
多优先级通用路由仲裁器的设计实现
2020-05-12 09:09周刚华邹德财卢晓春
小型微型计算机系统 2020年3期
周刚华,邹德财,卢晓春
1(中国科学院国家授时中心,西安 710600)
2(中国科学院精密导航定位与定时技术重点实验室,西安 710600)
3(中国科学院大学,北京 100049)
4(中国科学院大学 天文与空间科学学院,北京 101048)
E-mail:18829269702@163.com
1 引 言
伴随着芯片设计越来越复杂和以多核为核心的片上网络(Network on Chip,NOC)系统优点的不断凸显[1],研究者们对在片上网络上实现路由功能也越来越关注,而仲裁器作为路由功能实现中的重要模块,为路由器优化分配路由资源,其时延、功耗等特性对路由器的服务质量有着重要的影响.文献[2,3]结合动态优先级算法,根据从设备被主设备访问不同的任务情况,建立了动态分组转发的模型,更好地处理数据传输问题.文献[4-6]设计了不同类型的轮循仲裁器,文献[4]提出能提供更低延迟的乒乓仲裁器,文献[5]提出了可用于n2n循环仲裁的快速并行逻辑电路,文献[6]则设计实现了可用于高性能NOC里的并行伪循环仲裁器.随着芯片的集成度越来越高,片上网络内可容纳的主机和模块也越来越多,为快速高效地仲裁请求信号来分配总线等共享资源,提高数据通信的效率,并行仲裁处理路由请求成为如今提高路由服务质量的重要手段之一,如何设计一个性能优良的并行仲裁器是提高路由网络效率必须解决的重要问题.
本文通过对目前常用的仲裁方式进行学习研究,设计实现了两种融合固定仲裁和轮循仲裁的多优先级通用仲裁器.在采用多优先级仲裁后,仲裁器可并行处理多路由多模块的仲裁请求,提高了数据处理和通信的速度,并且当需要仲裁的路由请求总数相同时:无论是在芯片资源占用还是最大工作频率和最大输出时延上,多优先级仲裁器的指标都要优于单优先级仲裁器的指标.
2 仲裁机制
目前常用的仲裁机制为:固定优先级(Fixed-Priority)仲裁器、轮循(Round-Robin)优先级仲裁器、基于权重的优先级仲裁器 、彩票仲裁器(Lottery arbiter)等[7,8],本文主要对FP仲裁和RR仲裁方式进行了学习研究.
Round-Robin和Fixed-Priority仲裁器的仲裁机理可用图1和图2简要表示.
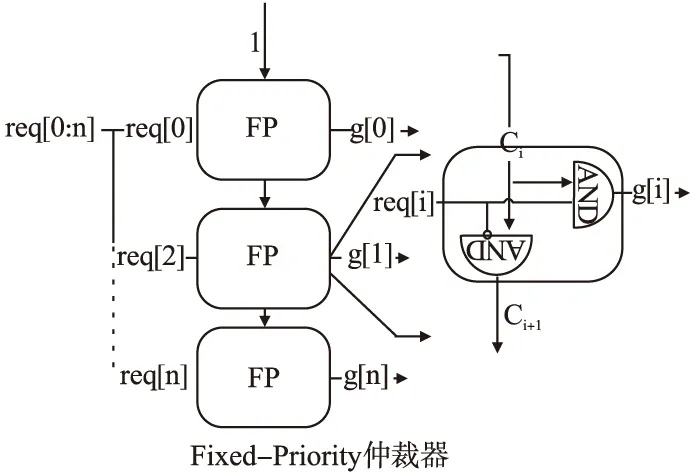
图1 FP仲裁器仲裁机理
将路由请求信号输入仲裁基本块中进行仲裁,仲裁优先级从上到下依次降低.高优先级仲裁块的输出信号Ci作为控制信号控制其下一级仲裁模块的仲裁输出结果,同时与~req[i]相与后得到Ci+1作为下下一级的控制信号,如此,高优先级的路由请求信号对低优先级具有绝对的压制,所以固定优先级仲裁容易出现“饿死”和“撑死”现象[8].
