
改进的基于日志聚类的异常检测方法
2020-04-24 08:54冯士龙台宪青马治杰
计算机工程与设计 2020年4期
冯士龙,台宪青,马治杰
(1.中国科学院 物联网研究发展中心 数据与服务研发中心,江苏 无锡 214135;2.中国科学院大学 微电子学院,北京 101407;3.中国科学院 电子学研究所 苏州研究院地理空间信息系统研究室,江苏 苏州 215121)
0 引 言
现如今,随着分布式系统规模的不断扩大,其复杂性也越来越高,因此给运维人员维护系统正常运行带来了严峻的挑战[1]。系统运维人员通常利用系统产生的运行日志来定位异常,但由于分布式系统产生的日志量较大,并且不同的系统会采用不同的容错机制[2],人工检索的方法耗时耗力。近些年随着非结构化日志解析方法[3-5]和机器学习的发展,基于机器学习的日志异常检测方法成为了一个研究重点。
基于机器学习的日志异常检测方法包括基于监督学习和基于无监督学习两种。基于监督学习的方法[6-8]的优点是检测精确,但是需要使用提前进行标记的训练集进行模型的训练,不适合实际生产环境。在无监督学习的方法中,基于主成分分析(principal components analysis,PCA)[9]和Invariants Ming[10]是两种比较典型的方法。然而,由于前者对数据非常敏感,导致其检测的精度随数据集的不同变化差异比较大;而后者是一种能够保证异常检测准确度的方法,但是其检测过程十分耗时。因此,这两种方法在实际异常检测中效果并不理想。LogCluster[2]是一种基于日志聚类的异常检测方法。它既能快速的处理大量日志数据,也能保证异常检测的精度的检测。但是LogCluster方法使用会话窗口的方式对日志进行分组,使得该方法只能检测带标记符的日志,限制了方法的适用性。
针对LogCluster方法的局限性,本文提出了一种改进的基于LogCluster的异常检测方法,通过使用滑动窗口的方式对日志进行划分,扩展了原方法的适用范围,并且对改进的方法进行了相关的实验验证。
