
基于HBase的QAR数据存储设计与实现
2020-05-23 10:06霍纬纲程文莉李继龙
计算机工程与设计 2020年5期
霍纬纲,程文莉,李继龙
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
QAR(quick access recorder)意为快速存取记录器,是指带保护装置的机载飞行数据记录设备。QAR数据涵盖了飞机飞行操纵品质监控的绝大部分参数,具有时序性、容量大、参数多等特点,是典型的多维时间序列数据。目前,中国民航每一架飞机上都已安装快速存取记录器,用以记录飞机包含的所有传感器每秒钟所产生的数据。据统计,一个中等规模航空公司每年产生的QAR数据量可达到PB级,甚至TB级。通过对QAR数据的有效存储和分析,航空公司可以掌握公司航班飞行的安全动态,从而有针对性地加强安全监管,减少事故隐患,提高飞行品质[1]。
传统的关系型数据库在存储海量QAR数据时存在性能瓶颈、数据组织模式单一、延时较高等诸多问题[2]。HBase[3](Hadoop database)是一个高可靠、高性能、面向列、可伸缩的分布式数据库,数据模式简单、灵活、存储速度快、扩展性高。文献[4-7]将HBase数据库分别应用于智能交通、船舶自动识别、云智能室内环境监测、生物DNA与蛋白质对等领域,都验证了HBase作为海量数据存储的可靠性。但根据QAR数据的特点和应用场景设计基于HBase的存储模式和行键结构至关重要。根据HBase中的数据写入及存储特点,如果仅按照快速存取记录器的采集时间作为行键,虽然从一定程度上能够保证查询效率,但在数据写入时,集群会出现热点问题,造成较大的写入延迟。另外,QAR数据参数众多(维数高),需设计合理的HBase表结构,以满足航空公司对QAR数据分析的查询需求。本文设计实现了一种基于HBase的QAR数据存储模式。该存储模式能够较好满足航空公司分析飞行超限事件的业务需求。将QAR数据划分为七大主题,设计了基于主题优化策略的行键,并采用了预分区技术,避免了写热点问题,使QAR数据能均衡地分布在集群中。
1 相关工作
HBase作为时间序列数据的存储介质在工业领域中有着广泛的应用。文献[8]从不同角度探讨、设计了行键结构,并通过二级索引改善了HBase的查询效率,但随着RegionServer(HBase集群中的从节点)中的Region(HBase中数据存储和管理的基本单元)发生split(分裂)操作,其索引结构需要不断更新,带来更新延迟;文献[9]通过采用MySQL和HBase存储地震业务需求的结构化数据和非结构化数据,非结构化数据采用基于列簇级别的大对象对文件形式的数据进行管理,对小文件数据的存储有较好的效果;刘博伟等[10]对于金融的时序数据的存储:该系统采用了异步机制的时间驱动的Netty中间件,对高并发事务有较好的处理性能,设计了基于HBase的行键优化策略和基于时序数据的表设计策略,在一定程度上解决了HBase存储热点问题以及数据存储的分散问题;陆