
半监督学习研究的述评
2020-03-19 10:45韩秋弘
计算机工程与应用 2020年6期
韩 嵩,韩秋弘
北京物资学院 信息学院,北京101149
1 引言
机器学习的核心是从数据中学习,从数据出发得到未知规律,利用规律对未来样本进行预测和分析。基于数据的机器学习包括监督学习、无监督学习以及半监督学习。监督学习需要大量已标记类别的训练样本来保证良好的性能;无监督学习不使用先验信息,利用无标签样本的特征分布规律,使得相似样本聚为一起,但模型准确性难以保证。随着大数据时代的来临,数据库中的数据呈现指数增长[1],获取大量无标记样本相当容易,而获取大量有标记样本则困难得多,且人工标注需要耗费大量的人力和物力。如果只使用少量的有标记样本进行训练,往往导致学习器泛化性能低下,且浪费大量的无标记样本数据资源。因此使用少量标记样本作为指导,利用大量无标记样本改善学习性能的半监督学习成为研究的热点。“半监督学习”术语第一次于1992年被正式提出[2],其思想可追溯于自训练算法[3]。半监督学习突破了传统方法只考虑一种样本类型的局限,综合利用有标签与无标签样本[4-6],是在监督学习和无监督学习的基础上进行的研究,包括半监督聚类、半监督分类、半监督降维和半监督回归四种学习场景。随着半监督学习的深入研究,近些年出现两个研究热点,不平衡数据分类问题和噪声数据的处理问题。
因此本文采用文献计量方法对半监督学习的研究的时间、应用领域和研究内容等进行多维度梳理,对研究的四个学习场景和两个研究热点进行归纳与述评,总结现有成果的不足以及探讨新的研究方向,为半监督学习的理论和应用研究提供参考。
2 国内半监督学习研究的总体状况
2.1 年度分布
本文以中国知网(CNKI)为检索数据库,以“半监督”为主题检索,国内外半监督学习领域发表文献的趋势如图1所示。
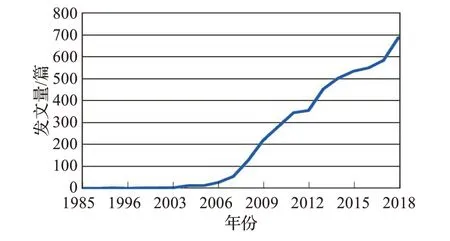
图1 年度分布
从图1 可以看出,从1983 年到2003 年文献的发表量较少,2003 年到2006 年有一个较小的斜率呈现出上升的趋势,2006 年到2018 年的文献数量几乎呈直线上升,平均一年的发文量大约364 篇,从发文量反映出半监督学习的研究状况火热,半监督学习凭借着自身的优势以及在各行业成功的应用吸引了大量的研究人员,从而使得相关研究成果数量直线上升。
2.2 半监督学习研究内容
为了更加全面了解半监督学习的研究内容,对国内外的半监督学习研究领域出现较多的关键词进行统计分析,具体结果如图2所示。从图2中可以看出分类器、数据集、样本点、半监督聚类、支持向量机、特征提取、主动学习、协同训练等关键词出现的频率较高,这些都是半监督学习研究的主要研究内容,涉及到了人工智能的各个领域范畴,其中半监督分类和聚类的研究相对较多。

图2 半监督学习关键词占比
2.3 研究内容学术关注度指数对比分析
根据学习场景的不同,半监督可以划分为半监督分类、半监督聚类、半监督降维以及半监督回归,从上述四个不同类别的学术关注度指数进行对比分析,可以看出半监督分类的关注度最高,一方面是很多现实问题是分类问题,另一方面是机器学习算法中分类算法研究成果丰富,为半监督学习提供了算法基础。其次依次是半监督聚类、半监督降维和半监督回归,半监督回归的研究指数相对平稳且研究关注度低,但近两年研究关注度处于上升趋势。