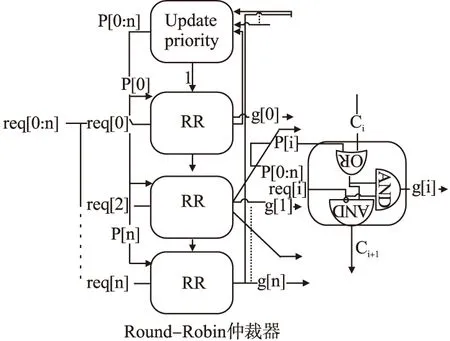
图2 RR仲裁器仲裁机理
与固定优先级仲裁器不同的是,轮循优先级仲裁器把前面的仲裁结果作为反馈信号与上级仲裁模块的输出信号Ci相或后成为控制信号控制此级的仲裁输出,此次的仲裁结果g[i]输入到update priority模块,update priority模块根据此次的仲裁结果调整下次各请求信号的仲裁优先级,循环往复,达到相对公平的仲裁请求结果.
为应对实际路由请求中需要不同仲裁方式的情况,在两种通用仲裁器中融合固定优先级仲和轮循优先级两种仲裁方式.当需要对某路由请求进行最优先仲裁或者路由请求信号数较少且无冲突时,为减少响应时间,提高数据处理速度时,采用FP仲裁;进行冲突路由请求仲裁时则采用RR仲裁,保证信息传递的有效性,避免饿死现象.
3 多优先级仲裁器
3.1 多优先级matrix仲裁器
3.1.1 多优先级matrix仲裁器原理
常见matrix仲裁器的原理是将n位输入请求req生成n*n的优先级矩阵A[7],Ai,j的值即req[i]与req[j]的优先级关系,矩阵A的转置对应位值相同,对角线值为1.为应对片上路由网络里出现多个路由中的多个模块同时请求仲裁的情况,在此提出一种多优先级matrix仲裁器的设计.
图3中的sel模块是具有one-hot控制信号的多路复用器,reduce模块具有判断请求信号那几段存在请求信号的功能,gate模块根据输入的选择信号选择输出对应部分的仲裁结果,lod模块功能是检测第一个输入高位的位置,图3中间的部分是储存优先级矩阵的值.对输入的路由请求进行多优先级仲裁的过程可分为两部分,一部分对所有输入请求分别进行优先级仲裁,另一部分对每个分组路由的请求信号进行检测缩减得到选择信号sel,sel信号再对上一部分得到的优先级仲裁结果选择输出.

图3 多优先级matrix仲裁器RTL原理图
3.1.2 matrix仲裁器功能实现仿真图
由图4可知,无论是单优先级还是多优先级,update信号为0时执行的是FP仲裁器功能,为1时对应RR仲裁器功能.单优先级matrix仲裁器执行的是普通的轮询仲裁功能,在仲裁一次数据请求(请求信号设定的是同一路由内的多个模块请求仲裁)后,对下一级的仲裁请求进行优先级更新,所以仲裁输出值不断循环变化,而多优先级matrix仲裁器不仅可以对同一路由的不同模块的仲裁请求有着优先级仲裁(请求信号设定的是多个路由内的多个模块请求仲裁),同时也可以在不同路由网络之间进行优先级仲裁,在仿真结果里可以看见有多个路由网络的仲裁结果在并行输出且同一路由请求的仲裁结果不断变化.多优先级仲裁器相比单优先级仲裁器的优势在于:多优先级仲裁器可以并行处理多组需要仲裁的请求信号,单优先级仲裁器同时只能对一组请求信号进行仲裁,而且在处理相同数量的路由请求信号时,多优先级仲裁器的关键路径时延更低,占用的硬件资源更少.
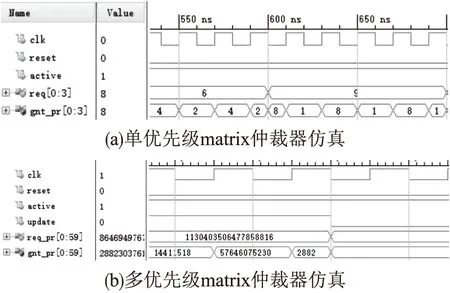
图4 单优先级和多优先级matrix仲裁器仿真结果
3.2 多优先级prefix仲裁器
3.2.1 多优先级prefix仲裁器原理
无论是matrix仲裁器还是其他被广泛使用的轮循优先级仲裁器,相对于已经成型的片上路由网络,其资源仲裁结果对于网络中的每个路由单元都是相对较为公平的,而在实际的路由应用中,设置某些特定的路由单元在某时拥有更高的优先级能显著提高路由服务质量.prefix仲裁器相比较于matrix仲裁器不再是生成一个n*n的优先级矩阵,而是基于树状图的理念,将输入请求生成m个n输入的向量组,根据不同的输入前缀来仲裁决定此时的各路由请求优先级,并可据此开始优先级轮询.
