
基于Adam-BNDNN的网络入侵检测模型
2020-03-09 13:12
计算机测量与控制 2020年2期
(西南科技大学 计算机科学与技术学院,四川 绵阳 621010)
0 引言
入侵检测系统(intrusion detection system,IDS)是计算机网络中一种主动防御的成果,它为人类工作和生活提供安全保护。此前,许多学者提出了一些典型的IDS;文献[1]结合改进的KNN和Kmeans实现I2K用于入侵检测,结果表明该算法具备良好的检测率和新攻击识别能力,但检测速度仍有待提升;文献[2]提出一种结合多目标优化理论的克隆选择算法,其能有效改善种群进化效率,增加种群多样性,进而提高检测率,但对于样本容量较大时,检测效率仍然比较低;文献[3]先用信息增益(IG)对网络数据进行特征提取,再用主成分分析(PCA)进行数据降维,最后用Naive Bayes来完成入侵分类检测,该方法虽然检测率高于KPCA、FPCA、PCA-LDA,但并未提高对各攻击的检测率。文献[4]使用自适应SSO的分组过滤方法来完成入侵检测,虽然在不降低网络安全性的前提下,能有效减轻基于签名的入侵检测系统的负担,但在黑名单分组过滤签名匹配时还是消耗了较多时间。
随着大数据时代到来,网络数据的数量增多、格式多变、网络入侵行为多样化等,传统网络入侵检测模型面临着检测精度低、误报率高等问题。而近年来深度学习的兴起,基于深度学习的IDS也慢慢开始得到应用。文献[5]利用独热编码对网络包进行编码形成二维数据,再用GoogLeNet进行特征提取并训练Softmax分类器,其在检测精度、漏检率和误检率等都有很大提升;文献[6]结合深度学习理论和神经网络的极限学习机,提出一种自编码器-极限学习机入侵检测模型;用MODBUS数据集进行仿真实验,结果表明其优于SVM、ELM、DBN、MLP、K-Means,符合网络入侵检测“高精度,低误报率”的检测要求。而本文结合DNN优异的特征学习能力、BN的规范化数据处理和Adam自适应梯度优化方法,提出了一种基于Adam-BNDNN的入侵检测模型。
1 DNN概述
深层神经网络(deep neural network,DNN)属第三代人工神经网络,它具有1个输入层,1个输出层和n个隐含层,结构如图1 所示,在数据量大的情况下可以计算得更快,花费更少的代价[7]。

图1 DNN网络结构图
DNN同样和分为前向和后向。首先对权值W和阈值b进行初始化,前向时数据通过预处理后从输入层经n个隐含层计算后传入输出层,输出层激活后的输出结果与期望结果进行对比得到误差,误差再以梯度下降的方式从输出层经隐含层回传至输入层,以此便完成了一轮神经网络的训练。
1.1 He初始化权值
初始化时一般将阈值b初始化为0,传统神经网络权值初始化常用初始化为0和随机初始化,但W初始化为0会出现每一层的学习能力相同,因而整个网络的学习能力也有限;而随机初始化实质上是一个均值为0方差为1高斯分布,若神经网络层数增加,则会出现后面层激活函数的输出值接近0,进而可能产生梯度消失。
而现在常用的权值初始化有Xavier初始化、He初始化等。Xavier初始化中输入和输出都被控制在一定范围内,激活函数的值都尽量远离0,则不会出现梯度过小的问题,公式如式(1):
(1)
但是Xavier对于激活函数ReLU不太适合,在更深层的ReLU中,激活函数的输出明显接近0,所以Xavier一般用于Sigmiod和Tanh。
而He初始化的出现解决了ReLU的问题,此方法基本思想是正向传播时,激活值方差不产生变化,回传时,激活值梯度方差不产生变化;对于ReLU和Leaky ReLU有不同的初始化方法,ReLU适用于公式(2),Leaky ReLU适用于公式(3),本文采用的便是基于ReLU的He初始化方法。
(2)
(3)
1.2 ReLU和Softmax激活函数
激活函数的选择会对模型收敛速度、训练时间产生非常大的影响。之前常用的激活函数有Sigmoid以及Tanh,Sigmoid将输出结果规约到0~1之间,Tanh规约到-1~1之间,在隐层中相较而言Tanh要优于Sigmoid,因为Tanh的均值为0,关于原点对称,具有对称性;但两者在训练时都容易造成两端饱和使得导数趋于零,以致权重无法更新最终造成梯度消失;而RuLU左边是抑制的,右边是有梯度的,一般不会造成梯度消失,因为神经网络的输入数据一般都大于0;且RuLU具有更快的计算速度和收敛速度,因此隐藏层使用RuLU比前两者更好。3种激活函数的输出图像如图2所示。

