
基于分组SIFT 的图像复制粘贴篡改快速检测算法
2020-04-06 08:24肖斌景如霞毕秀丽马建峰
通信学报 2020年3期
肖斌,景如霞,毕秀丽,马建峰
(1.重庆邮电大学图像认知重点实验室,重庆 400065;2.西安电子科技大学网络与信息安全学院,陕西 西安 710071)
1 引言
随着互联网技术的快速发展,人们从网络上获取信息变得极其容易。同时,人们借助强大的图像编辑软件,可以轻松地篡改数字图像的内容。如果大量篡改图像在互联网上广泛传播,将会导致诸多不良影响。因此,判定一幅图像是否为真实图像变得尤其重要。现有的数字图像篡改方法主要包括重采样、复制粘贴、剪切以及删除对象。其中,复制粘贴篡改是指复制原始图像的一个区域或者多个区域并粘贴到同一幅图像的某个区域,以达到掩盖或增加图像内容的目的。一个复制粘贴篡改的例子如图1 所示,图1(a)为篡改图像,图1(b)指示了篡改图像中的篡改区域。本文旨在研究图像的复制粘贴篡改问题,提出快速、有效、准确的图像复制粘贴篡改检测算法。

图1 复制粘贴篡改图像及其真实篡改区域
多年来,图像篡改问题引起了研究人员的广泛关注,他们发现大多数图像进行篡改操作后会导致某些固有的图像统计数据失真,因此可以通过分析这些统计数据来识别图像是否被篡改。现有篡改检测方法的基本操作流程可分为预处理、特征提取、特征匹配、后处理。预处理操作将输入图像转换到灰度空间或者其他彩色空间(如HSB、YCbCr 等);特征提取操作从不同的图像区域(如重叠规则块、非重叠不规则块、高熵区域等)提取特征,所提取特征的描述能力和抗攻击能力直接影响最终检测效果,是复制粘贴篡改检测方法的关键阶段;特征匹配操作通过提取的特征进行匹配筛选,根据匹配特征的位置确定篡改区域;后处理操作从匹配的信息中过滤掉异常值,然后对剩余信息进行处理,得到最终检测结果。通常,根据提取特征区域的类型,可以将复制粘贴篡改检测方法分为3类,分别为基于图像块的检测方法、基于特征点的检测方法、基于分割的检测方法。
基于图像块的检测方法首先把图像分成重叠的规则块,利用各种变换提取每个块的特征;然后利用块的特征向量实现块匹配。已有的基于图像块的检测方法如表1 所示,主要采用的特征提取方法包括离散余弦变换(DCT,discrete cosine transform)[1]、奇异值分解(SVD,signal value decomposition)[2]、主成分分析(PCA,principle component analysis)和离散小波变换(DWT,discrete wavelet transform)[3]、方向梯度直方图(HOG,histogram of orientation gradient)[4]、Krawtchouk 矩阵(Krawtchouk moment)[5]、Zernike 矩阵(Zernike moment)[6-7]、极性复数指数变换矩阵和YCbCr 颜色空间(polar complex exponential transform moment and YCbCr color)[8]、极性复数变换矩阵(polar complex transform moment)[9]、一维描述符(1-D descriptors)[10]、一致性敏感哈希(coherency sensitive hashing)[11]、空间和颜色模型(spatial and color rich model)[12]等。为了提升检测算法的抗攻击能力,文献[6]算法利用Zernike 矩阵和局部敏感哈希进行块匹配来定位篡改区域;文献[10]算法将重叠的像素块映射到对数极坐标,在极坐标空间生成一维描述符。为了降低算法的时间复杂度,文献[11]算法应用增强一致性敏感哈希算法来建立特征对应关系,通过迭代细化特征对应关系最终定位篡改区域。由于采用重叠块,基于块检测的检测方法具有很好的检测效果,但由于需要匹配筛选的块特征数量很大,因此此类检测方法的计算时间复杂度都比较高。