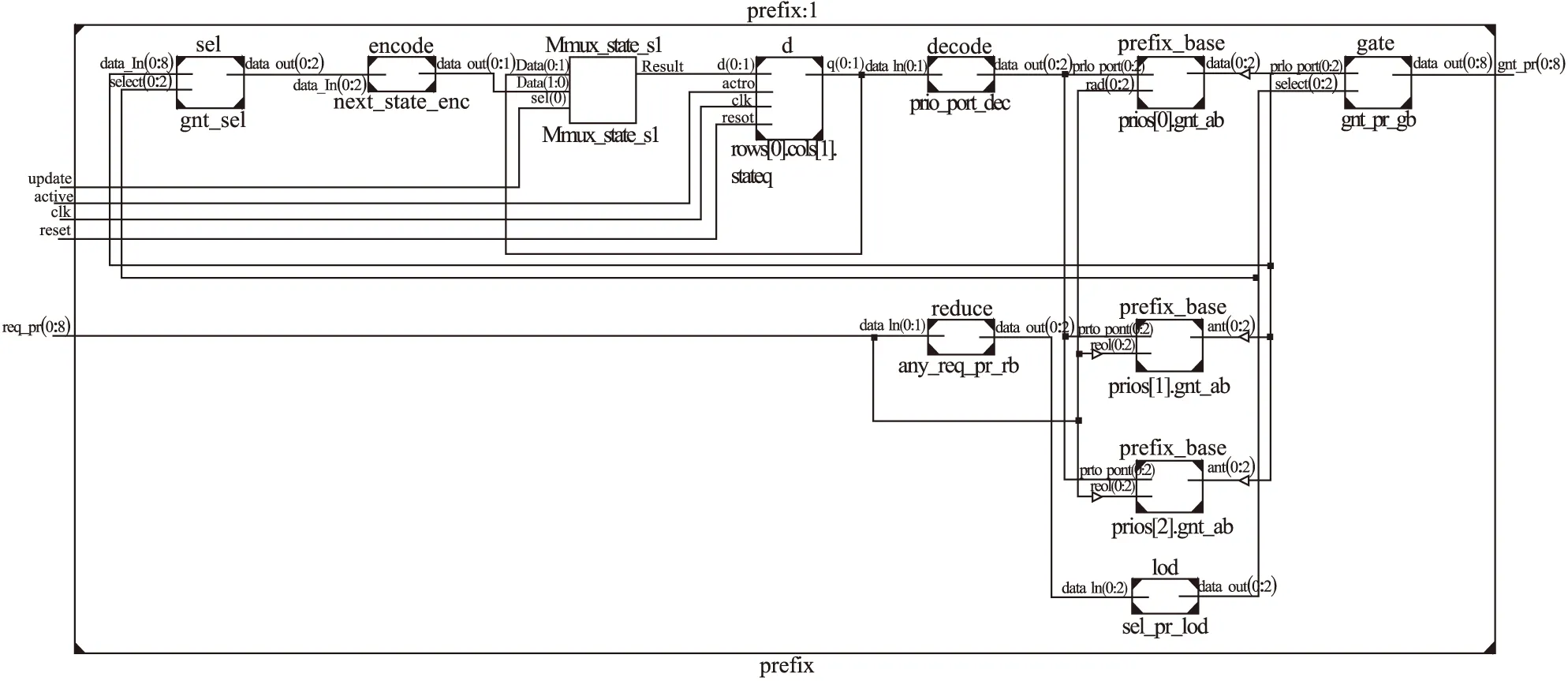
图5 多优先级prefix仲裁器RTL原理图
图5中encode模块将one-hot码转换为二进制码.decode模块则是将二进制码解码成one-hot码.prefix_base模块是prefix仲裁器的核心—是基于前缀树的循环仲裁器基本块,前缀树网络和根据输入的前缀得到仲裁结果在这里实现.sel、reduce、gate和lod模块与多优先级matrix仲裁器中的模块功能相同.
