
藏文音节的错误检测方法研究
2020-02-14 05:58王福钊周雁
计算机时代 2020年1期
王福钊 周雁


摘 要: 在藏文信息化处理中,藏文音节的正确拼写是一切工作的基础。文章针对藏文文本中藏文音节的错误自动检测技术进行了研究,以包含62597个藏文音节的50篇新闻稿作为文本语料,研究比较了基于藏文音节构件识别的构件间约束限制匹配和基于全藏字列表的直接匹配这两种方法的藏文音节检错误判率,进而探讨了不同的音节检错方法适用的最佳范围和情况。
关键词: 藏文; 音节; 错误检测; 约束限制匹配; 直接匹配
中图分类号:TP391.4 文獻标识码:A 文章编号:1006-8228(2020)01-05-05
Abstract: In the Tibetan information processing, the correct spelling of Tibetan syllables is the basis of all work. This paper studies the automatic error detection technology of Tibetan syllable in Tibetan text, and uses 50 news articles containing 62,597 Tibetan syllables as text corpus to study and compare the syllable error rate with two methods, i.e., the constraint limited matching between Tibetan syllable components method and the Tibetan syllable full-word list based direct matching method, and then explore the optimal range and situation for different syllable error detection methods to use.
Key words: Tibetan; syllable; error detection; constraint limited matching; direct matching
0 引言
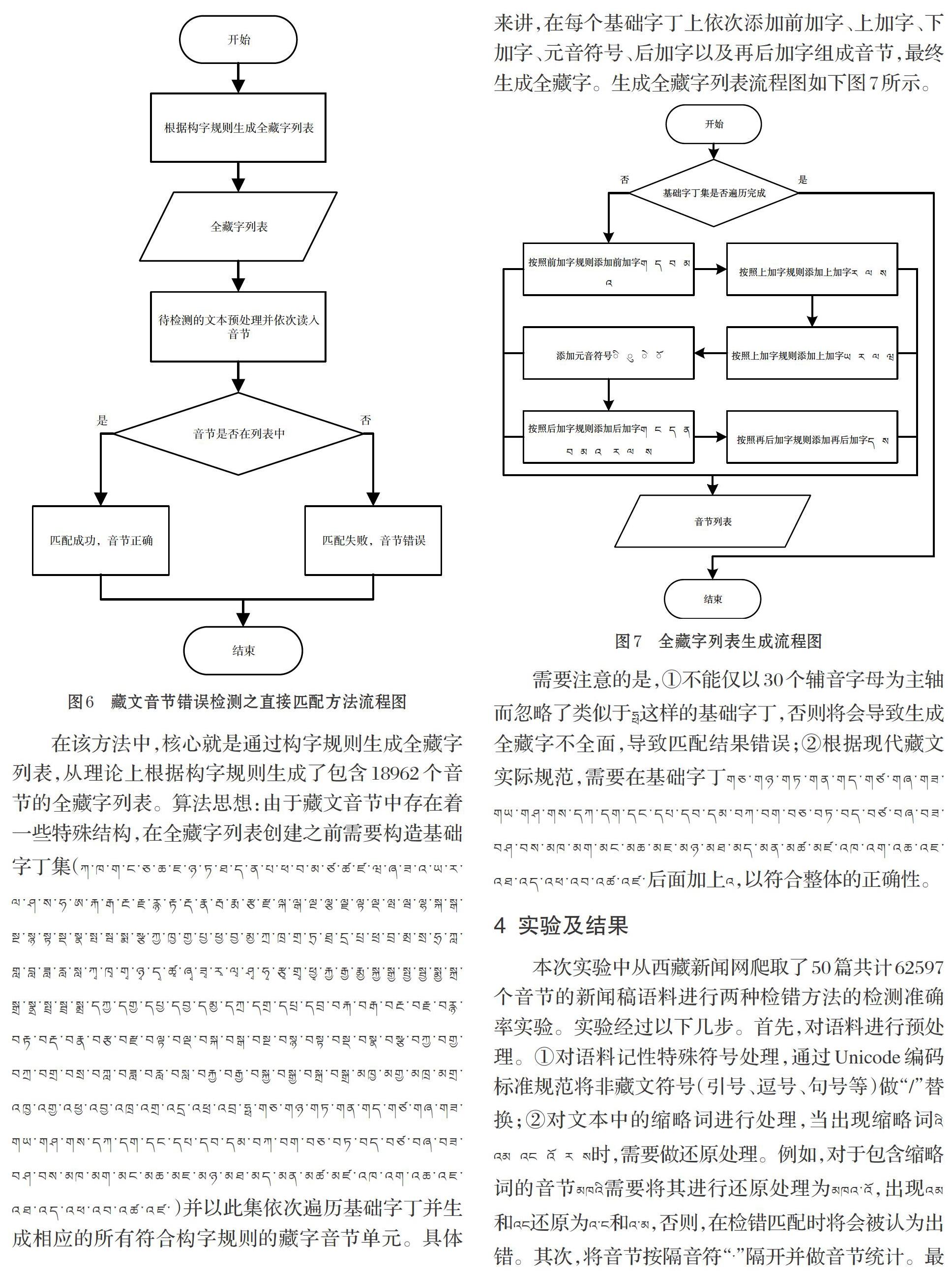
本世纪初,国内藏文信息化处理进入了发展阶段,以中央民族大学、西藏大学、西北民族大学等高校为首的研究机构加大了藏文信息处理的研究,在藏文文字处理上取得了大量成果。藏文是具有悠久历史的古老文字,其可追溯至上古象雄时期,后经过中世纪的发展,至吐蕃王朝第三十三代赞普松赞干布时期,由该时期的著名大臣吐弥桑布扎结合梵文正式创制了这一独特的文字[1]。藏文是藏族人民交流沟通的主要语言文字,是藏文文化传播的重要载体,是经过不断修正完善的中华民族古老文字的重要组成部分。藏语是中华民族语言大家庭中的重要一员,在信息化发展的不断推动下,藏文信息化得到了快速发展。随着藏文信息化的发展,计算机对藏文的处理显得格外重要,计算机中藏文的正确表示和存储是藏文信息处理的基础,是进行藏文分词、词性标注、词频统计等工作的基础。本次研究是从藏文的文本基本组成单元——音节出发,以西藏新闻网的新闻稿件为文本语料,从构字规则上研究并编写计算机程序,实现了藏文音节的拼写错误检测。
