
数据挖掘:C5.0决策树算法在警察院校学生体质分析中的应用
2020-03-02 02:09宋兆铭董如军
四川体育科学 2020年1期
宋兆铭,叶 菁,董如军
数据挖掘:C5.0决策树算法在警察院校学生体质分析中的应用
宋兆铭1,叶 菁2,董如军3
1.四川警察学院,四川 泸州,646000;2.四川化工职业技术学院,四川 泸州,646000; 3.广东警官学院,广东 广州,510230。
C5.0决策树算法适用于大数据集处理,特别是它的Boosting集成机器学习算法可以有效地将精度较低的“弱学习算法”提升为精度较高的“强学习算法”,从而达到模型修剪与优化的目的。研究结果表明:C5.0决策树算法生成的模型可以精确地评价学生的体质健康状况(97.8%)且模型预测的泛化能力较强(98.1%)。因此,C5.0决策树算法可以用来判断影响警察院校学生体质测试成绩的关键因素,为深层挖掘相关警务数据内涵与监测提供了实证依据。
C5.0决策树;警察院校;学生体质
我国警察院校的学生体质监测工作自1985年始已经进行了30多年,建立了体量巨大的体质信息数据库。面对海量的数据,如何探寻简便有效的分析方法对体质状况精确、快速、直观地给出反馈,一直是对警务培训研究者的重大考验。当前对警察院校学生体质数据的分析,主要还是使用一般性的现状描述和传统的相关性检验的统计分析方法,缺乏深层次的数据挖掘研究和决策分析,更无法发现测试数据中隐含着的重要结论[1]。因此,利用好耗费大量人力、财力采集的学生体质测试数据,深层挖掘数据的内涵,得出更多更精确的结论来为监测工作服务,是每一位警务培训研究者的重要任务。同时,如何根据简单测量指标判断体质状况也是目前警务培训数据分析中的一个重要课题。值得庆幸得是,决策分析技术的出现使得这一课题有了重大的突破,基于决策分析的方法,可以根据身高、体重等一些简单的体质指标快速判断学生体质的关键影响因素。
丁亚芝等[1]以新疆师范大学学生体质测试数据为例,引入趋势选择的概念,将TESTSPRINT算法应用于体质测试数据分析中,该研究结合了先进的数据挖掘算法,提高了精确性,在一定程度上达到了监测学生体质的目的。但同时,TESTSPRINT算法也存在以下一些缺点,导致该方法在大量数据分析和数值型数据分析中的效果还有待提高:(1)使用属性列表,使存储代价是原来的三倍;(2)节点分割要创建哈希表,加大系统负担;(3)节点分割处理相对复杂。于岱峰等[2]以人体握力肌肉力量测试数据研究为例,将ID3算法应用于人体肌肉力量数据分析中,为选择人体握力Gain(K3)指标作为评价人体握力肌肉力量指标,提供了科学依据。但同时,虽然ID3算法具有理论清晰,方法简单,学习能力较强等优点,但它只对比较小的数据集有效,且对噪声比较敏感,当训练数据集加大时,决策树可能会随之改变。李伟平[3]等采用K-Means快速聚类法、序列关联规则、贝叶斯网络、QUEST决策树、C&R决策树、CHAD决策树、支持向量机(SVM)和神经网络等数据挖掘技术,对西安市城镇居民体育消费入户调查数据进行了实证分析。同时,通过对这几个模型评估效果的比对,李伟平等认为C5.0模型的解释性、正确率为最高。