表1 基于图像块检测方法的特征提取方法、匹配方法
基于特征点的检测方法通过提取图像的局部角点或者极值点作为特征向量进行匹配,定位篡改区域。已有的基于特征点的检测方法如表2 所示,主要采用的特征提取方法包括加速稳健特征(SURF,speeded up robust feature)[13]、基于多支持区域的梯度直方图(MROCH,multi-support-region order based gradient histogram)[14]、二进制稳健性不变可扩展关键点(BRISK,binary robust invariant scalable keypoint)[15]、双阈值 SIFT 描述符(dual-threshold SIFT descriptor)[16]、Harris 角点(Harris corner point)[17]、SIFT 描述符和Zernike 矩阵(SIFT descriptor and Zernike moment)[18]、尺度不变特征变换(SIFT,scale-invariant feature transform)[19-21]。由于提取的特征点数量比重叠块数量少,因此该类方法的特征匹配和后处理的计算时间复杂度比基于块的检测方法低。同时,由于特征点具有很好的抗变换能力,因此该方法稳健性强。但是,如果篡改图像对比度较低或者以有损格式保存,提取特征点的数量会急剧降低,导致检测效果不佳。

表2 基于特征点检测方法的特征提取方法、匹配方法
为了解决上述2 类方法存在的问题,研究者们提出了基于分割的检测方法[22-25]。已有的基于分割的检测方法如表3 所示,该类方法先将输入图像分组为超像素,然后从超像素中提取特征点进行匹配。在大多数情况下,不规则且不重叠的图像块不仅能比常规块更好地定位篡改区域,还能降低计算时间复杂度。然而,基于分割的检测算法依赖于初始分割设置,即超像素的初始大小。

表3 基于分割检测方法的特征提取方法、匹配方法
综上所述,以上3 类检测方法主要解决的问题集中于保持检测效果和减少计算时间复杂度。本文研究发现,3 类检测方法的特征匹配方法大都是穷举搜索匹配。穷举搜索匹配虽然效果好,但是会大大增加计算时间复杂度。因此,本文提出了基于SIFT 分组的图像复制粘贴篡改快速检测算法。该算法采用类间匹配的思想,即通过计算结构张量属性对超像素进行分类,相同类的超像素进行块内SIFT特征点匹配。通过类间匹配思想快速准确定位篡改区域,同时保证较好的稳健性。
2 基于分组SIFT 的检测算法
基于分组SIFT 的图像复制粘贴篡改快速检测算法流程如图2 所示,包含4 个步骤,分别为块划分、块特征提取、块分类、块类间匹配。
步骤 1应用简单线性迭代聚类(SLIC,simple linear iterative clustering)算法对输入图像进行块划分。
基于图像块的检测算法都是预先定义块的大小,然后将输入图像划分为重叠且规则的块,最后通过匹配块来定位篡改区域。定位的篡改区域由规则块组成,准确度不高。同时,当待检测图像增大时,重叠块数量增加,块特征的匹配计算时间复杂度也会随之上升。因此,本文采用SLIC[22]将输入图像分为不重叠且不规则的图像块。SLIC 算法采用k-means 聚类生成超像素,主要包含2 个步骤:初始化聚类中心、迭代寻找最佳的聚类中心。
步骤2从图像块中提取SIFT 特征点作为块特征。
特征点提取方法SIFT[15,26]和SURF(speeded up robust features)[27]已广泛应用于计算机视觉领域,SIFT和SURF特征点已被广泛证明对于常见的图像处理操作(如旋转、缩放等)具有稳健性。因此,SIFT和SURF常用作现有基于特征点的复制粘贴篡改检测方法中的特征点提取方法。Christlein 等[28]研究表明,SIFT 具有更稳定和更好的性能。所以本文方法选择SIFT 作为特征点提取方法。
步骤3利用结构张量划分图像块的类别。
结构张量[29-32]描述了一个点的指定邻域中的梯度方向,以及这些方向相关的程度。在图像处理中,结构张量是由偏导数表示的矩阵,用来表示边缘信息并描述局部模式。图像I 的结构张量S 通常被定义为I 的一阶偏导数的局部协方差矩阵。I 是根据先前估计的梯度∇I =[IxIy]构建的,其中Ix=I ∗ Dx,Iy=I ∗ Dy,Ix和Iy分别表示x 方向和y 方向的梯度,∗表示卷积,Dx和Dy是卷积核。I 使用高斯卷积核来估算离散域中偏导数。然后通过梯度外积的空间平滑来计算结构张量S 。

