
基于Apache AsterixDB的相似性查询
2020-04-24 14:50杜伍陈琳
电脑知识与技术 2020年5期
关键词:优化
杜伍 陈琳


摘要:在许多应用程序中,例如数据清理,记录链接,Web搜索和文档分析,相似性查询处理变得越来越重要。该方法使用现有的运行时运算符来实现这种复杂的联接算法,而无须重新发明轮子。这样可以使系统自动受益于这些操作员的未来改进。该方法包括一种技术,该技术通过使用很大程度上以系统用户级查询语言表示的模板,在查询优化期间将相似性联接计划转换为基于操作员的有效物理计划;这项技术大大简化了这种转换规则的规范。我们使用并行大数据管理系统Apache AsterixDB来说明和验证我们的技术。我们使用并行计算集群上的几个大型真实数据集进行了一项实验研究,以评估相似性查询支持。
关键词:大数据管理系统;Apache AsterixDB;相似性查询;并行数据库;优化
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)05-0003-02
开放科学(资源服务)标{o码cOSID):
1 概述
相似性查询会计算满足不完全匹配但近似的匹配条件的答案。支持相似性查询的问题在许多应用中变得越来越重要,包括搜索,记錄链,数据清理和社交媒体分析。例如,在与客户进行实时电话交谈期间,呼叫中心代表可能希望通过键入序列号立即识别客户购买的产品。即使在搜索号码中出现错别字,系统也应找到产品。社交媒体分析师可能希望找到共享共同爱好或社交朋友的用户账户。医学研究人员可能希望搜索标题与特定文章相似的论文。在这些示例的每一个中,查询都包括具有特定于域的相似度函数的匹配条件,例如关键词的编辑距离或兴趣组的Jaccard。
相似性查询有两种基本类型。一种是search或selection,它查找与给定记录相似的记录。另一个是Jom,它计算彼此相似的记录对。关于这两种类型的查询已有许多研究。已经开发了许多数据结构,分区方案和算法,以在大型数据集上有效地支持相似性查询。当计算超出一台计算机的限制时,也将有并行解决方案支持跨集群中多个节点的查询。
由于在许多应用程序中数据都驻留在数据库中,所以一个自然的问题是如何在这样的数据库系统上采用这些现有技术来支持相似性查询。一种方法是在数据库。也就是说,我们开发了一个独立的应用程序层,该层从数据库中检索数据,并在此应用程序中部署这些索引结构和算法以支持相似性查询。这种方法的一个优点是它在实现中具有很大的灵活性。同时,它也有几个主要缺点。首先,数据本质上具有两个副本,一个副本在数据库中,一个在应用程序中。其次,需要付出额外的努力来将应用程序中的数据与数据库中的数据同步,以便将最新结果返回给用户查询。第三,没有充分利用数据库的内部功能,包括存储,索引和查询执行。另一种方法是将这些技术完全集成到内部数据库,从而可以克服所有上述限制。特别是,不必将数据复制到单独的层中,并且可以利用数据库系统的内置功能直接对数据进行查询。
2 AsterixDB
2.1 体系结构
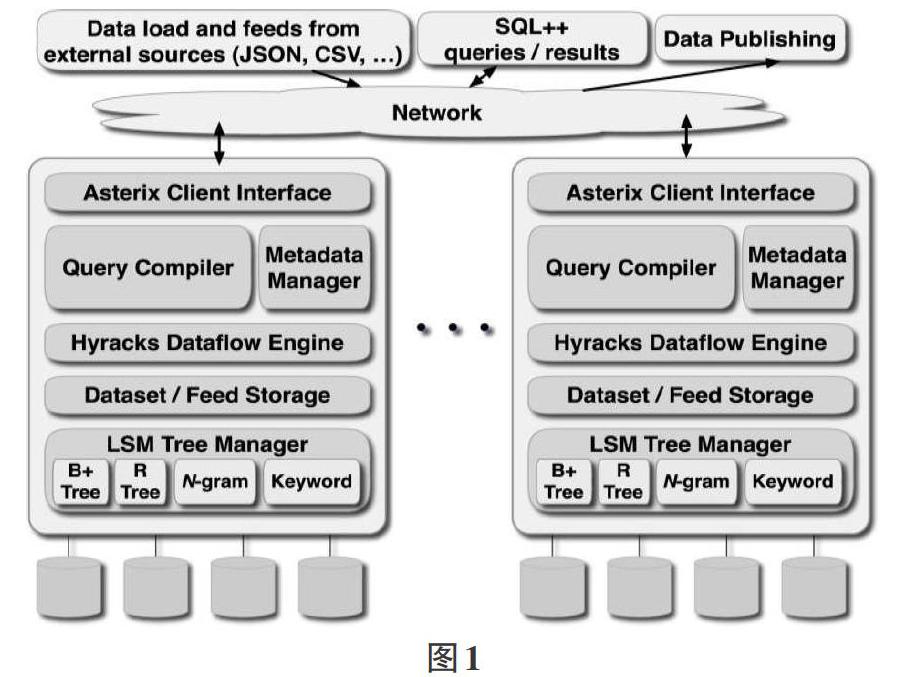
AsterixDB由几个软件层组成,如图1所示。最顶层提供了完整,灵活的数据模型(ADM)和查询语言(SQL++和AQL),用于描述,查询和分析数据。AQL是AsterixDB的初始查询语言。SQL++现在是用户首选的语言。
下一层,基于Algebricks的查询编译器,用于并行查询处理。该代数层从上层接收翻译后的逻辑SQL++/AQL查询计划,并执行基于规则的优化。一个规则可以分配给多个规则集。根据规则集的配置,可以重复应用每个规则,直到规则集中的任何规则都无法进一步转换计划为止。对于逻辑计划转换,当前有15个规则集和171个规则(包括将一个规则分配给不同的规则集)。逻辑优化之后,Algebricks为计划中的每个逻辑运算符选择物理运算符。例如,对于逻辑联接运算符,可以基于联接谓词选择混合哈希联接或嵌套循环联接。之后,物理优化阶段开始。在逻辑和物理优化期间,有许多顺序应用的规则集。物理优化阶段有3条规则集和30条规则。物理优化过程完成后,Algebricks层将生成Hyracks作业,以在ra层。
Hyracks层包括由AsterixDB存储和管理的数据集的存储工具,这些数据集是基于分区的基于LSM的B+树,具有可选的基于LSM的二级索引。AsterixDB将计算任务转换为运算符和连接器的有向无环图(DAG),并将其发送给Hyracks以便执行。在Hyracks中,运算符使用输入数据的分区并产生输出数据的分区。然后,将运算符产生的输出分区由连接器重新分区,以为下一个运算符产生输入分区。一个操作员具有一个或多个活动(子步骤或阶段),并且在某些操作员上的两个活动之间可能存在控制依赖性。使用此信息,创建一个或多个阶段。一个阶段包括可以共同安排的一组活动(一个活动集群)。因此,将逐级执行作业。由于在此级别上将数据表示为字节元组,因此Hyracks是不可知的数据模型层。