因此,本研究在总结前人算法引进不足之处的基础上,提出引入在执行效率和内存使用方面进行了改进的C5.0算法,并以S警察学院学生体质监测数据为分析对象,定量分析我国警察院校学生体质健康水平的关键影响因素。旨在引起上级主管部门对学生体质健康水平的重视,为以学校为基础的干预措施提供科学依据,为我国警察院校体育课程的改革提供实证参考。
1 C5.0算法
1.1 算法简介
C5.0是决策树模型中的经典算法[5]。决策树模型是一个预测模型,它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象,树的叶子节点表示对象所属的预测结果。决策树模型的建立通常包括特征选择、决策树的生成和修剪3个步骤[4-8]。
J R Quinlan于1979年提出了ID3算法,主要针对离散型属性数据,其后又不断的改进形成C4.5,它在ID3基础上增加了对连续属性的离散化[7-8]。为了适应处理大规模数据集的需要,后来又提出了若干改进的算法,其中SLIQ(super-vised learning in quest)[3]和SPRINT (Scalable Parallelizable Induction of Decision Trees)[1,9]是比较有代表性的两个算法。C5.0算法则是C4.5算法的修订版,适用于处理大数据集,同时它增加了强大的Boosting算法提高了分类精度[10]。Boosting算法依次建立一系列决策树,后建立的决策树重点考虑以前被错分、漏分的数据,最后生成更准确的决策树且计算速度比较快,占用的内存资源较少。Boosting算法作为一种新的集成机器学习方法,以学习理论为依据,可以有效地将精度较低的“弱学习算法”提升为精度较高的“强学习算法”,从而达到模型修剪与优化的目的[11-12]。
1.2 基本概念
C5.0决策树的生长过程采用的是最大信息增益率的原则进行节点选择和分裂点的选择,具体涉及的基本概念有:
信息熵:信息杂乱程度,信息越杂乱(越不纯),则信息熵越大;反之,信息熵越小[4-5]。其公式为:
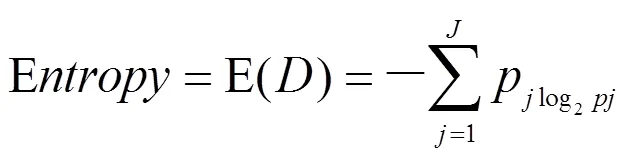
其中-log2(pj)反应的是信息量,即某随机事件发生的概率越小,则信息量越大;反之概率越大,则信息量越小。所以信息熵就是指事件发生的概率(pj)乘以其对应的信息量(-log2(pj)),然后再加总。
信息增益(Info Gain):分裂前的节点熵减去分裂后子节点熵的加权和,即不纯度的减少量,也就是纯度的增加量。其中,参数选择的规则是选择使信息增益最大的参数分割该节点[4-5]。其公式为:

其中,Info为Y变量的信息熵,InfoA为自变量A对Y变量分割的信息熵。其公式为:
由于信息增益选择偏向于取值多的属性(参数的取值越多,其分割后的子节点纯度可能越高)。C5.0采用了信息增益率的方法,对那些水平比较少的离散变量进行平衡处理[4-5]。其公式为:
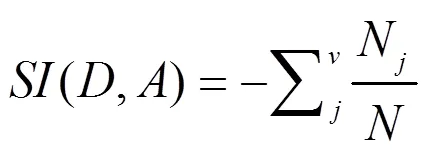
其中,为分割信息(自变量的信息熵);信息增益率就是在信息增值的基础上除以自变量的信息熵。
1.3 模型建立
