
倒排索引压缩算法研究综述
2020-04-10 05:15宋省身杨岳湘
小型微型计算机系统 2020年4期
姜 琨,朱 磊,宋省身,杨岳湘
1(西安理工大学 计算机科学与工程学院, 西安 710048)2(国防科技大学 计算机学院, 长沙 410073)
1 引 言
不断增长的网页数量和查询请求量对搜索引擎的性能提出非常大的挑战[1,2].互联网中的网页数量呈指数增长, 搜索引擎为了保持索引信息的全面性,需要不断地采集新出现的网页和更新已索引的网页.目前,主流的搜索引擎如Google、百度其网页索引量都超过了百亿,但这也只占了整个互联网中不到10%的网页信息[3].根据Netcraft统计,截至2014年9月份互联网上已经拥有近10亿个网站[注]Total number of Websites.http://www.internetlivestats.com/total-number-of-websites.2019.05.The size of the world wide web.http://www.worldwidewebsize.com.2019.05..正如《第43次中国互联网网络发展统计报告》指出,截至2018年底国内的网页总量就达到2816亿个,较2017年底增长了8.2%[4].近年来,互联网上更多自媒体如Twitter、Quora、知乎等应用的蓬勃发展使得搜索引擎系统待索引的数据规模进一步增加[5,6].面向海量互联网网页数据的磁盘压缩倒排索引数据非常庞大,拥有仅5千万个网页的Clueweb09(B)数据集的压缩索引就达到15GB(包含词典文件和倒排文件),更不用说针对整个海量互联网网页的倒排索引数据[7].这些海量互联网网页数据给搜索引擎系统的倒排索引存储和处理带来了持续的挑战和研究需求[2-8].此外,搜索引擎每天需要处理数亿次查询请求,相当于每秒处理数千个查询,并且这些查询请求往往需要实时返回查询结果[2].海量数据、海量查询、实时响应的应用需求对搜索引擎的存储和查询性能提出了很大挑战[8].
研究表明,利用倒排索引压缩技术可以极大的降低倒排索引数据的磁盘存储空间开销,并使更多的数据可以被加载到内存中;通过结合高效的解压操作就能达到对海量磁盘压缩索引数据的快速查询访问[9].因此,倒排索引压缩技术就成为提升海量倒排索引数据存储和查询性能的必要手段[10],而研究人员也展开了大量针对倒排索引压缩算法及其在搜索引擎系统应用中的性能优化研究[9,11].倒排索引压缩技术可以直接提升单个服务节点对索引数据的存储性能.在磁盘上,索引压缩技术可以使数据的存储更加紧密,这就降低了数据访问过程中的磁盘寻道延迟[12].更重要的是,索引压缩使得更多的索引数据可以直接加载到内存中,现代计算机采用存储器层来为处理器提供数据访问支持,最上层的缓存容量小,速度很快.依次向下层存储器的容量将变大,但是速度变慢[13].倒排索引压缩能够使得更多的索引数据存入上层的存储器中[14].可以看出,倒排索引压缩技术实际上关系到搜索引擎的索引存储、更新和查询性能,因此对倒排索引压缩算法的研究在商业搜索引擎公司和学术领域上都属于热点与难点问题.
本文对当前倒排索引压缩技术的发展动态进行综述,对倒排索引压缩算法和应用进行系统化地总结,以期望能够应对这一领域研究面临的新的挑战并为进一步的研究工作提供帮助.
2 传统倒排索引压缩算法
在拥有大规模索引数据的搜索引擎中,倒排索引被证明是一种非常高效的数据结构[15,16].基本的倒排索引主要由词典和倒排链表两部分组成.词典由大量的词项组成,主要用来记录整个文档集合中出现过的词项和对应的倒排链表指针.倒排链表记录了该词项在不同文档中的命中信息、位置信息或者预计算分数等信息.在实际应用中,词典文件比起倒排文件来说通常要小得多,所以当前研究人员主要集中于对倒排链表压缩算法的研究[17,18].倒排链表存储在磁盘上,每个从磁盘读取的数据块(block)包含一定数量的倒排链表的数据段(data chunk,DC).每个数据段作为压缩算法处理的基本单位,包含着一串被压缩的整数序列.每个数据段包含一组docid和对应的一组freq.图1给出倒排链表的数据块和数据段的关系.