图3 半监督四种学习场景的研究指数对比图
3 半监督学习研究内容评述
从前文的分析中可知,目前研究的主要内容和热点包括半监督聚类、半监督分类、半监督回归与半监督降维,以及不平衡数据分类和减少噪声数据六个方面。因此下文从这六个方面展开评述。
3.1 半监督聚类
半监督学习与无监督学习的差异在于监督信息的使用,其中监督信息主要包含两种类型,一种是样本的类别标签,另一种是样本的成对约束关系。
可以根据监督信息使用的不同,对半监督聚类方法进行划分,Seeded-Kmeans算法相比于Kmeans算法具有利用样本类别标签指导k 个原始聚类中心的选择,该算法的缺陷在于仅能利用样本类别标签的监督信息形式且很大程度上依赖于Seeds集的规模和质量。COP-Kmeans算法将成对约束信息增添到Kmeans 聚类过程,该算法与Kmeans算法的聚类思想相同,但在样本划分过程中,样本必须满足must-link 约束和cannot-link 约束,缺陷是在求解过程中会遇到成对约束违反问题。在实际应用中,监督信息会以样本标签和成对约束信息并存的情况,若只利用标签信息或将标签信息转化为成对约束信息时,会削弱监督信息或利用不充分,SC-Kmeans 算法综合利用Seeds 集和成对约束集引入到Kmeans 中指导聚类过程,但该算法效率降低以及监督信息的规模和质量会影响聚类结果;常瑜等扩大后的Seeds 集进行优化得到新的Seeds 集进行聚类[7];陈志雨等将主动学习引入到SC-Kmeans中,用于选取信息含有量更高的监督信息[8]。现有的半监督聚类算法多数是在传统聚类算法基础上引入监督信息发展而来,基于不同的聚类算法可以将其扩展成不同的半监督聚类算法,可以对密度聚类、层次聚类、谱聚类等聚类算法进行半监督的扩展;大多数的聚类方法不适用于高维稀疏数据,使得扩展的半监督方法难以处理高维稀疏数据的聚类,因此用于高维稀疏数据的半监督聚类算法的提出需要进一步研究。
3.2 半监督分类
常见的半监督分类代表算法可以划分为四类,包括生成式方法、半监督支持向量机、半监督图算法和基于分歧的半监督方法。下面分别介绍四种范型的半监督学习框架,汇总对比分析结果如表1所示。
3.2.1 生成式方法
生成式方法关键在于对来自各个种类的样本分布进行假设以及对所假设模型的参数估计。常见的假设模型如混合高斯模型、混合专家模型、朴素贝叶斯模型,采用极大似然方法作为参数估计的优化目标,选择EM(Expectation Maximization)算法进行参数的优化求解。赵夫群利用狄利克雷多项式混合分布对文本进行建模,针对EM 算法收敛速度过快以及容易陷入局部最优的难题,引入模拟退火算法和遗传算法进行处理[9];董育宁等指出传统的高斯分布容易受到数据样本边缘值和离群点噪声的影响,改用t 分布代替原有的高斯混合模型[10]。关于生成式方法的研究,难点在于样本分布与假设的模型不一致,即生成式方法的关键之处在于模型假设必须正确,而实际应用中很难使得假设的生成模型与实际数据分布吻合,从而模型效果欠佳。
3.2.2 半监督支持向量机