3.2.2 prefix仲裁器功能实现仿真图
相同的,update的值决定着实际运行中仲裁方式的类型,但prefix仲裁器与matrix仲裁器的不同之处在于prefix仲裁器可以通过外部输入对prefix_base模块中的prio_port端口进行掩码输入,实时的改变片上路由网络里的路由单元进行仲裁的优先级,不再类似于其他轮循仲裁器对路由系统内的仲裁优先级一直循环变换保证相对公平的仲裁结果,所以prefix仲裁器在某些特定的应用情况下可以实时地设置各个路由请求的优先级,在短时间内迅速处理某些指定的路由请求,提高路由网络的路由服务质量.除了解决通信冲突外,效率也是评价仲裁器的一个重要指标,从prefix仲裁器的仿真结果图可得出与matrix仲裁器相同的结论,多优先级仲裁器由于可将数据信号并行处理,能在一定程度上提高数据通信的效率.
4 仲裁器仿真分析
下面若干表皆为在Xilinx公司的vivado开发软件环境下使用Verilog语言对仲裁器模块进行综合实现(同样的路由请求数时)的系统指标情况,对应的FPGA开发板为Xilinx公司virtex-7系列里的VC707开发板.

图6 单优先级和多优先级prefix仲裁器仿真结果
4.1 仲裁器资源占用情况和片内功率
本文利用vivado对四种仲裁器在不同路由请求总数下分别进行综合映射,得到了在VC707开发板上实现仲裁器功能所占用的硬件资源.从图7可以看出,当需要处理的路由请求较少时,四种仲裁器实现所占用的资源基本接近,但随着同时需要处理的路由请求总数增加,单优先级的prefix和matrix仲裁器模块实现占用的资源比多优先级仲裁器实现占用的FPGA硬件资源更多,这一点在matrix仲裁器上更为凸显.在处理45和60个路由请求时,单优先级matrix仲裁器占用了3020和5465个的硬件资源,单优先级prefix仲裁器需要533和849的资源总数,而多优先级matrix仲裁器和多优先级prefix仲裁器实现相同的功能只需要300左右的硬件资源.由此可知,在仲裁较多的路由请求时,采用多优先级仲裁器实现相同的功能可以节省有限的硬件资源.
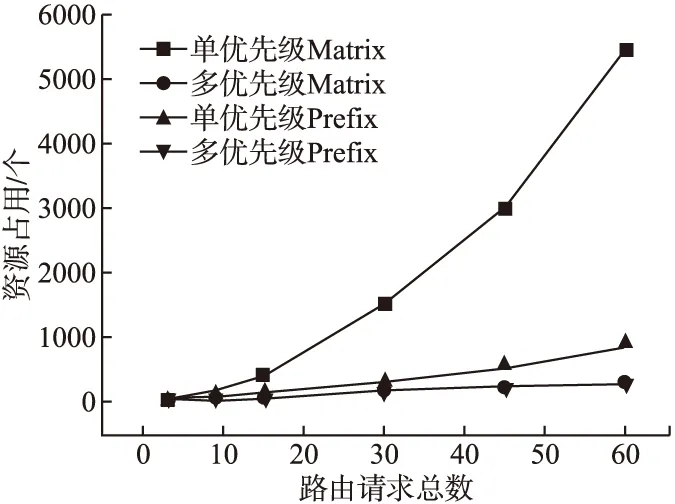
图7 仲裁器资源(LUT+FF+IO+BUFG)占用
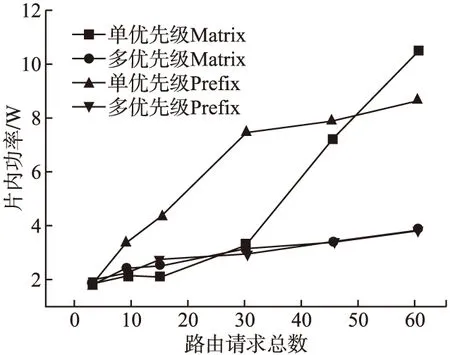
图8 仲裁器片内功率
图8为在不同请求总数下对四种仲裁器进行功耗分析得到的开发板片内功率(包括静态和动态).同理可知,在路由请求较低时,单优先级仲裁器和多优先级仲裁器占用的资源接近,所以此时板卡上运行单优先级仲裁器的片内功率与板卡上运行多优先级的matrix仲裁器的片内功率接近,但随着路由请求的增加,无论是matrix仲裁器还是prefix仲裁器,多优先级仲裁器的片内功率都会远低于单优先级仲裁器的片内功率.
