准备和实战两类多项具体子任务,即要先简单学习基本概念、功能及原理等预备知识,之后再动手进行系统安装部署,进行实际操作完成任务,最后进行总结交流,进一步加深理解、完善知识体系。
任务的先后顺序主要基于该组件在Hadoop生态圈所处的层次与地位来考虑,本课程按照自底向上、自里到外,自基础到扩展的原则来设计安排讲解的次序,逐步递进。针对7个模块共设计了20多项学习任务,如表1所示。

表1 教学任务设计
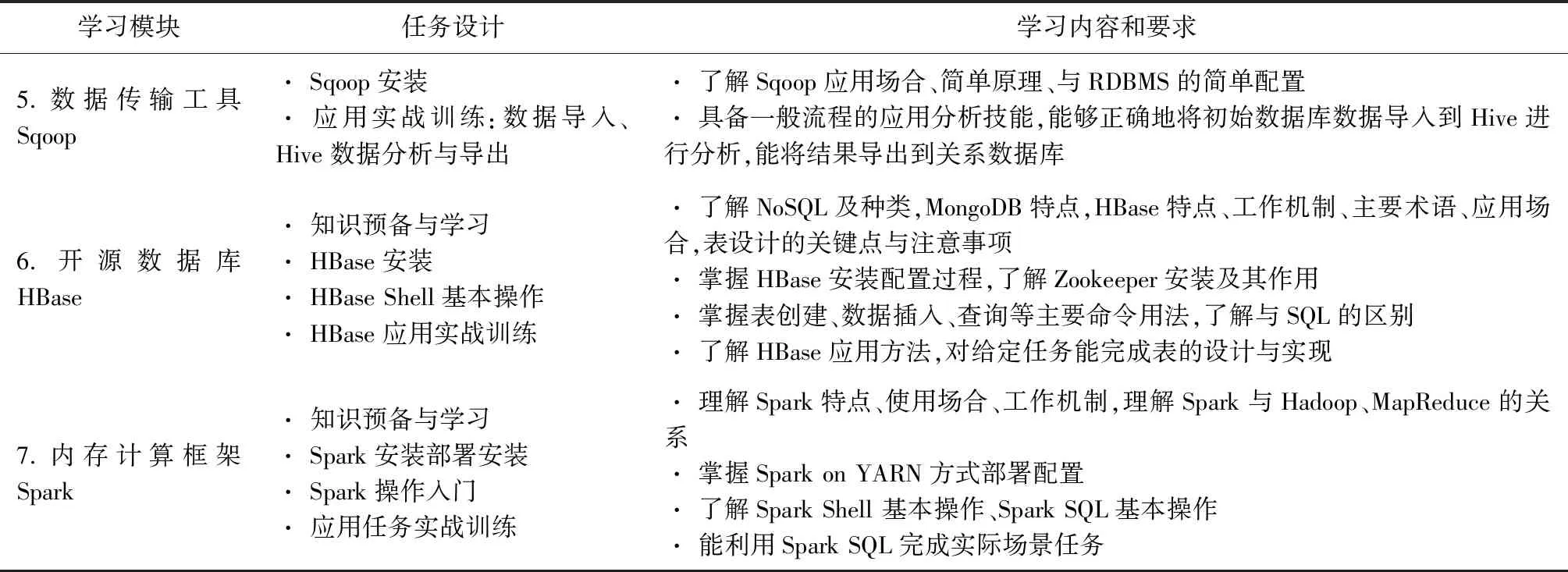
学习模块任务设计学习内容和要求5.数据传输工具Sqoop· Sqoop安装 · 应用实战训练:数据导入、Hive数据分析与导出· 了解Sqoop应用场合、简单原理、与RDBMS的简单配置 · 具备一般流程的应用分析技能,能够正确地将初始数据库数据导入到Hive进行分析,能将结果导出到关系数据库6.开源数据库HBase· 知识预备与学习 · HBase安装 · HBase Shell基本操作 · HBase应用实战训练· 了解NoSQL及种类,MongoDB特点,HBase特点、工作机制、主要术语、应用场合,表设计的关键点与注意事项 · 掌握HBase安装配置过程,了解Zookeeper安装及其作用 · 掌握表创建、数据插入、查询等主要命令用法,了解与SQL的区别 · 了解HBase应用方法,对给定任务能完成表的设计与实现7.内存计算框架Spark· 知识预备与学习 · Spark安装部署安装 · Spark操作入门 · 应用任务实战训练· 理解Spark特点、使用场合、工作机制,理解Spark与Hadoop、MapReduce的关系 · 掌握Spark on YARN方式部署配置 · 了解Spark Shell 基本操作、Spark SQL基本操作 · 能利用Spark SQL完成实际场景任务
每个模块对应3-4个任务,所有要求的知识技能点都有对应的子任务,任务设计由简到繁,由易到难,循序渐进,课程知识全部涵盖其中。完成所有任务后,学生即可完成一个大数据系统的完整安装配置,同时完成其中蕴含的、课程要求的知识技能的学习任务。本课程内容具体组织与要求如下表所示(按100学时设计)。
具体教学实施过程:
(1) 接受任务:接受老师下达的任务书,明确任务要求,成立任务小组。
(2) 定方案:学习相关预备知识,准备资料,研讨确定完成步骤和方案。
(3) 学做一体化完成任务:安装部署项目的系统环境,进行调测配置,利用系统环境完成规定任务,进行技能训练。
(4) 总结交流:进行小组项目总结,形成PPT汇报,集中交流点评。
(5) 课程诊改:对阶段教学进行效果评估,设计下一步的教学任务及改革方案。
通过教学做一体化过程实践,学生达到学知识、练技能、提能力、悟原理的目标。同时提高了学习能力、分析问题解决问题能力、动手能力和团队精神。
3 注重能力培养的实训方案设计
实训环境是实施任务驱动教学的必要保障条件,本课程涉及到的实训环境复杂,这是由大数据系统本身的复杂性和教学实施的过程性决定的,整个学习过程是循序渐进的,这就需要根据学习进度,为学生提供不同场景、不同阶段、不同层次的实训环境。其中,既有单节点环境又有多节点的完全分布式环境,既需要有现成的操作训练平台,又需要有让学生从零开始一步一步的系统搭建平台的环境,还需要有处在不同状态下的实训场景和安装好不同组件的半成品平台,既有基本的使用操作又有应用案例的综合操作,既有字符界面又有图形化界面,既有小任务又有大任务(需要保留环境下次继续操作)。
3.1 两种实训环境分析
当前可以采用的实训方案基本分两种:一是本地机器方式,二是学生登录校内服务器线上操作,但前提是学校需购买专门的大数据实训平台软件并搭建集群服务器环境。
1. 本地机器方式:这种方式下,每个学生需要一台Linux机器,而且是Linux虚拟机。因为用Linux物理机会有很多问题,如:很难准备出多个安装了不同组件进度的Hadoop环境,学生使用一台机器必须从课程开头一直做到尾,中间如出现问题很难继续前行,即使恢复系统也不易控制恢复点,再有,Linux对PC机硬件的兼容性也不是太好,因此我们采用了更灵活的虚拟机方式。
