
基于YOLOV4 的智能垃圾分类回收机器人
2020-03-24 03:49王伟杰姚建涛张敏燕
智能计算机与应用 2020年11期
王伟杰,姚建涛,张敏燕,王 敏
(四川工商学院 计算机学院,成都 611745)
0 引言
随着国家对环境问题的重视,以及环保意识逐渐深入人心,垃圾分类的理念也逐渐步入人们的视野。然而对于垃圾分类存在的问题,也急需得到解决。目前市面上清理垃圾的机器人主要分为两类:一是家用的扫地机器人,二是大型的垃圾分拣机器人。前者依靠红外线或者超声波进行避障和充电,只能清扫垃圾,没有分类功能;后者成本太高,只适用于大型的垃圾回收站。基于这些问题,本文设计完成了一款基于图像识别的垃圾回收和计算机视觉智能充电机器人,既能识别和分类回收垃圾,智能避障,也能实现自动充电。
1 现状
由于人们对环境问题越来越重视,尽快解决垃圾分类的话题已被提到议事日程。国家为解决环境问题颁布了一些法律支持,上海市已于2019 年1 月31 日率先通过了《上海市生活垃圾管理条例》,垃圾分类第一次被写入法律。目前中国的垃圾分类回收处理主要面临如下问题:前期垃圾分类阻力大、中期垃圾分类处置不合理、后期生活垃圾处理不够科学[1]。中国的全民垃圾分类目前还处于推广阶段,居民垃圾分类意识不强,很多城市依然采用混合收集方式,这给垃圾处理的中期和后期带来不便。垃圾处理的中期是垃圾中转站对垃圾进行进一步分类,大部分地区没有出台强制性的垃圾分类政策,一部分地区的垃圾中转站并没有对回收的垃圾进行分类和再利用。国内市场上还没有一款针对前期垃圾分类的智能产品,垃圾分类依然需要居民手动分类。
人们生活水平的提高,生活垃圾种类也在不断增加,但市场上还没有适用于家庭和公共场所的人工智能垃圾回收机器人。目前国内市场上垃圾清理机器人技术主要有:激光雷达的传输和感应技术,通过光的折射或者反射对不同的垃圾进行数据的返回,根据射程的距离来实现垃圾分类。而人工智能的出现在增加传统扫地机器人功能的同时,也打破了机器人依靠多个传感器才能运行的传统模式。
2 系统设计
2.1 功能设计
经调研分析,智能垃圾分类机器人的主要功能包括以下几部分:
(1)垃圾识别。机器人会将视觉信息通过树莓派发送给服务器,GPU 服务器会将处理后的目标信息(包括垃圾的类型和位置)返回给机器人。
(2)拾取垃圾并分类。树莓派会根据服务器返回的目标信息执行相应的命令控制机械臂夹取垃圾,并将其放入到相应的垃圾桶中。
(3)智能充电。当机器人的电量低于一定的值时,机器人将会通过摄像头自动检测周围是否有插座,当识别到插座时,机器人会通过机械臂将充电插头插入到插座中。
2.2 硬件设计
系统用到的硬件设备主要包含:摄像头、机械臂(含机械臂驱动模块)、电机(含电机驱动块)、树莓派、电池、底座(含履带)等。硬件结构如图1 所示。