婷等[11]利用多源缓冲结构对不同类型的流数据进行队列划分,结合一致性哈希、多线程技术、行键优化设计策略将数据存入HBase,实现了多源数据的存储性能的提升,具有良好的扩展性能;王远等[12]针对海量智能电网数据的存储,提出以策略驱动的基于HBase的时序数据存储方法,在OpenTSDB中实现了数据分散存储同一时间产生的数据,提高了数据加载时的I/O能力和查询分析能力,但只适用于数值型数据,存在一定的局限性;Ochiai H[13]等设计了基于HBase的楼宇设备信息管理系统,收集某栋大楼内的光照、暖通等设备传感器的数据进行存储。基于非关系型模型的QAR数据存储研究工作相对较少,冯兴杰等[14]设计了基于Hive的数据仓库的构建:通过对Hive特点及QAR数据结构分析,设计了基于Hive的QAR数据仓库的存储结构,该设计更适用于分析型应用,无法满足具有低延迟要求的QAR操作型应用需求。本文在上述工作基础上,根据QAR数据特点,设计实现了基于HBase的QAR数据存储模式,实验结果表明该存储模式具有良好的存取性能。
2 数据存储模式设计
2.1 参数主题划分
经过与领域专家讨论,将航空公司所关注的问题按主题对QAR数据进行划分,归纳为以下主题:安全分析主题、航迹描绘主题、节省燃油主题、发动机状况主题、预测主题、飞行员操作分析主题和其它主题。主题与QAR参数的对应关系见表1。

表1 参数主题划分
2.2 QAR数据存储设计
2.2.1 HBase表结构设计
经译码后的每个QAR文件包含飞机的航班信息、参数信息、参数值3部分,所以文中将每个QAR文件中的数据划分为航班元信息、参数元信息和参数值3类。根据QAR文件中的数据类别和超限事件分析需求设计了4张表,分别是航班元信息表Flight_info,参数元信息表Para_info,航班参数索引表Index和数据值表Value。
Flight_info表的行键为航班号与日期的组合。该表包含一个列簇Flight_CF,列簇中的列分别为航空公司、机尾号、起飞时间、落地时间、起飞机场、落地机场、航班序列号,其中航班序列号对应每个QAR数据文件唯一编号,记为fid。Flight_info表的表结构见表2。

表2 Flight_info表结构
Para_info表以参数名称作为Para_info表的行键,该表包含一个列簇Para_CF,该列簇包含参数的简称、单位、所属主题、序列号。根据2.1节中的参数主题划分确定参数的主题,记为topic,由每个参数的采集顺序生成一个唯一的参数序列号,记为pid,其结构见表3。
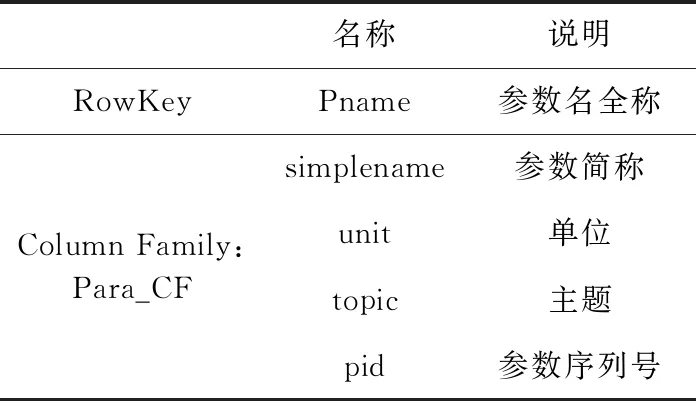
表3 Para_info表结构示意
Index表相当于下文Value表的索引,该表共包含两个列簇:Index_CF1和Index_CF2。该表的行键为航班号、航班日期、参数名三者的组合。Index_CF1列簇包含一个列,该列将Flight_info表的fid与Para_info表的pid进行组合,记为paraid;Index_CF2列簇中包含一个列,该列存储Index_CF1:paraid对应的航班号、日期及参数对应主题名三者组合的MD5值的前四字节,即Value表行键的前四字节,记为md5。Index表的结构见表4。