1 LogCluster介绍
本节首先介绍LogCluster方法的整体结构以及主要步骤,然后分析该方法的局限性。
1.1 方法概述
LogCluster方法主要分为两个阶段:构建阶段和生产阶段,总体结构如图1所示。构建阶段和生产阶段均包含4个步骤:日志解析、特征提取、日志聚类和代表性日志序列提取。构建阶段通过提取代表性的日志序列来构建知识库。在生产阶段将实际生产环境中采集的日志提取出代表性日志序列,然后检查它是否已经存储在知识库中,如果知识库中已经存在,那么将相应解决方案反馈给工程师,否则将对知识库进行更新。
接下来,根据图1中的LogCluster整体结构,我们分别介绍日志解析、特征提取、日志聚类、代表性日志序列提取和重复性检查5个步骤。

图1 LogCluster整体结构
1.1.1 日志解析
现代系统的运行日志一般是指由系统生成的非结构化日志文本,它包含静态消息和动态参数两种字段,其中静态消息字段也叫日志事件,表示每条日志的事件类型。日志解析的主要目的是从原始日志中提取日志事件。
LogCluster中日志解析采用基于聚类的日志关键字提取技术[11](log key extraction,LKE)。图2展示了LKE方法的解析效果。图中上方为原始日志信息,下方分别为日志事件文本和标记符与日志事件对应的结构化日志文本。
1.1.2 特征提取
特征提取主要是将解析后的日志特征进行分析提取,并进行矢量化,以便进行日志聚类。该步骤主要包含日志序列划分和日志矢量化两部分。日志序列划分将解析后的日志划分为多个日志序列。日志矢量化主要分为两步,首先将日志序列转化为日志事件计数向量,然后对向量进行加权。日志特征提取流程如图3所示。