图2 Sigmoid-Tanh-Softmax函数图像
输出层通常采用Sigmoid函数或Softmax函数将输出层的输出结果归约到0~1之间,如公式(4)和(5):
(4)
(5)
其中,Sigmoid将输出层每一个输出节点的结果归约到0~1之间,故输出节点间的输出结果相互是独立的,且总和可能为1可能不为1;而Softmax输出层中每一个输出节点的结果是相互紧密关联的,其概率的总和永远为1。由于本模型采用One-hot来编码分类结果,在输出层时选用Softmax分类器较为方便。
1.3 Mini-batch梯度下降
神经网络以梯度下降的方式来更新参数。在参数更新中,若使用整个数据集进行梯度下降,W和b每次更新都在整个数据集一次训练完以后,这样可能不利于鲁棒性收敛,有可能造成局部最优;如果一次只用1个样本进行训练,W和b更新太频繁,整个训练的过程也会很长。
而介于两者之间的Mini-batch,把整个数据集随机分为Mini-batch的Size大小,W和b更新是在每个小批量后,且每次小批量训练的数据更具有随机性,这样可以使得模型梯度下降参数更新更快,避免局部最优,同时加速模型的训练。
2 模型设计
2.1 Adam-BNDNN的检测模型
本文检测模型主要分3个模块,结构如图3所示。

图3 基于Adam-BNDNN的入侵检测模型
数据获取和预处理模块:获取网络数据集,并对其进行特征提取、数值转换、数据归一化等预处理操作,使其满足输入数据的要求;并将其分为训练集和测试集,分别用于模型训练和模型测试。
入侵检测模块:结合预处理后数据的维度确定Adam-BNDNN网络的输入输出节点,再根据隐层和其他参数从而确定整个网络结构和训练参数,用训练集对模型进行训练,完成训练后保存模型用于测试。
检测分类模块:测试集使用保存的模型进行测试,并将检测分类结果展示给用户。
2.2 BN批量规范化优化
Batch Normalization[8](BN)是近些年以来深度学习的一个重要发现,其应用在隐藏层,经常同Mini-batch一起使用。主要将每个隐层的输出结果进行归一化处理再进入下一个隐层,但并不是简单的归一化,而是进行变换重构,引入λ、β这2个可学习的参数,如公式(6):
(6)
引入参数后,网络即可学习出原始网络所需的特征信息;BN操作如图4所示。

图4 BN操作结构图
批量规范化(BN)操作流程:
1)数据先从输入层输入,经隐含层激活计算后得到激活值。
2)对隐含层激活值做批量规范化可以理解成在隐层后加入了一个BN操作层,这个操作先让激活值变成了均值为0,方差为1的正态分布,即将其归约到0~1之间,最后用γ和β进行尺度变换和偏移得到网络的特征信息。
3)数据完成BN后再进入下一隐层。
BN的使用降低了初始化要求,可使用较大学习率,也使神经网络的隐含层增强了相互间的独立性,同时增大了反向传播的梯度,进而避免了梯度消失的问题;且和Dropout一样具有防过拟合的正则化效果。
2.3 Adam梯度下降优化
神经网络传统的随机梯度下降(SGD)缺点是很难选择一个比较合适的学习率,同时收敛速度也很慢,且容易达到局部最优。而以梯度下降为基础的Adam优化算法[9],结合了RMSProp优化算法和Momentum优化算法。
RMSProp中神经网络在训练时可自动调整学习率,不用过多的人为调整;而Momentum则是调整梯度方向,使得在训练时加速梯度下降的速度,从而加快训练过程。参数更新如公式(7):
(7)

