
结合概率路由的机会网络自私节点检测算法
2020-05-14 07:09陈民华李秀峰
小型微型计算机系统 2020年5期
任 智,陈民华,康 健,李秀峰
1(重庆邮电大学 通信与信息工程学院,重庆 400065)
2(重庆邮电大学 移动通信技术重庆市重点实验室,重庆 400065)
E-mail:2849819270@qq.com
1 引 言
机会网络[1,2]是一种源节点与目的节点之间没有完整的传输路径,利用节点移动带来的相遇机会来实现源节点与目的节点通信的移动自组织网络,其数据传输模式为“存储-携带-转发”.概率路由机制[3]是机会网络中一种消息只沿着与目的地址相遇概率更高的方向传输的路由算法,该算法通过计算节点之间的接触概率来为消息选择交付概率更大的中继节点.由于机会网络中节点自身的资源(节点能量、缓存空间等)有限,节点会为了节省自身资源而表现出拒绝向其它节点提供消息转发服务的自私行为,这种自私行为会导致整个网络的性能下降甚至无法正常工作[4,5].因此,如何设计高效的自私节点检测机制来促进消息在非自私节点间顺利传输是机会网络中一项重要的研究课题.
2 相关工作
目前,国内外有很多关于自私节点检测算法的文献.
Watchdog[6]算法的思想是:当前携带消息的节点将消息转发给下一跳节点之后,通过对下一跳节点的行为进行监听.若下一跳节点在规定的时间内对该数据消息进行了转发,则表明当前节点的下一跳节点是非自私节点,其提供了转发服务;若在规定的时间内下一跳节点没对该数据消息进行转发,则表明当前节点的下一跳节点是自私节点.根据监听结果来判断下一跳节点是否是自私节点存在一定的缺点,原因是下一跳节点有可能因为脱离监听范围或链路不稳定而造成当前节点对下一跳节点的误判.
CORE[7]机制和CONFIDANT[8]机制是在Watchdog机制的基础上给网络中的节点设置一个量化的信誉值,同时每个节点维持一张信誉表来记录网络中其它节点的信誉值.网络中每一个节点通过监听其邻居节点是否转发数据消息来动态地调整其邻居节点的信誉值:若邻居节点为自身转发了数据消息,则在自身的信誉表上增加该邻居节点的信誉值,否则降低该邻居节点的信誉值.然后根据邻居节点的信誉值是否超过预先设置的阈值来判断邻居节点的自私性.若该邻居节点为自私节点,则对该节点进行惩罚.虽然通过设置信誉值的方式可以一定程度上避免Watchdog机制带来的误判,但是由于节点信誉机制计算与维护过程比较复杂且不可靠,容易导致信誉值不一致的问题.
IRONMAN检测算法[9]是一种自主检测算法,其核心思想是:通过节点相遇交互各自的历史记录信息来判断中继节点的自私性,若检测出中继节点为自私节点则降低该节点的信誉值.由于机会网络中的节点是随机移动的,因此节点之间的相遇就具有随机性,不能满足节点检测的实时性,同时中继节点有可能并未先于源节点遇到目的节点而产生误判.
RADON[10]机制的核心思想是:每个节点存储一张信誉表用来表征网络中其它节点的信誉值,同时结合Watchdog的节点检测机制来对节点的转发行为进行检测,并且根据检测结果来更新节点的信誉值.当节点转发数据消息时,会选择信誉值最大的邻居节点作为中继节点,这种方式使消息朝着信誉值递增的方向传输.但是由于该机制采用了Watchdog的监听机制,因此存在节点信誉值计算不准确的问题,同时对于低信誉值的节点不能对其进行激励使其进行合作的问题.
基于2-ACK的自私节点检测算法[11]是利用上一跳节点是否接收到当前节点的下一跳节点的ACK信息来判断当前节点的自私性,但是基于2-ACK检测算法中下一跳节点与上一跳节点之间可能存在相遇概率低的问题,导致检测效率较低,易引起误判.EACK机制[12]用于消息在转发过程中,记录参与转发消息的节点ID及对应跳数,参与消息转发的当前节点的后L-2个节点都要向当前节点回复ACK消息,以此作为当前节点的下一跳节点转发了消息的凭证,该算法改进了基于2-ACK检测算法中下一跳节点与上一跳节点相遇概率低的不足,但是由于引入了过多的ACK回复消息,使得网络开销增大,同时容易引起网络拥塞.