在倒排链表压缩过程中,各个倒排项都包含文档号(docid)信息,并且每个词项的倒排链表中的倒排项按文档号从小到大进行排列.这使得在存储文档号docid信息时,可以存储文档号docid之间的差值d-gap来提升倒排链表的压缩率.文档重排技术可以使得d-gap数值进一步降低而提升倒排索引的压缩率[19,20].根据Shannon的分析,分布概率为P(x)的数字的最优压缩比特长度为-「log2P(x)⎤[12];此外,互联网网页中词项的文档频率服从Zipf定律(幂定律)[21].因此,倒排索引压缩的目的就是采用尽可能接近最优比特长度的编码来表示一个原来以32或64位机器字表示的d-gap整数.我们称压缩状态下的编码为码字(code word).
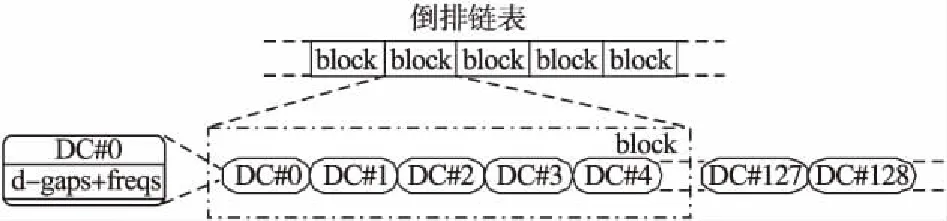
图1 倒排链表结构的数据块和数据段关系图Fig.1 Inverted lists of data blocks and data chunks
传统的符号压缩算法如Huffman编码、算术编码、PPM等半静态或者自适应压缩方法需要预先知道被压缩符号的统计信息并保留其压缩模型,而互联网网页较快的更新速度使得d-gap序列不稳定且无法为每个倒排链表d-gap序列保留一个稳定的压缩模型[22].另外,更加复杂的词典方法如LZ77、LZW等也较少应用在倒排索引压缩中,这是因为倒排链表d-gap序列的语义重复度要比符号序列小很多[23].因此,倒排索引压缩算法的研究主要集中在不需要统计信息的轻量级压缩(light-weighted compression)[24,25].倒排链表的压缩算法按码字对齐的方式可以分为:比特对齐(bit-aligned)压缩算法和字节对齐(byte-aligned)压缩算法.
比特对齐压缩算法为给定每一个待压缩整数分配一个对应的码字,而压缩的过程就相当于对输入序列的符号替换.这些方法根据压缩的模型,一般可以分为全局方法和局部方法,全局方法的码字不依赖于输入序列,对所有的输入都使用同一模型进行压缩,这类算法有Unary、Gamma、Delta、Golomb、Rice等[12,22,26,27];局部方法则根据输入的变化适当调整模型的参数,如Interpolative Code[28].局部模型在压缩效果方面要优于全局模型,但解压过程的性能要比全局模型差.这类压缩算法具有较高的压缩率,但在解压的时候频繁的位操作运算会大大地降低效率.
为了加快压缩和解压速度,进而出现了字节对齐压缩算法,如Varint(又称为variable byte或者vbyte)、Group Varint等[1,29,30].它们的基本思想是使用字节的低7位来存储数据,最高位作为压缩结束的标识符.字节对齐的压缩方式可能会浪费一部分空间,但解压的速度要远高于比特对齐压缩算法.在字节对齐压缩算法的基础上,Google公司提出并采用的Group Varint倒排索引压缩算法可以大大提升Varint的解压性能[1].它通过将原来由Varint压缩的4个数字改为一次性压缩来进一步减少分支判断,结合硬编码(hard-coding)和移位(shifting)方法可以达到更好的压缩/解压性能.这是因为Group Varint对多个字节的状态位进行统一存储,这样就可以在单次数据操作中压缩多个数字.这也表明一次性压缩多个整数能提升压缩和解压的性能.此外,研究人员为了提高算法的压缩率而提出了Nibble Varint压缩算法,利用4比特作为单位来避免Varint对空间的浪费[31].比特对齐压缩算法能够达到较高的压缩率,而字节对齐压缩算法能够达到较好的压缩/解压速度[22].这两类压缩算法都是针对单个整数进行压缩,压缩过程类似于将每个整数替换为对应的码字.