半监督支持向量机(Semi-supervised Support Vector Machine,S3VMs)的思想最早可以追溯至Vapnik提出的猜想,无标记数据可以有效地减少函数空间的VC 维。常见的S3VMs 方法如直推式支持向量机(Transductive Support Vector Machine,TSVM)、拉普拉斯支持向量机(Laplacian Support Vector Machine,Laplacian SVM)、均值标签半监督支持向量机(meanS3VM)、安全半监督支持向量机(Safe Semi-supervised SVM,S4VM)、基于代价敏感的半监督支持向量机(Cost-sensitive Semi-su‐pervised SVM,CS4VM),表2列出了上述几种典型方法的基本介绍和优缺点。
虽然半监督支持向量机具有适用于小样本、利用无标签样本提高模型性能的优势,但仍存在不足,因此,国内外学者提出创新性的半监督支持向量机方法以及对现有算法进行改进,文中列举了最新的模型、模型特点及效果,如表3所示。
半监督支持向量机方法需要关注以下问题:(1)S3VMs在小规模数据集中能够得到很高的分类精度,但对于大规模数据并不适用,且当解决非线性或流形数据,需要构造核函数,此时会存在更高的复杂度;(2)现有的模型多数属于二分类问题,但在现实问题中不仅局限于二分类,在解决S3VMs的非凸二次优化问题时需要消耗大量的存储空间和计算时间,当解决多分类问题时更加困难。
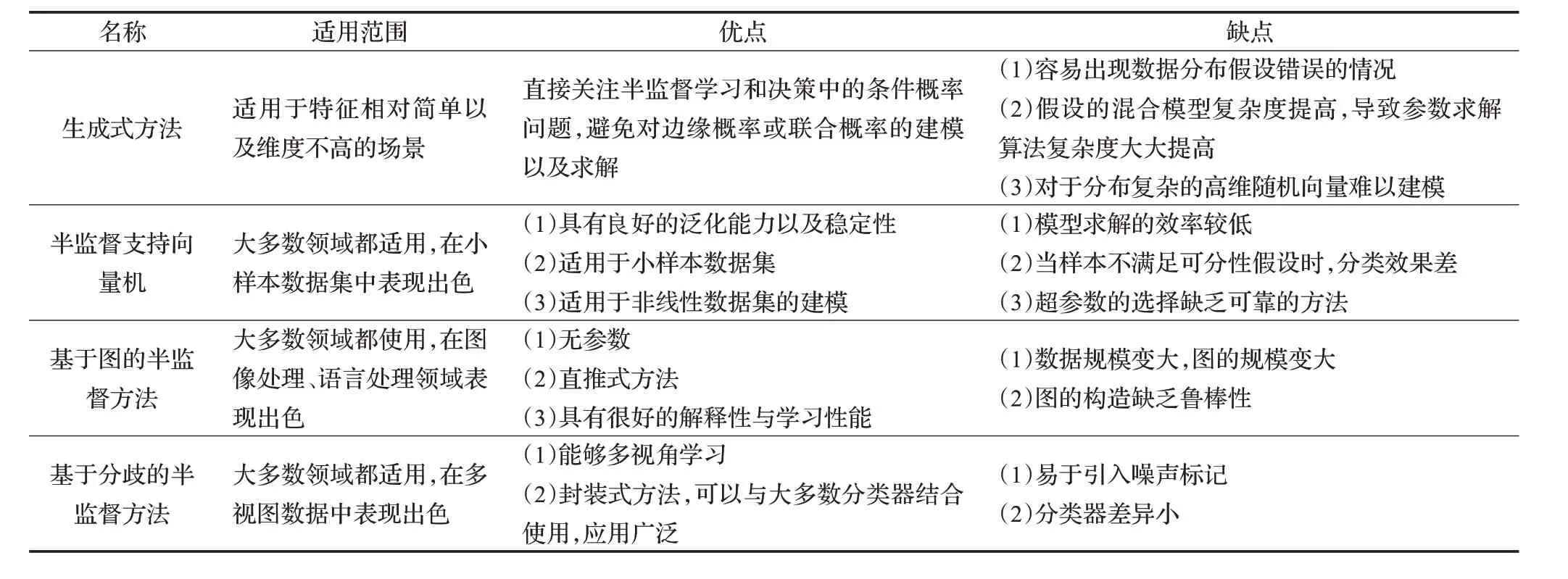
表1 半监督分类四大范型对比分析
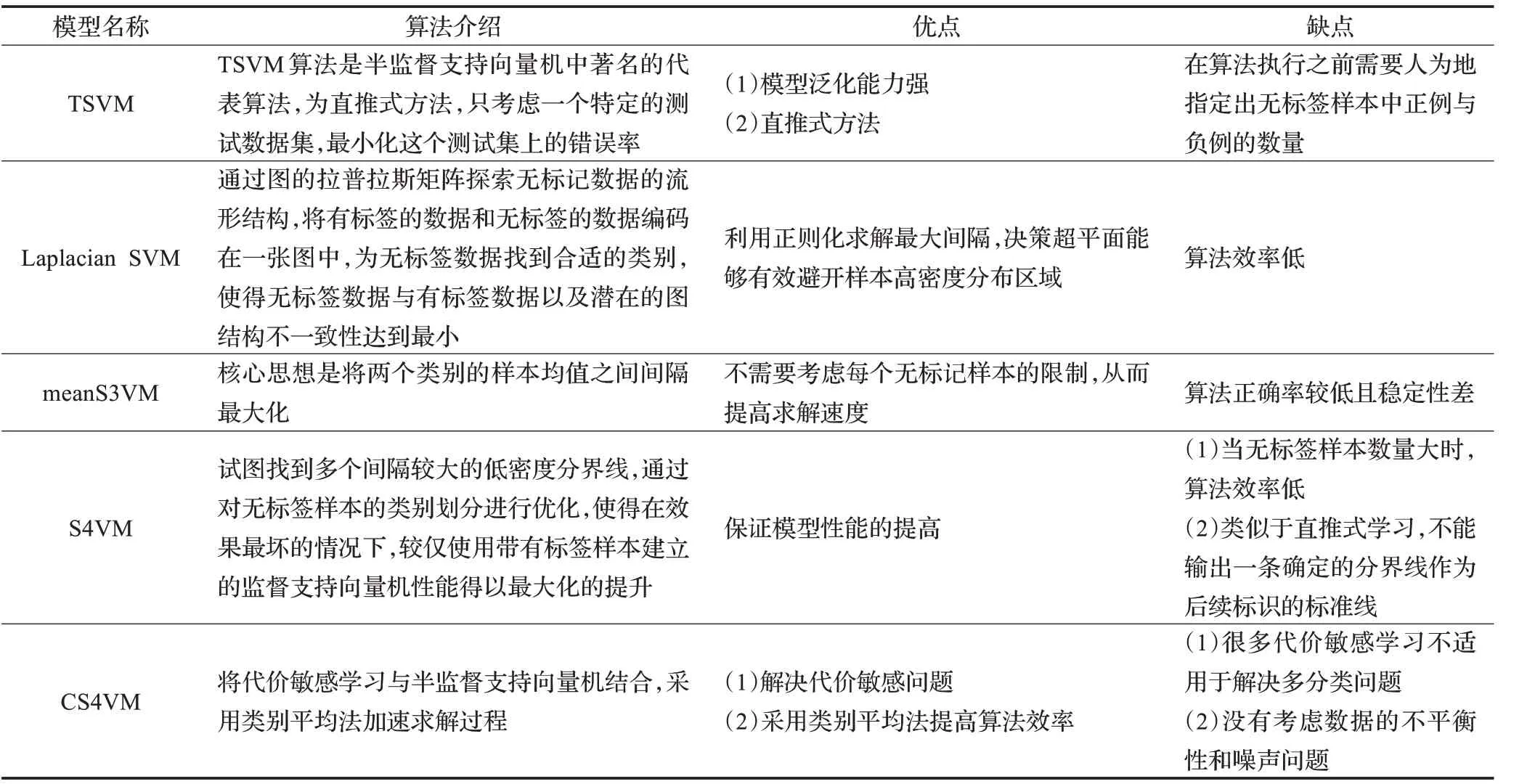
表2 半监督支持向量机模型对比分析

表3 改进型半监督支持向量机的主要改进特点以及模型效果
3.2.3 基于图的半监督分类
基于图的半监督分类方法是利用有标签和无标签样本之间的联系得到图结构,利用图结构进行标签传播。典型的基于图的半监督分类方法有标签传播算法、最小割算法以及流形正则化算法,三种方法的比较及优缺点如表4所示。
近些年,学者对图半监督学习创新性研究较多,为直观展现图半监督学学习方法的发展情况,在表5 进行了列举。
基于图的半监督学习研究成果丰富,但存在以下不足:(1)数据量大往往构造的图的规模大,导致计算的时间与空间复杂度非常大,但图模型的大小与模型正确率相关联,如何平衡图模型的大小和模型正确率之间的关系也需进一步研究;(2)在构造图时,一般只考虑了数据之间的距离信息,忽略样本特征空间的类别分布信息;(3)高维数据中易于含有噪声以及冗余信息,从而构造的图难以对数据的几何结构进行精确的探索[23]。
3.2.4 基于分歧的半监督学习
基于分歧的半监督学习起源于协同训练算法,由Zhou 和Li 命名的[24],其思想是利用多个学习器之间的差异性提高泛化能力。根据视图个数的不同,可以划分为多视图和单视图下基于分歧的半监督学习。
