
基于Takenaka-Malmquist系的语音信号压缩与降噪方法
2020-03-23 09:54张立明
上海大学学报(自然科学版) 2020年1期
雷 娅, 方 勇, 张立明
(1.上海先进通信与数据科学研究院,上海200444;2.上海大学特种光纤与光接入网重点实验室,上海200444;3.澳门大学科学技术学院,澳门999078)
语音信号是人与人之间进行交流的一种音频信号,能够有效而方便地实现信息的传输与获取.目前,人们都采用数字信号处理技术对语音进行相关处理,使处理后的语音能够满足工业、军事等不同领域的需求[1].在语音的传输和获取中,如何更好地实现通信成为研究热点.语音通信的一个改进点是传输压缩后的语音数据,减小传输功率.同时,由于通信过程非常复杂,信道中存在的噪声会影响接收端对语音的处理.因此,对含噪语音进行压缩处理时,首先要对语音进行降噪处理,再进行压缩处理.
利用语音信号的稀疏表示来实现语音压缩与降噪是一种重要方法.稀疏表示中的贪婪算法在语音压缩与降噪处理中得到了广泛的应用,如匹配追踪(matching pursuit,MP)算法、正交匹配追踪(orthogonal matching pursuit,OMP)算法等.这些算法均是基于过完备字典展开的,因此如何构建出能更好地实现信号稀疏表示的过完备字典是稀疏表示的一个重要研究方向.目前,常用的字典有Gabor字典、Chirplet字典等,其中Gabor字典具有非常好的时频聚集性,该特点可以使基于Gabor字典的贪婪算法收敛速度较快.因此,基于自适应Gabor子字典的匹配追踪算法(matching pursuit algorithm based on the adaptive Gabor sub-dictionary,GMP)收敛速度较快,从而可以对信号进行稀疏表示,利用这一点可以实现对信号的压缩以及对含噪信号降噪后压缩的目的[2].但是,这类方法在处理较高频率的信号诸如语音信号时,分解结果的稀疏性并不理想.
GMP收敛较慢的原因主要有两点:一是GMP的完备字典中的原子是非正交的,使新得到的原子与前面所得原子张成的子空间并不正交,这样就引入了不期望的分量,在后续的迭代中需要更多的原子才能将这些分量补偿掉,因此该方法需要较大的计算量[2];二是GMP是基于Hilbert空间的贪婪算法,已有研究表明基于再生核Hilbert空间的贪婪算法对信号的稀疏性表示得更好[3-5].因此,本工作在澳门大学钱涛教授提出的自适应傅里叶分解(adaptive Fourier decomposition,AFD)算法的基础上,对AFD的再生核Szeg¨o[6-7]进行正交化形成Takenaka-Malmquist系,即TM系统[8].该系统也被称为单位圆内的有理正交系,解决了GMP的第一个缺点.同时,利用TM系统构建了一种基于再生核Hilbert空间的贪婪算法,即基于Takenaka-Malmquist系的贫婪权值算法(a greedy weight algorithm based on Takenaka-Malmquist system,TMGW).本算法对信号分解的每一步与MP算法类似,都是通过极大选择原理(maximum selection principle,MSP)选择使该步分解系数模值最大的基函数,并找到其在TM系统中对应的列数.本工作假设收发双方使用一个已知的TM系统,此时可以只传递这些分解系数及相应的基函数对应的列数便可得到重构的语音信号.
本工作在Matlab仿真平台上,使用GMP和TMGW分别对来自于TIMIT-Speech-Database的语音数据进行稀疏表示.利用TMGW更适合于对信号稀疏表示的特点,实现了对语音信号的压缩.同时,本算法根据稀疏分解后信号与噪声在时频面上能量分布不同的特点实现了对含噪语音降噪的目的.实验结果表明,如果对一个信号进行稀疏表示需要GMP的m个原子时,只需要TMGW的n个基函数(n?m)即可,即TMGW对信号的稀疏表示效果较好.因此,本算法可以显著提高数据的压缩率,同时可利用对含噪信号的稀疏表示来实现对语音信号的降噪压缩处理.
1 基于TMGW的语音稀疏表示
目前,基于字典的各类贪婪算法如GMP是比较常用的对语音信号进行稀疏表示的方法,但由于GMP中存在原子不正交的缺点,对语音信号进行压缩后的数据量仍然较大.因此,本工作提出了一种基于TMGW的信号稀疏表示方法,可解决GMP对语音信号处理时存在的缺点.
TMGW是一种基于再生核Hilbert空间上Takenaka-Malmquist系的算法,其中Takenaka-Malmquist系被记为其组成函数Bl的表达式如下:

式中:a∈D,D表示开单位圆
j是再生核Szeg¨o.
对于任一语音信号f(t),首先需要将其投影到Hardy空间转换为f+(t).本工作使用Hilbert变换将实值语音信号转化成解析信号f+(t).根据Plemelj定理可得,对于f∈Lp(R),1 6 p<∞,有

式中:H表示实数轴上的Hilbert变换[8].
使用TMGW对f+(t)进行处理.首先,在开单位圆内均匀采样,选取一系列a值,这里的采样间隔设置为0.02[9].a值的分布如图1所示.