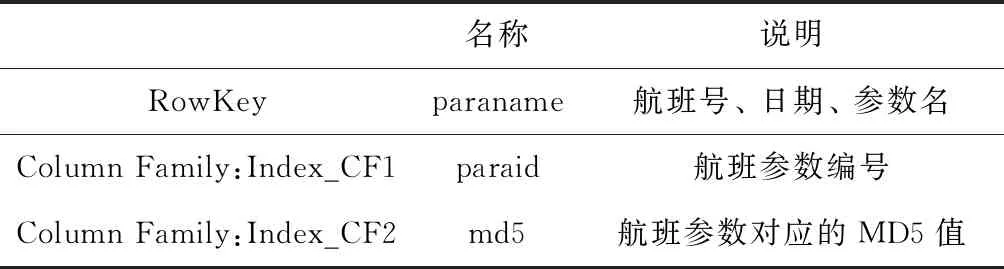
表4 Index表结构
Value表负责存储QAR文件中参数的时序数据值,每行存储一个航班文件中一个参数在一分钟内的数据。该表的行键设计参见2.2.2节的详细说明。除行键外,Value表包含一个列簇Value_CF,该列簇包含60列,分别存储QAR参数一分钟内每秒的数据值,列名即为秒数,其表结构见表5。
2.2.2 Value表行键设计
根据QAR参数的主题划分及2.2.1节HBase表结构
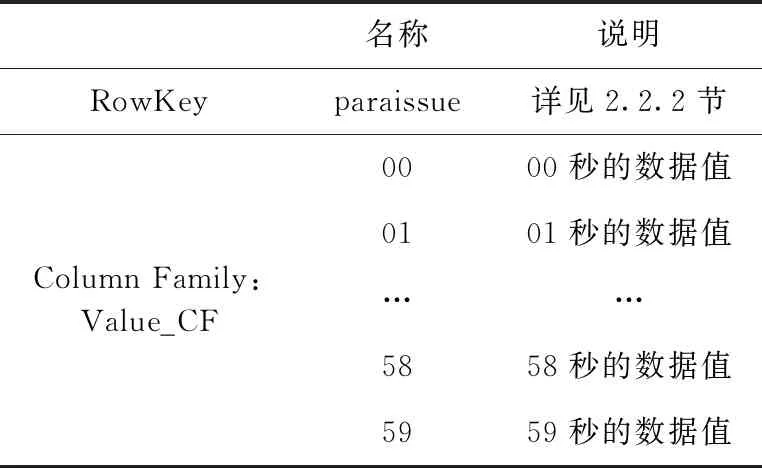
表5 Value表存储结构
设计对Value表的行键结构进行了设计,其结构如图1所示。Value表的行键设计中包含了以下信息:航班号、航班日期、参数及参数所属主题、参数取值对应的时间。由于在设计行键时应保证行键的长度应尽量短,尽可能占用较少的存储空间,本文设计行键长度为16个字节,行键的前4个字节内容计算方式为:航班号、航班日期及参数主题进行组合,采用MD5散列方法对该组合进行处理,取散列值的高四字节作为行键的高4字节内容。行键的中间八字节取Flight_info表的fid和Para_info表的pid序列号组合。低四字节取参数采集的时间中的小时、分钟位。

图1 Value表行键结构
现以2017年7月19日的某航班的名为GROUND SPEED的参数在4∶46分的数据为例说明Value表行键结构及数据存储形式。该航班的fid为0018,参数的pid为0179,将时间4∶46以0446表示,将一分钟内的数据存入Value表,其存储形式如图2所示。

图2 行键计算
2.2.3 预分区设计
HBase在创建数据表时同时创建一个没有起始和终止行键的Region,数据按照键值对的字典序升序向该Region中写入,随着写入数据的增多,当HBase中的Region达到阈值,会频繁触发Split操作。这种原始的写入机制会产生热点问题,并且split操作也会消耗集群的I/O资源。本文在2.2.2节基于MD5散列行键设计的基础上,采用预分区策略,以进一步提高集群读写性能。具体分区策略如下:
取散列值的前两个字节作为预分区的splitKey。MD5散列值的前两个字节的取值范围是00~ff,假设拟划分m(m为整数)个分区,将00~ff范围内的候选splitKey从1开始进行编号,按照如下方式初步确定预分区的splitKey,第n个region的切分键的序号产生方式如式(1)所示

(1)
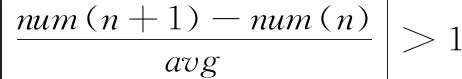

(2)
其中,x的取值如式(3)所示
(3)
最后,根据得到的预分区结果生成二维字节数组splitKeys,创建预分区的Value表。
