
基于强化学习DQN的智能体信任增强
2020-06-24 06:30亓法欣童向荣
计算机研究与发展 2020年6期
亓法欣 童向荣 于 雷,2
1(烟台大学计算机与控制工程学院 山东烟台 264005)2(纽约州立大学宾汉姆顿分校计算机科学系 纽约州宾汉姆顿市 13902)
多智能体(agent)系统是一种分布式计算技术,是多个自主个体组成的群体系统,目标是通过个体间相互信息的通信,进行交互作用.利用多智能体系统对现实问题进行研究已经相当普遍,在社交网络背景下的信任研究是其中的典型研究内容.随着网络的发展,利用社交网络进行推荐已经非常普遍.许多研究都将社交关系网络中的用户信任值作为基础,通过用户的过往交互记录以及用户间的互动来推测用户的偏好和评级,并向用户进行相关项目的推荐.近年来,许多学者都给出了社交网络中信任计算及推荐的方法,这些方法建立在不同研究基础上,也有不同的研究目的.总体来说,大多数方法都聚焦于信任的传递及信任推荐系统,将信任视为静态不变的参数.而实际上,信任作为一种主观状态,可随用户交互经验、时间等因素的动态变化而发生变化.利用静态信任进行计算会使推荐结果渐渐偏离现实状态.
现有的动态信任研究大多针对信任相关因素的变化以及信任变化后的状态,未充分考虑影响信任动态变化的因素及动态变化过程.实际上,信任动态性将在较大程度上影响推荐结果,动态变化过程会实时地反映到推荐系统中,影响推荐系统的系数,进而实时影响推荐结果,使之得到完全不同的推荐结果.因此,将信任来源的动态性和动态变化一起考虑来改进推荐系统的性能可以得到更加准确、及时的推荐结果,使得推荐系统的实时性得到更大的提高,从而改善推荐系统的性能.
现实生活中,当A出于某种目的希望提升B对自己的信任时会主动增加与B的交流次数,这种交流往往是从B的兴趣爱好开始的.如果B喜爱看电影,A会经常向B推荐他可能喜欢的电影.当B对A的推荐电影做出正向评价时,说明A的推荐符合B在电影方面的偏好,同时B将更加相信A在电影方面的欣赏水平,此时B对A的信任将增加;反之,则说明B怀疑A的欣赏水平,B对A的信任值将降低.随着A向B推荐电影的次数增加,A将越来越了解B在电影方面的偏好,并可以更精准地推荐B喜爱的电影,同时,B将十分信任A.该过程实质上是一种学习其偏好并“投其所好”的过程.
本文的方法模拟了上述过程:推荐者为增强用户信任,向用户进行项目推荐,用户接受推荐后,将对项目做出实际评价.实际评价与用户接受项目时的心理预期存在一定差异,该差异决定了用户对项目的满意程度:若实际评价高于心理预期,则用户向推荐者返回正向反馈;反之,用户返回负向反馈.正向反馈表明用户对推荐者的认可,用户对推荐者的信任将增加;负向反馈表明用户怀疑推荐者的推荐水平,导致用户对推荐者信任下降.本文利用强化学习方法实现用户的信任增强,并将其应用到推荐系统中,提高推荐结果的实时性和准确性.实验结果验证了所提出的基于强化学习的深度q-学习(deepq-learning, DQN)的信任增强算法可以更为准确、及时地展现信任的动态变化,并得到更为可信的推荐结果.由于DQN方法有稳定性强、可处理大量数据的特点,所提出的方法可以很好地扩展到推荐系统使用.
本文主要贡献有2个方面:
1) 提出的方法结合了强化学习方法深度q-学习(DQN),对信任变化过程进行学习以增强用户信任.以体验评价和预期评价之间的差值为依据,对用户偏好进行学习,可以得到更为完全的信息,进而提高推荐的个性化水平和准确性.
2) 提出的方法综合考虑了用户的兴趣度、直接信任、间接信任,并对这些因素进行了选择性的筛选,使计算结果更加符合实际.
1 相关工作
在信任的相关研究中,一些学者已经取得了一些成果.如Jiang等人[1]提出的邻域感知的信任网络提取方法,目的为解决信任网络中的信任传播失败问题.该方法考虑到用户在在线社交网络中的领域感知影响力,采用有向多重图对异构信任网络中用户间的多重信任关系进行建模,随后设计了一个领域感知信任度量来度量用户之间的信任程度.Yan等人[2]提出了一种改进后的基于邻域和矩阵分解的社会推荐算法,旨在解决关系网络中的大规模、噪声和稀疏性问题.该方法开发了一种新的关系网络拟合算法来控制关系的传播和收缩,为每个用户和项目生成一个单独的关系网络.然后将矩阵因子分解与社会正则化和邻域模型相结合,利用关系网络生成建议.一些学者在研究过程中对信任的动态性有所考虑,提出了一些关于动态信任的方法,如Ghavipour等人[3]考虑了信任传递过程中用户信任值的改变,提出了基于学习自动机的启发式算法DLATrust,并使用改进后的协同过滤聚合策略来推断信任的价值.在此基础上,Ghavipour等人[4]又提出了利用分布式学习自动机的随机信任传播的动态算法DyTrust,两者目的均为学习发现社交网络中用户之间的可靠路径.游静等人[5]提出了一种考虑信任可靠度的分布式动态管理模型,使用可靠度对信任进行评估来降低不可靠数据的影响,并在交互结束后修正可靠度.此外,许多学者针对自适应声誉和信任相关性质等方面进行了相应的研究[5-11].本节将对前人所做的工作和DQN方法进行简要介绍.
1.1 DyTrust
DyTrust算法是利用学习算法进行动态信任计算的方法之一.DyTrust考虑了信任传播过程中节点信任值的动态变化,利用分布式学习自动机获取信任传播过程中信任的动态变化,对信任变化做出反应并根据信任的变化来动态更新可靠的信任路径.
该方法作为一种动态信任传播算法,可以更准确地推断出信任路径.但是该方法仅利用了信任的动态性特征,并未对其动态变化过程进行研究.本文的方法对信任动态变化过程进行研究,并详细阐述了该过程.
1.2 q学习与DQN
DQN[12]是q学习算法[13]的发展,也是将深度学习与强化学习结合起来而实现学习的一种新兴算法.
q学习算法通过单一神经网络进行值函数估计与现实累积经验计算,与q学习相比,DQN使用2个相同结构的神经网络分别计算值函数估计(Q网络)与现实(target-Q网络).Q网络估计每个动作的值(Q_eval),并根据策略选择最终动作,环境根据动作返回奖励值;target-Q网络利用奖励值进行现实估计(Q_target).
