
基于LSTM的辅助动力装置系统辨识与仿真
2020-03-09 13:12
计算机测量与控制 2020年2期
(深圳航空有限责任公司 沈阳分公司维修工程部,沈阳 110000)
0 引言
辅助动力装置(APU)是飞机上的一个小型的燃气涡轮发动机。其功能是在地面或者飞行中为飞机的空调系统及用电设备提供引气和电力供应,是飞机不可缺少的子系统。对APU进行参数辨识对飞机仿真建模具有重要研究意义[1]。
系统辨识是根据系统的输入输出函数来确定描述系统行为的数学模型,系统辨识的目的是通过表征系统行为的重要参数,建立一个能模仿真实系统行为的数学模型[2]。近年来,已经有大量科研人员对发动机系统进行系统辨识,常用的辨识方法有基于最小二乘法、支持向量机、BP神经网络等静态辨识方法,以及ARIMA、NARX等基于时间序列模型的动态辨识方法[3-6]。APU是一个复杂的非线性时序系统,静态辨识模型忽略了系统的时序信息,而传统的时序模型对非线性系统表征能力不足[7-8]。随着深度学习的兴起,深度学习模型逐渐被引入到系统辨识的研究中,循环神经网络(RNN)将时序信息嵌入到神经网络结构中,使得神经网络具备了动态辨识能力。长短期记忆(LSTM)模型作为RNN的变体,解决了RNN梯度消失或爆炸、长时记忆能力较差等问题,使其兼具静态模型的非线性表征能力与时序模型的长时间存储能力。在系统辨识中表现出更强的适应性与泛化性[9-10]。
APU工作过程较为复杂,大致可分为启动、电提取功率、主发动机启动、环控引气及停车5个阶段。本文选取APU的启动阶段,结合发动机试车数据,针对表征APU工作状态的排气温度EGT、转速N,提出了一种基于LSTM的辅助动力装置参数辨识模型。在建模过程中,充分考虑影响辨识参数的其他静态特征,进一步提出了基于LSTM的多变量时间序列辨识模型。将所建模型与最小二乘法、神经网络等传统辨识方法进行对比,验证了该模型的优越性。
1 长短时记忆网络
1.1 网络构型
长短期记忆神经网络(long short-term memory,LSTM)是一种时间递归神经网络(RNN)。传统的神经网络模型分为输入层、隐藏层、输出层,层与层之间是全连接的,但是每层之间的节点是无连接的,此网络结构对于序列问题建模效果较差[11-12]。RNN的隐藏层节点具有连接性与记忆性,会处理信息并将信息传递给当前节点,对序列问题建模有较好的效果,如图1所示。

图1 RNN网络结构
RNN输出两层单元,其中隐藏层单元的输出ht以及状态的单元输出yt表达式:
ht=fa(Wxhxt+Whhht-1+bh)
(1)
yt=Whyht+by
(2)
其中:Wxh为输入层到隐藏层的权重系数矩阵;Whh为隐藏层到隐藏输出的权重系数矩阵;bh为隐藏层的偏置向量;fa为激活函数;Why为隐藏层到状态输出层的权重系数矩阵;by为状态输出层的偏置向量;t表示时刻。
RNN虽然解决了序列建模的问题,但是序列长度比较长时,回传时残差指数会下降,进而降低网络权重更新速率,导致长期记忆效果较差,但LSTM可以存储记忆因此被提出解决问题。
LSTM同样是循环结构,但是重复的单元有不同的网络结构。LSTM采用门结构方式来改变信息至目前细胞状态。门采用选择式的通过方式,其中包含sigmoid神经网络以及pointwise乘法操作。LSTM通过遗忘门、输入门、输出门三种门方式来控制细胞状态[13-15],网络结构如图2所示。

图2 LSTM网络结构
遗忘门ft负责控制上一个时刻的输入,选择性地忘记过去某些无用信息,减小记忆负担。
ft=σ(Wf·[ht-1,xt]+bf)
(3)
输入门it控制当前时刻的输入,同样是过滤无用信息,选择性记忆当前重要信息。
it=σ(Wf·[ht-1,xt]+bi)
(4)
Ct为当前细胞状态,此时合并需要记忆的信息,更新细胞状态。
(5)
(6)
输出门ot将过去信息与当前信息合并,输出新的状态信息。
ot=σ(Wo·[ht-1,xt]+bo)
(7)
ht=σt*tanh(Ct)
(8)
1.2 网络训练
LSTM采用前向传播和反向传播两种训练过程,前向传播通过式(3)~(8)计算出神经元输出值,反向传播则是BPTT算法,从时间和网络两个方面反向计算每个神经元的误差项,根据计算的误差结果,采用不同的优化算法,优化神经元权重。
梯度下降法是优化神经网络中常用算法,例如SGD、Adagrad、RMSprop、Adam等梯度下降法。本文采用自适应矩估计(adaptive moment estimation,Adam)优化算法,Adam可优化每一个参数的自适应学习率。拥有Adadelta和RMSprop算法存储一个指数衰减的历史平方梯度平均值功能的同时还可保存一个历史梯度的指数衰减均值。实际应用表明,Adam具有算法优势。
2 基于LSTM的多变量时间序列辨识模型
根据APU的工作原理,表征其工作状态的参数主要有以下两个:排气温度EGT、发动机转速N,即本文的辨识目标。传统的时间序列建模只考虑当前时刻与之前时刻的数据关系。这类只考虑时序信息的建模方法有很明显不足,时序信息以外的干扰因素同样有着非常重要的作用,比如预测APU的发动机排气温度(EGT),影响当前EGT的因素除了上一时刻的EGT,其他重要因素还包括发动机点火状态、起动机状态等因素。在APU系统辨识建模的过程中,需要将时间以外的其他因素同时考虑进去。
APU起动阶段,采用时序开环控制,既不引气也不提取电功率;负载压气机出口管道喘振阀SCV全开,引气阀LCV关闭,负载压气机出口气流通过SCV排到APU尾喷管,进口导叶IGV处于角度最小状态,以提高APU起动速度。当启动按钮打开时,APU起动机通电打开,当APU转速达到7%时,燃油活门打开,APU点火启动,当APU转速达到50%时,APU起动机断电,当APU转速达到95%,点火断开,APU启动完成。在APU起动阶段,SCV、LCV、IGV三个阀门状态固定,为非变量因素,不考虑其对辨识系统的影响,此阶段系统辨识的影响因素见表1。