图1 序列a的分布Fig.1 Distribution of sequence a

式中:B1(eit)可以根据MSP选出,即B第一步分解后的标准误差.可以证明r仍然属于Hardy空间,以上述方式对r(t)按照式(2)进行分解,可以得到

在上述每一步分解过程中,根据MSP选择基函数Bl(eit)及其系数,并记下Bl(eit)在中对应的列数.当分解的项数l达到设定的阈值n时,就停止对信号的分解,此时根据前l项来重构信号.
当al全部取0时,TMGW就变成了Fourier分解.因此一般来说,凡是Fourier分解可以应用的领域,均可使用TMGW进行处理.根据文献[12]可知,当把式(4)中余项丢弃,可以得到由TMGW重构出的实值语音信号fTMGW,


依此类推,由逐步的余项正交性可以得出能量

由此可得,TMGW每一步分解的能量增益如图2所示[13].

图2 TMGW能量增益Fig.2 Energy gain of TMGW
由图2可以看出,TMGW中每一步分解的能量增益非常大,即TMGW的收敛速度很快.因此,在对语音信号进行重构时,只需要较少的分解项数,压缩率就可以显著提高.
2 基于TMGW的稀疏表示的语音压缩与降噪
2.1 语音压缩与降噪分析
本工作在Matlab平台上使用TMGW对TIMIT-Speech-Database语音数据库中的语音信号进行处理.由上述分析可知,只需传输很少的分解系数及相应的基函数在有理正交矩阵对应的列数便可以实现在接收端重构语音信号的目的,从而减少了传输信号所需的能量.
对于含有噪声的语音信号

式中:fsignal代表原始信号;nnoise代表噪声信号;fsignal的能量大于nnoise的能量.由于对大多数信号而言,能量主要集中在小的时频面上,而随机噪声分散在整个时频面上,因此只要选择一个合适的分解阈值n,就可以由具有良好时频分布的再生核Szeg¨o(eal(z))组成的基函数来逼近原始信号,从而实现降噪的目的.
为了确定合适的分解阈值,首先把经过TMGW处理得到的重构信号fTMGW看成是纯净的语音信号,丢弃的余项r看成是噪声,接着定义重构信号的信噪比SNR1,

最后通过设置SNR1的值便可以得出最佳分解阈值n[13].
本工作使用的语音降噪压缩的TMGW流程图如图3所示.