(8)
其中:α、β1、β2、ε都有缺省值,也可以自行调整。
2.4 L2正则化
在网络的训练过程中若数据过少或者训练过度则可能会产生过拟合现象,而正则化可以在学习中降低模型的复杂度,从而避免过拟合。正则化实质在损失函数中添加了正则项,对损失函数的参数做一些限制;一般有L1和L2正则化,本文选用L2正则化,L2正则化对b更新无影响,对w更新有影响;拿逻辑回归为例,公式如(9)所示:
(9)

3 数据集选取和处理
3.1 实验数据集选取
实验选取的是NSL_KDD数据集[10],它是KDD CUP数据的浓缩版,其在KDD CUP数据集的基础上进行的改进有:
1)KDD中冗余数据的去除:使分类结果不会偏向更频繁的记录。
2)KDD中重复数据的去除:使检测更加准确。
3)数据集大小更合理:KDD共有500万左右条数据,数据总量多且冗余、重复数据多,可能会造成检测结果不理想以及训练时间过长。而NSL数据集总量125973条,正常和各异常数据占比也符合真实网络情况,用于训练的时间也不会太长。
NSL一共有41维属性特征和1维标志特征,具体信息如表1所示。

表1 NSL数据的属性信息
3.2 数据预处理
3.2.1 特征提取
在NSL数据集的41维属性特征中,每一维属性特征对结果的影响都是不一样的,为了合理选取网络数据的属性参数,文献[11]选取了12个属性特征,文献[12]选取了14个属性特征;文献[13]选取了15个属性特征;本文结合2种特征选取技术综合考量后最终选择21个最优特征属性,如表2所示。

表2 NSL数据集21个属性选取
3.2.2 数值化
21维属性特征选取完以后,其中Protocol type、Service、Flag和Label是离散型数据,对离散型数据首先应数值化;
在Protocol type中,共有Tcp、Udp、Icmp三种协议类型,分别用数字1、2、3代替;
Service中共有70种服务名称,分别用数字1~70代替;
Flag中共有11种网络连接状态,分别用数字1~11代替;
最后是Label标志的数值化,Label共有5种,分别标识Nor、Pro、Dos、U2r、R2l,为了便于后面检测的分类工作,在数值化时使用One-hot进行编码,如Normal编码为10000。
3.2.3 归一化
NSL数据经数值化后,有些数值区间较大,各特征间差异也大,若不经处理就做输入数据,可能会使训练结果偏向更大的数,继而对训练速度和精度也会有一定的影响。为了避免上述情况发生,一般使用公式(10)将其归一化到0~1之间,
(10)
归一化后一方面能提升模型收敛速度,另一方面提升模型的精度。
3.3 训练集和测试集的划分
NSL数据进行预处理以后,随机取其2/3做训练集,剩下1/3做测试集,如表3所示。检测评价标准是2分类检测结果和5分类检测结果的准确率以及误报率。

表3 训练集和测试集划分
4 实验与对比分析
4.1 实验参数选取
在数据预处理中选择21维属性特征,5维One-hot编码标志特征,则Adam-BNDNN对应的输入为21个节点,输出为5个节点。
为了选择模型训练合适的Epoch,以3隐层Adam-BNDNN网络21-50-30-20-5为例,选取总迭代次数200次,迭代Epoch和对应的代价Loss如图5所示。

图5 迭代Epoch和代价Loss曲线图
结果显示:在迭代100次以后,网络的训练代价趋于平缓。在迭代次数选取时,若迭代次数过少,则会造成训练不足,若迭代次数过多也有可能会造成过拟合。因此,在模型训练中,选取的迭代Epoch为100次。
接着是神经网络隐层数选择。为了选择合适的隐层数量,分别选取隐层数为1~5的5种不同网络结构5分类的平均准确率,网络结构如表4所示。