2.3 存储及查询过程实现
2.3.1 QAR数据存储实现
下面按2.2.1节设计的表结构说明QAR数据的存储过程。其中Flight_info表与Para_info表、Index表的存储原理类似,现以Flight_info表的存储过程为例描述。文中将所有译码后的QAR数据文件的路径记录在文本文件file_path.txt中,通过读取file_path.txt文件中的路径打开QAR文件,然后解析具体QAR文件的表头第一,二行内容,生成Flight_info表对应的航班元数据信息。其中航班号为航空公司二位代码和航班序号组成,航班日期按格式yyyymmdd进行提取,机尾号为字母“B”加数位阿拉伯数字构成,起落地机场为机场四字码,起落地时间为12小时制,以AM与PM区分日间或夜间。在读取QAR文件的路径时,记录该路径所在位置,生成4个字节的数字序列号,将序列号赋值于fid。将QAR文件表头与Flight_info表相关的数据以Put(List

图3 Flight_info等表数据存储流程
首先,创建List
Value表存储QAR文件的参数值部分。首先,每100行为一组读取QAR文件的数据部分。对于每组中的数据按照参数维进行处理,取每行的参数采集时间切分为时分数据和秒钟数据,按2.2.2节的行键设计方式组织行键,并创建对应的Put对象,以秒钟数据作为Value表的列名,将每分钟的数据列添加至Put对象中,将该Put对象添加至Put列表对象中,最后提交到数据表,完成该组参数的数据值存储,再进行下一组数据的存储。
Value表数据写入
Input:file_path
Output:void
if(count% 100)then//每100行数据进行处理
batch←List
forjfrom0tothirdlenthen//从参数维进行循环处理
forkfrom0to100then//以读取到的100行为循环对数据进行处理
mintim←time(k).subString()//将时间的子字符串的时分数据截取
sectime←time(k).subString()//获取时间字符串的秒数数据
rowkey←md5+fid+pid(j)+mintime//组合为Value表的rowkey
qualifier←sectime//以秒钟时间作为列名
value←value[k][j]//将数据部分的参数值作为value值
put←Put(rowkey)//以rowkey创建Put对象
put.addColumn(CF,qulifer,value)//将键值对添加至对应行的put对象
batch.add(put)//将Put对象添加到列表中
endfor
endfor
table.put(batch)//将Put列表提交到对应表
endif
2.3.2 数据查询实现