Blum 和Mitchell 提出了协同训练框架[25],采用贪婪的方式,并在假设视图独立性和兼容性的情况下进行操作。针对多视图下协同训练方法的研究,如Nigam等提出协同EM 算法[26];Sindhwani 等提出协同正则化算法[27],具有非贪心、包含凸代价函数等优点;王娇等通过随机子空间方法将两视图推广至多视图,同时避免了充分冗余视图问题[28];唐焕玲等将寻找两个满足一致性和独立性特征视图的目标转变成寻找两个既满足一定的正确性,又存在较大差异性的两个基分类器的问题[29];孙念等提出松散条件下的协同学习框架,放松了特征充分冗余假设[30]。部分学者降低数据要求并进行了理论证明[31-32],其中Wang 和Zhou 表明若两个分类器存在足够大的差异,协同训练在单视图上也能取得成功[33]。

表4 基于图的半监督分类方法的对比分析

表5 基于图的半监督分类方法
单视图下的基于分歧的半监督方法,研究重点在于如何创造弱学习器之间的显著差异。Goldman 和Zhou提出的基于决策树的协同训练算法[34],使用不同的学习算法来表示弱分类器之间的差异化;Zhou和Li提出的三体训练法(Tri-training)[35],通过不同的数据采样训练使用三个具有差异化的弱分类器;Li和Zhou提出Co-forest算法[36],将Tri-training算法由三个分类器扩展到更多分类器。
基于分歧的半监督学习研究成果较多,包括算法的理论证明和新的算法的实证研究,但仍然存在以下问题:(1)当具有差异的弱分类器相互之间提供伪标记样本进一步丰富训练集,但伪标记类别错误,则导致新的训练集出现错误标记,使得训练出的模型性能“恶化”[37];(2)基于差异的半监督学习重点在于使得弱分类器之间存在差异,但如何去使得弱分类器之间存在显著的差异,以及如何衡量差异是否显著需要进一步的讨论;(3)基于分析的半监督学习方法中参数较多,且对于参数的选择尚无经验指导,因此如何进行参数缩减和参数取值需要进一步研究。
3.3 半监督回归
现有的半监督回归的研究成果,可以归纳为基于协同训练的半监督回归和基于流形的半监督回归两类。
Zhou等提出的协同训练回归,选择k 近邻回归作为初始回归器,分别采用不同阶的闵可夫斯基距离[38]、不同距离度量[39]、不同k 值[39]保证两个回归器之间的差异。Brefeld等将协同训练回归思想移植到正则化框架下,提出了协同正则化最小二乘法[40]。基于协同训练的半监督回归虽然方法简单便于理解,但由于回归问题中目标变量为连续变量,存在预测值的置信度难以衡量的难题。
半监督回归对应的是流形假设,主要考虑模型的局部特性。对于核的半监督回归的研究,如Wang 等基于经典的核回归,提出了半监督核回归方法[41];Xu 等在最小二乘支持向量机回归的基础上,提出了半监督最小二乘支持向量机回归[42];Seok提出了半监督局部常数估计回归算法,但该方法为单变量回归[43]。对于拉普拉斯正则化的半监督回归的研究,如Belkin 等通过构图,将得到的拉普拉斯矩阵作为惩罚项引入到支持向量机的正则化框架中,得到拉普拉斯正则化框架[44];杨剑等在拉普拉斯正则化框架基础上,给出不同损失函数下的拉普拉斯半监督回归算法,并进行了实验分析[45]。