硬编码和移位方法被广泛应用在各类倒排索引压缩算法中以达到算法压缩和解压实现性能的提升[7,32].其中,硬编码是指将压缩算法的每一种填充模式的各类描述信息直接写入程序,避免压缩和解压过程的循环和分支判断开销.通过硬编码和移位方法可以避免循环和分支判断的开销.表1和表2是采用硬编码/移位方法的对5个整数进行压缩和解压的例子.对于给定的待压缩整数序列,通过逐个对整数的最大位宽和可压缩整数个数进行检测来确定采用哪种填充模式(padding mode).
表1 compress_69算法伪码
Table 1 Pseudocode of compress_69

input:5 integers in int array d and status s=691 r[0]=(r[0]<< 14) + d[0]2 r[0]=(r[0]<<10) +(d[1]>>>4)3 r[1]=(r[1]<<4) +((d[1]<<28)>>>28)4 r[1]=(r[1]<<9) + d[2]5 r[1]=(r[1]<<9) + d[3]6 r[1]=(r[1]<<9) + d[4]7 r[0]= s <<24 | r[0]output:2 codewords in int array r
在表1所示的压缩过程中,给定的5个可单次压缩的整数(d[1]~d[5])和填充模式的状态信息s(s=69).算法依据填充模式的位宽等描述信息将5个整数移位至各自的预分配码槽(padding slot),然后将填充模式状态信息s存储在码字头部,这样在解压时通过移位操作就可以获得码字所采用的填充模式.
表2 decompress_69算法伪码
Table 2 Pseudocode of decompress_69

input:2 integers codewords in array r1 d[0]=(r[0]<<8)>>>182 d[1]=(r[0]<<22)>>>18 |(r[1]>>>27)3 d[2]=(r[1]<<5)>>>234 d[3]=(r[1]<<14)>>>235 d[4]=(r[1]<<23)>>>23output:out_s=5 integers in int array d
在表2所示的解压过程中,给定2个码字r[0]和r[1],每个整数在压缩状态下的位宽、可压缩整数个数等信息由硬编码描述,首先通过对码字移位获取码字中存储的填充模式的状态信息s(s=r[0]≫24),之后选择对应的硬编码解压算法,最后在选定的解压算法中利用预先设定好的码字描述信息直接移位就可以得到5个整数.
3 机器字对齐压缩算法
目前,倒排索引压缩算法中被广泛研究和采用的是字对齐(word-aligned)压缩算法,其可以在给定的32位或64位机器字长内一次处理多个倒排信息整数.该压缩算法分为按照单个机器字对齐进行压缩(非固定整数个数进行压缩)和按照固定整数个数进行压缩两类.按照单个机器字对齐压缩的主要思想是将尽量多的整数压缩在一个32位或64位机器字内,如Simple系列压缩算法[33-37].按照固定整数个数进行压缩的主要思想是选取32m(m为正整数)个整数进行等位宽压缩,同时保证码字末尾是字对齐的,如FOR系列压缩算法[32,38-40].两类字对齐压缩算法的解压过程均可采用硬编码方式来降低CPU分支判断等操作的次数.下面我们综述几种典型的字对齐压缩算法.
Simple系列:该系列压缩算法最初由Anh和Moffat提出,包括Simple-9压缩算法[33]及其改进压缩算法如Carryover-12、Slide等[34-37],其基本思想是将尽可能多的整数压缩在一个单一的32位机器字中.如表3所示,Simple-9压缩算法使用4比特作为状态位来描述其余28个数据位,形成9种可能的数据位填充模式.每种填充模式为每个被压缩的整数分配固定的比特宽度.解压阶段通过状态位确定填充模式来提取数据位存储的所有整数.压缩和解压过程采用硬编码方式来降低循环的次数.Simple系列压缩算法中每次可压缩的整数个数因采用的填充模式不同而不同.因此,Simple系列压缩方法实际上是依据填充模式对倒排链表进行“贪心”划分(left-greedy partition)并分别压缩.为了将更多的整数压缩到一个机器字中并降低固定比特宽度带来的位宽浪费,研究人员提出了众多具有更为丰富的数据填充模式的改进算法,包括Carryover-12、Slide、Simple-16、Simple-8b等[33-37].尤其是Simple-8b作为对Simple-9在64位机器字上的改进,采用4比特的状态位来描述60位数据位的不同填充模式[35].Simple-8b因为采用64位机器字对压缩序列进行处理,增加了单次可编码的整数个数.故Simple-8b相比Simple-9能够明显减少CPU分支判断的次数,所以其压缩和解压速度都好于Simple-9算法.