定义f、p、t1、t2分别代表航班号、参数名称、起始查询时间、终止查询时间,飞行品质监控分析中典型的查询条件表示为q(f,p,t1,t2)。 例如2017年7月19日航班号为AB2834的航班,k时间在12:34到12:36的地速GROUND SPEED取值查询表示为q("AB283420170719","GROUND SPEED", "1234","1236")。 现以该查询为例说明文中的QAR数据查询实现过程,具体如下:
首先,根据查询参数f="AB283420170719"、p="GROUND SPEED"、t1="1234"、t2="1236",将查询条件按照index表的行键结构进行组织,得到index表的rowkey="AB283420170719GROUND SPEED",通过行键过滤器获取到index表对应的paraid列值:“00180179”和md5列值:“c9c6”;然后,将两列值组合得到Value表行键的高十二字节。其次,将查询的参数的时间范围添加至Value表行键的低四字节,得到查询Value表的行键范围:"AB283420170719GROUND SPEED1234"~"AB283420170719GROUND SPEED1236";设置二级过滤器,分别以GREATER、LESS对Value表进行过滤;最后,创建扫描器对象,将二级过滤器添加至扫描器对象,返回查询结果。其它飞行品质监控的查询场景如单值查询、基于参数主题的查询等与上述查询原理相似。
飞行品质分析典型查询实现
Input:f,p,t1,t2
Output: result
table1←pool.getTable(“Index”)//通过连接池创建与Index表的连接
table2←pool.getTable(“Value”)
rowkey1←f+p//将查询航班号、 参数名组合为index表的查询行键
get←Get(rowkey1)//创建get对象
paraid←table1.get.addColumn(“paraid”)//从index表获取paraid列
md5←table1.get.addColumn(“md5”)//从index表获取md5列
startrowkey←md5+paraid+t1//将时间与md5、paraid组合为查询起始行键
endrowkey←md5+paraid+t2//将时间与md5、paraid组合为查询终止行键
setfilter1(GREATER,startrowkey)//对起始行键按GREATER指定过滤器1
setfilter2(LESS,endrowkey)//对终止行键按LESS指定过滤器2
filterlist←FilterList//创建过滤器列表,为多级过滤器指定通过方式
scan←Scan()//创建扫描器对象
scan.setFilter(filterList)//为扫描器对象设置过滤器列表
scanner←table.getScanner(scan)//在数据表上创建扫描器
result←scanner.next()//得到Result结果集,并输出
3 实验结果与分析
3.1 实验环境设置