日志序列划分:为了提取特征,首先需要将日志数据分成不同的组。该方法中使用会话窗口将日志链接为不同的日志序列。会话窗口基于标识符,标识符用于标记某些日志数据中的执行轨迹。例如,带有block_id的HDFS日志会记录某些块的读写等操作。依据带有同一标记符的日志代表同一会话的相关性,将日志根据标记符进行分组,其中每一个会话窗口都有唯一的标记符。如图3中所展示的,图中的日志都拥有相同的block_id,所以将含有blk_904791815409399662和含有blk_904791815415648154的日志行都链接到一起,形成多组日志序列。

图2 日志解析效果
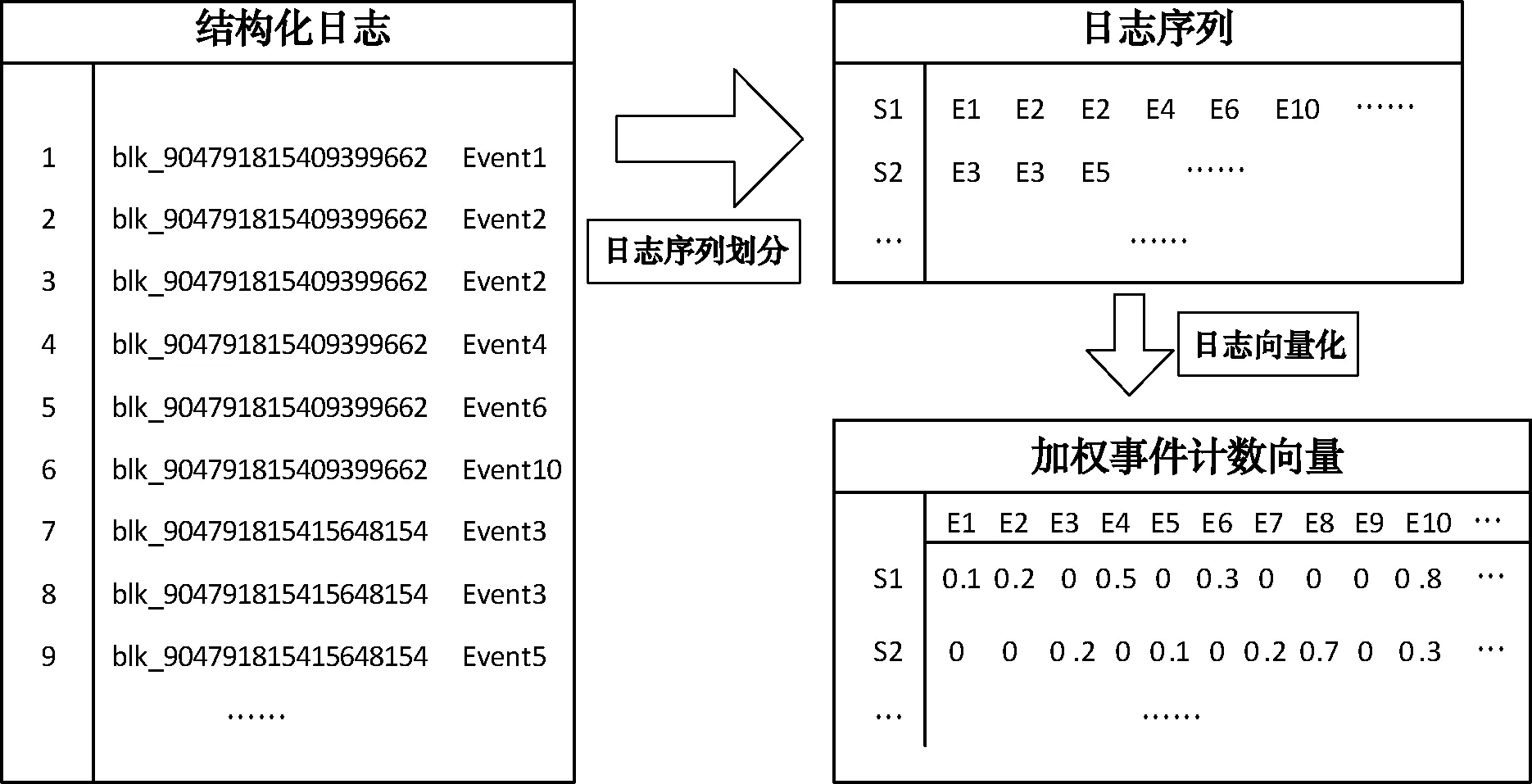
图3 日志特征提取
日志矢量化:将日志事件序列转化为事件计数向量,即日志事件序列中的每个日志事件出现的次数。然后使用基于IDF[12](inverse document frequency)和基于对比的方法对事件计数向量进行加权,形成加权事件计数向量,如图3所示。
(1)基于IDF的事件权重:如果一个日志事件频繁的出现在多个日志序列中,那么它的判别能力就低于只出现在少数日志序列中的事件。
(2)基于对比的事件权重:在实验环境和生产环境都出现了的事件对异常识别的判别能力不如只出现在生产环境中的事件,仅在生产环境出现的事件更有可能反映异常,因此应该具有更高的权值。
1.1.3 日志聚类
日志聚类主要是将特征提取步骤得到的加权事件计数向量进行聚类。LogCluster计算日志序列之间的相似度,然后采用层次聚类对相似的日志序列进行聚类,形成正常和异常两种集群。
1.1.4 代表性日志序列提取
代表性日志序列提取将从正常和异常两种集群中提取代表性日志序列,构建知识库。对于每个集群,通过选择集群的质心来作为代表性日志序列。计算每个日志序列距离集群内其它日志序列的平均距离,选择平均距离最小的作为每个集群的代表性日志序列。
1.1.5 重复性检查
重复性检查主要对生产阶段产生的日志提取的代表性日志序列与知识库中的日志序列进行对比。采集生产阶段产生的日志经过上述4个步骤后提取代表性日志序列,计算与知识库中存储的日志序列之间的相似度,如果知识库中已经存在,那么将该日志序列对应的异常解决方案进行反馈。将知识库中不存在的日志序列进行人工判断,然后对知识库进行更新,从而减少人工检查的日志序列的数量。