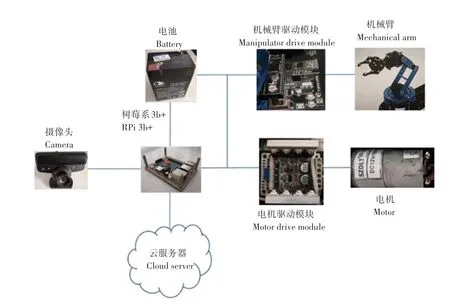
图1 硬件结构图Fig.1 Hardware structure diagram
其中:摄像头采用的是1080p 高清usb 工业摄像头;机械臂驱动模块采用插卡式设计,系统采用STM32 控制板,支持PC 图形化、代码编程以及脱机运行,提供正运动学分析和逆运动学分析;电机驱动模块开关频率高,可有效避免调试电机频率低带来的问题;树莓派使用的是Raspberry pi 3 Model B+,板卡配备64 位的1.4GHz 四核ARM Cortex-A53 处理器,该设备的双频无线局域网具有模块化的兼容性;系统使用铝电池,主要为机械臂舵机、小车电机、以及树莓派供电;电机型号为985 低速版,额定转速为12 V 3 000 r/min;机械臂由合金机械爪、6 个数字舵机(包含3 个防烧防堵转舵机)、全金属旋转底盘以及若干铝合金支架构成。
2.3 软件架构
软件架构如图3 所示。它主要有二种模式,即垃圾识别分类模式和智能充电模式,默认模式为垃圾识别分类模式。通过将摄像头获取的视觉信息传输给树莓派,再由树莓派传输给系统后端,后端GPU 服务器将会对该视觉信息进行处理,并将目标的位置信息和类别信息传输给树莓派。树莓派执行相应指令,调整摄像头的位置(摄像头在机械臂上),同时驱动电机靠近目标,直到调整到合适的位置,树莓派才会给机械臂驱动模块发送夹取的命令,机械臂根据对应目标类别信息放入到自带的对应垃圾桶中。并且会再次判断目标是否夹取成功,若失败将再次调整机器人与目标之间的位置。如果多次夹取失败,树莓派会将其相关信息发送给服务器,研究人员会对其进行分析和做相关处理。
智能充电的原理与垃圾识别分类的原理相似。当电池电量下降到相应值时(第一阈值),树莓派自动将模式切换为智能充电模式。该模式下机器人会自动寻找插座,当机器人识别到插座时,树莓派会执行相应命令调整摄像头,并驱动电机靠近插座,机械臂再将机器人充电器夹起,并调整机械臂位置,直到充电器插入插座。树莓派会判断该插座是否有电,如无电,则取出充电器寻找其他的插座。若电量低于第二阈值时,此时机器人的电量已经不够其完成自动充电,机器人会停留在原地给后端发送位置坐标,以便相关人员能够找到。软件逻辑关系如图2所示。
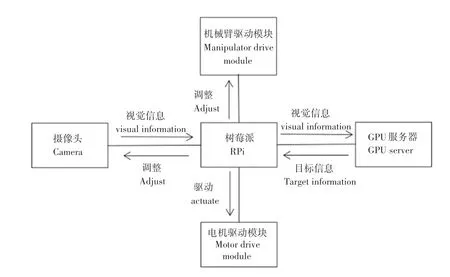
图2 软件逻辑图Fig.2 Software logic diagram
2.4 算法设计
2.4.1 Yolov4 目标检测算法概述
Yolov4[2]是Yolov3[3]的改进版,无论在精度还是速度上Yolov4 都碾压了Yolov3。YoLov4 原文作者在论文中提到,在进行bounding box regression 时,传统的目标检测算法(如Yolov3)都是根据预测框和真实框的中心点坐标,以及宽高信息设定MSE(均方误差)损失函数,Yolov3 的总损失函数公式如式(1):