相较于Q网络,target-Q网络的权重更新较慢,即往往每经过多轮更新一次target-Q网络.该方法保证DQN可避免时间连续性的影响,从而得到更优结果.
同时,DQN方法利用经验回放对Q网络进行训练.DQN进行神经网络参数训练时,利用贝尔曼方程思想计算LossFunction并更新Q网络权重参数:
LossFunction=Q_target-Q_eval,
target-Q网络的计算方式由Markov决策得到.
本文中的信任增强算法结合DQN算法进行计算,实际上针对单个用户的信任增强过程使用q学习算法也可以取得相近的结果.现实中使用q学习方法时,状态量过多且需人工设计特征,且结果质量与特征设计质量关系紧密,导致q学习方法无法应用于推荐系统对大量用户进行项目推荐;同时,q学习方法需使用矩阵存储Q值,当针对用户过多时,会造成数据量过大,导致存储空间需求急剧增加.推荐系统中用户群体数目庞大,推荐项目类别复杂,对q学习方法的数据存储来说是一场灾难.
因此,考虑到本文提出的方法应用于推荐系统时的相关问题以及DQN相较于q学习算法的先进性,本文使用DQN算法进行信任增强,并推广至推荐系统.
2 问题描述与基本定义
本节详细介绍了问题的基本描述、用户信息集、推荐者信息集和DQN信息集等.
2.1 问题描述
如图1所示,用户A为提升用户B对自己的信任,向B推荐与他感兴趣的内容相关的项目.当B接受A的推荐后,如果B对A推荐的项目的评价高于其心理预期值,B对A的信任值将增加;反之,B对A的信任值将降低.
2.2 基本定义

定义1.用户信息集{T,S,sp}.
本文对社交网络中每个用户建立用户信息集.其中,T为用户信任矩阵,S表示用户评价矩阵,包括用户过往评价及用户对推荐项的预期评价,sp表示用户对推荐项的实际评价.
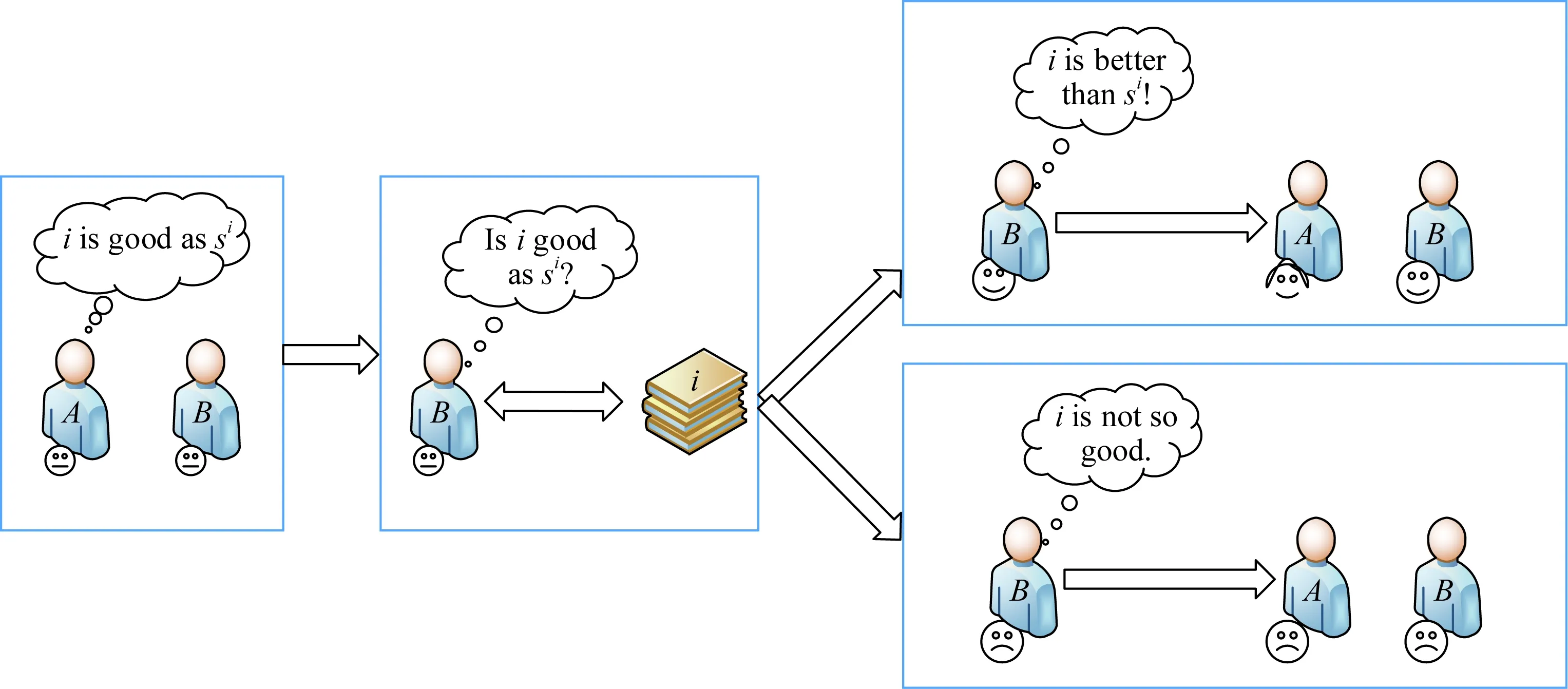
Fig.1 Relationship between recommendation and trust图1 建议-信任影响关系示意图
推荐过程中,推荐者从项目集中选择项目进行推荐,用户对符合偏好的项目有高满意度,满意度将动态影响用户间信任.
定义3.DQN信息集{n,a,π,r}.
1) 推荐者状态n.用户于时刻τ发出广播,推荐者根据选择策略做出动作,与该动作对应的推荐者状态为nτ.推荐者动作选择结束后,状态更新为nτ+1并等待用户下一次广播.
2) 推荐者动作a.推荐者从项目集选择最终向用户推荐的项目,推荐该项目即为推荐者动作a.
3) 动作选择策略π.选择策略决定推荐者最终选择的推荐项目.本文选择策略与DQN中策略相同,为ε-greedy policy.
4) 动作奖励r.用户对推荐者提供的推荐项将有相应的满意度.满意度对信任的影响幅度记为奖励r,该值影响推荐者在下一时刻的动作选择.
本文通过用户预期评价与实际评价差值来表征用户满意度,利用最小均方误差方法(least mean square, LMS)方法计算评价差值与信任变化的动态映射关系.本过程将信任的动态变化视为DQN过程中给予推荐者的奖励,信任的变化将影响推荐者对推荐项目的选择行为.
