
融合kd tree邻域查询的深度学习点云分类网络
2020-01-06 02:55王旭娇马鹏飞杨立闯王楠楠
深圳大学学报(理工版) 2020年1期
马 杰,王旭娇,马鹏飞,杨立闯,王楠楠
河北工业大学电子信息工程学院,天津 300401
随着科学技术的发展,三维激光扫描仪在数字博物馆、医学可视化和逆向工程等领域都有广泛应用,令人们可以得到各种不同场景和不同对象的原始点云数据[1].作为一种表示三维图形的方法,点云获得了越来越多的关注.目前三维特征提取的方法主要包括基于手工特征的方法、基于投影图像的方法、基于三维体素的方法和基于原始数据的方法.基于手工特征的方法直接在三维形状上提取手工特征,将这些特征作为深度神经网络的输入,用以学习高层特征表示[2-3].该方法的缺点在于过度依赖手工特征的选择和参数优化,且对研究人员的专业知识要求较高.基于投影图像的方法是把三维形状投影到二维图像空间,然后把二维图像输入到深度学习模型中进行特征学习[4-6].此方法充分利用了深度学习在二维图像上的网络架构,但投影操作损失了大量原始结构信息.基于三维体素的方法将三维形状看作三维体素网格中的概率分布,用二值或实值的三维张量表示[7-8].该方法虽完整保留了三维形状信息,但对三维体素的分辨率有限制,体素化结果较为稀疏,要求对网络有合理的设计以避免大量空运算.基于原始数据的方法针对三维形状数据的特点设计特定的神经网络输入层,避免了数据非规则化的问题.如QI等[9]提出的以原始点云为输入的深度神经网络PointNet,为三维形状分类、物体分割和场景语义分割提供了统一的体系结构.但该网络处理的是单个点的样本,忽略了点的局部邻域信息,导致它描述局部特征的能力相对较弱.PointNet++弥补了以上缺陷,使用分层方式处理在度量空间中采样的一组点[10].该网络由多个集合提取层(set abstraction level)组成,每个集合提取层包括采样层、分组层和PointNet层3部分,如图1.采样层在输入数据中选择一组点,作为局部区域的质心;分组层通过寻找每个质心周围的相邻点来构造局部区域集,即子点云.PointNet层使用一个mini-PointNet捕获本地特性,将这些特征聚合为较大的单元,进而计算更高维度的特征.PointNet++网络改进了特征提取方法,增强了局部信息感知能力,但网络训练时间较长,准确率提升效果有限.为此,本研究在集合提取层的分组层引入k维树(k-dimensional tree, kd tree)邻域查询,构建点云索引结构,快速创建子点云,并将这些子点云输入给特征提取层以获得更高维度的表示,再通过引入随机失活(dropout)解决了网络训练过程中出现的过拟合问题.在ModelNet40数据集上的分类结果表明,改进后的网络提高了点云分类能力,也减少了收敛训练时间.

图1 集合提取层的结构
1 邻域查询算法
给定欧氏空间的一组点{Pi|i=1,2,…,n},每个点Pi代表一个(xi,yi,zi)坐标的向量.采样层通过最远点采样从中选择一组点{Qj|j=1,2,…,m},作为局部区域的质心.分组层的作用就是将寻找到的这组质心的相邻点,构造成局部区域集,即子点云.质心Q和相邻点P的距离为
(1)
在PointNet++网络中,分组层的点云邻域查找是一个十分耗时的环节.面对大量无拓扑关系的点云数据,一个高效的数据存取结构能大幅缩减邻域查询时间.PointNet++中采用ball tree进行邻域查询,获取固定半径内的邻域点.ball tree在搜索路径优化时的判断依据是两边之和大于第3边,每次搜索都要计算3次距离,因此在输入数据较大时,时间成本较高.为降低时间成本,引入kd tree邻域查询,因为kd tree在查询时仅需判断两点之间的欧氏距离,处理速度比ball tree更快[11].
kd tree邻域查询需要查找查询点周围固定半径r内的k个近邻点(在实验中会设置k的上限).这里k不是一个固定数值,但是后续的PointNet层能够将其转换为固定长度的局部区域特征向量.算法包括kd tree的构建和查询两方面.
kd tree的构建过程为:
1)确定划分维度和划分点.为保证较好的切分效果及平衡性,选择方差最大的维度开始划分.根据该维度上的点的数值进行排序,取中值点作为划分点对数据进行划分.