半监督回归的研究与应用非常缺乏,其原因在于:(1)半监督分类中的聚类假设在回归问题中不一定成立,从而大多数的半监督分类方法不能直接用于回归;(2)半监督协同训练回归是半监督回归最常用的方法,但由于回归问题中目标变量为连续变量,存在预测值的置信度难以衡量的难题;(3)回归估计本身是一个比较困难的问题,学习算法很难取得比较好的结果,且回归问题中存在多种损失函数和评价指标,无疑增加了半监督回归的难度。
3.4 半监督降维
针对半监督降维方法的研究,包括提出新的半监督降维框架,即对所有数据点之间的几何关系进行建模,以及如何将半监督的思想应用于传统的降维算法当中两个方面。
Zhang 等提出一种半监督降维方法[46],考虑了成对约束与无标签样本信息,然而该方法只能保持全局协方差结构,不能同时保持局部结构;Wei 等提出了一种基于成对约束信息的半监督线性降维方法[47],该方法既能用到成对约束信息,也可以保留数据局部结构;Zhao 等分析了跟踪比问题,推导出一个正交约束半监督学习框架[48],多种降维算法都可以在此框架进行改进;尹学松等提出一种基于成对约束的半监督维数约简一般框架[49]。
将无监督降维方法扩展至半监督,需要在原有的无监督降维算法中增添监督信息,如将类标签、成对约束或其他监督信息添加到概率主成分[50]、流形方法[51]以及局部保持投影方法[52]进行半监督的扩展。将有监督降维方法推广到半监督方法多数是采用基于图来完成的,通过在原有的监督判据中加入代表数据内部结构信息的流形正则化项,如Cai 等将线性判别分析模型进行半监督扩展[53];为了解决上述模型的噪声敏感问题,Zhang 等采用鲁棒的方法来捕获数据的流形结构[54];Zhao 等提出一种新的降维方法,通过无标记的样本来提高线性判别分析模型的性能[55];杨昔阳等针对具有少量模糊隶属度类别的数据和大量未知类别的数据组成的数据集,提出一种结合主成分和局部费歇尔判别分析的半监督降维方法[56]。
半监督降维相关研究成果较多,但仍存在以下几点问题:(1)针对于高维稀疏样本,虽然一些行之有效的方法被提出,但一个好的降维方法应具备一定的鲁棒性和稳定性,因此在微小扰动的情况下,半监督降维算法如何依旧保持良好的性能需要进一步研究;(2)现有的半监督降维算法所使用的监督信息多为标签信息或成对约束信息,为离散变量,但当监督信息为连续变量时[57],如何进行半监督降维是下一步的研究重点。
3.5 不平衡数据分类与半监督学习
现有的半监督学习方法假定数据集是平衡的,直接使用已有模型对不平衡数据进行处理会造成分类性能急剧下降。不平衡数据分类的研究成果可以分为基于数据层面和基于算法层面的不平衡数据下的半监督学习。
基于数据层面的半监督学习是先通过一定的方法改变样本数以达到样本的平衡,再进行半监督学习。采样是常用于平衡数据的方法,然而随机欠采样可能删去了很多潜在有用的数据,而随机过采样会增加过拟合的可能性。为此,部分学者将动态子空间[58]或优化样本分布方法[59]与半监督方法结合解决数据不平衡问题,以及Zhou 等通过半监督生成式对抗网络算法在训练过程中只生成少数类样本,使得少数类和多数类样本取得平衡[60]。