但是这种方式,教师需要亲自将每一种状态的虚拟机环境准备出来,而且有时候准备并不顺利、会遇到各种意外的问题或返工或排除,投入的精力会相当大,当然老师从中也能积累实践经验,提高执教能力。
2. 在线大数据实训平台方式:近两年,市场上已经出现一些商品化的大数据实训平台软件,它部署于多节点构成的服务器集群上,专门用于大数据技术实验教学。这个平台提供了比较全面的实验机类型,也提供了一些实际的应用案例,学生可以随时随地的线上操作练习,学生使用简单,老师管理和备课难度降低,但是因为实验中学生只要按规定步骤做即可完成任务,内容死板,不够灵活,不利于锻炼学生的实际能力,发挥余地小。
所以经过实践测试和分析比较,我们最终设计的实训环境方案是本地虚拟机方式与在线大数据实训平台相结合,互补进行。
3.2 实训方案设计
根据各模块的内容特点、教学目标、学生学情,我们具体设计的实训方案如下。
1. 本地虚拟机方式实训方案:设计并提供4种虚拟机,供学生的不同实训项目使用。由于每一种虚拟机其实就是Windows下的一些文件,因此,课前要把教师已做好的虚拟机文件,分发到每台学生机上,实训时学生直接打开虚拟机,即可直接进入相应的实训环境中。
Linux虚拟机:仅安装Linux,即一台Linux机器,供学生完成Linux平台下的各种实训项目,包括Linux基本操作与应用、Hadoop本地模式安装、Hadoop伪分布式安装、图形化升级、eclipse安装、Hadoop开发插件安装、Java 的HDFS API开发、Hadoop完全分布式安装等实训实验项目;
单个Hadoop虚拟机(伪分布模式):即一台Linux机器,并已安装Hadoop系统。供Hadoop shell操作、MapReduce应用案例实验、Hive安装、HBase安装、Spark安装等;
完全分布式Hadoop虚拟机:3个虚拟机、构成3节点的Hadoop集群,供Hadoop集群运维、HA拓展实验等;
Hadoop完全实验机:安装了本课程所有模块软件,供Hive实验、HBase实验、Spark实验及应用案例等实验。
计算机配置采用8GB内存,4个节点时运行流畅。以上是我们的做法,实际中也可以根据需要提供更多处于不同阶段的虚拟机,供学生实训使用。这种方式的优点是学习方便,适合进行技能学习训练,存在的主要问题是虚拟机方式缺乏直观性、与生产环境有差异。
2. 在线大数据实训平台方式实训方案:根据这种方式开放性好,不受时间地点限制、环境稳定操作简单、方便重复的特点,在平台上设计的实训项目主要有:阶段性技能练习项目,原理视频的学习、课下的作业完成与实训练习、各部分中shell命令的操作练习、单一步骤的操作实训、平台集成的案例操作、以及平台提供的其他成熟实训项目等。另外在平台还可安排需要多次课连续操作的大任务大应用实训、三个节点以内的完全分布式安装、元数据存至MySQL的Hive部署等实训项目。
需注意的是这些平台为了操作简单往往会对用户屏蔽很多内容,做实验的环境都是一个与之绑定的实验机,很多东西已经内置好了,学生按要求步骤继续操作下去即可,导致学生对实验环境难以深刻了解,操作过程中程序在哪、数据在哪,总是云里雾里、心里不透亮,会影响对内容的理解。同时教师也很难在平台上部署个性化的教学环境,所以更灵活的拓展实训需要结合本地虚拟机方式进行。
4 总结
目前,我们已经完成了两个班级的教学活动,在教学过程中,根据设计方案坚持通过学生主体参与,强化能力培养;通过教师主导,突破学习难点提高效率;通过分组分层照顾个体差异,保证所有人都能学有所获,取得了良好效果。但教学研究永无止境,为了更好地培养学生,需要大家共同努力,坚持诊改,不断优化教学方案。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中老年保健(2021年12期)2021-08-24
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
智慧健康(2021年33期)2021-03-16
计算机教育(2020年5期)2020-07-24
中国生殖健康(2020年6期)2020-02-01
电子制作(2019年10期)2019-06-17
特别文摘(2016年8期)2016-05-04
汽车维修与保养(2015年7期)2015-04-17