RSND检测算法[13]采用错帧解析等机制对相遇节点的自私性进行判断,其可以很好地解决Watchdog机制中由于节点脱离通信范围或链路不稳定原因造成节点产生误判的问题,但是其对难以确定类型的节点采用概率定性的方式来判定节点是否自私的方法容易引起误判.
为解决上述中自私节点检测算法开销较大和节点自私行为判断不够准确的问题,本文提出了一种结合概率路由的机会网络自私节点检测算法.
3 假设与问题描述
3.1 假设
假设1.网络节点分为自私节点和非自私节点,自私节点不参与网络中消息的转发,即表现出不请求其它节点的数据消息或者请求了数据消息之后也是直接删除,同时它只发送本节点产生的消息.
假设2.网络中节点配置相同,即每个节点的通信范围以及数据处理能力相同.
假设3.网络中节点采用概率路由的转发方式,即只有相遇节点与目的节点的相遇概率更高时才会对消息进行转发.
3.2 问题描述
问题1.现有的2-ACK机制的自私性判定是在数据信息交互结束之后进行的,若此时判定相遇节点为自私节点,而在此之前将数据消息转发给相遇节点,会导致数据消息被丢弃,从而导致了无效的网络开销.
问题2.现有的RSND机制对难以判断的节点类型采用概率定性的方式来判断节点的自私性,这种概率定性的方式容易造成对节点的自私性判断不准确.
问题3.当前节点在检测出其它节点为自私节点时,在散播自私节点信息时,需要单独的控制信息或增加消息的长度,从而导致网络的开销增大.
4 SNPR算法
针对上述提出的问题,本文提出了一种结合概率路由的机会网络自私节点检测算法—SNPR,该算法能有效地提高节点自私性判断的准确性和减少网络开销.
4.1 交互模型
机会网络中相遇节点的通信过程如图1所示,节点C接收到节点B周期性的Hello消息后,与节点B交换SV(Summary Vector)列表与DP(Delivery Predictability)列表信息,SV列表中储存每个节点所携带的消息的摘要信息,如图2所示,DP列表记录了本节点与其它节点的相遇概率,如图3所示,节点B与节点C比较彼此的SV列表与DP列表后,向对方请求自身所没有的并且自身与目的节点相遇概率更高的消息,以及发送对方所请求的消息.
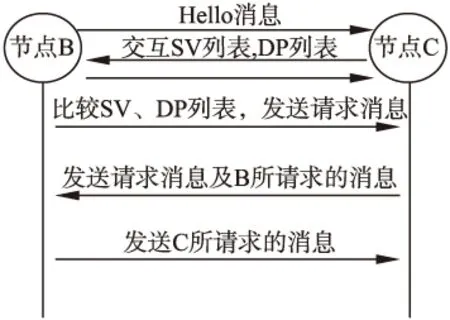
图1 节点间交互模型
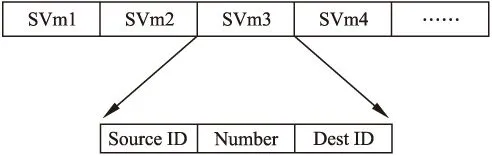
图2 SV列表

图3 DP列表
4.2 SNPR算法包含的新机制
SNPR算法包含3种新机制,具体如下.
4.2.1 基于控制消息判定节点自私性
当前节点在接收到对方节点的SV-DP消息以后,首先利用对方的SV列表中的信息进行判断对方节点是否是非自私节点:若对方SV消息列表中存在源地址不是对方节点的消息,则表示对方节点在为其它节点转发数据消息,据此可以判定出对方节点是非自私节点;若对方节点SV列表中的消息的源地址都是对方节点,则判定其为难以判断类型的节点.
当与对方节点交互SV、DP列表以后,若未判定对方节点为自私节点,则向对方请求自身所没有并且与目的节点相遇概率高于对方节点的消息,并将对方所请求的消息发送给对方.此过程存在以下检测判定:
1)当前节点SV列表中包含有对方节点SV列表中没有且目的地址不是对方节点并且对方节点与目的节点相遇概率更高的消息,但对方节点未请求这类消息,则可以判定对方节点为自私节点.