实验数据为某航空公司2017年200个航段的QAR数据文件。实验集群包含3个节点:一个主节点master和两个虚拟从节点slave1、slave2。集群整体搭建在一台内存为16 G、磁盘存储空间为2 T的服务器上,服务器型号为Power-Edge T130。每个节点分配50 GB磁盘空间,1 GB内存,单核CPU。Hadoop集群的版本分别为Hadoop 2.7.3,Zookeeper3.4.10,HBase1.2.6。文中设置分区个数m为27,按照2.2.3节预分区设计方法,经过预分区的测试实验,确定预分区的Splitkey为{1, 1b, 2a, 2f, 2z, 3b, 42, 4e, 5c, 65, 6f, 72, 7b, 80, 8f, 93, 9e, a6, ac, b4, bf, ca, d, df, f, fc}。集群中HDFS的复制因子设置为2。
3.2 QAR数据存储分布实验
实验在QAR文件数量逐步递增的情况下,验证集群中QAR数据存储分布效果。共设置了5个测试,每个测试使用的QAR文件个数见表6。实验结果如图4所示。
图4中横坐标表示测试的次数,左侧纵坐标表示集群数据节点的数据量,右侧纵坐标表示实验过程中所用数据总量,单位均为GB。DN1、DN2表示集群的数据节点DataNode1、DataNode2,数据量图例表示每次测试实验的数据量大小。从图中不难看出,集群的数据节点DN1、DN2

表6 实验一数据
的数据量在各测试实验中始终保持相对均衡,随着数据总量的线性增长,各数据节点的数据增长也呈现相同的趋势,各数据节点中存储的数据量大小相差少于2%。本设计中,Value表的行键高位采用了哈希处理,使Value表中的数据分布具有更好的离散性,避免了数据写热点问题的发生。在行键的哈希设计基础上,Value表采用预分区技术,共划分27个分区,各数据节点上的数据分区数量相对均衡,避免了数据倾斜。
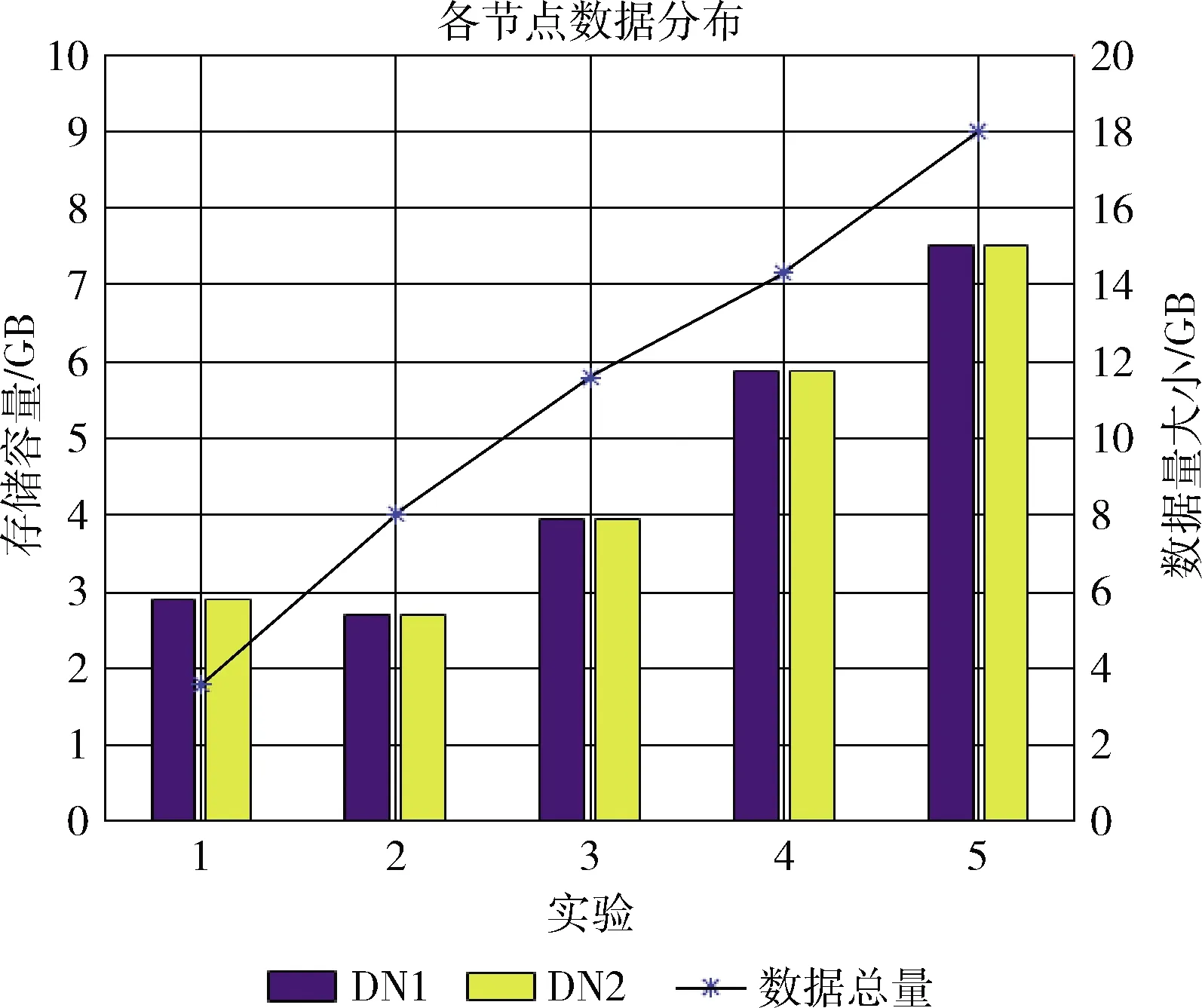
图4 QAR数据存储实验结果
3.3 QAR数据查询实验
根据实际飞行品质分析需求,本节设置了3种不同的查询场景。具体如下:
实验1:查询指定航班指定参数连续5分钟内的300个参数数据。
实验2:查询指定航班指定主题下的5个不同参数,在1分钟内的60个连续数据,共300个值。
实验3:查询指定航班5个不同主题下的指定参数在1分钟内的60个连续数据,共300个值。
以上的每个实验均进行20次测试,实验结果如图5~图7所示。图5~图7中横坐标表示实验次数,纵坐标表示查询耗时,单位为ms。图5~图7中的20次查询的平均耗时分别为291.45 ms,1860.4 ms,1992 ms。由此可知,文中的存储设计最适用于查询指定QAR参数在一段时间内的连续取值序列。同一主题下的不同参数的取值序列查询效率高于不同主题的参数取值查询。这是因为在本文Value表的行键结构设计中,基于航班号和参数主题的哈希散列值能使同一个主题的不同参数连续存储在region中,在行键的中间八字节采用航班编号及参数编号对参数进行精确定位,Value表行键的低四字节取参数的采集时间,使得同一参数的数据以时间的递增顺序存储在连续空间中。