2)确定左、右子空间.分割超平面过划分点将整个空间分为两部分,数值小于中值点的划为左子空间,另一部分为右子空间.
3)左、右子空间重复前两个步骤,以相同方式递归地进行分割,直到分割的子空间内点的个数满足条件为止.
图2是本研究构建的三维kd tree结构.

图2 三维kd tree结构
kd tree的查询采用固定半径的查询方法,即搜索查询点在固定半径r内的相邻点.kd tree的查找过程为:
1)从根结点开始,按照查询点与各个结点的比较结果向下访问kd tree,直至达到叶子结点.
2)计算查询点与叶子结点上保存的数据之间的距离,若距离小于r,则记录该点的索引和距离.
3)回溯搜索路径,并判断搜索路径上结点的其他子节点空间中是否有与查询点距离小于r的点,若有,则跳到该子节点空间中去搜索,进行与步骤1)一样的查找过程;否则,继续回溯过程直到搜索路径为空.
2 dropout优化
dropout是一种防止过拟合的正则化方法,其原理为:在一次训练时的迭代中,对每一层中的神经元(总数为N)以概率P随机剔除,用余下的(1-P)×N个神经元所构成的网络来训练本次迭代中的数据.当相对于网络的复杂程度(网络的表达能力和拟合能力)而言数据量过小时,出现过拟合,显然这时各神经元表示的特征相互之间存在许多重复和冗余.在PointNet++具体的训练过程中存在过拟合的现象导致网络运行时间延长.
为有效防止过拟合,减少网络收敛时间,在PointNet++的全连接层的输出加入50%的dropout,即p= 0.5.初始学习率设为0.001,动量momentum为0.9,每次送入网络中训练的一部分样本数量batch size为32.
3 实验及分析
为评估本研究提出的改进分类算法的有效性,在ModelNet40数据集上进行训练和测试,再与原方法对比,并分析测试改进后网络的语义分割性能.实验使用GTX 1060显卡,Ubuntu14.04.5 LTS操作系统,Python(2.7版)和TensorFlow-GPU(1.2.0版).实验所用数据集为用于分类任务的Princeton ModelNet40数据集和用于语义分割任务的斯坦福三维语义分析数据集(Stanford 3D semantic parsing dataset).
3.1 分类实验及结果
分类实验在ModelNet40数据集上进行,该数据集包含了用于训练深度网络的40个类别的12 311个计算机辅助设计(computer aided design, CAD)模型[12].其中,9 843个形状用于训练,其余2 468个形状用于测试.具体实验步骤为:
1)启动Python,下载ModelNet40数据集;
2)训练模型对ModelNet40分类,使用Adam optimizer进行训练,学习率设为0.001,batch size设为32;
3)评估分类的准确率;
4)使用Tensorboard可视化工具查看训练日志.
图3为Tensorboard可视化结果.由图3可见,随着迭代次数的增加,两者的准确度也在以相同趋势增加.值得注意的是,在0~15×103次的迭代中准确率增长明显,之后上升趋势变缓,直至达到4×104次时趋于稳定.
实验还测试了不同的查询半径在ModelNet40测试集中对分类准确率的影响,并与PointNet++作比较,结果如表1.
