
基于地域约束的单位名称二次聚类∗
2019-11-29 05:13贺依依黎铁军蒋艳凰
计算机与数字工程 2019年11期
贺依依 黎铁军 蒋艳凰
(国防科学技术大学计算机学院 长沙 410073)
1 引言
近几年来,链接开放数据的可用性越来越高,从而引申出了大规模知识图谱[1],如FreeBase[2]。在构建知识图谱的过程中,需要从不同结构的数据中抽取特征节点(即实体,例如:人,组织,位置和其他类型等)以及定义节点间关系[3]。由于自然语言的表达存在多样性、动态性、非规范性等问题,知识图谱抽取的多个实体节点(实体名称)可能存在多种表达方式,即表达歧义。因此需要对抽取出的实体进行歧义的消解。
在进行实体消歧过程中,研究的内容主要分为两类:同名消歧与多名聚合[4]。由于翻译、缩写、书写方式等问题,造成了对同一个实体单位有不同的表述方式。将这些不同的表述方式识别成同一个实体,即为多名聚合。目前多名聚合问题的其中一种解决方法是利用上下文信息构建特征向量结合相似度计算实体间距离。将一定阈值距离范围内的实体进行聚合,从而达到消除歧义的目的[5]。但是对于大多数上下文信息匮乏的文本,在进行多名聚合过程中,模型无法明确给定实体的特征信息或文本的标签描述。由于不存在明确的文本标签描述,无法通过目前常用的分类方式(如语义网络[6]等)来完成对不同实体的分类。在这一条件下只能通过实体表述本身的文本信息进行相似度的计算,获取实体间距离来进行无监督聚类。基于统计的计算和基于规则的计算等方式是目前主流的解决方式。通过将短文本转化为计算机可识别的向量来进行文本间的距离计算。
当大规模数据是无标签时,一般是以聚类的方式,对同一实体的不同表述进行聚合。在聚类的过程中,主要通过设定文本表述的相似度距离的阈值,将文本表述相似的聚成同一个簇。本文中,主要使用的聚类算法是密度聚类,通过使用密度聚类,将无标签短文本的实体进行多名聚合,解决无实体标签时,无法确定实体的个数问题。然而使用密度聚类时,由于使用的是固定的参数,会出现相近的类被合并成一个聚类。因此在此基础之上,还可以进行二次聚类。
本文中提出了二次聚类的方法。第一次密度聚类将大致相同的实体表述聚合在同一个簇。在第一次聚类的基础上,使用地域约束和第二次聚类对第一次密度聚类产生的簇,进行进一步划分,解决密度聚合过程中由于密度距离泛化导致的同一簇内存在多个不同实体的问题。
2 相关工作
实体消除歧义中多名聚合主要分为两步,第一步是实体文本的相似度计算,第二步是基于文本的相似度对同一实体的不同表述进行聚类。在本节中主要介绍文本的相似度计算和聚类方法。
主流的文本相似度计算分为三类:基于字符串的方法、基于统计的经验主义方法与基于规则的理性主义方法。基于字符串的方法通过计算两个字符串的字面差异来定义字符串之间的距离。Wang J 等[7]使用编辑距离的方法,通过计算一个字符串变成另一个字符串的最少编辑次数(如:增加、删除和替换单一字符)来定义字符串间的距离,从而进行相似度匹配。但是对于同一实体存在词序上的表达差异时,由于距离变化较大,导致文本相似度降低。为了解决这个问题,余婷婷[8]等使用Jaccord计算两个文本间的相似度。Jaccord 通过计算文本中词的交集和并集的比值,来计算两个文本之间的相似度。但是基于字符串的方法没有考虑到文本蕴含的特征信息,现有的算法从统计和规则两个方面进行考虑。基于统计的经验主义方法主要是利用统计方法,通过构建文本向量,来计算文本间的相似度。Mikolov T[9]等提出了一系列基于语料库的方法,为文本向量赋予各维度的特征信息。其中最常见的就是利用语料库中的句子进行词向量的训练(如word2vec[10],Golve[11]),通过词向量来计算相似度。由于这种词向量训练模式是基于句子进行训练,而实体的表述方式一般是名词性短句,在句法结构上具有很大的相似性。在某种程度上,相同的句法结构中的词在向量空间中的表述会非常接近,从而造成即使是不同实体的表述,相似度也会非常高。另一种方式是使用TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆向文件频率)[12],对词进行加权。例如,华秀丽[13]等利用TF-IDF 选择特征项,来计算文本的语义相似度。对于基于规则的方法,一般是采用人工构建的知识库,定义知识库中的规则来进行文本相似度的计算。比如彭琦[14]等基于哈尔滨工业大学《同义词词林》扩展版本,利用《同义词词林》作为词语相似度来计算文本相似度。