1.2 局限性
LogCluster方法虽然能有效的进行异常检测,并减少人工检查的工作,但是在特征提取步骤采用了会话窗口的方式进行日志序列的划分,这种方法使得LogCluster方法只能处理带有标记符的日志。而对于日志本身不带有标识符或者无法后期为日志增加标记符的日志类型,该方法无法进行特征提取。特征提取步骤的局限性影响了LogCluster方法的适用性。
2 SW-LogCluster介绍
针对LogCluster异常检测方法的局限性,本文提出了一种改进的基于LogCluster的日志异常检测方法,即SW(Sliding Window)-LogCluster。SW-LogCluster通过采用滑动窗口代替LogCluster的会话窗口,可以有效扩展LogCluster方法的适用性。图4展示了LogCluster与SW-LogCluster方法的对比,SW-LogCluster采用与LogCluster相同的整体结构,关键的区别在特征提取部分。特征提取分为日志序列划分和日志矢量化两个步骤,LogCluster使用会话窗口的方式进行日志序列划分,而SW-LogCluster使用滑动窗口的方式进行日志序列的划分。
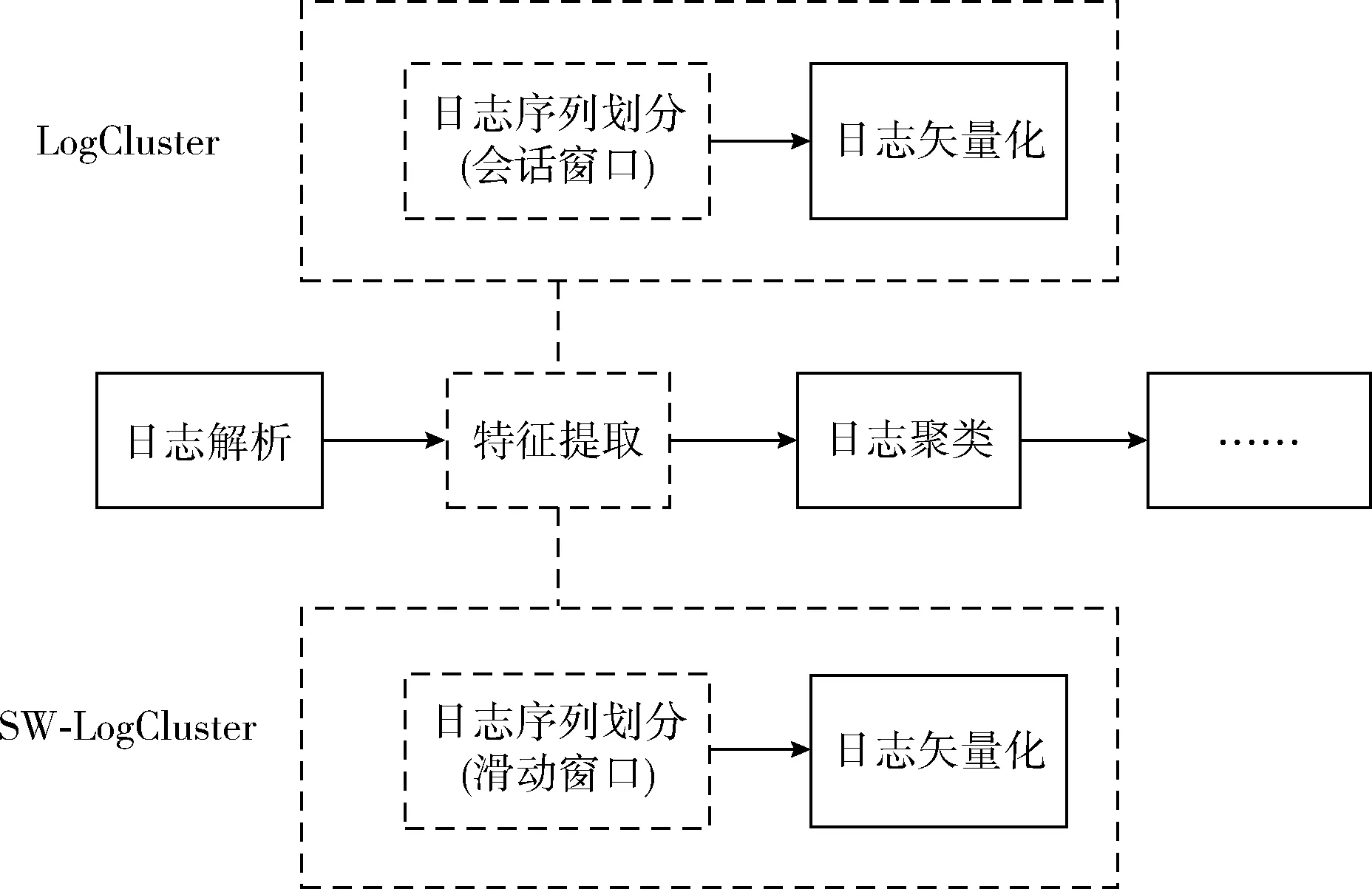
图4 SW-LogCluster与LogCluster方法对比
滑动窗口方法是一种基于时间戳的序列划分方法,时间戳记录每条日志产生的时间。窗口由两个属性组成:窗口大小ΔT和步长Δt,ΔT表示每个窗口包含的时间间隔,Δt表示窗口每次滑动的时间间隔,如图5所示。窗口以步长大小的时间段向后滑动。一般来说,我们设置步长小于窗口大小,这样每次窗口滑动会形成不同窗口之间的重叠,可以增加划分出的日志序列,减少窗口覆盖不均匀产生的误差。