3 兴趣度、信任计算与建议处理
本节介绍了用户间信任的基本定义及用户建议定义,信任计算结合了用户兴趣度及推荐用户信任,使得计算结果更加符合实际.本节给出了用户建议处理过程,并说明了预期评价的计算方法.
3.1 用户兴趣度
1) 网页保存、收藏.sf(pk)表示保存、收藏参数.用户进行保存、收藏行为时,sf(pk)=1,否则sf(pk)=0.
2) 网页浏览.用户对网页内容感兴趣时,相应的网页浏览时间与访问次数均会增加.设置用户浏览时间比率表示单位页面大小的用户浏览时间,即浏览时间time(pk)与页面大小e(pk)之比,时间比率越大,表示用户对该网页内容越感兴趣.页面pk被访问次数f(pk)与页面浏览时间time(pk)构成页面浏览参数b(pk),即:
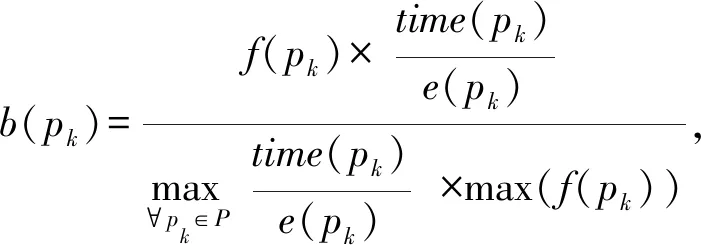
(1)
其中,P是所有用户浏览页面的集合.
3) 点击网页提供的超链接.超链接点击参数c(pk)通过点击的超链接数nc(pk)和页面pk提供的超链接总数ls(pk)计算为
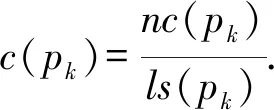
(2)
4) 分享、转发网页内容.分享参数trans(pk)衡量用户的分享行为,若用户对网页pk进行分享、转发操作,trans(pk)=1,否则trans(pk)=0.
用户对项目内容相关网页pk的兴趣度Im(pk)可计算为
(3)
(4)
3.2 信任计算及数据结构
用户间的信任可通过直接信任和推荐信任得到.有交互经验的用户为直接用户,无交互经验但存在信任路径的用户为间接用户.
有交互经验的直接用户之间产生直接信任,无交互经验但存在信任路径的间接用户之间产生推荐信任.
tj,b表示用户j对用户b的直接信任:
tj,b存储在矩阵T中,tj,b∈[0,1].

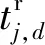
其中,信任值的范围为[0,1],信任值为0表示完全不信任,信任值为1表示完全信任.
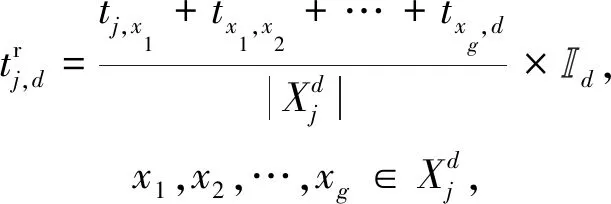
(5)
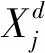
3.3 用户评价建议处理

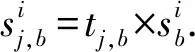
(6)
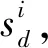
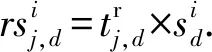
(7)
其中,rsi与si均存储在矩阵Si中,Si为初始用户j通过不同用户得到的对项目i的预期评价存储矩阵,用户评价分值范围为[0,10].
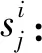
(8)
用户j接收到多项推荐时,将计算得到每个项目的预期评价,接受预期评价最高的项.
4 DQN信任增强过程
本节详细介绍了DQN信任增强过程(trust boost via deepq-learning, DQN-TB),说明了该过程的方法和流程,并给出了相应的伪代码.图2给出了DQN-TB过程的流程图框架.

Fig.2 Flow chart of DQN-TB图2 DQN-TB过程流程图
需要说明,DQN-TB过程中可以存在1对1关系,即只有用户u1期望提高u2对自己的信任值tu1,u2;也可以存在多对1的关系,即用户u1,u2,…均期望提高用户u3对自己的信任值.
4.1 模型框架
如图3所示,项目集中每个项目分别对应不同动作,DQN-TB方法将用户视为环境主体,在每个状态通过记忆池中的数据进行训练,并从项目集中选择项目作为最终动作向用户推荐项目,同时获得用户返回的奖励并将其与状态、动作存入记忆池中进行下一次网络训练更新.
本过程使用Q网络预期回报,并根据图2的过程流程及图3的框架图,更新网络:
Step1.推荐项目
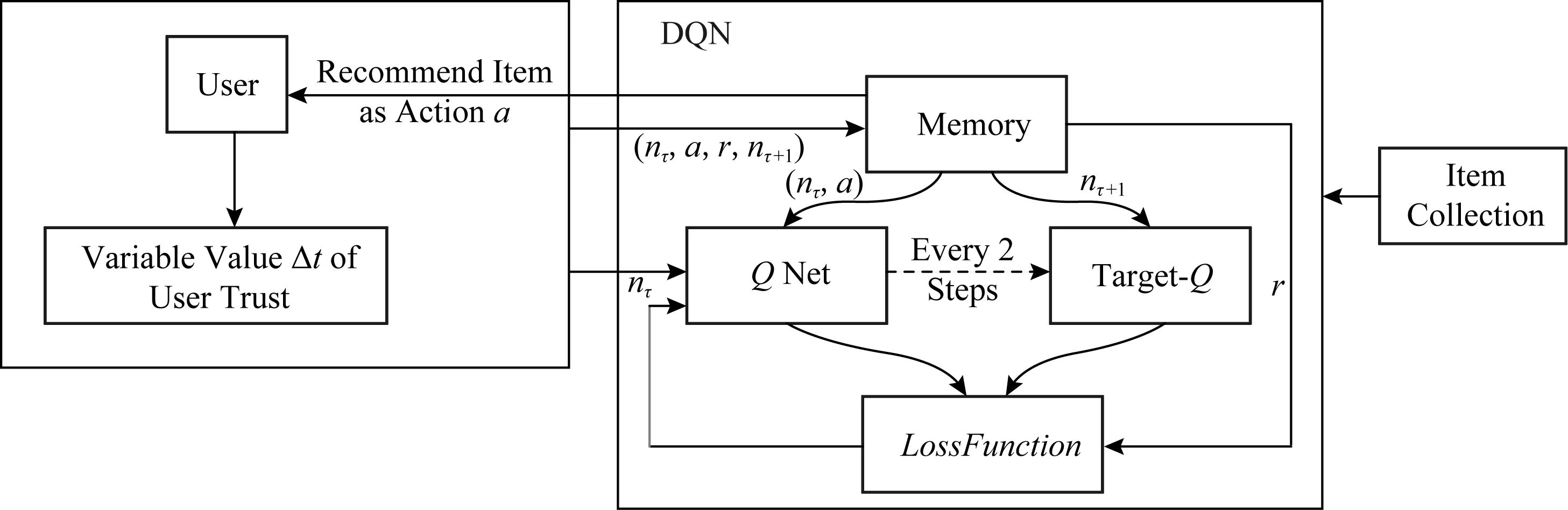
Fig.4 Data transmission process of DQN-TB图4 DQN-TB过程数据传输流程图
用户在时间τ发出广播,推荐者根据用户广播中的项目要求,从对应项目集中选择项目进行推荐,所选项对应动作aτ,推荐者状态记为nτ.