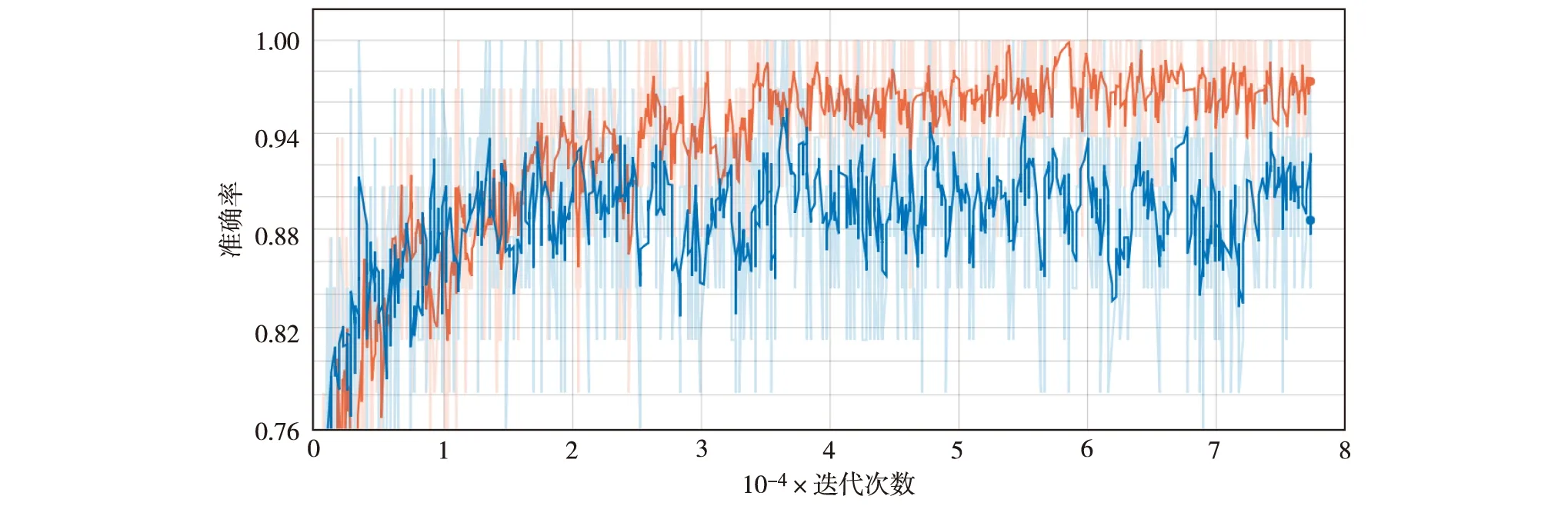
图3 本研究改进算法的训练日志-准确率变化

表1 不同邻域查询方法的分类准确率
由表1可知,改进算法的分类准确率较PointNet++网络有明显提升.随着查询半径增大,捕获的局部特征将更多,分类准确率亦将更高.此外,改进网络的推理时间为64.9 ms,低于原网络的82.4 ms,说明改进后的网络具有更高的分类效率.
3.2 语义分割实验及结果
将改进算法用于整个分类分割的深度学习网络中,并验证其点云语义分割效果.实验在Stanford 3D semantic parsing dataset上进行[13].该数据集包含了6个区域271个房间的3D扫描图像.每个点都由13类语义标签(桌子、椅子、墙壁、地板以及杂物等)中的一类进行标注.实验遵循PointNet训练数据的方式,把点划分成一个个的房间,并将其采样成1 m×1 m的小块,然后训练网络预测每个小块中各点的类别.在训练时,每个block随机抽取4 096个点,而在测试时,使用所有的点进行测试.测试完成后使用点云可视化工具查看结果.图4为场景语义分割预测结果,对比了ground truth、ball tree和kd tree的输出.由图4可见,kd tree的分割效果更接近ground truth,且对遮挡物体具有鲁棒性.

图4 场景语义分割定性对比结果
采用平均交并比(mean intersection over union, MIoU)衡量模型的语义分割性能,并分别对PointNet、PointNet++、SnapNet[14]、DeepPr3SS[15]和本研究改进算法进行场景语义分割实验,得到各自的MIoU值依次为47.7%、52.5%、55.8%、56.1%和57.2%.对比可知,改进模型的分割效果较好.
结 语
提出一种基于kd tree的邻域查询方法,在三维点云上构建kd tree,采用固定半径的方式进行查询,以期提高PointNet++网络的分类准确率.同时,在全连接层增加dropout,避免了网络过拟合现象的出现,减少了训练时间.实验在Ubuntu14.04系统上搭建TensorFlow的GPU深度学习环境,ModelNet40作为测试和训练集完成分类任务.实验结果表明,kd tree的点云分类准确率高于ball tree,且在查询半径为0.3时分类准确率达94.3%,比PointNet++分类准确率高2.5%.对于Stanford 3D semantic parsing dataset语义分割任务,改进后的模型MIoU达到57.2%,优于PointNet++网络.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年7期)2022-07-09
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