图5 滑动窗口
SW-LogCluster采用合适的窗口大小以及步长对日志进行划分,将同一个滑动窗口时间段内产生的日志划分为一组日志序列,然后生成事件计数向量。图6为一个使用滑动窗口划分日志序列并生成事件计数矩阵的实例,图中左边为原始日志经过解析后生成的结构化日志,每个日志行代表日志生成的时间和该行对应的日志事件。假设滑动窗口的窗口大小为6 h,步长为1 h,第一个窗口产生的日志序列S1为第1行日志的时间到之后6 h内的日志行代表的日志事件,即日志序列图中的第一行(由于事件太多,没有完全展示)。第二个窗口根据步长向后滑动1 h,产生的第二个日志序列S2为第4行日志的时间到之后6 h内的日志行代表的日志事件,即日志序列图中的第二行。然后进行日志向量化,将日志序列转换为事件计数矩阵。
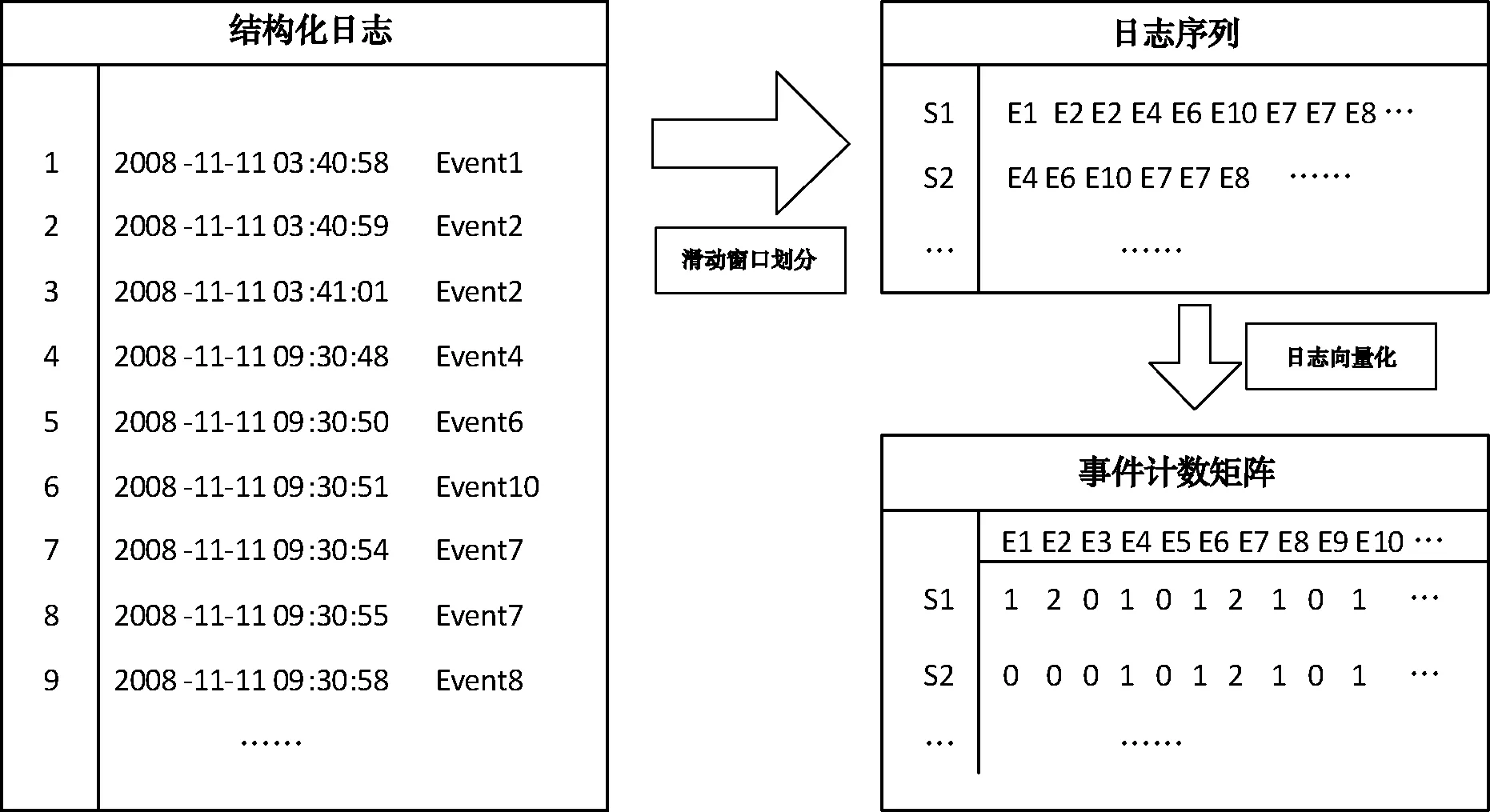
图6 滑动窗口划分日志序列实例
通过我们的方法,能够有效的将原始日志解析后的结构化日志进行划分,产生多组日志序列,进而应用到日志向量化的步骤中。由于滑动窗口方法基于时间戳的特性,SW-LogCluster方法不仅可以应用于LogCluster方法针对的带标记符的日志,还能有效的对不带标记符的日志进行异常检测,在扩展LogCluster方法适用性的基础上保证异常检测的效果。
3 评估指标
本文主要采用Precision(精准率)、Recall(召回率)和F_measure(综合评价标准)来作为评估指标。
Precision表示检测出来的正确异常占检测出来的所有异常的比例,计算公式为
(1)
其中,TP为检测出来的正确异常的数量;FP为将非异常检测为异常的数量。Precision的值越高,说明异常检测方法检测出的正确异常的准确率越高。
Recall表示检测出来的正确异常占实验数据中所有异常的比例,计算公式为
(2)
其中,FN为将异常检测为非异常的数量。Recall的值越高,说明异常检测方法将异常漏掉的比例越低。