Step2.信任更新
用户收到并接受推荐项目后,预期评价与实际评价的差值将影响用户对推荐者的信任.将用户视为DQN-TB过程的环境,信任值t随着用户对推荐项目的满意度进行更新,用户的信任变化幅度Δt将作为DQN-TB过程的奖励值.
Δt与动作aτ、推荐者状态nτ和未来状态nτ+1存储在记忆池中,并作为网络输入.
Step3.网络训练学习
DQN-TB过程使用记忆池中的数据与Q网络进行动作预期选择,通过target-Q网络模拟用户现实,并根据Q网络与target-Q网络的差值更新Q网络.
Step4.重复Step1~Step3.
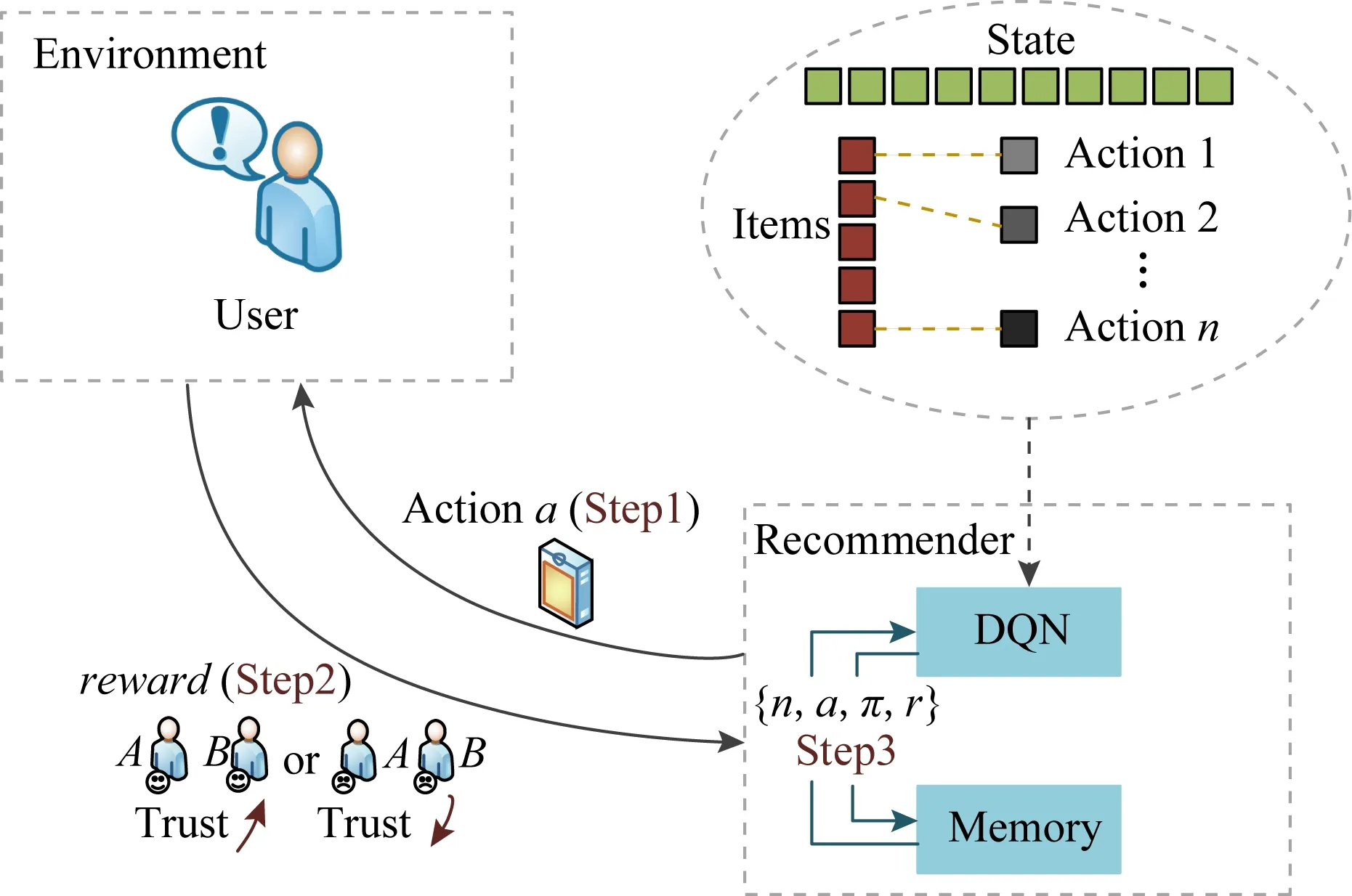
Fig.3 Framework steps of DQN-TB图3 DQN-TB过程步骤框架
考虑到现实情况,用户间的推荐过程一旦建立,将不会无条件停止.用户对推荐者信任值过低时,推荐者提供的意见不会被用户采纳.因此,若推荐者始终得到负向奖励或推荐失败次数过多,将会终止循环.为使推荐者可拥有更多机会进行推荐学习,同时考虑到实际情况,信任值过低时进行推荐不合现实,通过实验验证,发现当设定t<0.2时终止推荐,会得到较好的结果.并且,为防止信任值溢出,规定当t更新结束后,t>1时,取t=1.
4.2 DQN-TB设计
考虑信任的动态性以及推荐项目的具体过程,本方法使用Q网络来估计推荐者选择某项目进行推荐(即动作aτ)的回报.将信任变化程度作为奖励值后,项目选择回报可模型化为
Q(nτ,aτ;ω)≈Qπ(nτ,aτ),
(9)
其中,ω为Q网络权重参数,π为所选策略.考虑到推荐者与用户可能无交互经验,规定推荐策略:
1) 初次推荐.所有备选项目选择概率相等,随机选择推荐项.
2) 后续推荐.使用ε-greedy policy,选择概率根据推荐结果动态变化,最终收敛.
