
基于Python 对资讯信息的网络爬虫设计
2020-06-03 02:21严家馨
科学技术创新 2020年5期
严家馨
(重庆大学经济与工商管理学院,重庆400033)
1 相关概念
1.1 Python 语言
Python 是一种面向对象、解释型、可移植的交互式编程语言。其语法简单清晰,容易理解,非常适合编程初学者学习使用。且Python 语言的标准库和第三方库非常庞大丰富,使其功能非常强大,能够完成数据采集、数据分析、数据挖掘、网站开发等。
1.2 网络爬虫
网络爬虫是一种按照一定的搜索规则,自动爬取web 网页的应用程序。首先从一个初始页面的URL 开始,通过分析页面中的其他相关URL,抓取新的网页链接,然后在这些网页链接下,再继续寻找新的网页链接URL,反复循环,直到爬取和分析完所有页面内容。
1.3 Scrapy 框架
Scrapy 是Python 技术语言开发的一个高层次,快速抓取web 网页的框架,用于抓取Web 网页中的内容。Scrapy 的应用非常广泛,常被用于网络爬虫,且其拥有很多简化的高级函数和中间件接口,可以灵活地完成各种需求。
1.4 MySQL
MySQL 是一个关系型数据库管理系统,其可以将网络爬虫爬取的数据信息保存在不同的表中以增加储存速度并提高灵活性。并且能够作为一个单独的应用程序,也可以作为一个库嵌入到其他的软件。被用于Navicat 数据库软件。
2 网络爬虫程序的设计
2.1 伯乐在线网络爬虫的流程结构图
首先确定最新文章的种子地址为start_url,进入最新文章后便通过response.css 选择器来得到第一页及所有下一页的url,选取一部分作为目标url,其余部分放入待爬取的url 队列中等待爬取。在目标url 中同样通过response.css 得出每篇文章特定的目标内容并解析匹配保存到navicat 数据库中。以此再进入下一个循环,直到最新文章的资讯内容全部爬取完成。
2.2 伯乐在线网络爬虫的环境搭建(图1)
开发环境:Windows 系统
开发语言:Python 语言,配置系统环境变量Path
开发工具:Pycharm
Web 抓取框架:Scrapy
数据库管理系统:Mysql 和Navicat
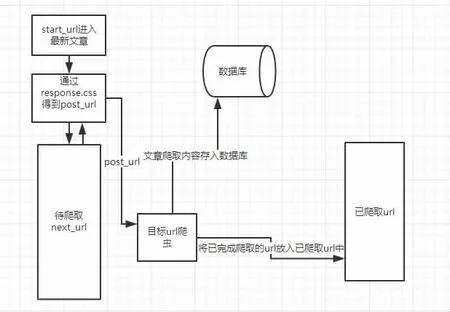
图1
2.3 伯乐在线网络爬虫的详细设计
本爬虫是以Python 语言作为脚本语言编写,Pycharm 作为此爬虫的工具,Scrapy 是此系统的框架。在Pycharm 中创建jobbole 项目并进行Python 语言网络爬虫代码的编写。
2.3.1 伯乐在线资讯信息的获取
a. 进入伯乐在线的开始地址为start_url: ['http://python.jobbole.com/all-posts/']
b. 通过css 选择器获取最新文章中一页的url 和目标文章post_url 并交给scrapy 下载后进行解析。

d.在parse_detail()方法中通过css 选择器获取文章的封面图、标题、创建时间、收藏数、点赞数、评论数、内容等并使用正则表达式进行匹配。

e.item 类的实例化
item 类在Python 中可以指定字段,通过实例化item,网络爬虫爬取的数据不容易出错。
实例化:article_item =JobboleItem()
调用article_item 类:

2.3.2 伯乐在线资讯信息的存储
首先通过MysqlPipelines()方法建立数据库的连接,然后将伯乐在线网站获取的标题、封面图、日期、内容等存入数据库中。

3 网络爬虫程序的测试
3.1 最新文章中封面图的储存,通过pipelines()方法将封面图存储在images 文件中。
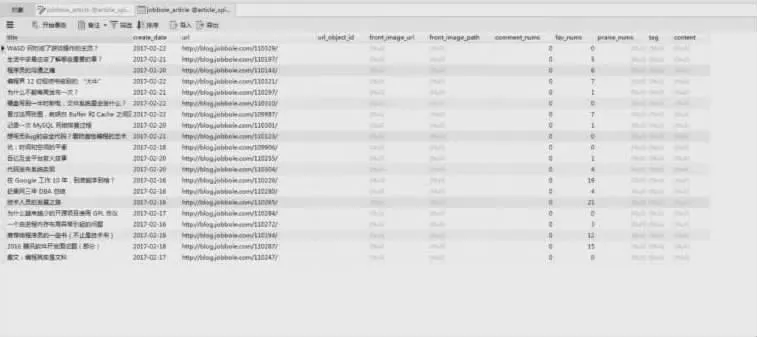
3.2 数据库的存储,在pipelines 中编写MysqlPipelines ()方法,将获取到的所有资讯内容存储到Navicat 数据库中。
结束语
本文基于Python 语言的网络爬虫对伯乐在线最新文章的资讯信息进行了采集设计与测试,通过借助Pycharm 工具和Scrapy 网页抓取框架编写Python 语言的网络爬虫代码,将伯乐在线最新文章中的URL、标题、内容、封面图、点赞数、评论数等信息抓取并保存到数据库中。此设计大大提高了人们对目标资讯信息采集的速度和准确度,也为后续准确高效挖掘与分析数据提供了保证。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
学生天地(2020年16期)2020-08-25
中国-东盟博览(旅游版)(2020年8期)2020-08-19
电子制作(2018年2期)2018-04-18
汽车实用技术(2017年23期)2017-05-29
通信产业报(2016年47期)2017-04-17
电子制作(2017年9期)2017-04-17
人生与伴侣·共同关注(2009年18期)2009-08-31
中外会展(2009年6期)2009-08-07