F_measure表示Precision和Recall两项指标的相对重要程度,是Precision和Recall的加权调和平均[13],是最重要的一个评估指标。F_measure可通过如下公式计算
(3)
其中,β是参数。当0<β<1时,精准率有更大的影响,当β>1时,召回率有更大的影响。在本文的异常检测方法中,既要保证非异常不能检测成异常(精准率),又要保证异常不能检测为非异常(召回率)。假设Precision和Recall的权重的相同的,即β=1, 式(3)可表示为
(4)
4 仿真验证
本文实验使用Python语言进行LogCluster方法以及SW-LogCluster方法的实现,实验日志数据采用了HDFS和BGL(BlueGene/L)日志集[14]。每个实验分别进行20次,并对实验结果评估指标取平均值。
接下来,我们首先使用SW-LogCluster和LogCluster方法对带标记符的日志(HDFS)进行对比实验,然后再验证SW-LogCluster日志检测方法在不带标记符的日志(BGL)上的检测效果。通过两组实验验证SW-LogCluster方法是否有效扩展了原方法的适用性。最后验证了滑动窗口属性对SW-LogCluster方法的影响,并讨论窗口大小和步长对SW-LogCluster方法产生的影响。
4.1 LogCluster与SW-LogCluster的对比
实验采用50万条的HDFS日志的样本数据,分别使用LogCluster方法和SW-LogCluster方法进行异常检测的平均Precision、Recall和F_measure结果如图7所示。
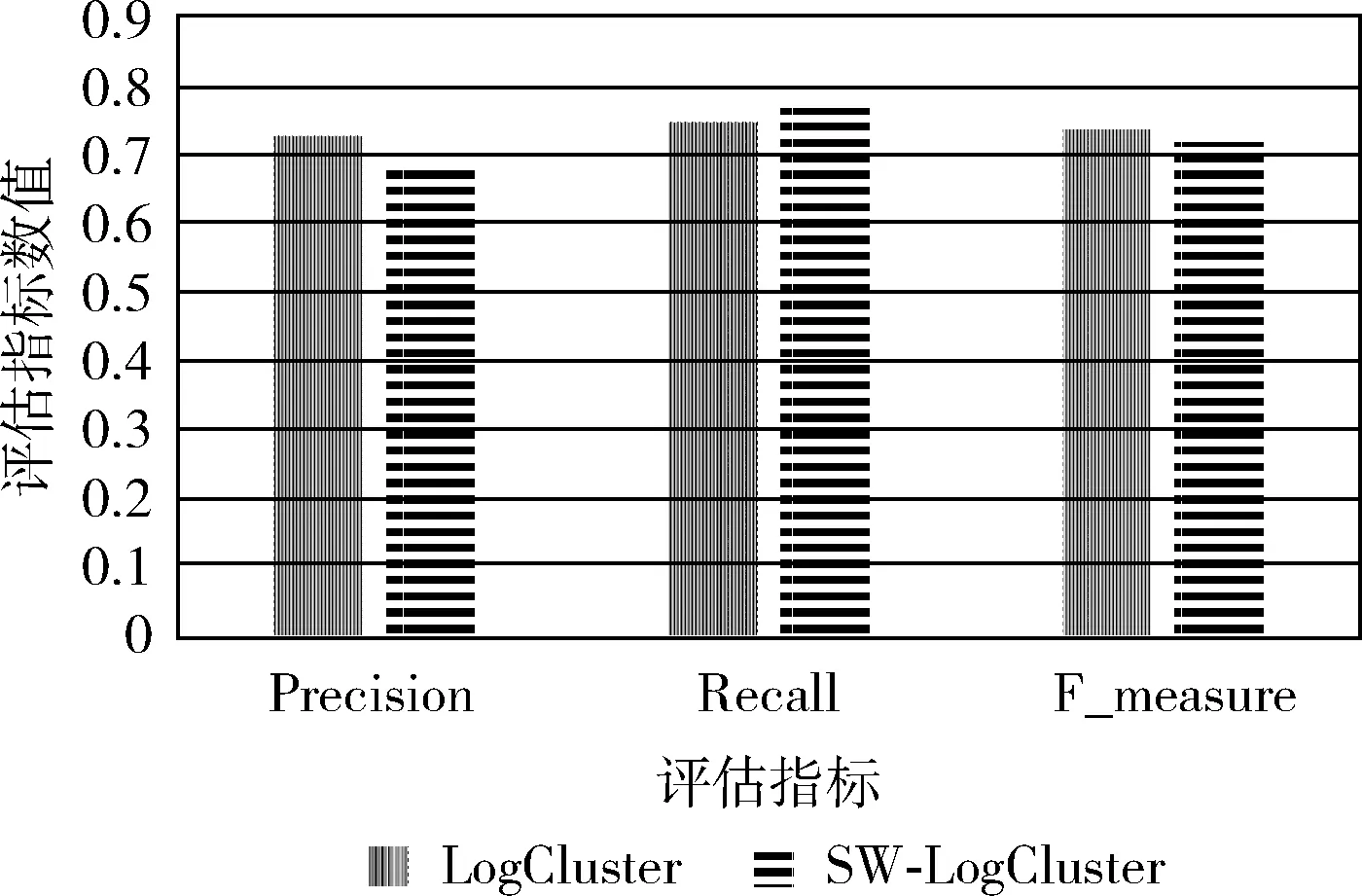
图7 LogCluster和SW-LogCluster在精确率、召回率和F_measure方面的实验结果对比