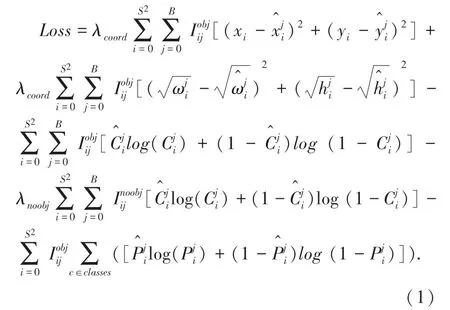
MSE 损失函数包括3 个部分:即预测框的位置损失、预测框预测的类别损失和预测框置信度损失。MSE 损失函数将检测框中心点坐标和宽高等信息作为独立的变量对待,但实际上这些信息之间是有联系的。因此,Yolov4 的作者将MSE 替换为CIOU(Complete-IoU)。CIOU 考虑到3 个几何因素,即重叠面积、中心点距离和长宽比。CIoU 的惩罚项是在DIoU 的惩罚项基础上加了影响因子α和ν,这个因子把预测框长宽比拟合目标框的长宽比考虑进去。其中α是用做trade-off 的参数,v是用来衡量长宽比一致性的参数[4],具体公式如式(2)、式(3):
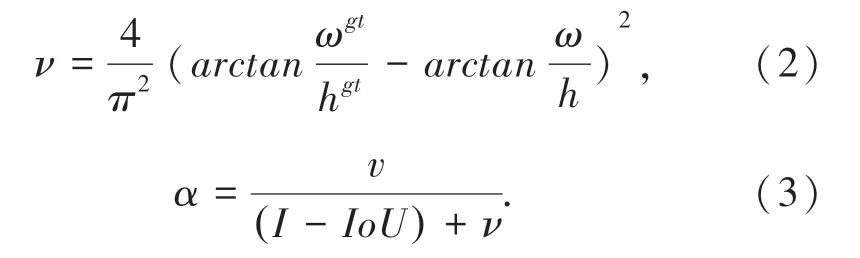
其中,ωgt和hgt为真实框的宽和高,ω和h为预测框的宽和高。如果真实框和预测框的宽和高一样,则v为0,即该惩罚项失效。其次Yolov4 将DarknetConv2D 的激活函数由ReLU 修改成了Mish,如公式(4):
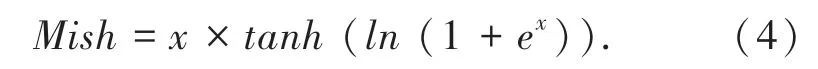
相比ReLU 激活函数,Mish 激活函数的输出更为平滑,而平滑的激活函数可以让更好的信息进入神经网络,从而使模型得到更好的泛化能力,避免过拟合。其次,是将resblock_body 的结构进行了修改,运用了CSPnet 结构。运用这种结构的作用是在降低计算量的同时增加模型的精准度,CSPnet 结构如图3 所示。
图3 CSPnet 结构Fig.3 CSPnet structure
Yolov4 采用了PANet(用于实例分割的路径聚合网络)[5]的结构,将低层与高层的特征进行融合,提高目标检测的精度,尤其是对小目标识别的精度。PANet 总体上是Mask-Rcnn 的改进版[6],整体思路为提高信息流在网络中的传输速度。其主要在3 方面进行了改进:
(1)提出了Bottom-up Path Augmentation,它能提高底层特征信息的利用率,加快底层特征信息的传输效率;
(2)提出了Adaptive Feature Pooling,在提高特征提取速度的同时也保证了特性信息的利用率;
(3)提出了Fully-connected Fusion,提高了mask 的生成质量。
为解决小目标检测准确度低的问题,Yolov4 作者在其算法中引入了马赛克数据增强算法。其原理是从数据集中每次读取4 张图片,然后对这4 张图片进行翻转、缩放、色域变化等,如图4 所示。最后将其组合在一起,如图5 所示。