2)若对方节点请求了1)中所说的这类消息,当前节点将对方节点所请求的消息发送给对方,并采用监听机制监听对方节点是否进行了消息转发.若对方节点进行了消息转发,则当前节点对监听到的数据消息进行头部地址信息的提取,比较消息源地址是否是对方节点,若不是则判定对方节点是非自私节点;否则采用RSSI机制[14]判断对方节点是否仍处于当前节点的监听范围,若是则继续监听,若不是则将对方节点的类型归为难以判定类型.
如图4所示为基于控制消息判定节点自私性机制的流程图.
4.2.2 借助相遇节点信息判定节点自私性
当前节点(称之为“节点A”,下同)与对方节点(称之为“节点B”,下同)完成数据消息交互之后,节点A继续监听节点B的消息转发行为.
若监听到节点B与另一节点(称之为“节点C”,下同)进行了数据传输,则在节点A中记录节点C的地址信息,表示节点A在监听过程中发现节点B与节点C进行了消息交互,同时对监听到的数据消息进行头部地址信息的提取,若消息源地址是节点B,与此同时节点A采用RSSI机制判断节点B即将离开节点A的监听范围时,那么根据“基于控制消息判定节点自私性”机制只能将节点B归为难以判断类型的节点.为了进一步对节点B的类型进行判断,节点A接下来在一段时间内如果遇到节点C,则根据“基于概率值捎带节点自私信息”机制查看节点C的DP列表中对应节点B的概率,若节点C根据“基于控制消息判定节点自私性”机制将节点B判定为自私节点或者非自私节点时,节点A则根据节点C的判断结果将在自身DP列表对应的节点B处判定为相应的类型;若节点C将节点B判定为难以判断类型的节点时,根据“基于控制消息判定节点自私性”机制可知节点B的SV列表中没有源地址为其它节点的消息,而节点B与节点C交互之前节点A转发了消息给节点B,由此可知节点B将节点A转发的消息删除了,因此判定节点B为自私节点.

图4 机制1流程图
若节点A在监听过程中没有监听到节点B与其它节点进行数据交互时,则节点A按照如图5所示的结构记录相应的信息(Address表示相遇节点的地址;T表示相遇的时间点;Flag取值为0或1,用于表示当前节点是否转发了目的地址不是相遇节点的消息给相遇节点;PreHop表示相遇节点在与当前节点相遇之前的上一个相遇节点地址).当节点B在脱离监听范围后与其它节点(称之为“节点E”,下同)进行数据交互时,若节点E在与节点B交互过程中将节点B判断为自私节点或者非自私节点,则节点E不对节点B的信息进行记录,原因是:根据“基于概率值捎带节点自私信息”机制可知,当节点E与节点A相遇时,节点A查看节点E的概率列表就可以知道节点B是自私节点还是非自私节点.若节点E在与节点B交互过程中将节点B判断为难以判断类型的节点时,则按照图5所示的结构记录节点B的信息,此时PreHop记为A节点地址.当节点A与节点E在某个时刻相遇时,根据记录信息可知,节点A在与节点B交互完之后,节点B与节点E进行了消息交互,而由于节点A中的Flag等于1,因此可以判定节点B将节点A转发的消息删除了,从而判定节点B为自私节点.

图5 记录信息列表
Fig.5 Record information list
针对以上两种情况提出一种融合机制,即节点A与节点B进行消息交互之后,若通过监听仍然无法判断节点B的节点类型时,节点A采用如图6所示的信息列表记录节点B的信息(NextHop表示节点A监听到与节点B进行通信节点的地址).机制的具体实现过程如下:

图6 信息列表
Fig.6 Information list
S1:节点A中的Address记为节点B的地址,T记为当前时间TAB,PreHop记录节点B在与节点A进行交互之前的上一个交互节点,假设为节点G;
S2:若节点A在监听范围内监听到节点B与其它节点(例如,节点C)进行了消息交互,则在节点A的NextHop中记录节点C的地址,否则记为0;
S3:节点A在与节点B进行消息交互时,若节点A转发了目的地址不是节点B的消息给节点B,节点A中的Flag则记为1,否则记为0;
S4:当节点A与其它节点(假设为节点E)进行交互时,先根据“基于概率值捎带节点自私信息”机制判断节点B的类型,若节点E已判断出节点B的类型,则节点A根据节点E的判断结果进行修改,同时删除记录信息;
S5:若节点E只是将节点B判为难以判断类型的节点时,节点A首先查看NextHop是否为0,若不为0则比较节点E的地址值是否等于NextHop的值,若相等则查看Flag的值是否等于1,若Flag=1,则判定节点B为自私节点,若Flag=0或者节点E的地址不等于NextHop的值,则判定节点B为难以判断类型的节点;若节点A的NextHop值为0,且Flag=1,则查看节点E中Address值为节点B的记录信息,若TEB的值大于TAB,且节点E中的PreHop的值为节点A的地址,则表示节点A在与节点B交互完之后,节点B与节点E进行了消息交互,因此可以判定节点B为自私节点.