图7展示了各项指标(Precision,Recall,F_measure)在使用LogCluster和SW-LogCluster方法时的平均值。由图7我们可以看出,SW-LogCluster方法在Precision和 F_measure 两项指标上比LogCluster方法略小,但是在 Recall 指标上稍大。SW-LogCluster方法的3项指标与LogCluster方法相差不多。实验结果表明SW-LogCluster方法在带有标记的日志(HDFS)上基本能达到LogCluster方法的异常检测效果。
4.2 SW-LogCluster方法验证
本实验通过使用SW-LogCluster方法对不同规模BGL日志集进行异常检测,以此来验证SW-LogCluster方法在Precision、Recall和F_measure这3项指标上的实验效果。
图8展示了各项指标(Precision,Recall,F_measure)在不同日志样本集规模(50万条,100万条,200万条和400万条)时的平均值。由图8我们可以看出,随着日志样本集的不断变大,3项指标均有略微的提高,并且维持在一个较为稳定的区间。3项指标的值与LogCluster方法在HDFS日志上的实验结果基本相同。实验结果表明SW-LogCluster在不带标记符的日志(BGL)上依然能达到LogCluster的异常检测效果。
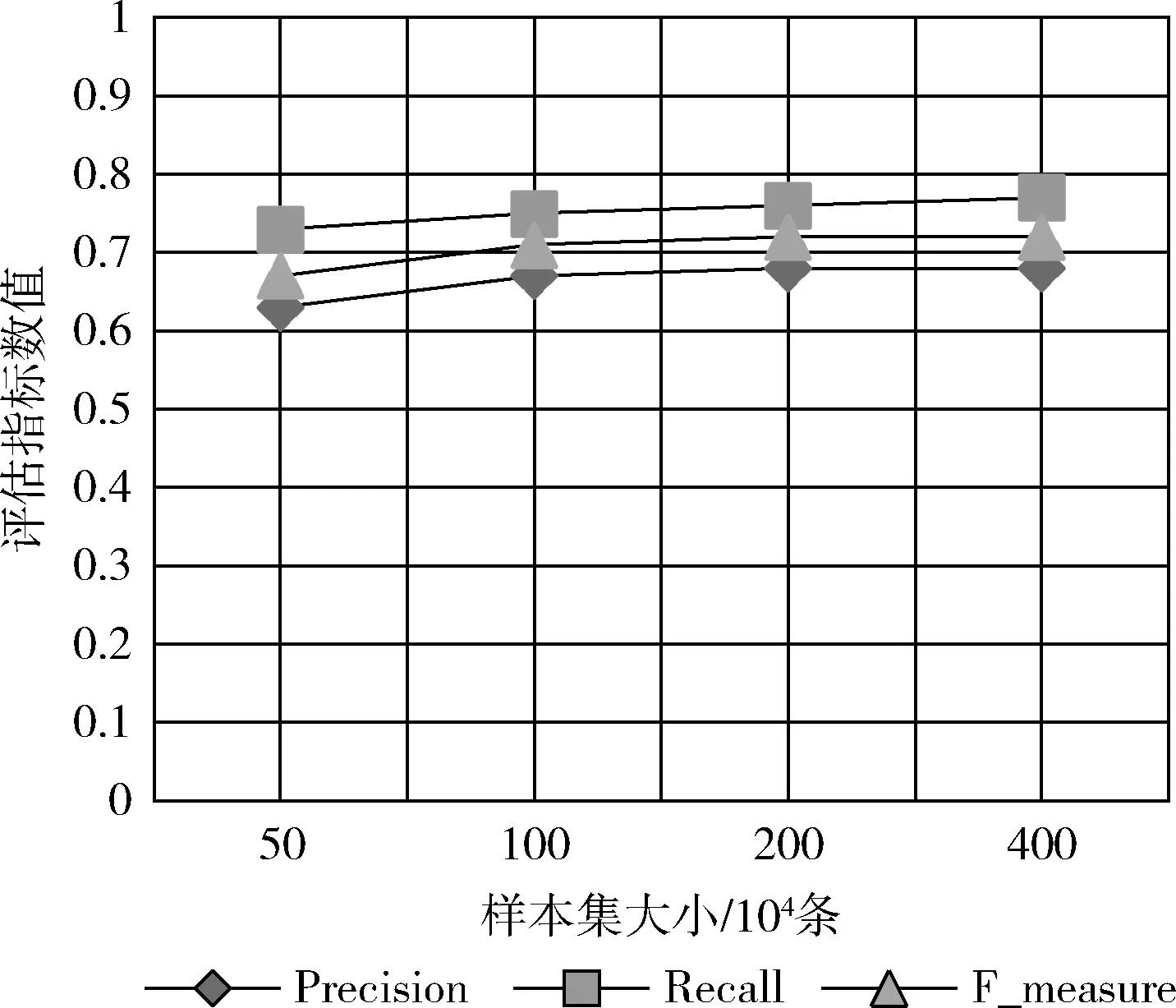
图8 SW-LogCluster测试结果
结合第4.1节进行的实验,改进后的SW-LogCluster方法不仅能达到原方法异常检测的效果,而且在检测不带标记符的日志类型时也能达到理想的检测结果,说明改进后的方法有效扩展了原方法的适用性。
4.3 滑动窗口对SW-LogCluster方法的影响
本实验将研究滑动窗口中窗口大小和步长对SW-LogCluster异常检测方法精度的影响。实验选取50万条的BGL日志数据作为样本数据。实验结果解释如下。