表3 Simple-9中采用的9种填充模式
Table 3 9 padding modes of simple-9
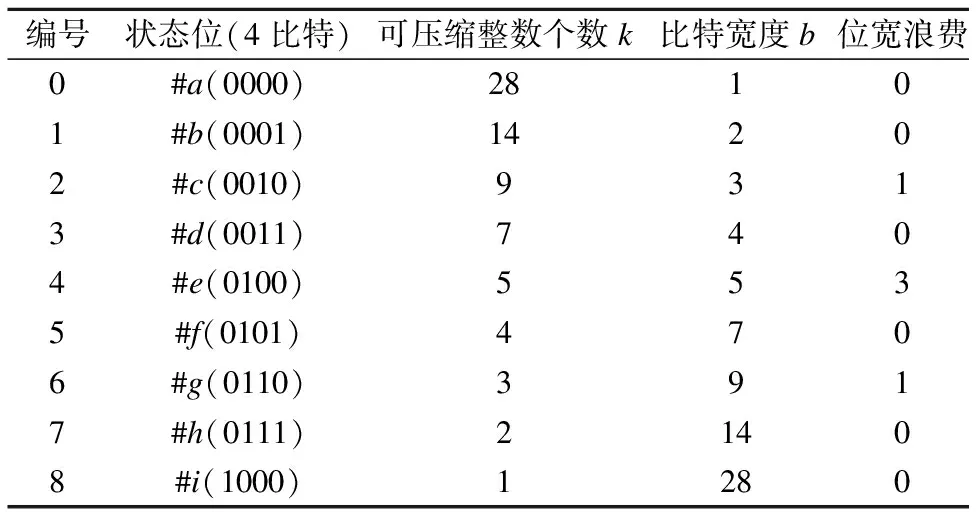
编号状态位(4比特)可压缩整数个数k比特宽度b位宽浪费0#a(0000)28101#b(0001)14202#c(0010)9313#d(0011)7404#e(0100)5535#f(0101)4706#g(0110)3917#h(0111)21408#i(1000)1280
FOR(FrameOfReference)系列:该系列压缩算法又称为Binary Packing、PackedBinary或者Null Suppression[7,41],其主要思想是把待压缩整数序列划分为定长的数据段(一般为一个磁盘分页,如可能包括216=65536个整数),然后用段内最大位宽来标示段内数字[38];PFOR是为了克服在某些分段中出现的异常值会迫使整个分段采用过大位宽的问题,把整个分段分成较小的正常值和较大的异常值两部分,异常值的个数通常取数据段长度的10%.其中,PFOR正常值仍采用定长压缩,异常值直接附在分段的尾部,使用32位机器字来表示[39];Zhang等人改进了原来的PFOR(Lemire等人[7]称该算法为PFOR2008),使得每次压缩的数据段长度为128,并且采用8、16或者32比特来压缩异常值[34].NewPFD和OptPFD也将数据段长度定为128,并把异常值拆成两部分,仅把超出正常值的部分移至尾部并采用Simple-16进行压缩;不同的是NewPFD选择10%的异常值,而OptPFD通过权衡正常值和异常值选择策略来实现最优压缩效果[19];FastPFOR和SimplePFOR则是把多个分段的数据区分别单独压缩,异常值组合形成一个分页(Page)进行压缩,而通过在解压时一并读取该分页加快解压速度;不同的是SimplePFOR采用Simple-8b压缩异常值,而FastPFOR生成32中不同长度的位宽数组来分别存放不同大小的异常值[7].总的来说,FOR系列压缩算法在每次可压缩的整数个数是一定的,因此属于等长压缩算法.