根据马尔可夫性,随机状态中下一时刻的状态只与当前状态有关.因此DQN-TB过程通过Q网络计算动作概率并作出动作选择后,会得到奖励值Δt及下一步的状态nτ+1.同时,实际回报由target-Q网络模拟计算:
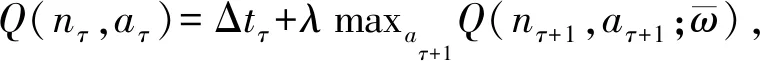
(10)
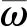

(11)
同时,对目标函数L(ω)使用随机梯度下降,即可更新Q网络参数ω.DQN-TB过程中,Q网络与target-Q网络结构相同,target-Q网络的权重参数与Q网络权重参数相同,每2次迭代同步1次.
图4给出了DQN-TB过程的数据传输流程过程.Q网络与target-Q网络提取记忆池中数据进行计算,根据计算出的Q_eval值从项目集中选取项目作为动作进行推荐.用户接受项目后,实际体验会使用户信任发生改变.用户信任更新后,信任变化值返回DQN-TB,Q网络的权重根据LossFunction进行更新,并进行下一轮迭代.DQN-TB过程中,Q网络每2步将网络权重传输至target-Q网络.
4.3 奖励参数Δt设置及信任更新
静态信任由于数值固定,无法准确表示用户在未来的信任关系,这一问题导致许多推荐算法不能响应用户关系及用户偏好的改变,使推荐结果的准确性降低.而随着经验累积,动态信任中的推荐者可及时响应用户的偏好改变,从而使推荐结果愈加精准.
已有部分学者将DQN方法应用于推荐系统,这使推荐过程保持长久的动态性.Zheng等人[14]提出了一种应用于新闻推荐的深度强化学习框架.该方法根据用户特征及行为反馈计算动态奖励值,使推荐系统能够捕捉用户偏好的改变,从而获得长久的奖励,并保持用户对推荐系统的兴趣.
本文提出的方法受到文献[14]的启发,考虑到信任的动态变化特性及长期推荐过程的经验学习,将信任动态变化幅度Δt作为奖励值,采用DQN进行过程建模.
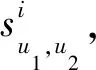
以u1,u2分别为用户和推荐者为例,使用LMS算法对信任变化及更新过程进行模拟:
由于实际信任更新过程中评价误差及信任均基于单个用户(即u1和u2),误差成本函数定义为
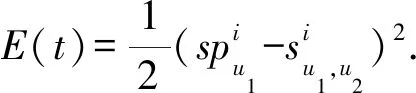
(12)
更新梯度g定义为
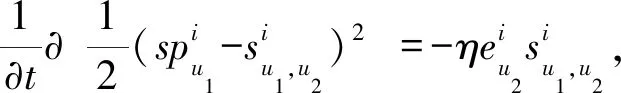
(13)
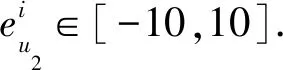
为保证数值计算合理性,防止信任更新值溢出,更新梯度g被约束为
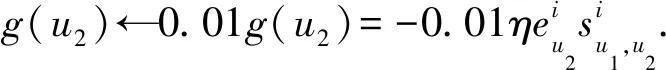
(14)
通过计算用户u1的实际评分与预期评分的差值,可对用户u1与推荐者u2的信任进行更新.若u1与u2的信任关系为直接信任,两者信任更新表示为
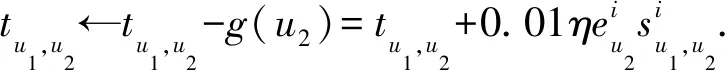
(15)
同样地,若u1与u2的信任关系为间接信任,更新表示为
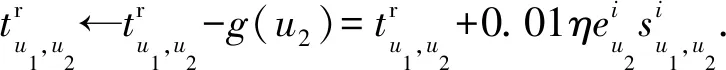
(16)
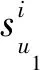
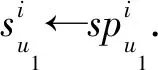
(17)
推荐者u2获得的奖励值为0.01g(u2)=Δt.
DQN-TB过程中,用户u1接受用户u2的推荐并做出实际评价后,该奖励值将作为参数输入网络中进行下一步计算.
4.4 Markov决策过程参数
表1给出了DQN-TB过程的Markov决策过程相关定义.

Table 1 Parameters of Markov Decision Process表1 Markov决策过程参数
用户推荐过程不会无条件停止,因此,用户状态数将随着推荐过程不断增加.推荐过程中的动作为推荐项目,因此可选动作与项目集中的项目数量相关.通过查阅相关文献和参考资料,本文设定γ=0.9.
4.5 算法伪代码
算法1.DQN-TB算法.
① 初始化记忆池D的容量N;
② 初始化Q网络的权重ω;
④ for (episode=1) do
⑤ 初始化序列n1={x1},序列预处理φ1=
φ(n1);
⑥ for (τ=1) do
⑦ 初次推荐使用随机概率ε选择动作aτ;
⑨ if (accept) do
⑩ 得到动作aτ的奖励值Δt,载入xτ+1;
4.6 计算复杂度分析
DQN-TB使用了随机梯度下降方法进行参数更新,因此,可知DQN-TB算法的计算复杂度为T(n)=(C+n)×n×n×n≈T(n4)=O(n4).可知算法复杂度为多项式级别.
5 实 验
本节将对DQN-TB过程中推荐信任与直接信任的转化比例、奖励参数计算中的信任更新学习率进行说明,同时说明DQN-TB过程的信任增强效果,并对DQN-TB应用于推荐系统后的性能给出了相应的对比验证,包括推荐成功率与感知用户偏好的动态变化.
5.1 基本介绍
本文使用仿真实验验证模型性能,来模拟推荐方向单个用户进行推荐,用户对推荐方的信任随推荐而变化的过程.实验环境基于OpenAI Gym,其中,奖励参数值reward随着DQN-TB的每一轮推荐,根据LMS方法动态更新,并传输至DQN-TB.实验数据使用从豆瓣采集的用户影评数据及电影项目类别,包括10个用户对11个电影项目类别中不同电影的评价数据,所有用户的观影总数为300部,影评数据规模为510条.实验从所有用户中随机选择用户作为目标用户,并进行推荐.
DQN-TB过程目的为提高单个用户信任值,本实验中Q网络结构示意如图5所示,Q网络从记忆池中提取数据输入到网络中,通过隐藏层计算Q值,并根据相应动作选择策略来选择最终动作.DQN-TB过程中的状态为用户当前信任值,动作为DQN-TB可向用户推荐的项目.