图9展示了不同窗口大小对F_measure值的影响。在该实验中,步长设为1 h。由这幅图我们可以看出,随着窗口大小的不断增大,异常检测的综合指标F_measure的值越来越大。这是因为在一定范围内,窗口越大就可以覆盖越多的信息,能减少一些小窗口覆盖信息不完全的情况,提升日志序列划分效果,进而发现更准确的异常检测模式。实验结果表明,当步长固定时,窗口越大,异常检测的效果越好。
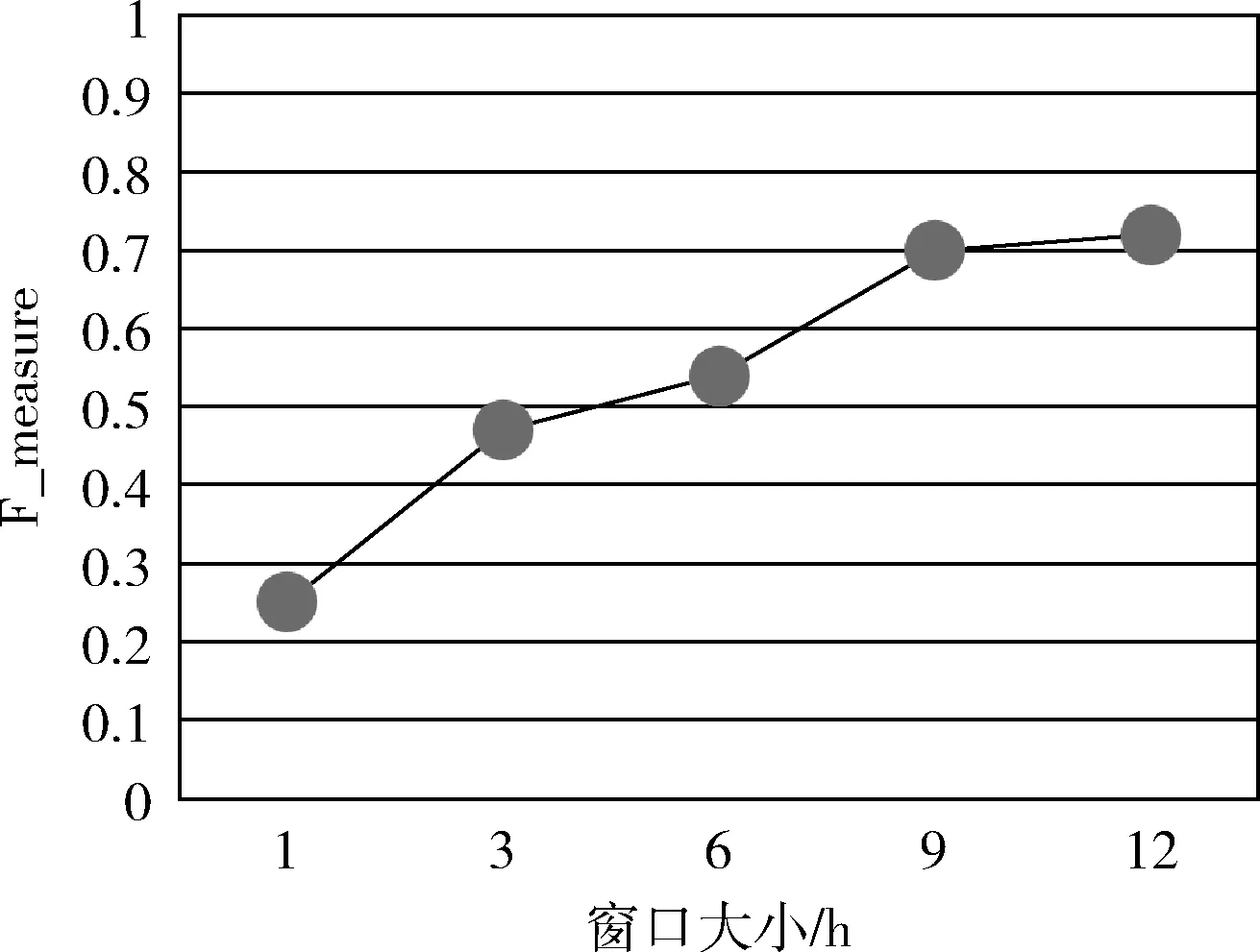
图9 窗口大小对检测精度的影响
图10展示了不同步长对F_measure值的影响。在该实验中,窗口大小保持在6 h。由这幅图我们可以看出,随着步长的变化,F_measure的值基本保持不变。这是因为步长的大小对窗口覆盖信息完不完整没有必然的联系。实验结果表明,当窗口大小固定时,步长大小对异常检测的结果没有影响。

图10 步长对检测精度的影响
5 结束语
本文针对LogCluster方法处理日志类型单一的问题,提出了一种改进的基于日志的异常检测方法SW-LogCluster,SW-LogCluster方法使用滑动窗口的方法代替会话窗口对日志进行划分,能够将更多类型的日志划分为日志序列,方法的适用性得到扩展。本文对SW-LogCluster方法进行了设计实现和实验验证,结果表明,SW-LogCluster方法的3项评估指标(Precision,Recall,F_measure)与LogCluster方法相差不大,说明SW-LogCluster方法在保证异常检测效果的基础上,有效扩展了原方法的适用性。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
中国惯性技术学报(2020年2期)2020-07-24
成都信息工程大学学报(2019年2期)2019-08-28
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
自动化学报(2017年11期)2017-04-04