图3 TMGW流程图Fig.3 Flowchart of TMGW
用于语音降噪的TMGW主要分为三步:第一步是把实值信号f投影为信号f+;第二步是在开单位圆内进行等间隔采样,获取一系列a值,接着利用这些a值并结合式(1)得到离散化的有理正交基矩阵,这里采样间隔设置为0.02;第三步在再生核Hilbert空间上,根据对信号f+进行展开分解,在每一步分解中根据MSP从{中选择Bl(eit)并计算相应的系数cl,当SNR1达到预设值时就停止对信号的分解.此时,丢弃的余项中几乎不包含原始的纯净信号,大部分由噪声信号构成,然后将重构信号再投影回去,得到重构的实值信号,至此便完成了对语音信号的降噪处理.
2.2 语音压缩与去噪处理优化
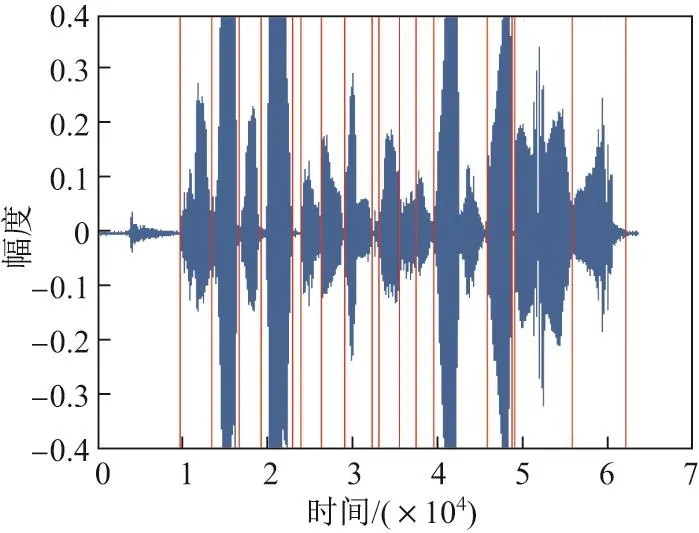
本工作采用TMGW对TIMIT-Speech-Database语音数据库中的“She had your dark suit in greasy wash water all year”这句话按单词长度进行分帧处理.将每一帧语音信号的分解阈值设置为50,可以得出不同帧信号的al分布,如图4所示.
由图4可以看出,al在单位圆上不是均匀分布的,在0.1 图4 不同语音序列的al分布Fig.4 Distribution of sequence alof dif f erent speech 图5 修正后序列a的分布Fig.5 Distribution of modified sequence a 本工作采用GMP与TMGW这两种算法分别对来自TIMIT-Speech-Database的语音数据进行处理,并比较处理效果.不失一般性,实验中设置分解阈值n=50.图6和7给出了处理“dark”单词的仿真结果. 这里定义经TMGW处理得到的重构语音与原始语音的能量误差同理,定义经GMP处理得到的重构语音与原始语音的能量误差fGMP是经过GMP处理得到的重构语音.由图6和7可以看出,当稀疏分解阈值n设置相同时,经TMGW处理得到的fTMGW比经GMP处理得到的fGMP更接近f,即TMGW比GMP更适合应用于语音信号的稀疏分解中,因此TMGW在重构语音时只需要较少的分解项数就能实现语音压缩的目的,从而减少了传输的数据量. 图6 GMP处理结果Fig.6 Processing result of GMP 图7 TMGW处理结果Fig.7 Processing result of TMGW 下面对已处理的TIMIT-Speech-Database语音数据库中的“dark”单词添加信噪比SNR2=5 dB的高斯白噪声,原始信号与被污染后的信号波形如图8所示.然后采用TMGW对含噪信号进行处理,根据2.1节可知当停止分解的条件设置为SNR1>SNR2时,可以确定合适的分解阈值,实现对语音信号去噪的目的,去噪结果如图9所示. 图8 原始语音与被污染语音Fig.8 Original speech and the polluted speech 图9 TMGW处理被污染语音Fig.9 Polluted speech handled by TMGW 通过仿真可以发现,本工作提出的TMGW可以实现滤除语音噪声的目的,而且需要传输的数据量与原始信号相比非常少,达到了去噪后再压缩的目的. 虽然TMGW可以很好地对语音进行压缩,但是算法比较复杂,尤其是每一步分解都涉及内积运算,程序耗时较长.而在内积运算中,待处理的语音信号越长,内积运算消耗的时间越长,而且时间的增长速度是斜率远大于1的非线性增长.因此,采用TMGW对待处理语音信号分别进行分帧处理的优化方法[15],这样在保证压缩语音的同时,实现了提高压缩语音速度的目的. 以处理“She had your dark suit in greasy wash water all year”(长度为63 488)为例(此处向其中添加信噪比SNR2=20 dB的高频噪声),由于TMGW对高频语音信号进行重构时需要较多的分解项数,即需要传输的数据量较大,而滤除语音信号的高频部分并不影响听力效果,因此首先使用低通滤波器将语音信号的高频部分滤除,同时该高频滤波器也可以滤除部分高频噪声.为了确定低通滤波器的通带截止频率wp,首先用快速傅里叶变换(fast Fourier transform,FFT)求取原始语音信号的单边幅度频谱(见图10). 图10 被污染语音的频谱Fig.10 Spectrum of the polluted speech 本工作中的低通滤波器通带截止频率wp是根据能量原则选出的.首先,计算语音信号在整个频带内的能量E,选取wp使得在[0,wp]频带内的语音信号能量大于E的95%.通过计算,wp=4 630 Hz,同时设置阻带截止频率ws=4 830 Hz.Matlab仿真结果如图11所示. 图11 滤波后语音Fig.11 Speech after filtering 通过多种语音分帧方法处理的大量实验结果可以发现,当根据语音波形包络对信号进行分帧时,可使重构的语音与原始语音更加接近.本实验根据包络将该语音分解为14帧(见图12),然后用TMGW对该语音进行处理.由图12可以看出,该音频包含很多静音段,由于静音段不包含任何信息,没必要进行传输,而且根据仿真可知,语音信号的静音段不适合用TMGW进行处理,这里仍然以“dark”单词为例,给出仿真结果如图13所示(不失一般性,设置分解阈值n=50). 