OCS(OptimizedChunkSplitting)系列:FOR系列压缩算法具有较高的解压性能,正是因为其可以单次处理较长(如:128或256个)的整数序列.但是增加单次可压缩整数的个数可能会造成该次压缩的数据段中存在较大的异常数(exception),从而制约了算法的压缩率.为了降低异常值给等长压缩算法带来的位宽浪费问题,研究人员提出基于倒排链表划分的优化压缩方法.该优化方法寻求最优的倒排链表数据段划分,每个数据段内部采用单独的等长压缩算法进行压缩,同时保证连续的多个数据段是字对齐的[8,42].Rossano Venturini等人提出的VSE针对整个倒排链表使用动态规划方法寻找最优数据段划分[32],但其全局优化的计算代价太高,使索引构建的时间大大加长.Renaud Delbru等人提出的AFOR采用固定长度的滑动窗口方式来划分数据段,可以说是以动态规划求解局部最优的办法来避免过高的计算代价[40].Gonzalo Navarro研究团队提出的DACs使用了和VSE相同的思想,但其数据段内采用了与Varint类似的字节压缩方式,同时对不同长度的码字构建分层结构来实现随机访问的效果[43];Rossano Venturini等人进一步提出的PEF和CEF压缩算法优化了Elias-Fano压缩算法[44],在划分时把整数序列视作有向无环图(DAG),并引入了近似计算的方法在线性时间内完成最优划分[45,46].eBay公司Andrew Trotman等人通过对整个内存倒排索引进行划分优化来提升Simple-9压缩算法的压缩率,但是该方法未能够考虑给定同步距离内多类倒排信息交错压缩存储带来的位宽浪费问题[47].
表4 机器字对齐压缩算法对比
Table 4 Comparison of word-aligned compressions

压缩算法单次可压缩整数个数k压缩率压缩速度解压速度Simple不固定(<128)中快中FOR固定(=64、128、256)低快快OCS不固定高慢快
结合上述分析和已有文献实验,表4给出了三类机器字对齐压缩算法的性能对比[48].FOR系列压缩算法虽然每次可压缩的整数个数是固定的,但是其压缩的码字所占用的机器字长是不确定的,所以将磁盘倒排索引分块载入内存IO缓存池(buffer pool)就会出现码字在解压时的缓冲池跨块读写的情况[49,50].在目前多数搜索引擎系统中海量倒排索引数据的存储和查询应用环境下,这一问题在磁盘压缩倒排索引的查询过程中会制约码字的解压性能.此时,Simple系列压缩算法相比FOR系列压缩算法的优势有两个方面:
1)其填充模式更加细化,可以降低较大异常数对于序列其他整数压缩位宽的浪费问题[7,32,34];
2)其压缩码字能够和所设内存IO缓存池的读写数据块对齐,可以避免读写磁盘压缩倒排索引数据时的跨数据块解压问题[22,39,51].
然而,Simple系列压缩算法仍然存在如下的问题:
1)在交错压缩给定长度的多类倒排信息时存在过多的分支判断和循环调用等开销;
2)在连续压缩多类交错倒排信息时存在严重的位宽浪费问题,其所采用的“贪心”划分方法无法达到最优的压缩效果.
3)在给定机器字长内可压缩整数个数的不确定性使得其自索引结构构建和优化过程中存在同步距离和地址偏移难以计算等诸多问题[48,52].
4 基于SIMD指令集的压缩算法
为了更加有效地提升处理器的性能,充分挖掘程序运行中可能存在的并行操作,现代处理器中引入了多种并行结构.SIMD指令能够对向量化的数据实现显著的性能加速[53].具体来说,单条指令不再只能处理单一数据,而能够在一组向量数据上同时执行相同操作.Intel推出的SSE和AVX扩展指令为可以向量化的数据密集型应用带来了明显的性能提升[54].例如,SSE向量指令使用了128位的寄存器,可以一次并行处理多个32位整数.开发人员仅仅需要调用提供的C/C++语法格式的内建函数(Intrinsic)就可以实现基于SIMD指令集的并行化开发[55].当前倒排索引压缩算法的一个研究方向就是通过采用SIMD向量指令集来提升现有各个类别的倒排索引压缩算法并行执行的速度.