C5.0决策树模型第一次拆分确定的样本子集随后再次拆分,通常是根据另一个字段进行拆分,这一过程重复进行直到样本子集不能在被拆分为止。最后,关注最低层次的拆分,那些对模型值没有显著贡献的样本子集被提出或者修剪。主要分为以下四个步骤[4-5]:
第1步,对数据进行预处理,将连续型的属性变量进行离散化处理形成决策树的训练集(分类属性忽略)。
第2步,计算每个属性的信息增益和信息增益率。
第3步,根节点属性每一个可能的取值对应一个子集,对样本子集递归地执行第二步过程,直到划分的每个子集中的观测数据在分类属性上取值都相同,生成决策树。
第4步,根据构造的决策树提取分类规则,对新的数据集进行分类。
具体计算过程如下:
(4)类别的信息熵:
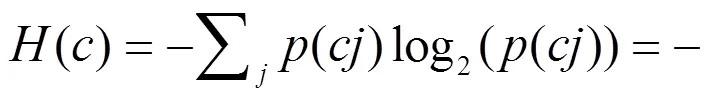
(5)类别的条件熵:
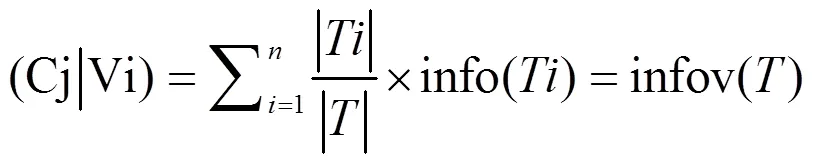
(6)信息增益(Gain):
(7)属性V的信息熵:
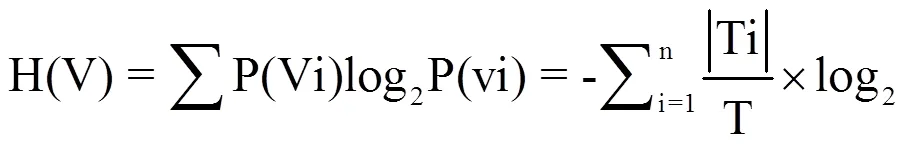
(8)信息增益率:
gain_ratio=I(c,v)/H(V)=gain(V)/split_info(V)
最后,通过比较各个属性的信息增益率即可确定决策树的节点,重复以上过程,最终得出属性分类的决策树。
2 实例分析
2.1 数据来源
按照《国家学生体质健康标准》[13]的规定,对四川警察学院所有在校大学生进行了体质监测测试,测试过程严格按照测试的操作方法要求完成。测试以年级为单位分别安排在2018年12月每周日(4、11、18、25)上午8:30-11:30、下午14: 30-17:30 两个时间段。测试人员均为经培训后的四川警察学院警体教师,现场测试技术规范并有巡视组监督检查,测试质量符合规定要求。数据汇总后按性别分为两类样本,有效样本量见表1。

表1 研究对象基本信息一览表
2.2 分析变量
按照《国家学生体质健康标准》[11]的规定测试的指标,本研究分析变量主要分为身体形态、机能、素质指标,BMI指数,具体赋值与说明见表2。

表2 变量选择与赋值
注:由于男女生测试项目不同,所以分别建模分析。
2.3 统计分析
采用Excel2010进行数据的录入与整理。数据分析采用R3.4.2完成,决策树建立应用“C50”软件包及相关函数完成。
(1)导入数据集,连续变量离散化代码命令和运行结果如图1:
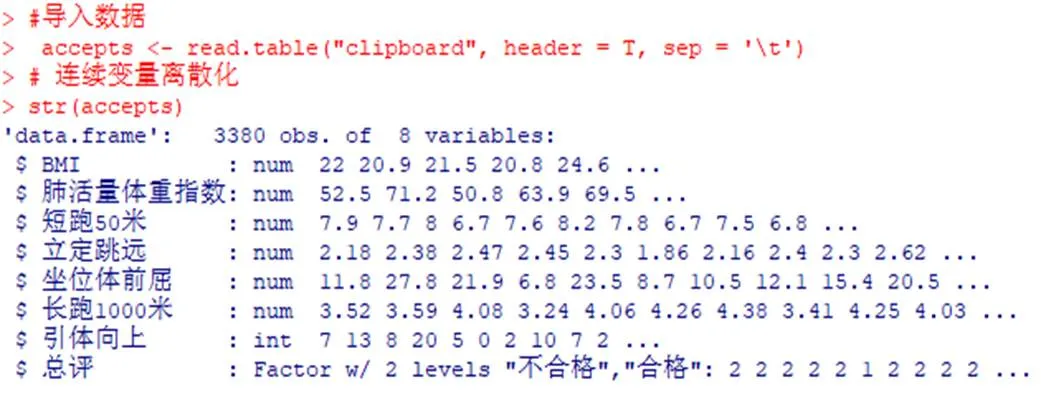
图1 数据导入、变量离散化代码运行结果图
(2)随机抽样,将数据分为训练集和测试集。运行结果如图2:

图2 数据拆分代码运行结果图
(3)运行C50算法建模代码,查看预测的结果,构建混淆矩阵,计算模型的在训练集预测准确率。运行结果如图3:

图3 C50算法建模代码运行结果图
图3表明通过训练数据测试,模型的预测准确性为97.8%,模型在测试集上有较好的预测效果。
(4)计算模型在测试集预测准确率。运行结果如图4:

图4 测试集预测准确率代码运行结果图
图4表明通过测试集数据测试,模型的预测准确性为98.1%,模型有较好的泛化效果。
(5)图形展示:plot(model)。
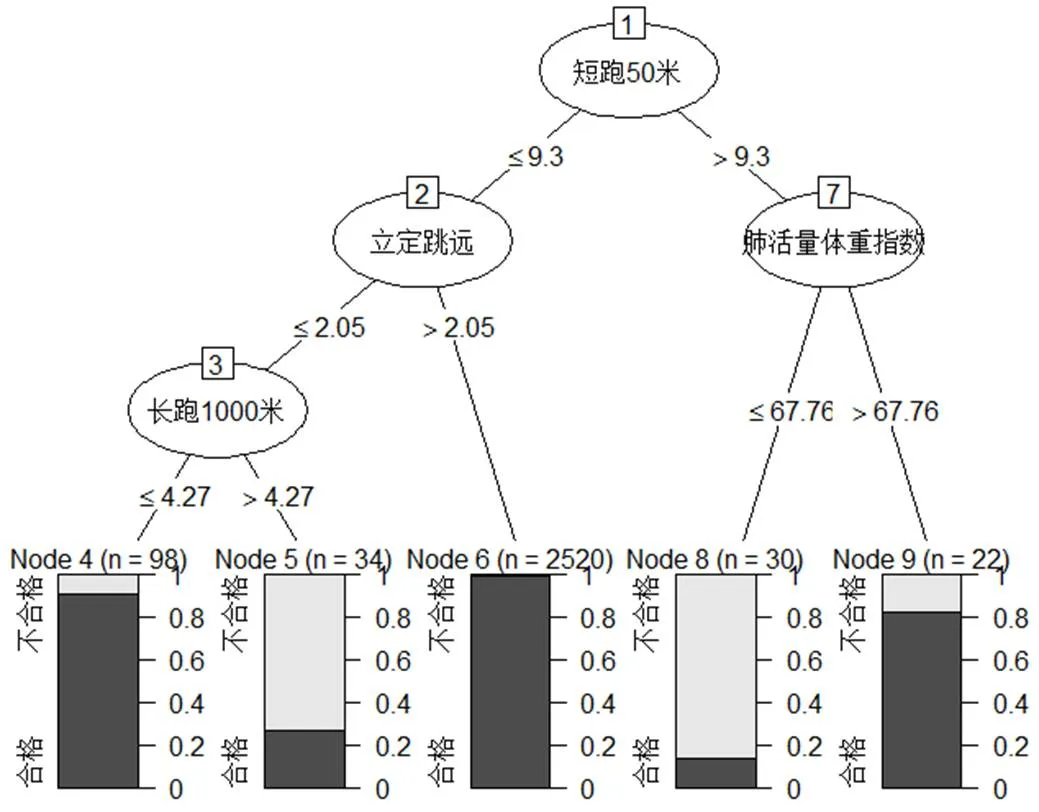
图5 男生决策树图形代码运行结果图