一旦判断出节点的类型,则删除对应节点在信息列表中的记录.
4.2.3 基于概率值捎带节点自私信息
在不增加额外控制开销的情况下,节点将其它节点的自私性信息用DP列表中的概率值捎带着传输:即将DP列表中到自私节点的概率值设置为负的当前值,将DP列表中到难以判断的节点类型的概率值设置为当前值加1,将到非自私节点的概率值用正常的0和1之间的值表示.当收到了相遇节点发来的DP列表后,节点便能够根据其DP列表中的概率值判断对应的节点的自私性.该机制能够在不增加额外控制开销的情况下有效地散播节点的自私性信息.
所述的“基于概率值捎带节点自私信息”新机制在不增加网络开销的前提下,使节点将其它节点的自私性信息用DP列表中的概率值捎带着传输,具体实现过程如下:
S1:机会网络中的节点通过周期性的广播Hello消息与其它节点进行邻居发现,节点双方发现彼此互为邻居后,交互SV-DP列表消息;
S2:节点在发送SV-DP消息之前,根据自己掌握的其它节点自私性信息,将其它节点在DP列表中对应的节点的概率值设置为负值、0~1之间的值或者1~2之间的值:自私节点的概率值在原值上取反成为负值、非自私节点的概率值在原来的0~1之间保持不变、难以判断的节点的概率值在原值上加1,因此位于1~2之间;
S3:若一个节点收到相遇节点的SV-DP列表后,将该SV-DP列表中概率值为负的节点在本节点的SV-DP列表中相应的节点处将概率值置为负的当前值;若收到的SV-DP列表中节点对应的概率值在0~1之间,执行步骤S4;若收到的SV-DP列表中节点对应的概率值在1~2之间,不做处理;
S4:当收到的SV-DP列表中节点对应的概率值在0~1之间时,表明节点是非自私节点,此时若本节点SV-DP列表中对应的该节点概率值在1~2的范围时,将该概率值减1;若概率值在其他范围时,不做处理.
4.3 算法操作
SNPR算法的具体操作步骤如下:
Step 1.节点C接收到节点B广播的Hello消息后,节点C查看自身的DP列表中是否有节点B.若有则表明节点非初次相遇,节点C根据 DP列表判断节点B是否是自私节点,如果没有判定节点B为自私节点,则采用PROPHET算法[3]更改到该节点的相遇概率.若节点初次相遇则加入DP列表中并赋初值.
Step 2.如果节点B没有被判定为自私节点,则节点C向节点B发送自身的SVC与DPC消息.
Step 3.节点B收到节点C的与消息后,先执行“基于概率值捎带节点自私信息”机制来更新自己的SV-DP列表,然后查看自身的DP列表来判定节点C是否是自私节点.若节点C为难以判定类型的节点或是初次相遇的节点,则根据节点C的SVC消息来判定节点C是否是非自私节点:如果节点C是非自私节点,则更新DP列表中对应节点的概率值;否则DP列表维持不变.
Step 4.如果节点C没有被判定为自私节点,则节点B向节点C发送自身的SVB与DPB消息以及发送请求消息.
Step 5.节点C收到节点B发送的SVB与DPB消息以及发送的请求消息后,执行“基于概率值捎带节点自私信息”机制来更新自己的SV-DP列表.如果节点B为难以判定类型的节点,则根据SVB消息来判定节点B是否是非自私节点:如果节点B是非自私节点,则更新DP列表中对应节点的概率值;否则根据节点B发送的请求消息来判断节点的自私性.