国外最早对压缩算法进行SIMD并行化的工作是Willhalm等人[25]提出的在轻量级内存数据库中将等长位宽压缩(如FOR等)的码字利用SIMD数据置换指令进行快速解压算法,其过程包括加载压缩数据到128位的SIMD寄存器、采用Shuffle数据置换指令对SIMD寄存器中的数据进行重新存储、消除冗余的比特位并进行并行化的整数提取.Schlegel等人[56]利用SIMD指令同时处理k个整数的编码,其中设计了压缩数据的垂直布局来避免解压过程中大量的SIMD数据置换指令操作,大幅提升了Null Suppression和Elias Gamma两种编码的解压性能.Stepanov等人[57]利用标志位的存储格式和编码方式对字节对齐压缩算法进行了分类,并在这一分类框架下通过SIMD数据置换指令(Shuffle)设计了SIMD-GVB(包括3个变种SIMD-GB、SIMD-G8IU和SIMD-G8CU)并行压缩算法.Lemire等人[7]提出了两种采用码字垂直布局(Vertical Layout)和SIMD数据置换指令进行并行化的压缩算法,其中SIMD-BP128*能够达到比未并行化的最优压缩算法varint-G8IU和PFOR近2倍的解压速度,SIMD-FastPFOR相比Simple-8b能够在保证较高压缩率的情况下达到2倍的解压速度.随后,Lemire等人[58]又研究了能同时处理4个码字的基于SIMD的S4-BP128和S4-FastPFOR两种压缩算法在4种不同差分编码策略下的性能,以及在所提出的倒排链表求交(Intersection)算法中的性能表现.Trotman[59]针对SIMD-BP128*压缩率较低的问题,提出了一种基于SIMD的压缩算法QMX,其中设计了128比特的各种划分(Quantities),指示位的集中存储格式(eXtractors),以及通过游程编码来存储重复整数(Multipliers),最后通过采用SIMD数据置换指令来实现对向量化数据的快速处理.
国内对于基于SIMD的倒排索引压缩算法研究包括:南开大学张曌华等人[60]以及Ao等人[61]采用SSE指令和AVX指令实现了Simple-9、Simple-16、PFORDelta和BP的并行解压算法,其中对于部分算法考虑了垂直布局来进一步提升算法向量化处理性能,剩余的算法采用SIMD数据置换指令来实现并行化数据访问.北京大学闫宏飞等人[62]通过SIMD数据置换指令和垂直布局两种方式对PackedBinary和PFORDelta进行了并行化,得到了明显的解压性能改进.最新的研究是Zhao和Zhang等人[63,64]利用SIMD向量指令提出一系列分组压缩算法:Group-Simple、Group-Scheme、Group-AFOR和Group-PFDelta.这些压缩算法按照各个分组中最大数字的位宽对所有分组进行等位宽垂直存储,所以虽然其解压性能得到了提升,但是会导致部分压缩算法的压缩率相比较未并行化的原压缩算法有一定的损失.
5 压缩倒排索引的随机访问策略
倒排索引压缩算法最终是要应用于搜索引擎系统中的,而为了保证良好的用户体验,搜索引擎任凭索引规模的如何增长,总是优先考虑系统的查询性能指标[2,10].Stefan Büttcher等人指出倒排索引压缩算法的性能评估不能仅考虑对倒排链表所形成的数个整数序列的压缩,而必须考虑海量磁盘倒排索引和构建自索引查询结构等实际应用环境[65].Jimmy Lin等人研究发现,在给定同步距离内的分段倒排信息交错存储环境下,Simple系列压缩算法的填充模式位宽浪费问题要比内存索引压缩的理想情况要严重的多,极端情况下可能影响压缩算法在倒排索引查询中的作用[66].
前面我们认为压缩算法的解压速度在一定程度上即代表了搜索引擎的查询速度,但是在实际应用中并非完全如此.在搜索引擎的查询过程中,采用直接在磁盘寻道的方式对索引数据进行访问所需要的时间是难以忍受的.如果先将存储在磁盘上的倒排链表全部加载到内存中,再对加载入内存的整个倒排链表进行完全解压之后再进行查询操作的话,过长的数据加载时间将加剧用户的查询等待时间[67].针对压缩倒排索引的随机访问问题,研究人员从以下两个方面进行研究:为倒排链表构建自索引同步点的自索引采样技术(Self-Indexes)和可以对压缩倒排链表进行局部解压的随机访问技术(Random Decoding).