图2 基于分组SIFT 的复制粘贴篡改快速检测算法流程

其中,结构张量S 与输入图像I 具有相同的尺寸,即相同数量的线和列。S 是结构张量 S(z)在位置z的对称半正定矩阵的矩阵值。在每个位置z,S(z)的特征值分解为2 个非负特征值 λ1(z)和 λ2(z),显示局部图像边缘的强度,即方向变化的强度;以及2 个对应的特征向量e1(z)=[e1x(z)e1y(z)]和e2(z)=[e2x(z)e2y(z)],e1(z)和 e2(z)正交且平行于局部边缘。根据与 λ1(z)相关联的特征向量 e1(z)计算局部方向趋势 O(z),其范围在之间。

本文利用结构张量计算每个块中每类像素所占比例,根据比例判定图像块是平坦块、边缘块还是角点块。假设p1、p2、p3分别表示某个块中平坦像素、边缘像素、角点像素的个数,则有

其中,pi表示某一个块中某类像素的总数,i=1,2,3;per(pi)表示不同类别像素在每个块中所占的比例。某图像块内不同类像素所占的比例根据式(5)判别得到其类别。

其中,q=1表示平坦块;q=0表示边缘块;q=-1表示角点块;ε1和ε2为平坦像素和边缘像素的比例阈值,即块分类阈值,两者的具体取值将在3.3 节中介绍。
步骤4采用类间匹配的思想进行匹配。
根据步骤3 所得的分类块,在每类中进行SIFT特征点匹配。采用欧几里得距离进行相似性度量。在这些块中,当2 个特征点描述符的欧几里得距离满足式(6)时,特征点 fa(xa,ya)与 fb(xb,yb)匹配。

其中,d(fa,fb)和 d(fa,fi)分别如式(7)和式(8)所示。

其中,i 表示第i 个特征点,n 表示相应的类别块中特征点的数量,threshold 表示特征点匹配阈值。threshold 越大,匹配精度越高,错误匹配的概率也越高。本文根据大量实验,设定特征点匹配阈值为3.5。
3 实验结果与分析
本节对所提检测算法进行验证和分析,并将其与现有复制粘贴篡改检测算法进行比较。所有实验都是在Intel(R)Core(TM)i5-4590 CPU @3.30 Hz的PC(Matlab 2018a,Win7)平台上进行的。为了确保实验的可行性,利用实验数据库来自公共数据集。
3.1 数据集
实验数据集由人物、风景、动物等图像组成,其篡改区域的类型主要为平滑区域和粗糙区域。数据集由612 幅图像组成,其中原始图像36 幅,篡改+攻击图像576 幅。数据集的攻击类型包括旋转、尺度缩放。本文将实验所使用的数据集命名为CMFD,其构成如表4 所示。

表4 数据集CMFD
3.2 评价参数
本文实验部分所参考的评价参数为准确率(Precision)、召回率(Recall)以及F 值。评价参数计算方式如下。

其中,TP表示检测结果中正确检测为篡改区域的像素总量,FP表示检测结果中错误检测为篡改区域的像素总量,FN表示检测结果中未被检测出的篡改像素总量。实验部分出现的Precision、Recall、F 都是所使用数据集检测结果的平均值。
3.3 参数设置
本文所提算法中,块分类阈值会影响图像块的分类,进而影响块类间匹配,最终影响检测时间复杂度以及检测效果。因此,为精确地对图像块进行分类,并减少块匹配的错误概率及时间复杂度,本文通过实验对比分析来确定块分类阈值,在保证算法检测效果的同时使算法具有较低时间复杂度。实验分别对块分类阈值的取值选择做了各种组合,检测结果分别如表5 和表6 所示,其中Time_1 和Time_2 分别表示检测图像大小为1 024 像素×768 像素(低分辨率)和3 000 像素×2 000 像素(高分辨率)的平均运行时间,Precision、Recall、F 分别表示检测结果的准确率、召回率和F 值。从表5 和表6 可以看出,当取不同的值时,算法的性能表现不一致。当检测低分辨率图像时,检测时间复杂度差异较小,但是检测准确率和召回率差异较大,其原因是阈值取值不当,在对图像块分类时,造成图像块分类出现错误,使图像块匹配不当。当检测高分辨率图像像素时,不同的块分类阈值对检测的准确率和召回率影响较小,但是对于检测时间复杂度影响较大,其原因是在对块分类时,难以精准地把图像块分为3 类,而是错误地将图像块分为了2 类或者一类,未达到分类的效果,进而采用类间匹配的方法出现失效的情况,导致匹配阶段时间复杂度上升。由于低分辨率图像总的图像块比较少,即使图像块的类别较少,在采用类间匹配时,对时间复杂度影响较小。根据实验结果分析可得,当阈值为ε1=0.9,ε2=0.3时,算法可以获得最优的检测效果,同时具有较低的时间复杂度。