表4 Adam-BNDNN网络的不同隐层数结构
经实验得出,隐层数为3和4时整体检测率差不多,但4隐层时U2r和R2l的检测率低于3隐层,隐层数为5时精度大幅度下降,综合考量则最合适的隐层数为3。
确定了网络的Epoch和网络结构后,Adam-BNDNN所有参数设置如表5所示。

表5 Adam-BNDNN参数
4.2 实验结果及分析
用NSL-KDD数据集仿真实验后,分别使用2分类检测结果和5分类检测结果的准确率以及误报率来评估模型的检测性能,结果如表6所示。
为了验证模型的检测效果,分别用浅层神经网络(SNN),K最近邻(KNN),深层神经网络(DNN)、Alpha-OSELM[13]与本文做对比,2分类结果如表7所示,5分类结果如表8所示。
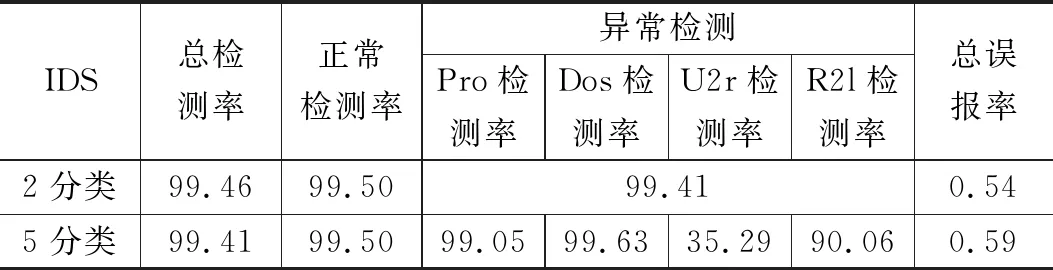
表6 Adam-BNDNN模型检测的分类结果 %
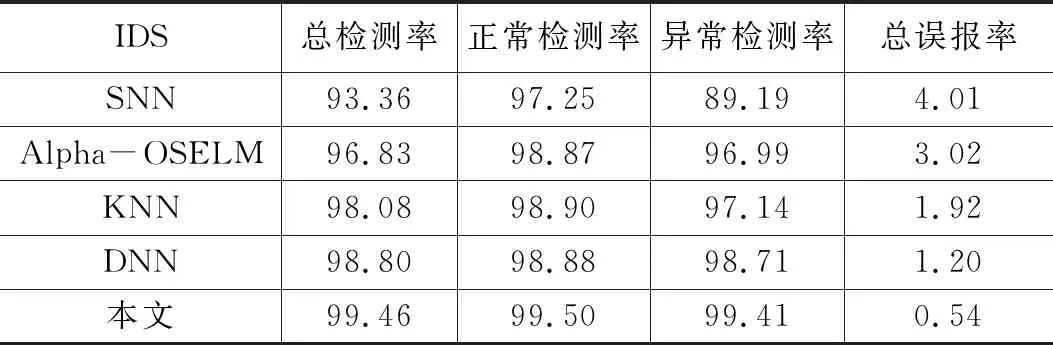
表7 各IDS的2分类结果 %

表8 各IDS的5分类结果 %
从表6可以看出,2分类的整体检测率要比5分类高,整体误报率要比5分类低。因为在2分类检测中,若类型为R2l的攻击误检为U2l,对于2分类检测结果是正确的,但在5分类检测中则是错误的。
从表7,表8可以看出本文检测模型的整体检测率要优于其他IDS,整体误报率要低于其他IDS。但5分类中U2r的检测结果并不是很好,主要因为在125973条样本数据中U2r只有52条,数据总量过于少,检测率没有其他4类高也是可以理解的;总体上证明了检测模型的可行性。
5 总结
针对传统入侵检测算法对网络入侵检测能力不足的问题,本文结合网络流量数据的特性,提出一个基于Adam-BNDNN的网络入侵检测模型,用属性简约后的NSL-KDD数据集来仿真实验,并与其他算法进行了对比分析,从而证明本模型的可行性。下一步工作将搭建真实网络环境,采集实时数据进行网络入侵检测。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
九江学院学报(自然科学版)(2022年2期)2022-07-02
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
软件(2017年6期)2017-09-23