1 研究基础
1.1 藏文结构
藏文类似于汉文属于拼音型文字,属于藏汉语系藏缅语族藏语支[2]。从狭义上讲,藏文是指藏语的符号;但就广义上讲,藏文除了符号外还包括藏文文法等[3]。藏文在组成上由30个辅音字母(共8组)和5个元音字母(其中?a为省略不写)组成[1]。具体如表1-表2所示。
藏文的基本组成单元是字母,文本的基本组成单元是藏文音节。另外,藏文音节是字、词、短语和句子的组成基本单元,音节间用隔音符“?”标记隔开,句子分割使用单垂符“?”或双垂符“??”标记隔开。每个藏文音节呈横向-纵向双重叠加的平面字,由30个辅音字母和4个元音字母按照构字规则填补在基字、前加字、上加字、下加字、元音符号、后加字和再后加字中的1~7部分,来进行构成。其中基字必须存在,是整个音节的核心部分。30个辅音字母皆可作为基字。藏字基本结构如图1所示。
基字:30个辅音字母皆可作为基字。
前加字:?????共5个。
上加字:???共3个。
下加字:????共4个。
元音符号:? ? ? ?共4个。
后加字:??????????共10个。
再后加字:??共2个。
前加字约束如表3,其中,? ? ? ? ? ? 6个只能在叠加时才可添加前加字?,其余只需作为基字即可添加相应前加字。对于上加字的添加限制如表4所示。
对于下加字的添加限制如表5所示。
对于再后加字的添加限制如表6所示。
对于后加字而言,? ? ? ? ? ? ? ? ? ? 皆可加在所有的字丁后,但不同的后加字将限制再后加字的出现[1]。还有一些特殊情况,基字+下加字+再下加字的三重叠加体,如???等。
1.2 检错原理
对于藏文音节的错误检测,是根据其构字规则进行规则匹配,匹配与否就是错误与否。对于整篇藏文文本而言,首先对文本进行预处理操作,替换非藏文字符的其他所有符号及进行藏文缩略词的还原,后将文章按照隔音符“?”进行单元隔开,最后通过音节匹配进行错误检测[4-8]。其原理图如图2所示。
猜你喜欢
西藏研究(2021年1期)2021-06-09
布达拉(2020年3期)2020-04-13
快乐作文(1.2年级)(2019年9期)2019-09-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
西藏艺术研究(2017年2期)2018-01-22
作文周刊·小学一年级版(2018年32期)2018-01-15
韩国语教学与研究(2017年1期)2017-11-12
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
中国音乐教育(2014年11期)2014-05-18