Step 6.如果节点B没有被判定为自私节点,则节点C向节点B发送请求消息以及节点B所请求的消息.
Step 7.若节点B仍为难以判定类型的节点,则节点C发完消息后采用监听机制监听节点B的消息转发行为,若监听到节点B与另一节点(称之为“节点E”,下同)进行了数据传输,则记录节点E的ID同时对监听到的数据消息头部进行地址信息的提取,若消息源地址不是节点B,则判定节点B是非自私节点;否则判断对方节点是否仍处于当前节点的监听范围,若是则继续监听,若不是则采用“借助相遇节点信息判定节点自私性”机制来对节点B的类型进行进一步地判定.
在每次判定中,若判定出对方节点为自私节点,则停止与其进行通信,并更新节点DP列表中对应节点的概率值.
5 仿真验证
本文采用OPNET14.5网络仿真软件对SNPR算法的性能进行仿真验证,并将仿真结果同基于2-ACK算法和RSND算法的仿真结果进行对比.
5.1 仿真参数
本文在不同的自私节点比例场景中进行仿真,其仿真具体参数如表1所示.
表1 仿真参数设置
Table 1 Simulation parameter settings
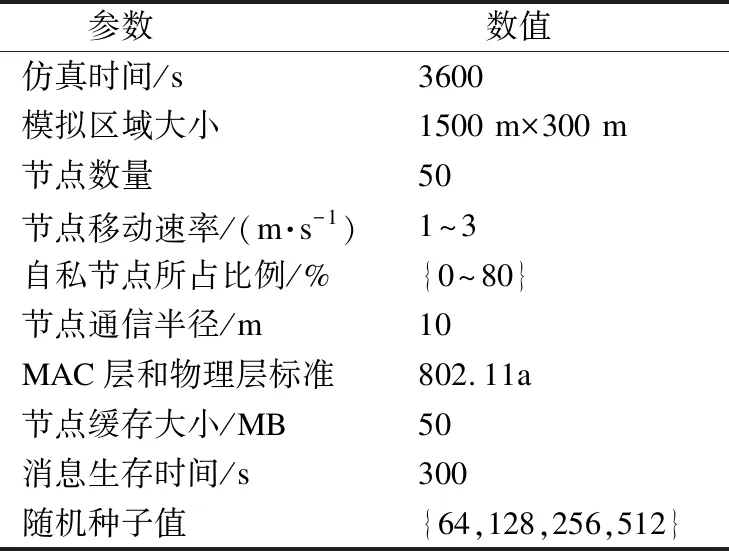
参数 数值仿真时间/s3600模拟区域大小 1500 m×300 m节点数量50节点移动速率/(m·s-1)1~3自私节点所占比例/%{0~80}节点通信半径/m10MAC层和物理层标准802.11a节点缓存大小/MB50消息生存时间/s300随机种子值{64,128,256,512}
5.2 仿真结果及分析
5.2.1 自私节点检测准确率
如图7所示,随着自私节点比例的增加,SNPR算法能够保持较高的自私节点检测准确率,并且检测准确率明显优于RSND算法和2-ACK算法,其主要原因在于提出了“基于控制消息判定节点自私性”和“借助相遇节点信息判定节点自私性”这两种新机制,使得自私节点检测准确率得到提高.

图7 自私节点检测准确率
5.2.2 消息到达率
消息到达率是指所有目的节点接收到的数据总量R与所有源节点产生的数据总数S的比值,计算公式为:
η=R/S(其中η表示消息到达率)
(1)
如图8所示,随着网络中自私节点比例的增加,消息到达率在减小.因为网络中自私节点数越多,消息被转发的次数就越少,从而导致消息到达率降低.从图中可以看出SNPR算法的消息到达率相比于2-ACK和RSND算法得到了提高.其原因是RSND算法中,当对相遇节点的自私性无法判定时,采取网络中的自私节点比例对相遇节点进行概率定性,当网络中的自私节点比例增加时,对非自私节点误判的概率也就越来越高,导致更多的消息无法成功传送.SNPR算法采用了“借助相遇节点信息判定节点自私性”机制,使得对节点的自私行为判断更为准确,并且不受自私节点比例的影响,因此消息到达率得到提高.