5.1 自索引采样技术
为了对压缩状态的倒排链表进行高效的随机访问,Moffat和Zobel提出对非压缩倒排链表进行等长采样并形成自索引结构,之后研究了最优的自索引结构层数[68].图2所示为一个自索引结构,这样就可以在查找过程中通过自索引结构定位到倒排链表的目标数据段,并通过二分查找在数据段内部定位目标文档号.Strohman和Croft研究了Impact-Ordered索引结构上的自索引结构问题[69].Boldi和Vigna提出了一种跳转塔的逻辑结构,该方法通过对每个数据段的自索引结构进行迭代形成塔状结构,在查找过程中可以从上到下逐步比较,准确定位所需的数据段[70].Dimopoulos等人为了研究倒排索引在内存中的查询问题,构建的自索引结构只是保存每个压缩数据段的首个文档号,且整个自索引结构并不进行压缩存储[71].Jonassen等人研究了PFOR等长数据段压缩的倒排索引的自索引结构构建问题[72].对压缩存储的倒排链表构建自索引结构能够减少磁盘读取的数据量.即使大部分索引可以被加载到内存中进行访问,自索引结构还是可以节省大量的解压时间.Bortnikov等人提出的自适应自索引结构能够在传统自索引和Treap自索引之间动态切换来实现基本的跳转查找操作,从而为Top-K查询优化提供更好的压缩索引随机访问性能[73].

图2 自索引结构示意图Fig.2 Example of Self-index Structure
5.2 局部随机访问技术
前述的压缩算法大多数利用文档号之间的差值d-gap信息进行压缩.尽管d-gap在提高压缩率和解压缩度上效果显著,但由于它对前后元素的依赖性,导致解压过程必须串行执行,无法实现对任意位置的元素访问.虽然构建倒排链表的自索引结构能在一定程度上实现倒排链表的随机访问,但是却无法对每个压缩数据段内部的整数进行随机访问.为了解决这一问题,研究人员提出了不利用d-gap信息而直接对原始整数序列进行处理的压缩算法.其中,DACs将所有文档号(docid)按照位宽不同分层存储,利用动态规划的方式来决定分层的个数以及每个分层的位宽,因为其位宽的单位为字节,所以其压缩率仍然较差[43];Interpolative Code利用序列两端整数的差值确定中间整数的编码长度,对单调递增的整数序列进行紧凑的递归编码,该算法是目前压缩效率最高的算法[28];刘小珠等人提出使用Interpolative Code压缩的方法来对等长数据段压缩的倒排链表实现随机访问[74,75].最新的Quasi-Succinct Indices[44]和Partitioned Elias-Fano Index[45]都源于Elias-Fano编码[76],它们将倒排链表所有整数按照指定的长度分成高位和低两层,低位部分以完整形式顺序写入压缩文件,高位则按照大小映射到不同的哈希分段中统计数目和位置,最后通过辅助的Rank/Select信息高效地实现压缩整数的随机访问.
6 搜索引擎系统中的压缩算法
随着倒排索引规模的不断增加,索引压缩算法性能上的任何提升都可以极大降低搜索引擎的硬件建设成本.虽然倒排索引压缩算法种类繁多、各具优势,但是在真实搜索引擎系统中的实现和应用还需要考虑很多因素,如:硬编码实现或者自索引结构等[7,10].不论是商业还是开源搜索引擎,都需要面对海量数据、海量查询、实时响应的应用需求.倒排索引压缩算法的选择需要权衡压缩率、压缩速度和解压速度三方面的因素.如何权衡选择合适的索引压缩算法在商业搜索引擎公司和学术上都属于研究的热点与难点[9].诸多性能优良的压缩算法能在某一性能指标上表现突出.搜索引擎选择压缩算法的重要原则是希望能够在各个性能指标之间取得一个平衡[77].当前各大商业搜索引擎所采用的索引压缩算法属于商业机密而不公开,但是我们可以从大量开源搜索引擎系统中得出倒排索引压缩算法的选择策略.
3The FastPFOR C++ library:fast integer compression.https://github.com/lemire/FastPFOR.2019.05.
当前流行的开源搜索引擎系统种类较多,使用Java语言编写的有Lucene、MG4J和Terrier,使用C/C++编写的有Xapian、Zettair、Indri等.Lucene提供了包括Gamma、Delta和Varint等多种算法的支持,默认采用了Gamma编码来压缩其索引数据[78].原来MG4J采用Golomb编码来压缩索引数据,同时也提供了其他压缩算法的实现接口[79],而MG4J在5.0版本开始使用了Quasi-Succinct Indices实现倒排索引的随机访问[44].Zettair和Galago中对于倒排链表所生成的d-gaps采用解压性能较好的Varint进行压缩,而采用Gamma或Delta对词频信息进行压缩[80,81].Terrier-v5.1实现了一个索引压缩的插件,其中包括当前各种常见的如PFOR、Simple等倒排索引压缩算法,其默认的索引压缩算法采用了Gamma编码,同时提供了进行压缩数据转换的功能[82].Lemire等人依据Moffat等人[35]论文中仿真数据生成的方法实现了一个索引压缩算法的Java语言仿真测试平台,其中包括了常用的各类压缩算法实现[7].另外Lemire等人还给出了一个C++语言实现的基于SIMD的压缩算法测试框架3.Catena等人对常见的倒排索引压缩算法在Terrier搜索引擎系统中的性能表现进行了比较全面的测试和分析[48].以上倒排索引压缩算法在开源系统中的应用可以作为进行倒排索引压缩算法研究和实验的参照.