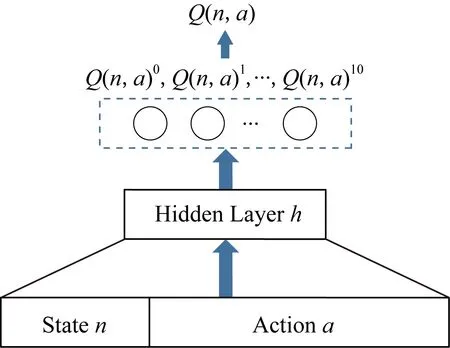
Fig.5 Q network structure图5 Q网络结构图
5.2 推荐信任与直接信任转化
用户项目推荐过程中,当通过推荐信任进行推荐后,用户间交互更新为直接信任,此时,为更符合现实情境,通过推荐信任计算出的信任值需进行一定折扣才可转化为直接信任值,并进行后续计算.推荐信任折扣因子由μ表示.
为确定μ的具体数值,本节使用4组小数据对选择不同折扣因子导致的结果变化进行分析.4组数据分别对应高推荐信任与高推荐评价、高推荐信任与低推荐评价、低推荐信任与高推荐评价、低推荐信任与低推荐评价,同时,4组数据中其他项均相同.分析使用的数据集由表2给出.推荐信任折扣因子μ采用不同数值时对结果影响如图6中整体评分项表示,对比评分项为仅使用Direct Trust1至Direct Trust4计算得出的预期评价.
由图6可知,当μ较低时,整体预期评价值低于对比评分;当μ较高时,推荐信任用户的评价结果对总结果起正向激励作用.该对比实验使用数据虽不能代表全部现实情况,但依旧可以反映推荐信任折扣因子μ对结果的影响.考虑到现实因素,当用户第一次进行直接信任推荐时,依旧会对评价主体用户有相应评分影响.为使用户评分由信任值影响,并尽量少的受到μ的干扰,本文设定μ=0.8.

Table 2 Trust Value and Score Value表2 信任及评分值表
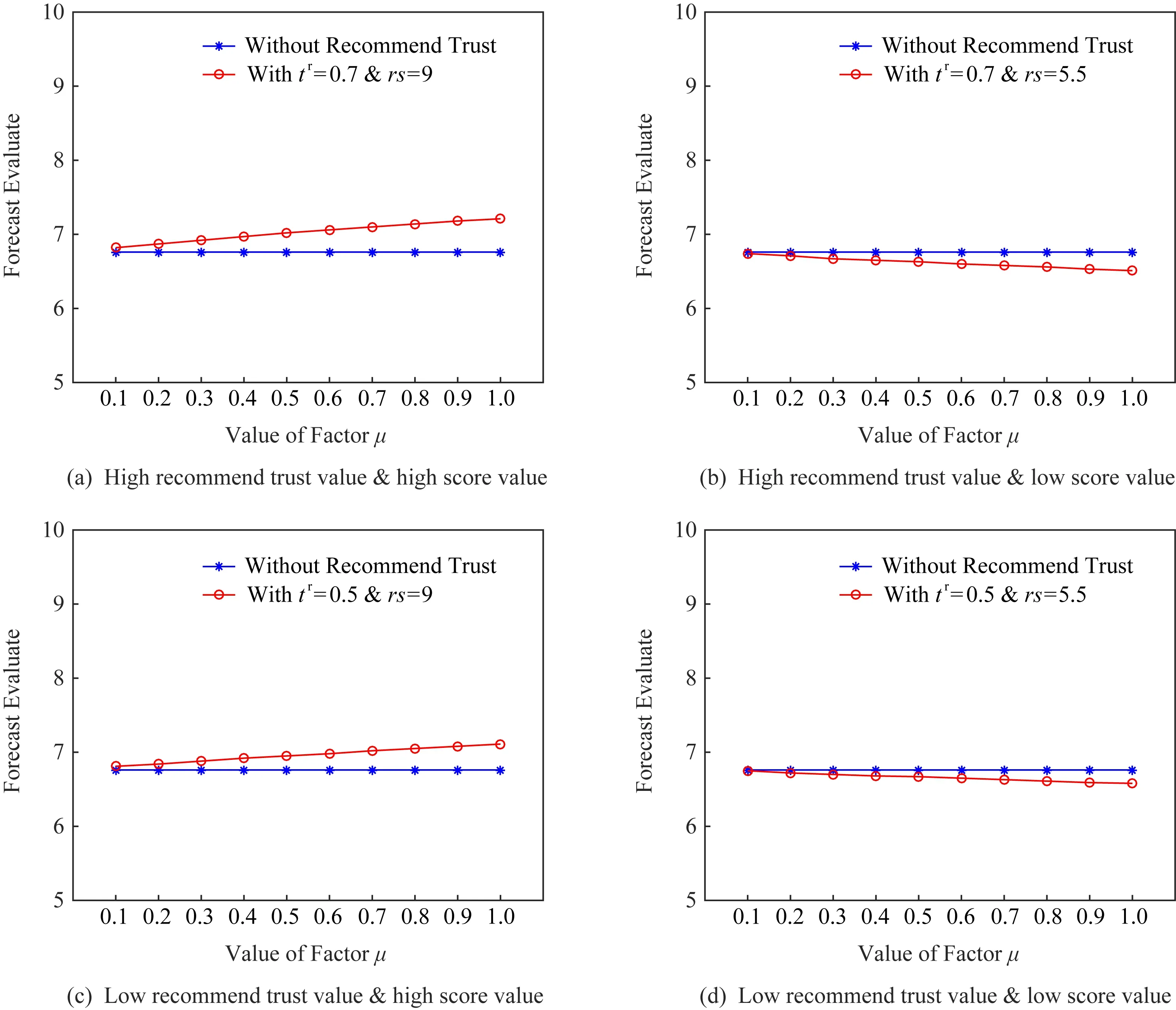
Fig.6 Performance comparison on different μ图6 不同μ下预期评价比较
5.3 信任更新学习率
由4.3节可知,奖励参数reward需要通过信任更新得到.信任更新的学习率η对更新结果有直接的影响.η过小会使更新步长过小,收敛速度过慢;η过大时收敛速度会提高,但可能因为步长过大而导致无法收敛.因此,本节将针对不同学习率对信任更新幅度的影响进行讨论.
信任更新时,根据建议用户与用户主体社会关系的远近,用户主体信任的更新幅度也会有所区别.本文将推荐用户分为直接用户和推荐用户.