现阶段主流的多名聚合是基于分类的方式[6],根据训练数据,训练指定模型的参数,然后使用该模型来完成分类的任务。例如DSSM、ConvNet、Tree-LSTM、Siamese LSTM[15~19]都是在对词语或者句子建模的基础上得到词向量或者句向量,来计算文本相似度。但是当数据集是庞大且无标签时,多采用聚类的方式。比如K 均值聚类算法(K-means clustering algorithm)[20],通过挑选初始的中心点,通过算法迭代重置中心点,最后达到类里面的点都足够近,类与类之间的点都足够远。但是K均值聚类算法最大的缺陷就是需要确定中心点的个数。在无法确定簇的数目时,可以使用基于密度聚类算法(Density-Based Spatial Clustering of Application with Noise,DBSCAN)[21],通过确定最小的簇的大小和点之间的距离,自动生成各个簇。
3 方法
本文主要是对论文中作者的所属单位进行多名聚合。整个处理框架如图1 所示,主要分为两个部分,第一部分是数据预处理,第二部分是聚类。
1)数据预处理:对数据集进行数据预处理,去掉特殊字符,同时对论文中作者的所属信息,进行实体词识别,提取出单位,城市和国家的信息。对提取出的单位的信息还需要进行进一步的处理。

图1 处理框架图
2)聚类:对于抽取出来的单位名称,根据单位名称之间的相似度距离,使用DBSCAN[12]进行数据集的划分,形成各个簇。对于形成的各个簇,进行二次聚类。首先使用地域约束对形成的各个簇,进行划分。对划分生成的各个子数据集,使用DBSCAN进行第二次聚类。
本文中主要的创新点在于聚类部分,下面主要介绍聚类部分。
3.1 DBSCAN
DBSCAN(Density-Based Spatial Clustering of Application with Noise)是基于密度的聚类算法,将密度相连的点的最大的集合定义为簇,能够把足够高密度的区域划分为簇,并且能够发现任意形状的簇。通过密度聚类,能够将数据集中的实体表述划分为不同的簇。
DBSCAN[12]可以被定义为

式(1)中C 表示集群的子数据集集合,SD表示应聚类的点P 的数据集,ε是SD中点P 的邻域的最大半径,MinPts 定义簇中的最小点数。其中ε在本文中为两个单位文本表述之间的相似度距离,相似度距离范围大小可调。ε和MinPts是影响DBSCAN聚类过程的两个输入参数。
通过使用DBSCAN,两两计算单位表述之间的相似度距离,可以初步把相似度距离小于ε的单位表述划分到同一个簇中。
3.2 二次聚类
3.2.1 地域约束
在采用聚类算法进行多名聚合时,由于文本附加信息的缺乏,只采用字符串间相似度可能会将存在部分描述一致的不同实体合成同一个簇。基于此,基于密度聚类生成的簇类中,可能存在表述类似,但是属于不同实体的情况。为了进一步区分同一簇里的不同实体,本文旨在引入识别的单位实体所处的地域信息。地域信息可以作为簇中单位表述的附加约束信息,来进一步区分簇中不同的实体。其中地域约束的信息来源于数据预处理中得到的单位与地域信息词典。
如图2 所示,在原始簇中存在多个表述相近的组织1,2,3 等。这类组织由于其表述相近难以用字符串相似度进行区分,但是不同表述的组织实体所处的地域可能不同(如北京大学位于北京,南京大学位于南京,其中北京大学与南京大学的字符串差异仅有一个词)。因此可以利用地域信息将存在同一城市的簇中不同单位实体进行进一步聚合,不同城市的实体进行进一步区分。如组织1与组织2同时都存在与城市A 因此它们为同一实体的概率较大,将这两个组织实体进行进一步合并,其算法实现如下:
算法1:基于地域约束的簇内合并算法
输入簇内组织集合:Sorg
输入簇内组织对应的城市集合:Scity
初始化子簇为C′为空
For i in Size(Sorg)do
isNew=TRUE
for j in Size(C′)do
if Size(city(i)∩city(j))<size(city(i)∪city(j))do