基于算法层面的半监督学习大多数是改进已有的算法,常用的方法包括重新加权、代价敏感和集成方法。基于图的半监督学习解决不平衡问题主要通过重新加权的方法,如Wang等提出一种传播算法,能更可靠地使图上和二进制标签矩阵上的函数的代价函数最小化[61],并进行噪声消除处理[62]。基于代价敏感和集成学习的半监督学习研究,如Zhu 等为了降低代价敏感的总成本,提出了一种基于不确定性的代价敏感半监督学习模型[63];黄静等提出半监督集成模型[64],用于非平衡数据的分类;肖进等将代价敏感学习与多分类器集成中的随机子空间方法结合[65],结果表明与单一的半监督模型以及半监督集成模型相比,该方法能取得更好的效果。
解决不平衡数据的方法较多,但半监督学习中的不平衡问题相关研究非常少,因此需要关注以下问题:(1)代价敏感学习的参数训练具有局限性,可以参考创新训练方式[66]进行参数的求解来获得优秀的代价矩阵;(2)现有的成果多为解决二分类的不平衡数据集分类问题,但是多分类数据集同样存在不平衡的问题,针对多分类不平衡问题需要进一步研究;(3)现有的不平衡数据下的半监督方法是将传统的解决不平衡的方法应用于半监督学习当中,而半监督与监督学习的数据分布环境不同,因此传统的解决不平衡问题的方法是否都可以适用于半监督学习还需要进一步探究;(4)如何利用半监督学习的数据集中存在大量的无标签数据的特点来改进不平衡数据集的分类需要进一步研究;(5)现有的半监督集成模型大多数适用于大数据规模,而小数据量的半监督集成如何保持较好的性能需要深入研究;(6)可以在已经成熟的代价敏感学习方法的基础上进行半监督的扩展,或在半监督学习的框架中添加代价敏感学习,为如何使得半监督学习模型具有代价敏感性提供解决思路。
3.6 可靠样本的选取与减少噪声数据
半监督学习研究成果较多,但并不总是有效,一方面在于标记样本中提供的监督信息存在信息含量低;其次,半监督学习在利用无标签样本的过程中,并不总能选取最具有价值的样本,一旦选取了不可靠的无标签样本,并从中挖掘数据分布信息,便会错误地指导分类边界的形成。部分学者主要从提出高置信度评价方法以及将主动学习引入半监督学习过程两个方面进行研究,主动获取有效的监督信息和降低伪标记样本的噪声,此外,也有学者通过数据剪辑方法[67-68]对产生的错误标记进行修正和净化。
部分学者致力于高置信度评估方法的研究,如Zhou 等采用投票法进行标记置信度计算[35],但该方法存在没有考虑样本的分布信息的缺陷;邹细涛提出样本代表性度量[69],如果某个样本与其他很多样本都相似,则该样本具有所有样本的共性,其被标记正确的概率就很大;景陈勇等考虑伪标记数据与实际样本空间的分布差异,提出了采用样本所属某个类别的最大概率与次大概率的误差作为基分类器的置信度[70],但该信度评估方法存在没有充分表达样本的随机分布特性的缺点;尹玉等引入加权融合样本所属某个类别的最大概率与次大概率的误差和样本所属某个类别的最大概率与样本所属其他各类别的平均概率误差,来确定样本作为伪标签的置信度[71]。
虽然高置信度通常意味伪标签预测是正确的,但不能保证分类性能的提高。部分学者将主动学习与半监督学习结合,如毕秋敏等在协同训练算法的基础上引入主动学习思想,从低置信度样本中选取最有价值的样本,人为标注完后添加到训练集中,重新训练分类器进行分类[72];柴变芳等提出一种基于主动学习先验的半监督K-均值聚类算法[73]。且部分研究表明,半监督学习与主动学习两种策略结合的性能优于单独使用单一方法的性能[74-75]。