从图5可以出,学生的体质测试成绩是否合格的关键因素有:“短跑50m”“肺活量体重指数”“立定跳远”和“长跑1000m”。(1)首先,“短跑50m”这一指标处于树的根部,即:学生体测成绩合格还是不合格,最关键的影响因素是学生短跑能力的强弱(节点1);(2)依据学生短跑能力的强弱(9.3s),第二层节点分别是“肺活量体重指数(节点2)”和“立定跳远(节点7)”。其中,反映学生呼吸系统机能状况的肺活量体重指数如果大于67.76 ml/kg,则学生的体测成绩合格率较高,反之则合格率较低;反映学生下肢力量与爆发力的发展水平的立定跳远成绩如果大于2.05m,那么学生的体测成绩合格率较高,反之则应进一步考查长跑1000m的测试成绩来判定总评成绩是否合格;(3)长跑1000m是反映学生坚持长时间运动的能力,如果长跑1000m成绩小于4.27min,则学生的体测成绩合格率较高,反之则合格率较低。
综上所述,如果学生的短距离快速运动的能力强,下肢力量与爆发力的发展水平高,则其体测合格的可能性最高。如果学生的短距离快速运动和坚持长时间快速运动的能力强,则其体测合格的可能性最高为其次。如果学生短距离快速运动的能力较弱,但其呼吸系统机能能力较好,则其体测合格的可能性也相对较高。但如果学生的短距离快速运动的能力较弱、下肢力量与爆发力的发展水平较低、坚持长时间快速运动的能力也较差,则其体测合格的可能性较低;特别是呼吸系统机能能力差的学生其体测合格的可能性为最低。因此,我们应积极进行警察体能课程教学改革,在课程开始前应对学生体质健康水平进行评估,并依据评估结果,在尊重学生个体差异的原则下开展分层教学,使不同层次学生得到有针对性的教法指导,从而有效提升学生的体质健康水平。
3 结论与展望
3.1 主要结论
本文利用C5.0算法对S警察学院学生体质测试成绩的影响因素开展了有数据支撑的定量研究,判断了影响学生体质测试成绩的关键因素,为深层挖掘学生体质测试数据内涵、监测学生体质提供了实证依据。主要结论有:(1)C5.0算法生成的决策树模型可以运用简单的体质监测的指标精确地评价学生的体质健康状况(98.4%)且模型预测的泛化能较强(98.2%)。(2)学生的体质测试成绩是否合格的关键影响因素有:“短跑50m”“肺活量体重指数”“立定跳远”和“长跑1000m”。(3)在警察体能课程教学中,我们要注重发展学生的下肢力量与爆发力、短距离快速运动的能力和长时间快速运动的能力;同时,要特别注重学生呼吸系统机能能力的提高,从而精确有效地提高学生体测的合格率。
3.2 研究展望
我国国民体质监测数据已呈现出不同地理位置上的数据共享,数据库系统的数据量的增加将导致未来国民体质数据分析必须采用分布式海量数据计算方法。因此,如何借助数据挖掘技术从庞大的数据中识别数据内部的联系,去伪存真,从中提取有用的信息,为体质监测和相关警务培训决策提供支持是极具意义的研究课题。同时,由于各种数据挖掘方法各有利弊,其理论和算法本身也正在不断的扩展和提升之中。所以,要得出更多更精确的结论还需要更多地致力于数据挖掘算法及其在体质数据分析中的应用研究。
[1] 丁亚芝,郑志高,马 嵘.改进的SPRINT算法及其在体质数据分析中的应用[J].体育科学,2014,34(06):90~96.