4.2 仲裁器最大工作频率和最大输出时延
在vivado中对四种仲裁器在不同路由请求总数下进行综合映射,得到各种情况下的Timing Report,由时序报告分析得到四种仲裁器最大工作频率的对比图.由图9可知:当路由请求数较少时,多优先级仲裁器的最大工作频率稍微高于单优先级仲裁器的最大工作频率,但随着路由请求总数的增加,无论是多优先级matrix仲裁器还是多优先级prefix仲裁器的最大工作频率都高于相对应的单优先级仲裁器的最大工作频率.当路由请求数为45个时,多优先级matrix仲裁器最大工作频率比单优先级matrix仲裁器高13%,多优先级prefix仲裁器最大工作频率比单优先级prefix仲裁器高134%;当路由请求数为60个时,多优先级matrix仲裁器最大工作频率比单优先级matrix仲裁器高19%,多优先级prefix仲裁器最大工作频率比单优先级prefix仲裁器高145%.
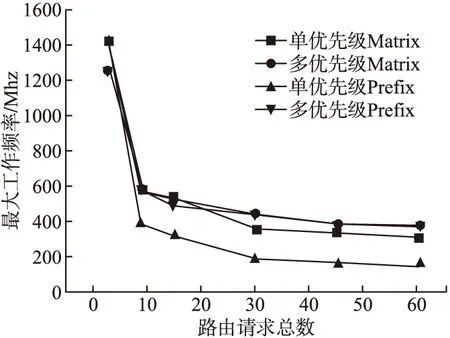
图9 仲裁器最大工作频率

图10 仲裁器最大输出时延
图10为四种不同类型的仲裁器在不同路由请求数下的最大输出时延对比.从图10中可知:随着路由请求数的增加,无论是matrix还是prefix仲裁器,多优先级的仲裁器的最大输出时延与单优先级仲裁器的最大输出时延之间的差值越来越大.计算6种路由请求数下四种仲裁器的平均最大输出时延可得:多优先级matrix仲裁器比单优先级matrix仲裁器最大输出时延降低了7.1%,多优先级prefix仲裁器比单优先级prefix仲裁器平均最大输出时延降低了23.8%.
本文实现的多优先级仲裁器与文献[9]中设计的混合并行仲裁器和文献[10]设计的有序仲裁器在面对相同请求路数时,最大工作频率方面多优先级仲裁器和混合并行仲裁器的数据较为接近,多优先级仲裁器的最大输出时延指标则明显优于混合并行仲裁器和有序仲裁器.在相同的路由请求下,路由网络采用多优先级仲裁器进行仲裁在一定程度上可以得到更高的路由服务质量.
5 结束语
本文对片上路由网络仲裁机制进行研究,提出2种多优先级的集成了FP和RR仲裁方式的通用仲裁器,仿真分析得出使用多优先级仲裁器对比于使用单优先级仲裁器能更少的占用板卡资源、更高的工作频率、更低的输出时延、更低的片内功率,在面对多路由的多模块的仲裁请求时能提供更好的路由服务质量.多优先级matrix仲裁器拥有更强的仲裁公平性和更高的最大工作频率,但matrix仲裁器本身的局限性在于随着路由请求的增加,其仲裁机制里生成的优先级矩阵占用的资源越大,所以,matrix仲裁器更适用于较少的路由请求条件下;多优先级prefix仲裁器占用的硬件资源少且能实时地更改仲裁请求优先级,可在特定时间内优先对特定的路由请求进行仲裁处理,为更好的路由服务质量提供保障.对两种通用仲裁器结构进行改良优化,并设计实现一种兼容两者优点的通用仲裁器是接下来的研究目标.
猜你喜欢
电脑知识与技术(2021年22期)2021-09-14
计算机与网络(2020年9期)2020-07-29
传播力研究(2019年24期)2019-10-21
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
科技与创新(2018年1期)2018-12-23
宇航计测技术(2018年3期)2018-09-08
科技传播(2016年20期)2017-03-01
中文信息(2016年11期)2017-02-11
现代电子技术(2015年22期)2015-12-02