表1 影响因素
在APU工作其他阶段,同样也可以根据工作原理,总结出其与辨识参数相关的各个特征,与时间序列特征拼接,构建基于多变量的时间序列辨识模型。
2.1 模型架构
基于多变量时间序列特征输入的考虑,本文提出了一种基于LSTM的多变量时间序列预测模型,充分考虑影响辨识参数的其他特征因素,模型架构如图3所示。

图3 多变量时间序列辨识模型
在数据准备阶段,需要对收集的发动机试车数据进行数据预处理,统一数据类型和量纲,然后拼接时间序列数据和多变量特征数据,将拼接的数据送入模型。在网络训练阶段,前向传播部分通过softmax进行回归预测,反向传播部分通过Adam梯度下降算法更新网络参数。最后通过参数寻优、模型评估等方法,优化网络参数,提高模型性能。以下分别做了详细介绍。
2.2 数据预处理
通过APU发动机试车采集的原始数据,并不能直接送给模型训练。主要存在以下两个方面问题:一方面数据量纲不一致,EGT的温度范围是0~1038℃,N的转速百分比范围是0~110,直接送入模型训练,会导致模型对量纲小的数据不敏感;另一方面数据类型不同,影响系统辨识的主要参数数据类型多样,包括布尔型、离散型、连续型,不同类型数据含义不一,直接送入模型会导致模型学习误差,因此需要对数据进行以下预处理。
1)布尔型特征和离散性特征向量化,主要用到的方法有One-hot编码、哈夫曼编码等。
2)连续型特征归一化,主要解决量纲不一致的情况,采取数据归一化的方法,一般会用maxminmap算法,公式为:
(9)
其中:x为待归一数据,xmin为预处理数据最小值,xmax为预处理数据最大值,xscale即为归一数据。
2.3 多变量时间序列数据输入
传统的时间序列预测的模型,其输入信息只考虑前一个或者多个时刻对辨识结果的影响。在时刻k,传统时序辨识模型表达式为:
EGTk=fEGT(EGTk-1,EGTk-2,…EGTk-n)
(10)
Nk=fN(Nk-1,Nk-2,…Nk-n)
(11)
其中:n为网络步长。fEGT和fN分别为排气温度EGT和发动机转速N的传统辨识模型表达式。
在APU启动阶段,作用于k时刻的辨识参数,不仅与前n个时刻的时间序列有关,同时作用于辨识参数的影响因素还包括点火器FIR、起动机STR、供油量OIL。此阶段多变量时间序列辨识模型表达式为:
(12)
(13)
(14)
(15)

2.4 基于Grid-Search的参数寻优
网格搜索算法(Grid-Search)是一种通过遍历给定的参数组合来优化模型表现的方法。在模型训练的过程中,需要调试的参数主要包括网络步长、隐藏层个数、批尺寸、学习率等。在模型训练过程中,为了确定最优的参数,Grid-Search采取了一种穷举搜索的调参手段,在所有候选的参数中,通过循环遍历,尝试每一种组合可能,性能最好的就是最终的辨识模型网络参数。
以隐藏层单元个数为例,在训练过程中,首先会根据经验设置参数为200个,以经验参数为中心,其他参数保持不动的情况下,模型分别遍历100、150、200、250、300。测试效果最好的参数,即作为最终的系统辨识模型隐藏层单元个数。
2.5 基于K折交叉验证的模型评估
通过发动机试车得到的数据,相对来说数量偏小,划分训练集、验证集和测试集之后,用于训练的数据更少,在这种情况下,分割后的数据分布很有可能和原始数据集的分布情况不一致,容易造成过拟合或者欠拟合的情况。
为了更加有效地评估模型的泛化性能,采取K折交叉验证的方式评估模型,此方法对K个不同分组数据进行训练,并将结果进行平均,进而来减少方差,降低数据敏感性,提升模型性能,具体步骤为:
1)将原始数据不重复抽样并随机分k份。
2)每次挑选其中一份作为测试集,其余的k-1份作为训练集用于模型训练。
3)重复第二步k次,每个子集都有一次机会作为测试集,其余机会作为训练集。
4)在每个训练集上训练后得到一个模型。
5)计算模型在相应的测试集上的结果,并保存模型的评估指标。
6)保存训练模型的评估指标。
7)计算k组测试结果的平均值,作为K折交叉验证下模型的性能指标。
对于模型的评估指标,本文选择均方根误差(Root Mean Square Error, RMSE)作为度量标准。其公式为:
(16)