[2] 于岱峰,钟亚平,于亚光.基于数据挖掘技术在人体肌肉力量数据分析中的应用——以人体握力肌肉力量测试数据研究为例[J].体育科学,2010,30(02):70~74+82.
[3] 李伟平,权德庆,蔡 军,魏 华,雷 文. 西安市城镇居民体育消费结构及其特征研究——基于数据挖掘的视角[J]. 体育科学,2013,33(09):22~28.
[4] JiaweiHan, MichelineKamber, JianPei,等. 数据挖掘:概念与技术[M]. 机械工业出版社,2012.:162~171.
[5] PANG-NINGTAN, MICHAELSTEINBACH, VIPINKUMAR. 数据挖掘导论:完整版[M].人民邮电出版社,2011:89~122.
[6] http://127.0.0.1:23641/library/C50/doc/C5.0.html.
[7] Quinlan J R. C4.5: programs for machine learning[M]. Morgan Kaufmann Publishers Inc. 1993.
[8] Max Kuhn, Steve Weston. C50: C5.0 Decision Trees and Rule-Based Models[J]. 2012.
[9] 王云飞. SPRINT分类算法的改进[J]. 科学技术与工程,2008,8(23):6248~6252.
[10] 刘迷迷,刘永佳,温 丽,蔡 巧,李丽婷,蔡永铭.C 5.0决策树对早期胃癌风险筛查研究[J].中华肿瘤防治杂志,2018,25(16):1131~1135.
[11] 张 宇,张之明. 一种基于C5.0决策树的客户流失预测模型研究[J]. 统计与信息论坛,2015,30(01):89~94.
[12] 杨剑锋,乔佩蕊,李永梅,王 宁.机器学习分类问题及算法研究综述[J].统计与决策,2019,35(06):36~40.
[13] http://www.csh.edu.cn/wtzx/bz/20141226/2c909e854a84301a014a8433fc500003.html
Research of Data-mining in Police Training: The Application of C5.0 Decision Tree to Students ' Constitution in Police Colleges
SONG Zhaoming1, YE Jing2, DONG Rujun3
1.Sichuan Police College, Luzhou Sichuan, 646000, China; 2.Sichuan Vocational College of Chemical Technology, Luzhou Sichuan, 646000, China; 3.Guangdong Police College, Guangzhou Guangdong, 510230, China.
The C5.0 Decision Tree can be used for large data sets. Due to the addition of Boosting, The C5.0 Decision Tree can get better models. Booting optimizes the model by effectively improving the less accurate “weak learning algorithm” to a more accurate “strong learning algorithm.”Result: The decision tree model generated by C5.0 algorithm can accurately evaluate students' physical health status (98.4%) with simple physical monitoring indicators and the generalization of model prediction can be strong (98.2%). Conclusion: The C5 .0 algorithm can be used to determine the key factors physical test results, to deeply dig Students ' Constitution data and monitor its changes in Police Colleges.
C5.0 Decision Tree; Students ' Constitution; Police Colleges
G804.49
A
1007―6891(2020)01―0052―04
10.13932/j.cnki.sctykx.2020.01.11
2019-06-17
2019-07-29
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
雷达学报(2017年6期)2017-03-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
振动工程学报(2015年1期)2015-03-01
郑州大学学报(医学版)(2015年1期)2015-02-27
郑州大学学报(理学版)(2014年2期)2014-03-01