图5 实验1结果
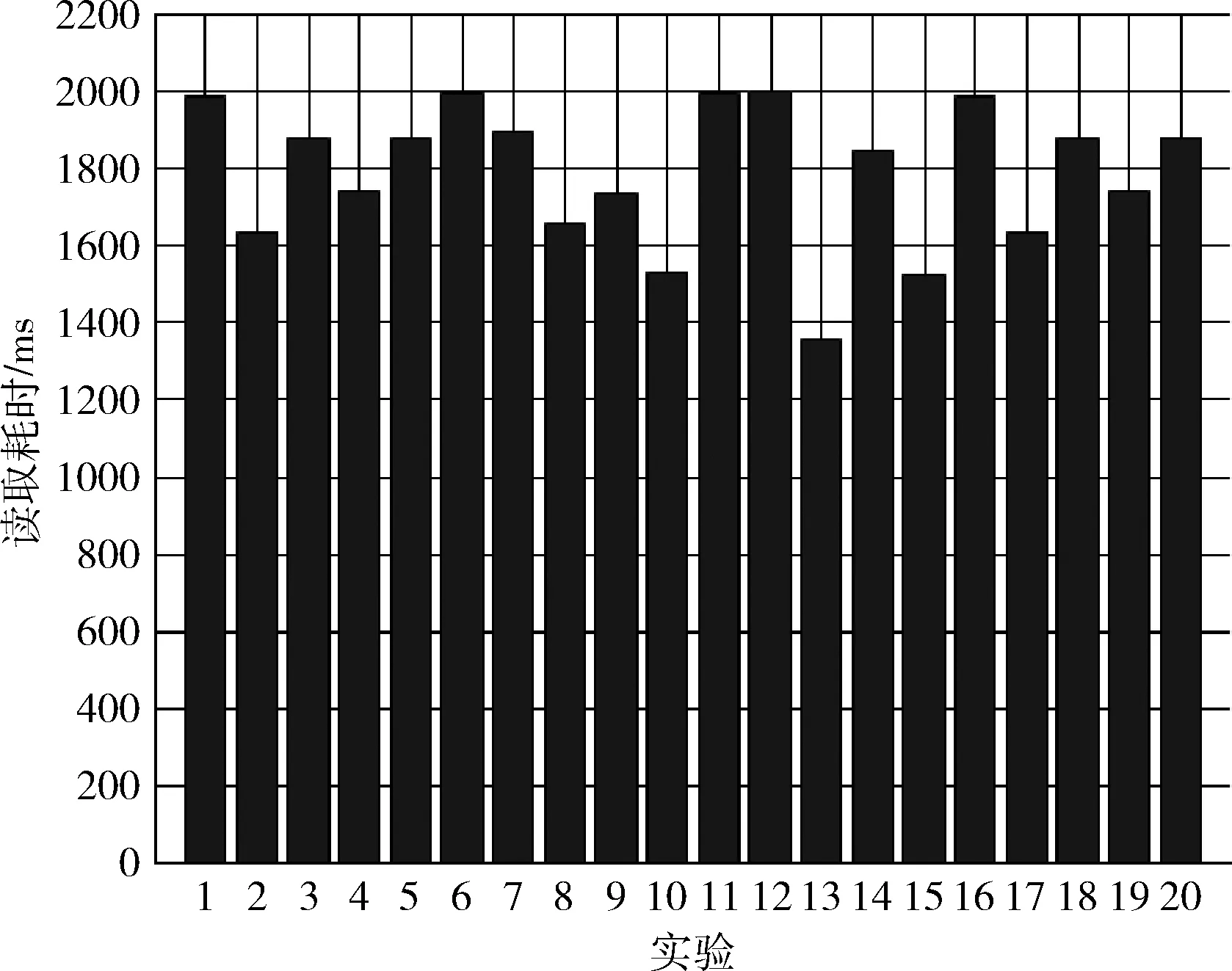
图6 实验2结果

图7 实验3结果
3.4 查询对比实验
为了验证文中设计的存储模式在典型QAR数据查询分析上的有效性,与文献[10]中存储时序数据的行键设计策略进行了对比。根据文献[10]的行键设计方法,实验中将航班号、日期、参数名及参数采集时间作为行键,以指定航班指定参数在一段时间内的取值序列为查询场景,查询序列长度分别为300、3000、300 000,每个实验均进行20次。实验结果如图8(a)~图8(c)所示。图8中每个图的横坐标为实验次数,纵坐标为读取耗时,单位为ms。由图8(a)可知,在读取参数取值序列较短的情况下,本文存储设计模式的查询耗时与采用文献[10]的行键设计存储模式下的查询耗时相差较小。但是,从图8(b),图8(c)不难看出,随着参数取值序列的增长,本文存储模式下的查询耗时明显低于文献[10]的行键设计策略的查询耗时。这是因为按照文献[10]的设计进行数据存储时,随着存储数据量的不断增大,HBase中的Region会进行多次分裂。在进行数据查询时,HBase首先根据查询条件生成的行键值确定Region,然后对该Region进行扫描得到查询结果。而本文根据航班号与参数主题散列值的前两个字节及预实验,将Value表分为了27个Region。在查询过程中,本文能根据航班号与参数名对应散列值的前两个字节快速定位待查询数据所在的Region,该过程的耗时少于文献[10]定位Region的策略。而且本文生成每个Region内的数据量也少于文献[10]中由HBase系统自动生成的Region,从而使本文在Region内部的数据查询时间也较少。

图8 与文献[10]实验对比结果
4 结束语
文中设计实现了基于HBase的QAR数据文件的分布式存储模式。根据飞行品质监控业务需求,将QAR参数集合划分为七大主题。设计了基于参数主题的行键组织结构和基于行键MD5散列值的预分区技术。真实QAR数据集上的实验结果表明,文中的设计能使QAR数据文件均匀存储在HBase集群中,在飞行品质分析中典型的QAR参数取值序列查询场景下有较高的查询效率。
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
销售与市场(营销版)(2021年10期)2021-11-21
民航管理(2020年4期)2020-05-10
动漫星空(兴趣百科)(2019年10期)2019-10-14
销售与市场(营销版)(2019年6期)2019-06-21
中小企业管理与科技(2018年11期)2018-11-06
知识经济·中国直销(2018年7期)2018-07-27
人间(2015年11期)2016-01-09
湘潭大学自然科学学报(2015年2期)2015-05-03