图4 图片的翻转、缩放、色域变化Fig.4 Flip,zoom,gamut change

图5 图片的拼接结果Fig.5 The Mosaic result of the picture
2.4.2 目标检测实现
本文基于Yolov4 实现目标检测,Yolo Head 会根据前面提取的特征层进行预测,不断调整先验框的大小和位置,使其生成最后的预测框。经过主干网络的特征提取,可以得到shape 为(N,52,52,255)、(N,26,26,255)和(N,13,13,255)的特征层,而每个特征层上会有3 个预设好的anchor box,总共会聚类9 个anchor box。对于输入图片为416x416时,在13x13 的特征图中由于其感受野最广,适合检测大目标,所以分配最大的 anchor box,即(116x90)、(156x198)、(373x326)。在26x26 的特征图中,它的感受野处于中等水平,适合检测中等大小的目标,所以分配中等大的anchor box,即(30x61),(62x45),(59x119)。在52x52 的特征图中,感受野最小,适合检测小目标,所以分配最小的anchor box,即(10x13),(16x30),(33x23)。边框预测公式为式(5)~式(8):
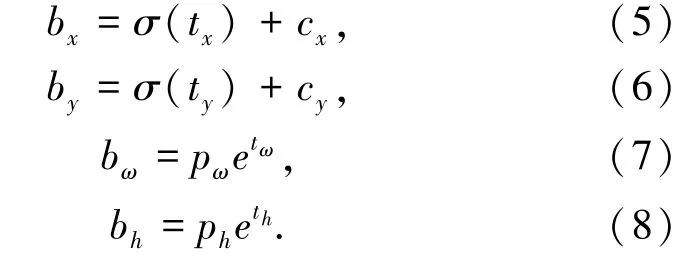
通过上面的公式可以得到边界框相对于特征映射的位置和大小,但网络实际学习的目标是tx、ty、tw、th 这4 个参数。由于Yolov4 的输出是一个卷积特征图,其中包含了特征图深度的边界框属性,而边界框的属性又由彼此堆叠的单元格测出,这种格式对输出值的处理很不方便。
其中tx和ty是预测的坐标偏移值,tw和th是尺度缩放,根据前面的公式可以求出真实的预测框坐标。求tx,ty,tw,th的公式如式(9)~式(12):
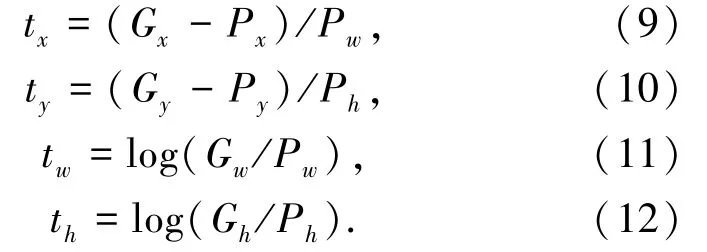
每张特征图上有3 个先验框,具体哪个先验框预测目标,需要在训练中确定,即由IOU 最大的先验框来预测,而其余的两个先验框不会和ground truth 匹配。最后根据得到的tx,ty,tw,th来对先验框进行微调,使其与ground truth 重合,得到最后的预测框。
3 实验结果与分析
3.1 数据集制作