表5 ε1=0.9,ε2变化时的复制粘贴篡改检测结果Precision、Recall、F 和运行时间

表6 ε2=0.3,ε1变化时的复制粘贴篡改检测结果Precision、Recall、F 和运行时间
3.4 评价实验及对比分析
随机选取本文算法的6 组检测结果作为示例,如图3 所示。其中,图3(a1)~图3(a6)表示篡改图像,图3(b1)~图3(b6)表示真实篡改区域,图3(c1)~图3(c6)表示本文算法的检测结果。图3 的示例是复制粘贴篡改的理想情况,在这种情况下,只将图像的一部分复制粘贴到同一图像中而不对图像进行任何攻击。
本节选取了文献[6,10-12,21-22]算法作为对比算法,进一步验证本文算法的有效性。表7 中展示了不同算法检测结果的Precision、Recall、F值和运行时间。由表7 可知,本文算法的时间复杂度高于文献[11]算法,低于其他对比算法;虽然文献[11]算法的时间复杂度低,但其F 值低于本文算法。由于对图像块进行分类,在匹配阶段采用类间匹配会在一定程度上减少检测时间复杂度,但是随着图像大小逐渐增大,图像块的数量也随之增加,进而时间复杂度也会随之上升。从表7 中可以看出,本文算法的Precision 高于其他算法,但是Recall 和F 并不理想,说明有漏检的篡改区域。其原因是图像块分类不够精准,导致块匹配过程中图像块没有完全被正确匹配。以上情况说明选择最佳的固定阈值时,虽然检测效果比较好,但是如果能根据每幅图像自身的规律自适应地计算分类阈值,从而对图像块进行分类,检测效果会有明显提升,这也是未来需要展开的工作。

图3 本文算法检测结果

表7 不同算法检测结果Precision、Recall、F 和运行时间
本节测试了本文算法和对比算法在不同类型、不同程度攻击下的检测效果,结果如图4 所示。图4(a)和图4(d)表示各算法在不同攻击下检测结果的Precision,图4(b)和图4(e)表示各算法在不同攻击下检测结果的Recall,图4(c)和图4(f)表示各算法在不同攻击下检测结果的F。从图4 可以看出,在旋转和尺度攻击下,本文算法都展示了较好、较稳定的检测结果。
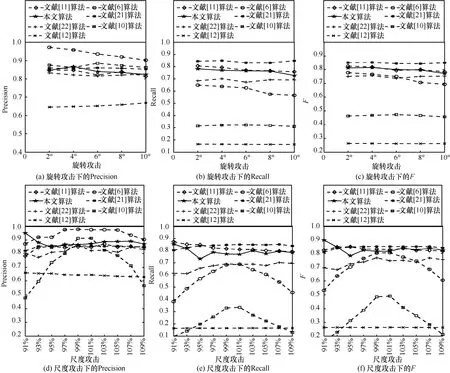
图4 不同算法的检测效果
4 结束语
现有的复制粘贴篡改检测算法的匹配阶段大多采用穷举搜索,导致检测过程的计算复杂度较高。针对这一问题,本文提出了一种基于SIFT 分组的图像复制粘贴篡改检测算法,将图像块进行分类,对相同类的图像块进行SIFT 特征点匹配。实验结果表明,本文算法检测效果较好,时间复杂度大多优于其他几种对比算法。但本文算法也存在不足之处,算法对块进行分类时采用固定阈值,当篡改区域与周围区域的对比度非常相近时,采用固定阈值会降低算法的检测准确度。在未来的工作中,将继续研究自适应方法对图像块进行分类,进一步提升算法的效果。
猜你喜欢
建材发展导向(2021年19期)2021-12-06
陕西档案(2021年4期)2021-09-22
成都信息工程大学学报(2021年6期)2021-02-12
临床骨科杂志(2020年1期)2020-12-12
智族GQ(2020年7期)2020-08-20
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
计算机与网络(2019年3期)2019-09-10
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
火控雷达技术(2016年3期)2016-02-06
探测与控制学报(2015年4期)2015-12-15