将org(i)合并进入Cj′
city(j)=city(j)∩city(i)
isNew=FALSE
end
if isNew do
为子簇C′创建新元素Cnew′
city(new)=city(j)
end
end
end
输出子簇C′
在算法1 中,每个组织实体org(i)对应一个所属的城市集合city(i)(如分校区的存在可能导致某一大学在不同城市同时存在)。如果两个组织的城市集合间交集与其并集一致,则代表两者的城市集合交集为空。两个组织不在同一城市出现过,因此将其分离。如果两个组织的城市集合间交集与其并集不一致,则两者的城市集合存在公有项,即Size(city(i)∩city(j))<size(city(i)∪city(j))。若两个组织在同一城市存在过,将其合并。通过对组织实体对应的所属城市集合的集合运算能够对簇内的不同实体进行进一步约束,将同一所属地域的组织进行进一步聚合,将不同地域的组织进行进一步分离。
3.2.2 第二次DBSCAN
由于第一次的DBSCAN 聚类受限于实体间相似度距离ε。当ε的值设置较小时,容易将同一实体的不同表述划分为多个簇。这种情况下,消歧结果较差,难以将同一实体的不同表述进行聚合。当ε的值设置比较大时,由于实体间的相似度密度分配不均,容易将距离比较近的不同实体的簇聚合为同一个簇,增大消歧误差。为了保证将同一实体不同表述进行聚合,通常设计的相似度ε往往是比较大的,此时需要解决较大距离时不同实体聚合的消歧误差增大的问题。为了解决这个问题,提出了第二次DBSCAN 聚类。通过设计DBSCAN 中的距离函数,对一次DBSCAN聚类产生的每一个簇进行二次聚类,其距离函数设计如下:
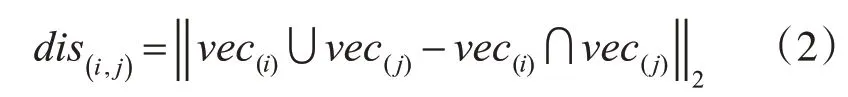
其中i,j 表示两个不同的文本表述,vec(i)表示的文本的向量化。由于二次聚类旨在关注同一簇内两个实体间的差异,因此对两个实体的文本向量表述的非交集部分采用二范数( 二范数:)求取欧式距离。通过将放大实体间的不同表述对实体表述的影响来提高两个不同实体的表述差异,以达到将不同实体分离的结果,减小消歧误差。
4 实验
4.1 实验数据和评估标准
现阶段从120 万篇pubmed 论文的摘要中抽取出来了300 多万条作者所属信息。这些信息进行处理,抽取出作者所属单位,单位所在城市,国家。对抽取出来的单位表述,取最大级别表述。比如一个作者所属单位是301 医院某个科室,我们只取出301 医院作为这个作者所属的单位。因此,本文中实体消除歧义的工作,就是对这些单位实体进行消歧。将300 多万条信息经过数据预处理去重后,得到10 万条不同的单位表述,对其进行聚类。本文中实验结果的衡量标准使用精确度来衡量。
4.2 实验结果
本文中验证了在不同的距离函数下,地域约束和第二次聚类取得的结果。对于实验结果,我们在不同的距离函数下,选取了一些带指定字符串的实体单位名称,第一次聚类参数ε设为0.1 和0.2,距离函数选择分别为Jaccord 相似度系数,TF-IDF 余弦相似度,以及Word2Vec 欧式距离相似度。第二次聚类为地域信息加上二次密度聚类,对第一次聚类的结果进行划分。我们使用人工识别的方法,采用上述的精确度的方法来衡量不同方法的评分数值。
我们选取了4 类实体,指定包含的字符串实体单位名称,如表1。

表1 选取实体类别
筛选出这四类实体,计算对应的精确度。第一次基于不同向量表示函数和二次聚类结果如表2所示。
由于JaccordJaccord 相似度系数函数是将表述存在少量差异的实体名称进行聚合,当实体间的表述差异为少数几个字符串且实体名称较长时,使用Jaccord 将无法进行分离。如“['the affiliated changzhou maternity and child health care hospital of nanjing medical university','the affiliated maternity and child health hospital of nanjing medical university','the affiliated maternity and child health hospital of nanjing medical university wuxi']”。在使用本论文提出的地域约束后能够将存在少量实体表述差异的实体进行分离从而提高衡量标准评分结果。