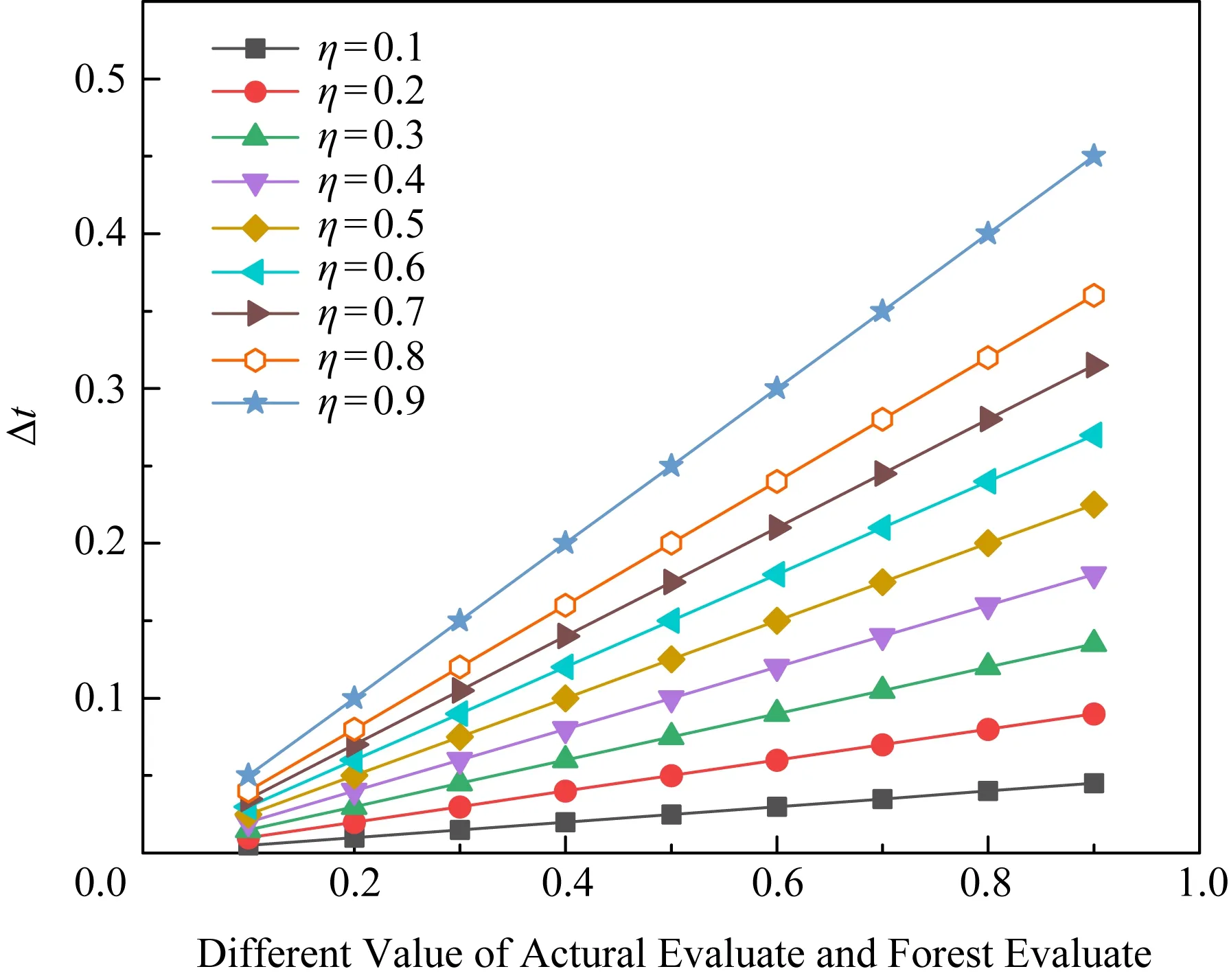
Fig.7 Performance comparison on different η图7 不同η下信任更新幅度比较
推荐用户由于社会关系较远,不会被用户主体给予高度包容性,同时由于心理预期较低,推荐成功后用户主体的信任值将变化较大,因此推荐信任的更新步长相对较大.并且,由于信任值范围为[0,1],η数值过高会导致信任变化过大,因此设定推荐用户信任更新学习率η=0.2.
对于直接用户,由于社会关系近,用户主体会抱有更多包容性,直接用户比推荐用户单次信任更新步长相对小,因此本文设定直接信任用户的信任更新学习率η=0.1.但直接信任用户信任更新存在累计作用,因此直接用户学习率设定为

其中,p为直接用户推荐得到正面反馈的次数,q为得到负面反馈次数.
5.4 信任动态变化
根据DQN-TB过程,用户通过推荐结果学习到相关经验后,推荐选择将会进一步调整,以符合被推荐用户的相关兴趣偏好.图8给出了DQN-TB过程中随轮次增加的信任变化折线图,用户初始推荐信任值为0.67.
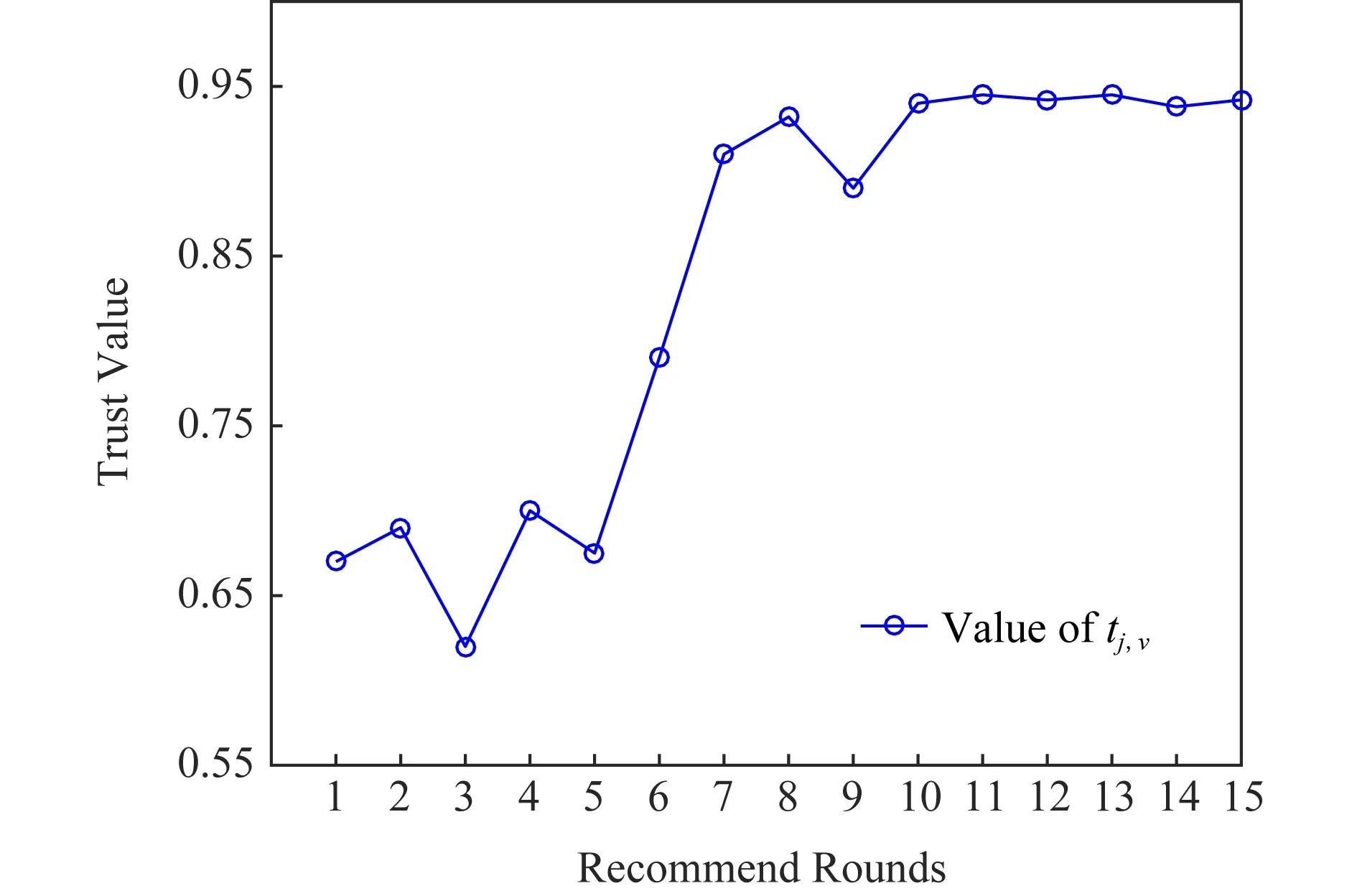
Fig.8 The line chart of dynamic change of trust value图8 信任动态变化折线图
当用户间第1轮推荐结束后、第2轮推荐开始前,用户间信任将根据5.2节中转化率进行推荐信任-直接信任转换,使得信任值有一定程度的下降.由图8可知,当轮次较少时,DQN-TB过程处在探索阶段,此时记忆池中的经验不够丰富,因此信任变化折线较为波折,由于最初用户间为推荐信任,因此当推荐者经验增加时,对被推荐用户的偏好的了解加深,此时用户间的信任值持续上升.并且由于成功经验的增多,后续推荐轮次中用户间信任值始终处于较高水平,且波动幅度很小.
DQN-TB过程可较准确地刻画用户的信任变化状态,并取得较好的效果.用户信任的动态变化可以实时地反映用户偏好的变化以及社交关系的改变,因此DQN-TB的动态性研究是很有意义的,这一特性也为DQN-TB应用于推荐系统带来更多灵活性.
5.5 DQN-TB应用于推荐系统
5.4节中的实验验证了DQN-TB对于信任的动态变化及增强都有准确的刻画,因此该方法亦可应用于推荐系统中,为系统中的用户提供精准的推荐.本节将DQN-TB与Li等人[15]的CSIT方法和Gohari等人[16]提出的CBR方法进行了对比,并比较了三者向用户进行推荐的成功率及三者对用户偏好改变的响应灵敏度.
CSIT方法是一种性能优越的矩阵因子分解和上下文感知推荐者法,作者同时提供了GMM方法进行增强并同时处理分类上下文和连续上下文.CBR方法使用对用户意见的信任和意见的确定性来描述用户信心,并将用户信心引入信任建模,通过隐式信任模型向用户提供一系列的推荐.由于目前的推荐系统仅利用用户的社交关系以及关系网络中其他用户的偏好来进行相关推荐,无法反映用户的信任变化,且用户的偏好变化捕捉只能来源于关系网络中的其他用户,造成系统对用户偏好的变化反馈不及时、不准确.