综上所述,虽然高置信度评价方法多样,但是缺少评价方法选取的指导标准;将主动学习与半监督学习结合,可以主动发现有效的监督信息,但主动学习何时停止,发现多少有标记样本能够有效地提升模型性能需要进一步探究。
4 结论与展望
随着数据量呈指数增长,半监督学习相比较传统的监督学习与无监督学习,具有能够利用少量带有标签的数据指导大量无标签数据的优点,半监督学习俨然成为机器学习研究的热点与重点。近些年来,半监督学习研究成果丰硕,成功应用到经济、金融、医疗等各个行业。因此,本文从半监督聚类、分类、回归、降维以及不平衡数据分类和降低噪声六大方面对现有的半监督学习研究成果进行归纳总结,在已有研究现状的基础上,本文对未来的研究方向进行以下思考:
(1)随着半监督学习研究的深入,学者们针对已有半监督学习方法与框架的不足进行改进与补充,但部分新提出的方法在文献中仅通过特定数据集进行了实证,而缺少一定的理论基础与证明,无法进一步说明该方法的有效性与稳定性。
(2)随着数据出现维度高、数据稀疏、非线性以及非平衡等特点,学者们在原有半监督学习方法的基础上,进行算法改进以适应复杂数据,引入额外的参数虽然提高了模型性能,但同时增添了算法复杂度,带来迭代次数增多、模型训练时间增长等缺陷;对于参数的取值,多数凭借经验或者手动调整最优值,缺少一定的指导方法;当参数取值的微小变动,导致模型性能发生改变,从而导致训练的模型不具有稳定性和鲁棒性。
(3)半监督学习中需要选取少量监督信息作为指导,但如何确定监督信息中信息量是否充足以及至少需要多少标记样本才能实现有效的半监督学习还缺乏相应的讨论。
(4)监督信息主要为类标签和成对约束的形式,由于基于成对约束信息的模型构造相对容易,多数算法将类标签信息转化为成对约束信息后再进行半监督学习,但将类标签信息转换为成对约束信息会使标号信息的意义减弱,如何利用标签信息进行半监督学习以及将标签信息与成对约束信息结合使用形成基于混合约束的半监督方法是下一步研究方向。
(5)监督信息为连续变量时,相关研究甚少。机器学习中回归和回归意义下的维数约简方法是以连续变量为目标变量,而半监督学习中的聚类假设在上述方面不一定成立,以及在置信度、损失函数和评价指标等方面与半监督分类、聚类等方法存在差异,使得当监督信息为连续变量时,半监督学习方法的设计存在难点。
(6)半监督学习已有的研究成果多数是在已有的监督模型或无监督模型的基础上进行扩展,半监督分类方法众多,而对半监督聚类、降维以及回归研究相对较少,因此可以基于不同的聚类、降维及回归思想,形成不同的半监督方法,以及从减少噪声数据、提高求解速度、提高模型精度等不同的角度对现有的半监督方法进行改进。
猜你喜欢
车主之友(2022年4期)2022-08-27
海峡姐妹(2019年12期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
火控雷达技术(2016年1期)2016-02-06
智能系统学报(2015年4期)2015-12-27