由于TF-IDF 余弦相似度函数是基于词频权重,将表述存在较多相近关键词的实体名称进行聚合,当不同实体的表述差异在非关键词体现时,则难以将不同实体进行分离。以包含带“university”,“child”,“maternity”,“hospital”字符串的实体单位名称为例子,第一次聚类产生如['no 7 people hospital in zhengzhou','shanghai 7th people hospital','the 7th people hospital','the 7th people hospital of chengdu','the 7th people hospital of shanghai','the dalian 7th people hospital']。由于“people”,“hospital”为表述关键词,因此TF-IDF 将这些不同表述的实体形成了聚合。采用地域约束的方式能够将不同地域的实体进行分离,采用二次聚类能够放大非公有词即使这些非公有词为非高权重关键词,但由于实体间差异同为非高权重关键词,因此能将其进行分类提高衡量标准评分结果。
由于word2vec 欧式距离函数是基于语义的方式将词序相近的不同实体名称聚合。当不同实体的表述差异不体现为词序差异而是少量字符差异时则无法将不同实体进行分离,如:['gongan county people hospital','huichang county people hospital','huidong county people hospital','lianghe county people hospital','linxian county people hospital','qianxi county people hospital','shache county people hospital']。在这一例子中,实体表述皆为名词性短语描述,差异体现在对于名词的定义字符上,因此word2vec 无法将其分离。采用二次聚类能够放大非公有部分来增大实体间差异,从而进行不同实体分离,因此能将其进行分类提高衡量标准评分结果。
基于上述分析,本文提出的方法,采用地域约束的方式能够将不同地域的实体进行分离。在此基础之上,再一次对各个簇进行第二次DBSCAN,能够放大非公有项,增大相近但不一致的实体间差异,从而提高聚类结果的可行性。在本文中,二次聚类主要解决了密度聚类过程中,通过边界点将表述比较相似,但是属于不同实体合并为同一个簇的问题。
5 结语
本文对密度聚类进行了改进,在第一次聚类的结果上,进行二次聚类。二次聚类的过程中,分为两步,第一步是对第一次聚类产生的每个簇进行地域划分。第二步是在经过地域约束处理后产生的新的簇之上,对其进行第二次密度聚类。基于地域约束,将聚类产生的簇中所属不同地域的单位进行进一步的分离,减少由表述相似带来的误差。在基于地域约束产生的结果上,进行第二次密度聚类。设计第二次密度聚类的距离函数,放大实体间的不同表述对实体表述的影响,减少由于密度聚类将不同实体簇聚合成为同一个簇这种情况下带来的消歧误差,结合这两种情况提高聚类结果的准确率。但是在使用地域约束时,对于部分没有附加地域信息的单位表述,会独立划分成新的簇,这是之后需要解决的一个问题。对于文本相似度计算,word2vec 虽然能够解决对单位实体长短表述不一致的问题,但是并不能将长短表述不一致的但是为同一实体的聚合。对于如何将这种长短表述不一致的实体表述进行聚合,有待于进一步的研究和探讨。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
小学阅读指南·低年级版(2017年1期)2017-03-13
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
互联网天地(2016年1期)2016-05-04
中国信息技术教育(2015年21期)2015-09-10
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