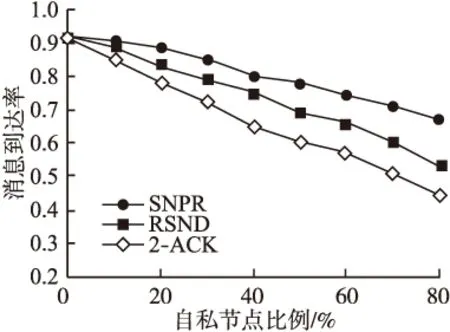
图8 消息到达率
5.2.3 吞吐量
吞吐量表示网络传输数据消息的能力,它是指单位时间内网络中成功传输数据消息的比特数,计算公式为:
Throughput=P/(Tend-Tstart)
(2)
其中P表示的是网络中数据消息成功到达目的节点的总比特数,Tstart表示网络仿真开始时间,Tend表示网络仿真结束时间.
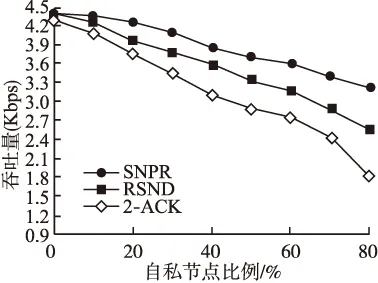
图9 网络吞吐量
如图9所示,吞吐量随着网络中自私节点的比例增加而减少,原因是网络中自私节点数越多,消息到达率就减少,从而导致吞吐量下降.另外,从图中可以看出 SNPR算法的吞吐量明显高于2-ACK算法和RSND算法.其主要原因是SNPR能更准确的判断相遇节点是否为自私节点,对自私节点和非自私节点所产生的消息都能进行正确处理,减少了对非自私节点判断失误而采取的惩罚策略,使更多的消息能传递到目的节点,因而吞吐量得到提升.
5.2.4 平均时延
平均时延表示数据消息成功传输到目的节点所需要的平均时间,其计算公式是:
(3)
其中,D表示数据消息到达目的节点的个数,Ti表示第i个消息到达目的节点的时延.
如图10所示,随着自私节点比例的增加,平均时延在上升,原因是网络中提供消息转发的节点数在减少,消息不能及时地进行转发.同时,SNPR算法的平均时延小于2-ACK算法和RSND算法,其原因是SNPR算法对自私节点的检测更为准确,避免因对非自私节点判断失误而导致消息没有及时转发带来的时延,使消息能更迅速的在非自私节点之间传输;同时由于“基于概率值捎带节点自私信息”机制能够减少网络中的控制消息,使得数据消息能够提前转发.
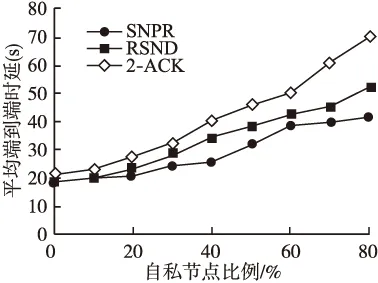
图10 网络平均时延
6 结束语
本文提出了一种结合概率路由的机会网络自私节点检测算法.该算法由“基于控制消息判定节点自私性”、“借助相遇节点信息判定节点自私性”和“基于概率值捎带节点自私信息”三种新机制组成.通过采用“基于控制消息判定节点自私性”和“借助相遇节点信息判定节点自私性”这两种机制能够提高自私节点检测的准确性并且能够检测出网络中更多的自私节点,在传输数据包时减少将消息转发给自私节点的情况,进而提高数据包到达目的节点的成功率;采用“基于概率值捎带节点自私信息”机制能够使节点在不增加字段或消息的前提下,将其它节点的自私性信息用DP列表中的概率值捎带着传播给相遇节点,从而降低了网络控制开销.由于机会网络中消息的传输时延较大,因此下一步的工作是对机会网络的路由转发策略进行研究,通过研究路由转发策略来提高消息的转发效率.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
家庭影院技术(2021年3期)2021-05-21
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
课堂内外(初中版)(2020年5期)2020-06-19
中学生数理化·教与学(2017年4期)2017-04-22
中学生数理化·中考版(2015年10期)2015-09-10
环球时报(2014-03-24)2014-03-24
小说月刊(2012年3期)2012-05-08