首先收集图片,使用Python 程序将所有图片重命名,使用Labelimg 给每个图片的object 打上标签,生成的目标信息保存于对应的”.XML”文件里。本研究采用的是VOC 格式的数据集,训练前将“.jpg”文件放在VOC2007 文件夹中的JPEGlmages 目录,标签文件放在VOC2007 中的Annotation 目录中。在VOC2007 目录中运行test.py,会生成4 个.txt 文件,即train.txt、val.txt、test.txt 和trainval.txt。修改voc_label.py 中的相关参数(sets 和classess)的值,然后运行该代码,会生成3 个文件2007_train.txt、2007_val.txt、2007_test.txt,并在VOC2007 中生成一个labels 文件夹。
3.2 训练神经网络
上述生成的labels 文件夹中txt 文件,是训练真正用到的数据集,其中存放每张图片的绝对路径和真实框的位置。训练的命令也比较简单:./darknet detector train cfg/obj.data cfg/yolo-obj.cfg yolov4.conv.137。当神经网络的loss 值几乎不变时,则可停止训练。
3.3 结果分析
实验使用2 500 张图片来测试模型的精度,具体数据见表1。
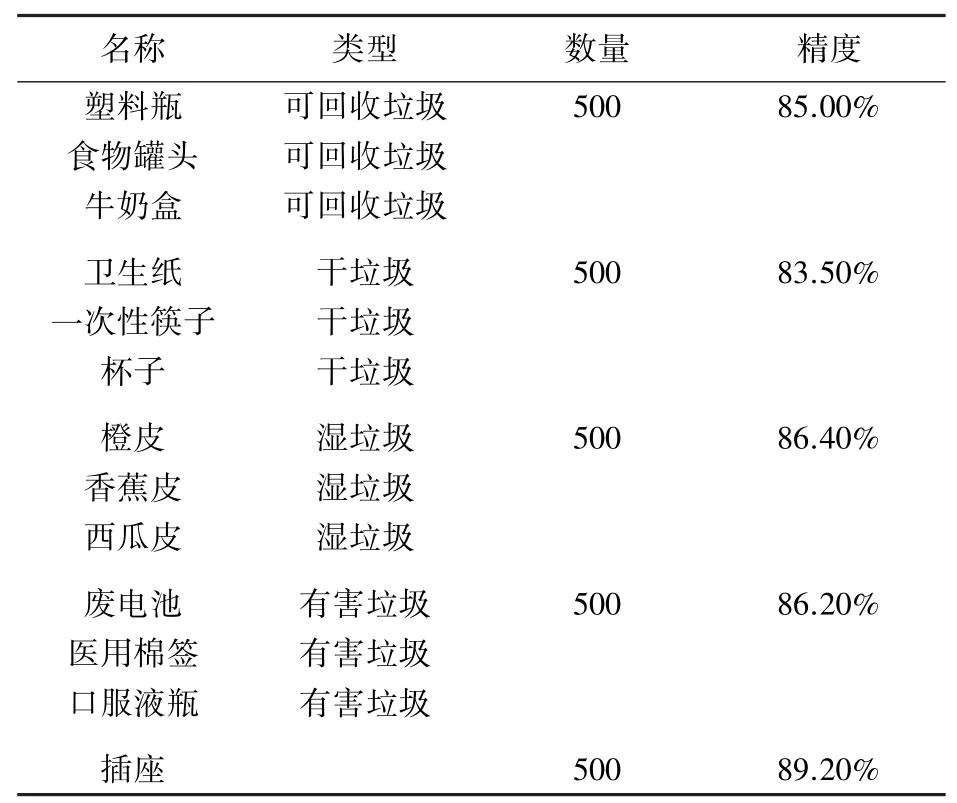
表1 模型测试精度表Tab.1 Model test accuracy table
从表中可以看出,模型对插座的识别精度最高,对干垃圾的识别精度最低。可能是选取干垃圾的训练图片特征不太明显或图片量太少而导致模型对该类别的收敛不及其它类别。因此,可以寻找特征更为明显的干垃圾图片,加入到训练集中,这样其识别精度应该会有所提高。另外,本模型的平均精度为86.06%,能识别的垃圾种类很少,离理想的模型还是有一定的距离,需扩充训练集图片的数量和种类,优化识别算法,使模型更加完善。
4 结束语
本研究是基于Yolov4 目标检测算法,将图像信息传输给树莓派,再由树莓派传输给服务器,服务器会根据相应算法进行处理后,将处理的数据传回到树莓派中。机器人通过芯片的返回数据执行相应的操作,将垃圾进行分类。自动充电和自动避障也是相同的原理来实现的。该机器人获取外界信息靠的是摄像头,而非各种传感器,这种设计不仅能减轻机器人的质量,提升机器人的灵活性,也大大减少了使用其它传感器产生的费用。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
汽车工程师(2021年12期)2022-01-18
红蜻蜓·中年级(2021年8期)2021-08-25
广东第二课堂·初中(2018年12期)2018-02-13
农产品市场周刊(2016年43期)2016-12-23
农产品市场周刊(2016年43期)2016-12-23
学苑创造·C版(2016年10期)2016-11-19
电脑爱好者(2016年6期)2016-04-01
学苑创造·A版(2016年1期)2016-03-10
中学生博览(2015年18期)2015-11-06