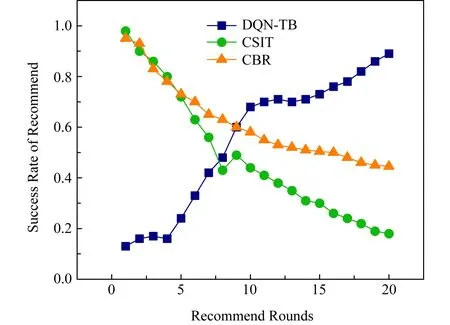
Fig.9 Change of success rate in recommend system图9 推荐系统成功率变化
图9给出了用户信任与偏好动态变化下,20轮内不同轮次对应的DQN-TB方法、CSIT方法和CBR方法的平均成功率对比.随着推荐轮次的增加,DQN-TB拥有越来越高的准确率,这是由于DQN-TB对于动态变化响应的灵活性.同时,由于CSIT方法和CBR方法的对用户偏好感知的计算方法影响,两者的准确性随条件的动态变化而逐渐下降.实际情况中,普通推荐者法准确率下降的速度随用户偏好的变化幅度而有所偏差,但亦足以说明DQN-TB的优越性.
5.6 响应灵敏度
定义MANR表示用户偏好变化后推荐系统响应变化所需要的轮次(answer rounds, ANR),MSUMR表示推荐总轮次(sum rounds, SUMR),MSEN表示推荐系统相应用户偏好变化的灵敏度(sensitivity, SEN),则MSEN可计算为
表3给出了450轮推荐中用户偏好变化60次后各推荐系统的响应灵敏度.隐式信任模型与上下文矩阵分解过多的依赖用户的邻居及相似用户,当偏好改变多次时,相关信息的分析将失去其准确性,将无法及时反馈用户的偏好.CBR方法同时为用户推荐多个项,因此具有一定的覆盖性,响应灵敏度优于CSIT模型.表3的数据验证了DQN-TB过程对用户偏好具有较好的灵敏度,这一特性与DQN-TB过程中的动态奖励及经验学习有关.因此,将DQN-TB过程应用到推荐系统可及时感知用户偏好的改变,并相应地调整推荐项目的选择.

Table 3 Response Sensitivity of Each Recommendation System表3 各推荐系统响应灵敏度
6 总结及未来展望
本文结合强化学习方法提出了一种基于动态信任的信任增强方法,该方法通过用户信任的动态变化感知用户偏好的变化,并根据推荐经验进行学习,以提供更加准确的推荐,从而使用户信任增加并保持在较高水平.实验表明:所提出的方法是高效、准确的.同时,本方法也可应用于推荐系统,并达到感知用户偏好变化、进行精准推荐的目的.
本文的方法重点考虑用户信任的动态变化,未来,将针对信任及建议计算方法进行改进以使推荐的结果更加精准、有效.
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
故事会(2018年14期)2018-07-19
故事会(2017年23期)2017-12-08
桃之夭夭B(2017年2期)2017-02-24
故事会(2016年2期)2016-01-19
故事会(2015年18期)2015-05-14
高中生·青春励志(2014年11期)2014-11-25