7 总结与展望
互联网信息的不断丰富所带来的索引数据的持续增加,为新的倒排索引压缩技术的发展提供了持久的动力.综合国内外研究现状可以看出,大多数倒排索引压缩技术评估和优化工作主要关注了对整数序列的压缩,却忽视了现有倒排索引压缩算法在搜索引擎系统应用中存在的如:倒排链表磁盘分段存储、多类倒排信息交错压缩和压缩数据自索引结构等实际情况.针对倒排索引压缩算法在存储和查询应用中存在的实际问题展开理论方法研究与性能测试.这些问题的解决有助于推动机器字对齐压缩算法在倒排索引存储和查询中的广泛应用,有利于解决海量磁盘压缩索引数据的快速查询访问问题,对提升各类搜索引擎的系统性能和服务质量具有重要的实际意义.综合国内外研究现状,倒排索引压缩算法当前正在展开和今后的主要研究方向有以下几个方面:
1)倒排索引压缩算法在搜索引擎查询系统中的实际应用问题,如:研究支持倒排链表随机访问的倒排索引压缩算法[75].因为支持随机访问的压缩倒排链表可以减少不必要的内存数据加载,提升搜索引擎中压缩倒排索引的查询性能;同时也可以在倒排链表求交操作(如SvS算法)中根据AND查询策略来调整或者改进所使用的压缩算法[58].搜索引擎查询中对不同倒排链表或者倒排链表数据段访问频率是不同的,对于不同查询访问频率的索引数据采用不同的压缩方式就可以实现更加细粒度的性能调节,再权衡索引大小、压缩速度和解压速度等性能指标,从而达到更好的时空效率[77,83].
2)基于新的指令集架构优化倒排索引压缩算法的数据处理能够进一步提升压缩和解压性能.单纯采用高级语言提供的库函数实现的倒排索引压缩算法对数据的操作粒度较粗,不利于倒排索引压缩算法的性能优化.随着处理器技术的不断发展,新的SIMD指令集(SSE或者AVX指令集)或者计算单元(GPU芯片或者芯片加速器[84])等的更新将会带来新的指令级并行化策略.例如:基于Intel CPU的SSE、AVX向量指令的如:更大的寄存器宽度、数据Shuffle置换指令和垂直布局存储等优势[54],可以从汇编指令级别来设计整数序列的存储布局,并利用内存和寄存器载入策略、指令级的比特位操作等技术提升倒排索引整数序列的并行化压缩和解压处理性能.
3)基于传统数据压缩领域的新技术和新理论提升倒排索引压缩算法的性能.部分传统压缩领域中的新理论和方法可以应用于倒排索引的整数序列压缩.在这方面的工作包括:Zhang等人提出的基于上下文无关文法(Context-free Grammar)的倒排索引压缩方法[85];Moffat等人提出的基于不对称数字系统(ANS)的倒排索引压缩方法[86,87];Pibiri等人利用复数分割(Plurally Parsable)理论提出了基于词典的倒排索引压缩方法[88].这类研究需要掌握传统数据压缩的理论并跟踪其最新研究动态.考虑到倒排索引压缩中整数序列也是一类特殊的符号序列,采用传统压缩领域的新技术和新理论分析文档号、词频等整数序列的存储特性,就可能从新的角度明显提升倒排索引的压缩性能.
猜你喜欢
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
计算机与网络(2022年2期)2022-03-17
疯狂英语·新阅版(2020年11期)2020-12-21
东坡赤壁诗词(2020年3期)2020-07-04
扬子江诗刊(2018年1期)2018-11-13
中等数学(2018年12期)2018-02-16
扬子江(2018年1期)2018-01-26
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
小朋友·快乐手工(2009年5期)2009-06-11