图12 语音分帧处理Fig.12 Frame processing of speech 图13 带静音段单词处理结果Fig.13 Result of the word with silent segment 由图13可见,语音信号的静音段不适合用TMGW进行处理,因此将静音段去除,再使用TMGW对语音信号进行处理(见图14),然后将每帧重构出的语音信号及相应的静音段组合起来便可以恢复出原始信号. 图14 不带静音段单词处理结果Fig.14 Result of the word without silent segment 表1给出了评价TMGW处理语音结果的客观指标,如能量误差err、每帧语音处理后的信噪比SNR、消耗时间、传输数据量、对数谱(log spectral distance,LSD)以及压缩率(compression ratio,CR).利用这些指标对重构语音质量进行分析,其中 式中:F(ξ,λ)与FTMGW(ξ,λ)分别表示原始语音与重构语音的短时傅里叶变换(short time Fourier transform,STFT);M表示每帧语音信号的长度;J表示语音的总帧数.这里STFT使用的窗函数是帧长为25 ms,相邻帧的重叠率为50%的汉宁窗.由式(11)可以看出,当LSD的值越小,F(ξ,λ)与FTMGW(ξ,λ)越接近,即重构语音质量越高.当原始语音与重构语音完全一样时,LSD=0[16]. 在使用本工作提出的方法对语音数据进行分帧处理时,将每一帧停止分解的条件设置为CR>50%,其中CR≈2n,因此可以根据设置CR值来确定稀疏分解阈值n.这里CR设置较大的原因是为了使重构能量误差err较小,使重构语音更接近原始语音.同时,为了对总的重构语音数据质量进行衡量,定义分段信噪比(segment signal to noise ratio,SSNR)及主观语音质量评估(perceptual evaluation of speech quality,PESQ)参数对语音数据进行评估.同时给出PESQ的评分等级(见表2). 式中:f(t)表示原始语音;fTMGW(t)表示重构语音;M表示每帧语音信号的长度;J表示语音的总帧数;Nm表示当前语音的帧数[17]. 式中:D表示语音的平均对称干扰度;DA表示语音的平均非对称干扰度. 表1 使用改进方法的处理结果Table 1 Results of using the improved method 表2 PESQ的评分等级[16]Table 2 Rating level of PESQ[16] 由表1可知,每帧语音信号经过稀疏分解后再重构时,得到的重构语音与原始语音的能量误差err和LSD均较小,SNR较大,说明每帧的重构语音均与原始语音接近.同时根据式(12)可得该重构语音的分段信噪比为SSNR=24.38 dB,PESQ=2.999 7,属于良好级别.因此,根据这5个数据可知重构语音的质量较好,接近原始语音.同时在图15中给出了原始语音和经分帧处理合并后得到的重构语音的波形图. 图15 语音分帧处理结果Fig.15 Results of speech framing processing 由图15可以看出,重构出的语音信号与原始语音信号在波形上几乎一样,达到了语音重构的目的.因此,从客观数值评判和主观语音波形观察这两个角度来看,本算法不仅可以实现对语音数据的压缩,而且得到的重构语音质量良好,而如果使用TMGW直接对含噪语音信号进行处理,则需要花费非常长的时间.因此,基于TMGW的语音压缩分帧处理方法在处理语音信号方面具有巨大的应用价值. 本工作针对语音信号的处理问题,利用新型函数变换方法——TMGW来实现对语音信号的压缩和降噪处理.由Matlab仿真可得出,利用TMGW对信号进行表示时比GMP的稀疏度更高,因此更适合应用于语音压缩和去噪领域. 本工作中使用的TMGW对语音的处理效果较好,但是算法比较复杂,尤其是每一步分解中的内积运算会导致程序耗时较长.虽然基于TMGW的语音压缩分帧处理可以减少程序运行时间,但是没有从根本上解决内积运算复杂的问题,因此今后将从这方面对TMGW进行深入研究.目前主要方法有两种:一是利用FFT来简化内积语音运算,从而提高算法的运行速度[18-19];二是将FFT与树形搜索策略、遗传算法等方法结合使用,从而提高程序的运行速度[20-21].此外,对语音去噪建立更加完善的数学模型,使该模型能够对噪声具有良好的自适应性,提高重构语音的信噪比[22].

3 算法仿真结果及分析
3.1 基于GMP和TMGW的语音压缩处理对比


3.2 基于TMGW的含噪语音压缩处理


3.3 基于TMGW的语音压缩分帧处理











4 结束语
猜你喜欢
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
临床骨科杂志(2020年1期)2020-12-12
中国生殖健康(2020年7期)2020-12-10
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
天津诗人(2017年2期)2017-11-29
读者(2016年14期)2016-06-29