3 模型仿真
3.1 仿真平台
实验所采用的计算机配置如下:处理器采用英特尔i7-8550U;内存为8.00 GB;操作系统为Win10(64位);集成开发环境为Anaconda 3;程序设计语言为Python 3.6.5(64 位);采用机器学习包scikit-learn、谷歌开源框架tensorflow 1.4.0进行实验。
3.2 实验结果
数据来源于采集的某型发动机地面起动阶段试车样本,采集样本包括供油量、点火状态、起动机运行状态。APU发动起启动时长大约为12 s因此以该时长作为试车样本采样周期。采集样本的时间间隔为0.2 s,单个样本点为60个。
3.2.1 参数寻优
模型训练过程中,需要确定的参数包括,网络步长、隐藏层个数、学习率分别采用Grid-Search策略进行参数寻优。实验过程记录了在不同参数条件下,取RMSE作为辨识参数EGT和N辨识结果的评判标准。实验结果如图4所示。

图4 网络步长参数寻优
根据图4的实验结果,网络步长越大,其RMSE越小,在步长超过4时,其RMSE变化不大,综合模型效率与准确率考虑,取网络步长为4。同时根据图5和图6的结果可以判断,转速N的参数辨识模型其学习率参数选取为0.01,隐藏层个数选取为250,排气温度EGT的参数辨识模型其学习率参数选取为0.005,隐藏层个数选取为200,模型辨识效果最佳。

图5 隐藏层参数寻优

图6 学习率参数寻优
根据网格搜索算法得出的最优参数,分别训练出APU的EGT和N的参数辨识模型,其中EGT的RMSE为3.64,N的RMSE为0.86。辨识结果如图7、图8所示。
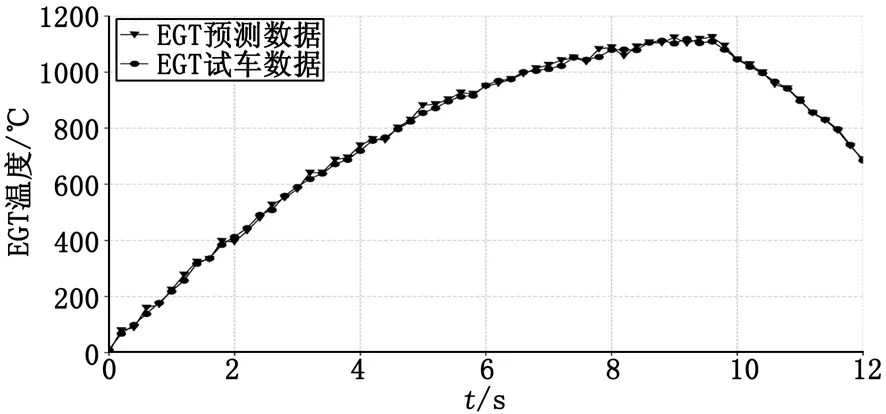
图7 EGT辨识模型拟合曲线

图8 N辨识模型拟合曲线
3.2.2 模型对比
为了验证模型效果,分别和传统的系统辨识模型进行对比,对比模型包括最小二乘法(OLS)、支持向量回归(SVR)、自回归积分滑动平均模型(ARIMA)、神经网络(MLP)。实验结果如下:

表2 模型对比
实验结果表明,在EGT和N的系统辨识任务中,LSTM因为其长时记忆的特性,其结果均优于其他同类模型。
4 结束语
本文针对表征APU工作状态的EGT和N两个系统参数,提出一种基于LSTM辅助动力装置系统辨识模型。建模过程中,结合APU发动机工作过程,分析影响辨识参数的影响因素,进一步提出了基于LSTM的多变量时间序列系统参数辨识模型。最后利用APU发动机试车数据,经过模型对比,实验结果证实了基于LSTM的多变量时间序列参数辨识模型的辨识性能。
基于多变量LSTM的时间序列模型在系统参数辨识上具有较大优势,但是文中模型仍有不足之处,目前辨识模型还是单步滚动预测,多步预测还有待探索,另外目前只进行了APU启动阶段的系统参数辨识,后续阶段的辨识任务还没有进行,下一步工作将围绕这些任务继续展开。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
数理化解题研究·综合版(2021年11期)2021-12-22
北京航空航天大学学报(2021年4期)2021-11-24
小学教学研究(2021年5期)2021-09-29
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
软件(2017年6期)2017-09-23
新高考·高二数学(2014年7期)2014-09-18