2.2 数据模型
AsterixDB定义了自己的针对半结构化数据的数据模型(ADM)。ADM是JSON的超集,支持包,嵌套类型和各种原始类型。图2显示了一些示例ADM DDL。AmazonReviewType被定义为开放类型,这意味着其实例必须具有所有指定的字段,但可能还包含因实例而异的额外字段。
AsterixDB数据集中的每个记录都由唯一的主键标识,并且记录将基于其主键在集群的节点之间进行哈希分区。数据集中的每个记录必须符合其关联的数据类型。图5还包括用于创建Amazon评论数据集的SQL语句。每个分区都通过LSMB+树中的主键(也称为主索引)在本地建立索引,并驻留在其节点的本地存储中。AsterixDB还支持二级索引,包括B+树,R树和反向索引选项。索引是本地的,即,它们以与主索引相同的方式进行分区。像主索引一样,每个辅助索引也采用基于LSM的结构。在AsterixDB存储管理文件中可以找到AsterixDB中基于LSM的索引结构的更多详细信息。
3 执行相关查询
3.1 倒排索引
AsterixDB中的反向索引是基于LSM的二级索引,它由可变的内存中组件和多个不可变的磁盘上组件组成。之所以选择这种设计来支持高频插入,因为基于LSM的索引通过在将更新写入磁盘之前合并内存中的更新来摊销写入成本。内存中的组件由两棵B+树组成,一棵用于内存中反向索引,另一棵用于存储已删除记录的主键。磁盘上的组件是不可变的,因此AsterixDB使用此B+表示磁盘上组件的已删除记录。-tree,而不是从反向索引本身中删除它们。
3.2 执行相似性选择
AsterixDB用于選择查询的执行策略。我们使用图3的示例查询来解释执行流程。此SQL++查询计算名为Reddit的数据集的字段标题与edit-distance-threshold为2的恒定搜索键良好竞争之间的编辑距离。然后再分别给予索引的搜索执行和基于非索引的搜索执行分别将结果返回给协调器。
3.3 执行相似联接
相似联接运算符具有两个分支作为其输入。我们称第一个为外部分支,第二个为内部分支。例如,在图3,SQL++别名一种[R指外部分支,并且[R指内部分支。该查询基于阈值为0.5的Jaccard连接条件从每个数据集中获取三个字段。再分别基于索引的联接执行和非索引的联接执行,再次将结果发送给协调器进行合并。
3.4 优化相似性查询
AsterixDB使用基于规则的优化方法。根据给定的查询构造一个初始逻辑计划,然后对该计划尝试每个优化规则。如果有规则适用,则计划将被转换。涉及数据集的逻辑计划始终以PRIMARY-INDEX-SCAN运算符开头,如果存在一个或多个条件,则以SELECT运算符开头。对于相似性查询,首先要构建非索引相似性查询计划,并且可以在优化过程中引入基于索引的转换或三阶段相似性联接。 4 结论
在本文中,我们描述了一种为并行大数据管理系统中的相似性查询提供集成支持的方法。我们使用Apache AsterixDB来说明和验证我们的方法。我们描述了系统中相似性查询的整个生命周期,包括查询语言,索引,执行计划和计划重写以优化查询执行。我们的相似性搜索解决方案利用了并行数据管理系统的现有基础架构,包括其运算符,查询引擎和基于规则的优化器。我们希望其他寻求将搜索功能集成到通用并行数据管理环境中的人会发现我们的工作结果很有用。
参考文献:
[1]克里斯汀.P.数据匹配一记录链接,实体解析和重复检测的概念和技术,以数据为中心的系统和应用,谷歌学术,2012.
[2]拉姆E.待办事项H.H.数据清理中存在的问题和当前的方法[J]lEEE数据工程师公牛,2000,23(4):3-13.
[3] Borgatti S.P,Mehra A.,Brass D.J.社会科学中的网络分析科学,2009:892-895.
[4]蒋翠清,疏得友,段锐.基于用户时空相似性的位置推荐算法[J].计算机工程,2018(7).
[5]米琳.基于q-gram的字符串相似性查询研究.现代计算机:专业版,2014(6).
【通联编辑:梁书】
猜你喜欢
房地产导刊(2022年5期)2022-06-01
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
中学生数理化(高中版.高考数学)(2021年12期)2021-03-08
